RAG 처음부터 고도화까지 — 5편: Agentic RAG · GraphRAG · RAPTOR · Long-Context
이번 글의 목표
지금까지 한 모든 게 단발 RAG (질문 한 번 → 응답 한 번) 였습니다. 2026 년의 모던 아키텍처는 그 위 한 단계 — Agentic / Graph / Tree-summary 패턴.
다룰 것:
- Agentic RAG — LLM 이 검색을 도구로 부르며 반복 추론 (ReAct)
- GraphRAG — 엔티티-관계 그래프로 multi-hop 질문 해결
- RAPTOR — 재귀 요약 트리로 추상/구체 양쪽 잡기
- Long-context LLM vs RAG — 누구를 언제 쓰나
- Semantic Caching — 비용 / 지연 절감
- LLM Wiki — Karpathy 패턴, 누적 학습형 RAG
1. Agentic RAG — LLM 이 도구를 부르는 루프
기본 RAG: 질문 → 검색 1회 → LLM 응답 1회.
Agentic RAG: 질문 → LLM이 도구 호출 → 결과 받음 → 또 도구 호출 → ... → 최종 응답.
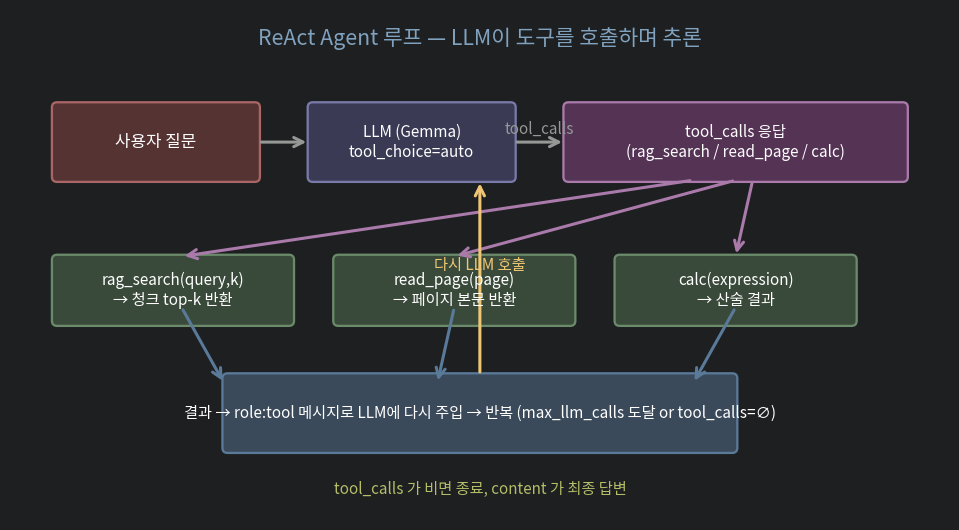
LLM 이 검색, 페이지 읽기, 계산, 외부 API 같은 도구를 자유롭게 부르며 답을 찾아갑니다. ReAct (Reasoning + Acting) 가 가장 흔한 패턴.
1.1. OpenAI 호환 tool calling
TOOLS = [{
"type": "function",
"function": {
"name": "rag_search",
"description": "사내 PDF에서 청크 검색.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"k": {"type": "integer", "default": 5},
},
"required": ["query"],
},
},
}, {
"type": "function",
"function": {
"name": "read_page",
"description": "특정 page 전체 본문 반환.",
"parameters": {
"type": "object",
"properties": {"page": {"type": "integer"}},
"required": ["page"],
},
},
}]
response = llm.chat(messages, tools=TOOLS, tool_choice="auto")LLM 이 도구를 부르면 tool_calls 가 응답에 들어옵니다. 우리는 그걸 실행해서 결과를 다시 role:tool 로 메시지에 주입 → 다시 LLM 호출. tool_calls 가 비면 루프 종료.
1.2. 무한 루프 방지
MAX_LLM_CALLS = 8 # 한 질문당 LLM 호출 한도
for turn in range(MAX_LLM_CALLS):
resp = llm.chat(messages, tools=TOOLS, tool_choice="auto")
msg = resp.choices[0].message
tcs = msg.get("tool_calls", [])
if not tcs:
break # 최종 응답
messages.append({"role": "assistant", "content": msg.content, "tool_calls": tcs})
for tc in tcs:
result = run_tool(tc.function.name, json.loads(tc.function.arguments))
messages.append({"role": "tool", "tool_call_id": tc.id,
"content": json.dumps(result, ensure_ascii=False)})MAX_LLM_CALLS 한도가 핵심. LLM 이 같은 도구를 반복 호출하며 답을 못 찾을 때 강제 종료.
1.3. 시스템 프롬프트
"너는 사내 문서 분석 보조다. 답하기 전 반드시 rag_search 로 근거를 찾고,
필요하면 read_page 로 전체 본문을 본 뒤 답변하라. 답변에는 참조한 page 번호를 표기한다.
근거가 없으면 '근거 없음'."Agent 의 행동을 강하게 제약하는 게 중요. 안 그러면 LLM 이 도구 안 쓰고 그냥 답해버리는 경우가 흔합니다.
1.4. 언제 쓰나
- Multi-hop 질문 — "A 와 B 의 차이를 C 기준으로" 같은 비교
- 답에 필요한 정보가 여러 페이지에 흩어진 경우 — 한 번 검색으론 부족
- 계산 / 외부 데이터 필요 — DB 조회, API 호출
비용 / 지연이 단발 RAG 의 3~10배가 됩니다. 모든 질문을 agent 로 돌리지 말고, Adaptive RAG (Part 4) 와 짝지어 어려운 질문만 agent 로 라우팅하는 게 정석.
2. GraphRAG — 엔티티 그래프
위 agentic 패턴이 강해도 한계가 있습니다. multi-hop 추론 에서 LLM 이 도구를 여러 번 부르더라도 흩어진 정보를 잘 종합하지 못하는 경우.
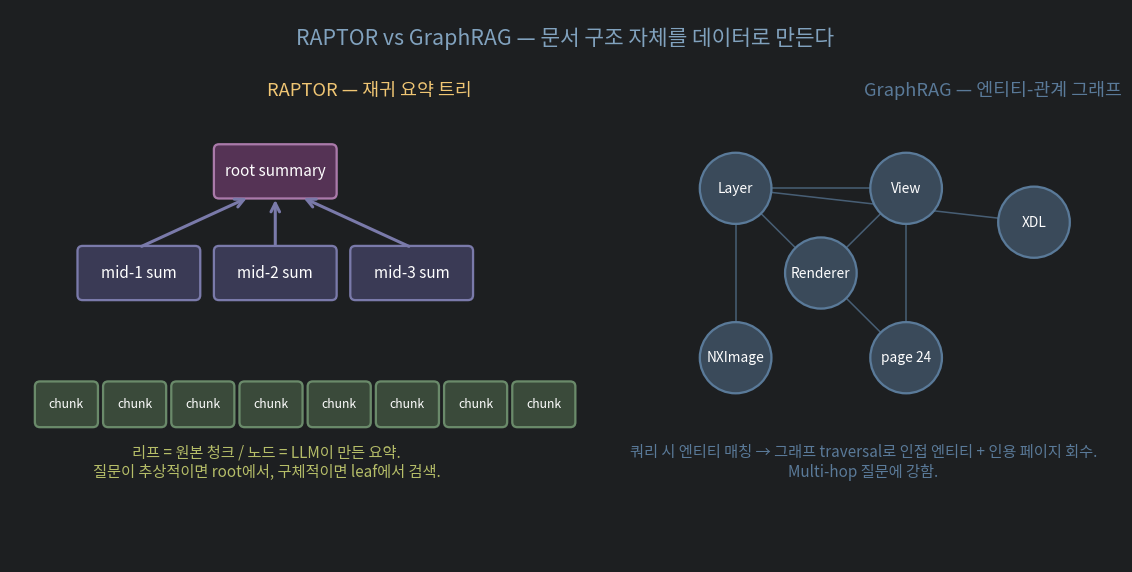
GraphRAG (Microsoft, 2024) 의 접근: ingest 단계에 LLM 을 써서 엔티티-관계 그래프를 미리 만든다.
2.1. Ingest — 그래프 빌드
원본 청크 한 개씩 LLM 에 입력
↓
LLM 이 (엔티티, 관계, 인용 페이지) 트리플 추출
("Layer", "contains", "View")
("View", "rendered by", "Renderer")
↓
누적해서 그래프 DB (Neo4j) 또는 JSON 으로 저장
↓
커뮤니티 탐지 (Leiden 알고리즘) 로 부분그래프 클러스터링
↓
각 클러스터를 LLM 으로 요약 → "community summary"비용은 ingest 단계의 LLM 호출이 큽니다. 청크 수만큼 LLM 호출 + 추가 요약.
2.2. Query — 그래프 traversal
질문에서 엔티티 추출 (LLM)
→ 그래프에서 그 엔티티 + 인접 엔티티 회수
→ 관련 community summary 들 + 청크 본문 추가
→ LLM 에 컨텍스트로 주입- 장점: multi-hop 질문에 강함. "X 와 Y 의 관계가 Z 에 미치는 영향?" 같은 거
- 장점: 전체 도메인의 상위 수준 패턴 을 community summary 로 답 가능
- 단점: ingest 비용 큼. 도메인이 자주 바뀌면 재빌드 비용도 큼
운영에서는 GraphRAG + 일반 RAG 하이브리드 가 보통 — 단답형은 일반 RAG, 종합형은 GraphRAG.
microsoft/graphrag 라이브러리가 구현체.
3. RAPTOR — 재귀 요약 트리
GraphRAG 가 엔티티-관계 위주라면, RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval, 2024) 는 요약 계층 위주입니다.
3.1. Ingest
원본 청크들 (leaf)
↓ 클러스터링 (GMM)
같은 클러스터 청크들을 LLM 이 요약 → 중간 노드
↓ 클러스터링 다시
요약들의 요약 → 상위 노드
↓
... 한 root summary 가 나올 때까지결과: 트리. 잎 = 원본 청크. 노드 = 요약.
3.2. Query
세 모드:
| 모드 | 어떻게 |
|---|---|
| tree traversal | root 부터 내려가며 가장 관련 있는 가지만 따라감 |
| collapsed tree | 트리의 모든 노드를 같은 인덱스에 넣어 보통 검색 |
| 하이브리드 | 위 둘 결합 |
- 추상적 질문 ("이 문서가 다루는 주제 요약해줘") → root 근처 요약 매치
- 구체적 질문 ("XDL 의 setSource 호출 순서") → leaf 청크 매치
같은 인덱스에서 추상-구체 양쪽 질문 을 다 답할 수 있는 게 RAPTOR 의 핵심.
비용: ingest 단계의 LLM 호출 (요약 생성). 청크 1만 개면 요약 호출 약 3천~5천 회 추가.
4. Long-Context LLM vs RAG — 누구를 언제
2024~2026 사이 LLM 컨텍스트가 100만 토큰 (Gemini), 200K 토큰 (Claude) 까지 늘었습니다. PDF 한 권 그대로 넣을 수 있다. 그러면 RAG 가 필요 없는 거 아닌가?
| 지표 | Long-Context | RAG |
|---|---|---|
| 정확도 (긴 문서 1개) | 비슷 또는 ↑ | 비슷 |
| 지연 (latency) | ↓↓ (한 번 호출에 다 들어감) | ↑ (검색 + LLM) |
| 비용 (입력 토큰) | ↑↑↑ (매 질문마다 전체) | ↓ (필요 부분만) |
| 문서 N권 | 한도 초과 | 그대로 ↑ |
| 문서 업데이트 | 매번 다시 보내야 | 인덱스만 갱신 |
| 환각 (잘못된 곳 보기) | "Lost in the Middle" 다시 발생 | reranker 로 압축 가능 |
결론:
- 단일 짧은 문서 + 매 질문마다 다른 요구 → Long-Context 가 빠르고 단순
- 다수 문서 + 자주 갱신 + 비용 민감 → RAG 가 압도적
- 운영 환경 99% → 후자
Long-Context 가 RAG 를 대체한다기보단, 둘이 결합 — 검색으로 top-50 청크 가져오고 그걸 long-context LLM 에 통째로 넣는 게 새 baseline 입니다.
5. Semantic Caching — 같은 질문 두 번 답하지 말자
같은 질문이 여러 번 들어오면 매번 검색·LLM 호출은 낭비.
# 1) 들어온 질문을 임베딩
q_vec = embedder.encode(question)
# 2) 캐시 (Redis vector / 자체 Qdrant 컬렉션) 에서 비슷한 질문 검색
cached = cache_db.search(q_vec, threshold=0.95)
if cached:
return cached.answer # 캐시 히트 — LLM 호출 0회
# 3) 캐시 미스 → 일반 RAG 흐름 → 결과를 캐시 적재
answer = rag_pipeline(question)
cache_db.upsert(question, q_vec, answer)
return answer- 임계값
0.95가 보통. 너무 낮으면 잘못된 캐시 매치 (다른 질문에 같은 답) - 캐시 TTL 필요 — 문서 업데이트되면 캐시 무효화
GPTCache, Redis Vector, Pinecone, 자체 Qdrant 컬렉션 다 가능.
운영에서 반복 질문 비율 30~50% 가 흔합니다 → 캐시 도입으로 평균 LLM 비용 절반 이하로 떨어지기도.
6. LLM Wiki — 누적 학습형 RAG
Andrej Karpathy 가 X(twitter) 에 던진 패턴: LLM 이 문서를 처음 보면 자기만의 정리 노트를 만들고, 이후 그 노트를 우선 본다.
6.1. 폴더 구조

mini_wiki/
├── CLAUDE.md # 운영 규칙
├── raw/ # 원본 — 읽기만, 절대 수정 안 함
│ └── XDL3.0.pdf
└── wiki/
├── index.md # 모든 엔티티 페이지 카탈로그 (자동 갱신)
├── log.md # append-only 변경 기록
└── entities/
├── layer.md
├── view.md
└── renderer.md6.2. Ingest 흐름
새 원본이 raw/ 에 들어오면
↓ LLM 이 본문 읽고 엔티티 3~7 개 추출
각 엔티티 → wiki/entities/<이름>.md 작성
- 정의 / 관련 다른 엔티티 / 원본 참조 페이지
↓
index.md 갱신, log.md 에 append6.3. Query 흐름
사용자 질문
↓ LLM 이 wiki/entities/ 카탈로그 보고 관련 페이지 선정
선택된 entities/*.md 의 본문을 컨텍스트로 답변
→ 새로운 사실이 나오면 해당 entity 페이지에 추가 (누적 학습)차이점:
- 일반 RAG 는 원본의 슬라이스를 검색 — 매 질문이 같은 비용
- LLM Wiki 는 LLM 이 만든 정리 페이지를 검색 — 두 번째 같은 질문부터 훨씬 빠르고 정확
운영 환경에서 GraphRAG / RAPTOR 의 가벼운 버전 으로도 쓸 수 있습니다 — 그래프/트리 DB 없이 markdown 파일 + git 만으로.
7. 여기까지의 정리 — 5개 축 전체 그림
지금까지 다룬 것:
| 축 | 무엇 |
|---|---|
| ① 청킹 | recursive / semantic / Small-to-Big / multi-vector / 메타데이터 |
| ② 임베딩 | e5 · bge-m3 · 도메인 fine-tune |
| ③ 검색 | Multi-Query · HyDE · Step-Back · Hybrid (Dense+BM25+RRF) · ColBERT |
| ④ 재정렬 | Cross-encoder · LLM-as-Reranker · MMR · LiM 재배치 · 컨텍스트 압축 |
| ⑤ 생성 | 프롬프트 · Self-RAG · CRAG · Adaptive · RAGAS 평가 |
| 고급 | Agentic / GraphRAG / RAPTOR / Long-Context / Semantic Cache / LLM Wiki |
어디서부터 적용할지 우선순위:
- 첫 주 — Small-to-Big 청킹 + Cross-encoder reranker + 명시적 프롬프트 ("근거만") + RAGAS 50문항. 보통 이 4개로 baseline 의 RAGAS faithfulness 가 0.6 → 0.8.
- 다음 주 — Hybrid (Dense + BM25 + RRF) + Multi-Query / HyDE 추가. context_recall 큰 폭 개선.
- 그 다음 — Self-RAG 흉내 (or 진짜 Self-RAG 모델) + Adaptive 라우팅. 환각 ↓ + 평균 비용 ↓.
- 최종 단계 — Agentic / GraphRAG / RAPTOR 중 도메인에 맞는 거 선택.
측정 안 하면 모른다는 거 가 시리즈의 한 줄 요약. 모든 변경 → RAGAS 4지표 → 효과 있는 것만 채택. 그게 운영 가능한 RAG 입니다.
참고
- GraphRAG (Microsoft Research, 2024): arXiv:2404.16130 · github
- RAPTOR (Sarthi et al., 2024): arXiv:2401.18059
- ReAct (Yao et al., 2022): arXiv:2210.03629
- atalupadhyay, 9 RAG Architectures Every AI Developer Must Know: link
- MarsDevs, Agentic RAG: The 2026 Production Guide: link
