Instruction Tuning이란 구글의 FLAN(Finetuned Language Models are Zero-Shot Learners) 논문에서 처음 나온 개념입니다.
이를 간단하게 설명하자면 LLM 모델을 Instruction 데이터셋을 통해 fine-tuning을 진행하고 이를 통해 zero-shot 성능을 높이는 방법입니다.
이를 알아보기 전에 LLM의 발전 순서를 알면 좋기에 이를 먼저 소개하고자 합니다.
참고 : Natural Language Processing with Deep Learning CS224N/Ling284
- Zero-Shot and Few-Shot In-Context Learning
- Instruction tuning
- Reinforcement Learning from Human Feedback (RLHF)
1. Zero-Shot and Few-Shot In-Context Learning
2018년 OpenAI는 GPT를 발표합니다.
이 때 GPT는 12개의 Transformer Decoder layers와 7000개가 넘는 책(4.6GB)을 통해 학습을 하였습니다.
이는 모델의 크기가 Pretrained Model의 성능에 영향을 준다라는 시사점을 내보였습니다.
이후 2019년 OpenAI는 GPT-2를 발표합니다.
기존 GPT와 달라진 점은 다음과 같습니다.
같은 아키텍처를 사용하지만 파라미터가 117M -> 1.5B로 크게 증가합니다.
학습데이터 또한 4GB -> 40GB(Reddit 수집)으로 크게 증가합니다.
GPT-2의 가장 큰 특징으로는 Zero-shot, Few-shot learning입니다.
GPT-2는 Task에 따른 Fine tuning 없이 기존 Task의 SOTA 모델들을 넘어섭니다.
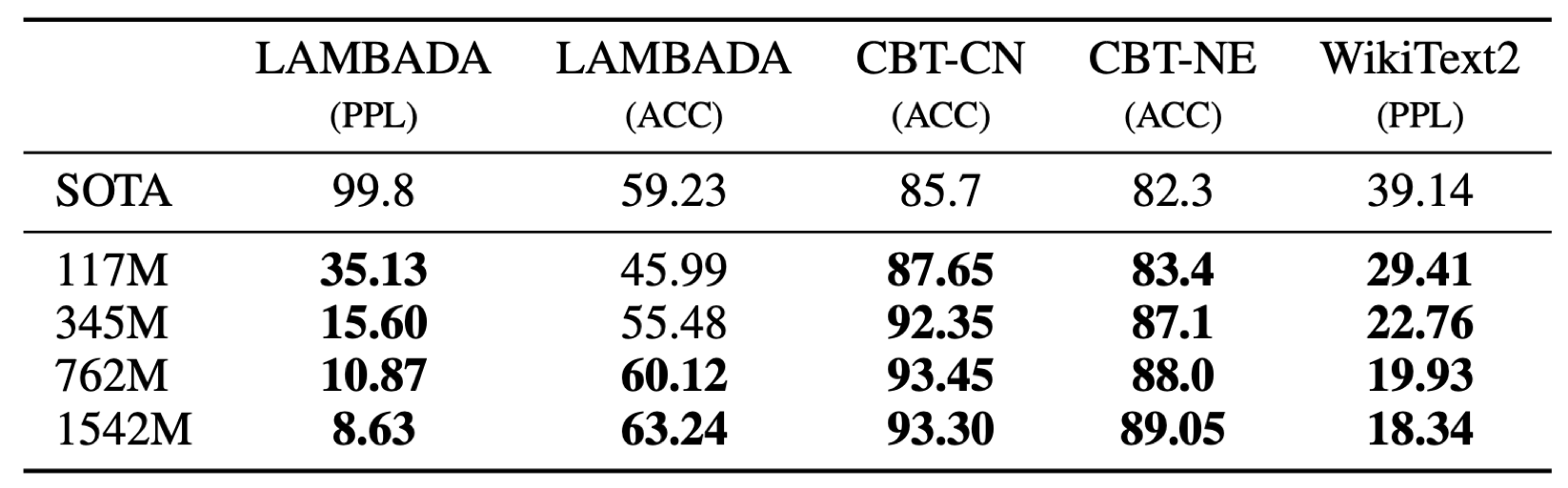
이를 통해 잘 학습된 LLM 모델 하나로 모든 Task를 할 수 있을지도 모른다는 임팩트를 남깁니다.
이후 2020년 OpenAI는 GPT-3를 발표합니다.
GPT-3 또한 파라미터와 데이터를 크게 늘렸습니다.
파라미터는 1.5B -> 175B, 데이터는 40GB -> over 600GB로 크게 증가하였습니다.
GPT-3는 다음 그림과 같이 풀고자 하는 문제를 제시하기 이전에 여러 예시를 제시하여 문제의 Task를 특정합니다.
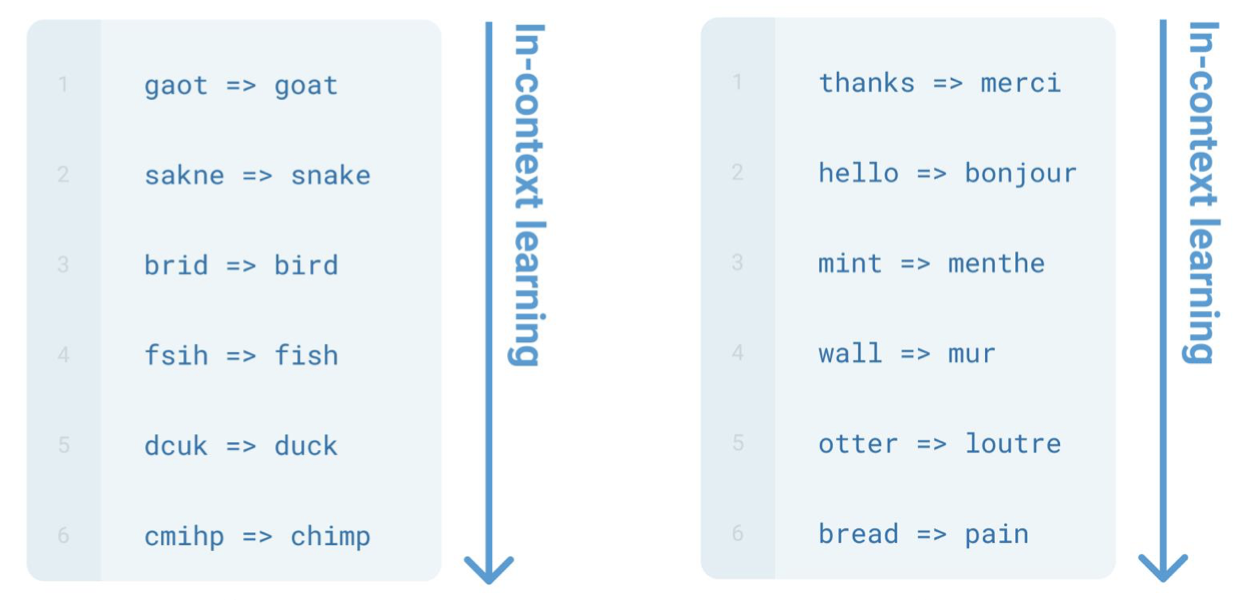
이는 새로운 Task를 배울 때 가중치 업데이트가 일어나지 않는 점에서 "in-context learning" 라고도 불립니다.
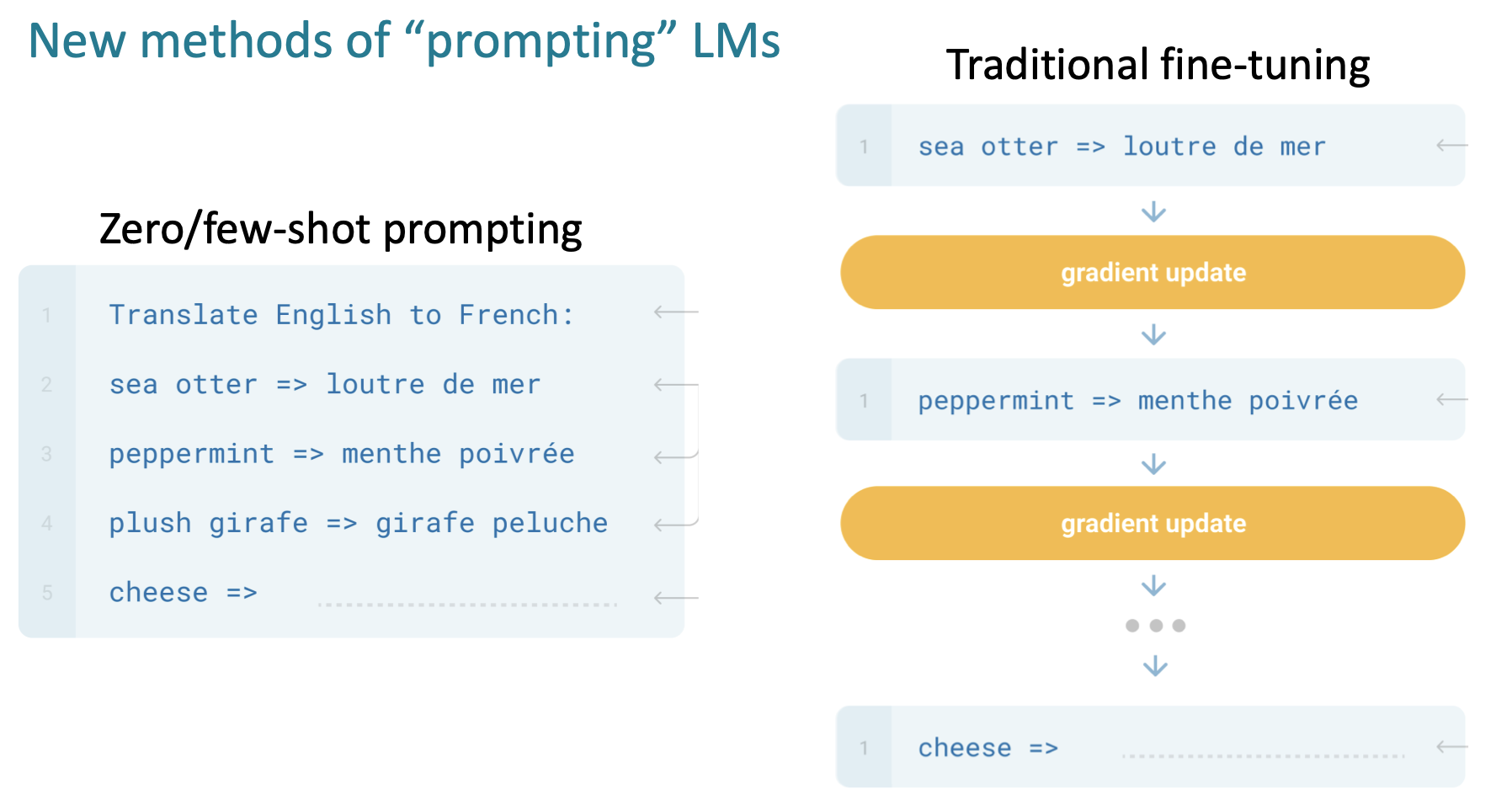
예시마다 가중치가 업데이트 되던 기존 방식과 다르게 이러한 "in-context learning"의 발견으로 인해 Prompt에 대한 중요성 또한 대두되었습니다.
하지만 해당 방식의 한계점 또한 존재합니다.
바로 여러 스텝을 거쳐야 풀 수 있는 문제들과 같이 Prompt만으로 배우기 어려운 문제들입니다.
이러한 한계점을 해결하기 위해 Chain-of-Thought Prompting 방식이 등장합니다.
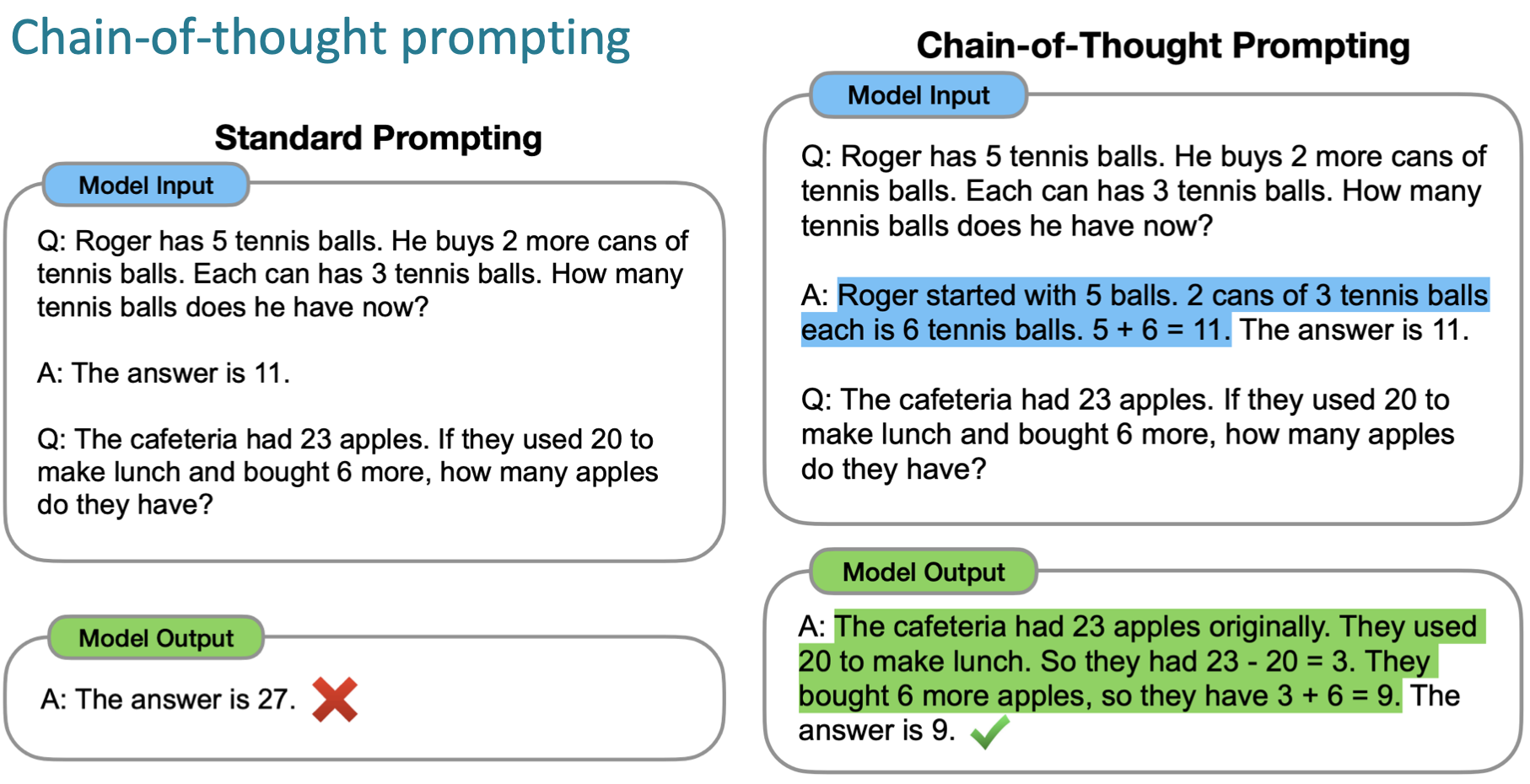
해당 방식에서는 A.에 해결 방식을 step by step으로 제시함으로써 Model의 Prompt 이해도를 높입니다.
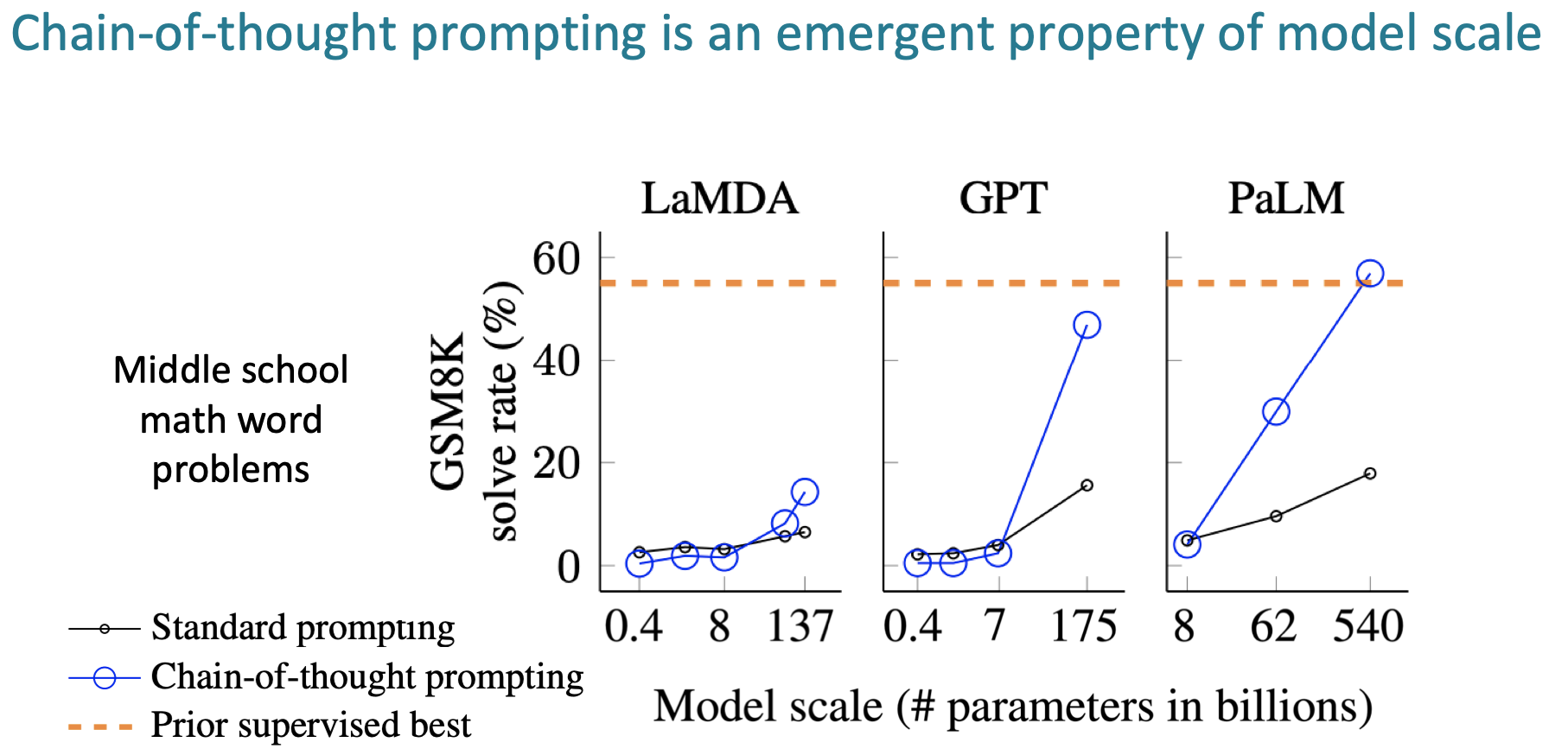
Model의 크기가 클 때 Chain-of-thought를 적용하면 지도학습 성능을 따라가는 양상을 보여줍니다.
여기서 한 발자국 더 나아간 방식이 "Zero-shot chain-of-thought prompting"입니다.
이는 기존의 step by step 제시를 LLM inference 결과로 대체합니다.
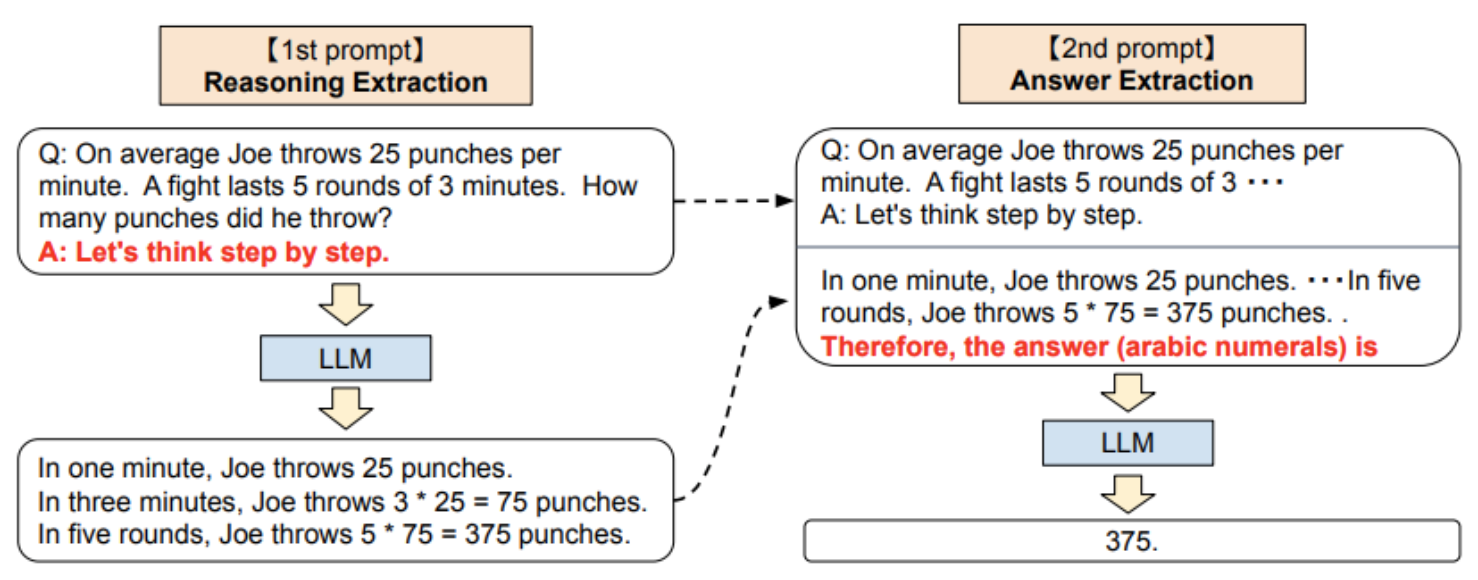
그 결과 다음과 같이 큰 성능 향상을 얻을 수 있었습니다.

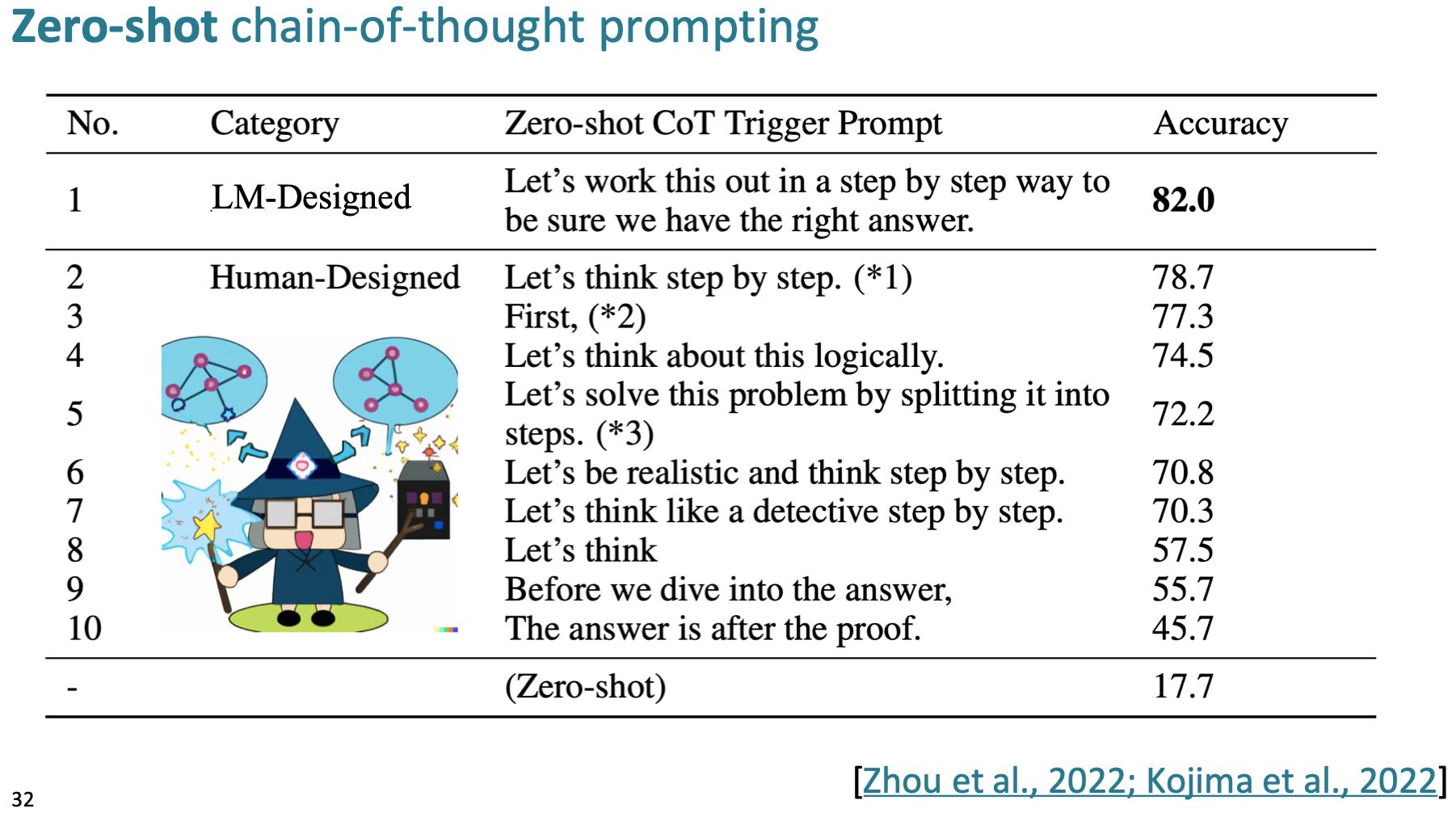
CoT를 유도하는 prompting은 다음과 같다고 합니다.
더욱 다양한 prompt에 대한 정보는 다음 링크에서 볼 수 있습니다. ChatGPT Prompt Engineering for Developers
Zero-Shot and Few-Shot In-Context Learning 정리
- 장점
- fine-tuning 없이 Prompt Engineering 만으로도 성능을 향상시킬 수 있다.
- 한계
- Limits to what you can fit in context
- Complex tasks will probably need gradient steps
2. Instruction finetuning
Instruction finetuning 등장 배경의 메인 키워드는 "Aligning"입니다.
이는 다음에 소개할 RLHF에도 등장하는 메인 키워드입니다.
Aligning을 잘 보여주는 예시가 있습니다.
우리는 달 착륙에 대해 질문을 하면 다음과 같은 답변을 원합니다.

하지만 GPT-3는 다음과 같은 결과값을 반환합니다.

이는 LM이 user의 의도는 다른 답변을 주는 문제점을 의미합니다.
그렇기에 이를 finetuning으로 해결하는 방법이 Instruction finetuning입니다.
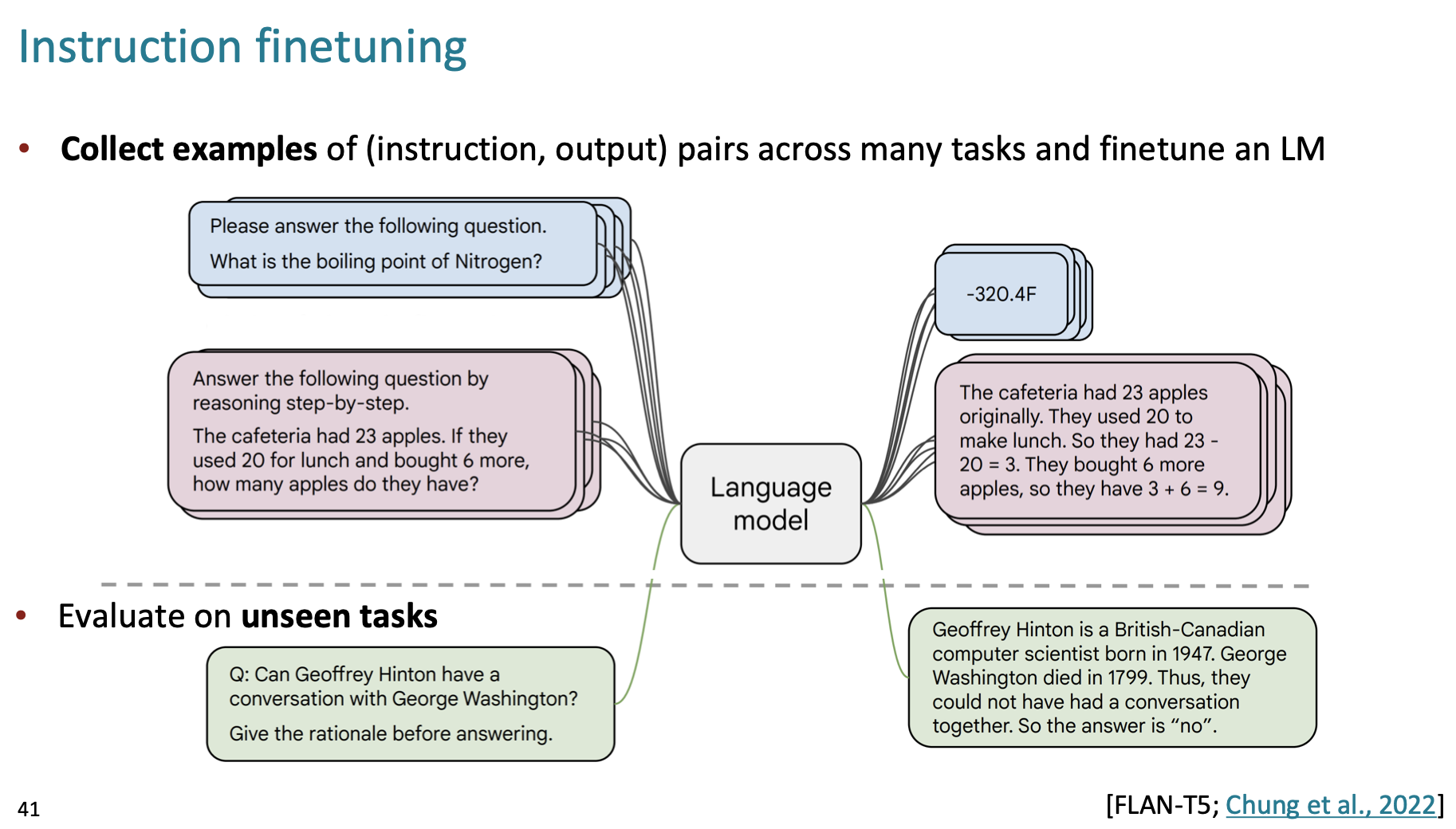
이는 위 그림과 같이 Instruction, output의 pairs 데이터셋을 통해 학습을 진행합니다.
이 때 해당 데이터셋에는 다양한 종류의 Task가 instruction 형태로 들어 있습니다.
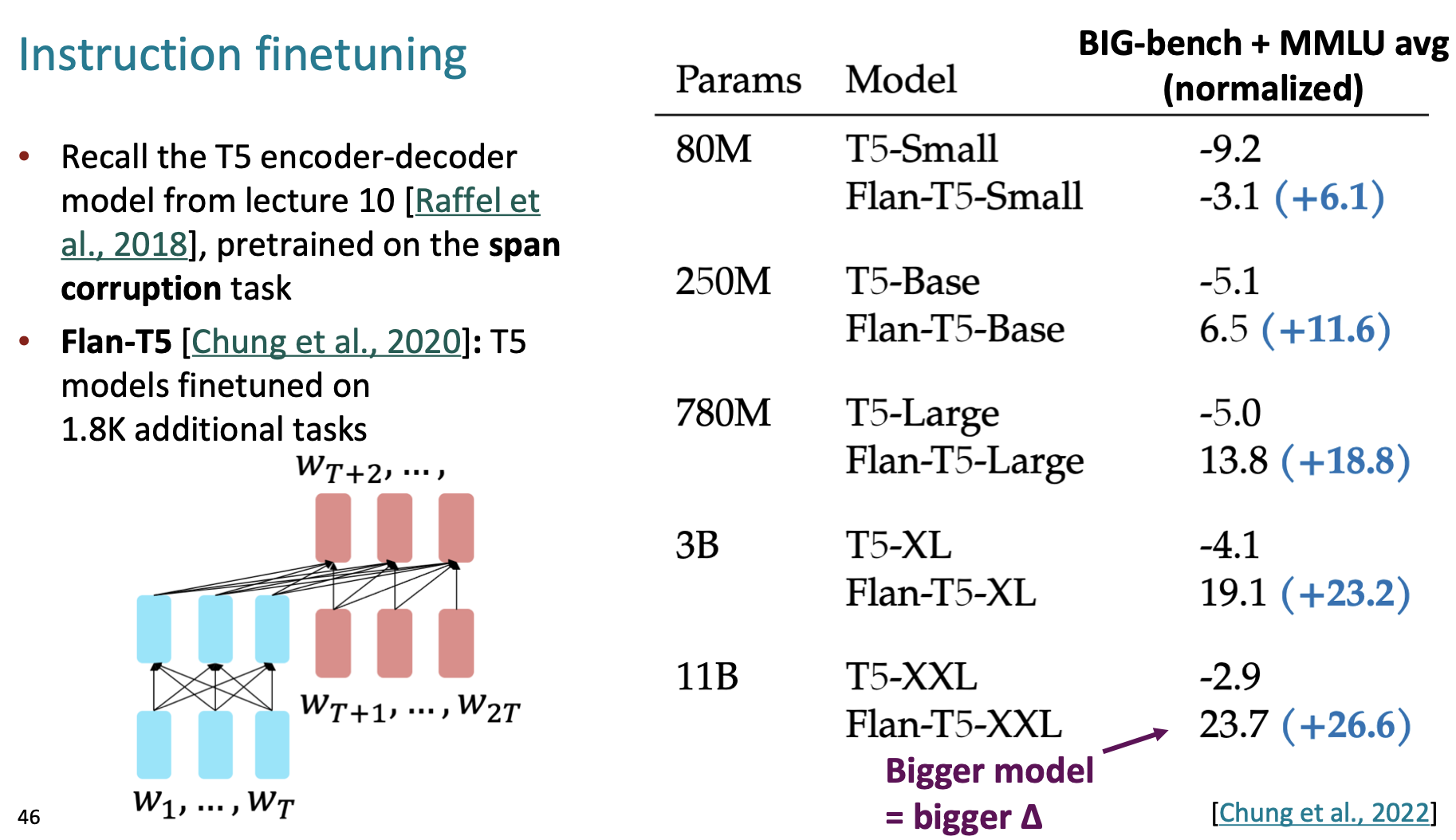
이와 같은 간단하고 직관적인 방법을 통해 꽤 높은 성능 향상을 이끌 수 있습니다.
또한 Adapter를 활용하여 Task별 관련 정보를 유지할 수도 있습니다.
해당 링크를 통해 예시들을 더 볼 수 있습니다. Instruction Tuning with FLAN
하지만 해당 방식 또한 단점이 존재합니다.
- Task가 다양하기에 성능을 측정하는데 소요되는 비용이 상당합니다.
- open-ended 문제에 대한 채점 기준이 애매모호합니다.
- 단어 실수에 따른 완성도의 영향이 단어마다 다르지만 모든 실수가 똑같은 실수로 여겨집니다.
- 여전히 우리가 원하는 만큼의 완성도를 만들지 못합니다.
Instruction finetuning 정리
- 장점
- Simple and straightforward, generalize to unseen tasks
- 단점
- Collecting demonstrations for so many tasks is expensive
- Mismatch between LM objective and human preferences
Mismatch between LM objective and human preferences 해당 단점을 극복하기 위한 솔루션으로 RLHF가 발표됩니다.
이는 이어지는 RLHF 포스팅에서 설명하고자합니다.
