RLHF : Reinforcement Learning from Human Feedback
RLHF Concept
ChatGPT는 이전 포스트에서 소개한 Instruction tuning 기법을 적용한 LM 모델에 Supervised Instruction tuning과 RLHF를 적용하여 만들어진 모델입니다.
해당 챕터에서는 수식적인 부분 보다는 개념위주로 진행하려고 합니다.
먼저 해당 기술이 나오게 된 계기는 조금 더 인간의 취향에 맞는 답변을 얻기 위해서입니다.
예를 들어 요약 Task를 위한 LM을 만든다고 가정을 하겠습니다.
임의의 sample을 inference한 결과에 대한 human reward(사람의 평가)을 얻을 수 있을 때
결과에 대한 expected reward를 최대화 하고자 RL을 사용합니다.
즉, 이름 그대로 HF(Human Feedback = 사람의 평가)를 최대화 하기 위해 RL(강화 학습)을 사용합니다.
RL의 수식적인 내용은 스탠포드 강의 55page에 설명되어 있습니다.
하지만 이를 수행하기에는 두 가지 문제점이 존재합니다.
- human-in-the-loop is expensive
- human judgments are noisy and miscalibrated
먼저 1번부터 살펴보겠습니다.
human reward를 기반으로 학습을 진행하기에 결국 output에 대한 평가를 지속적으로 받아야합니다.
하지만 사람이 매번 참가하는 "human-in-the-loop"의 경우 학습의 비용이 너무 커지게됩니다.
그렇기에 Human Preference(=reward)를 예측하는 LM을 학습하여 사람 대신 평가를 진행합니다.
다음으로 2번 문제입니다.
ChatGPT 기준으로 40여명의 리뷰어가 점수를 매겼다고 합니다.
이러한 경우 리뷰어에 따라 기준이 애매모호 합니다.
그렇기에 모델을 학습할 때에는 점수가 아닌 등수를 매기는 형식으로 진행하였다고 합니다.
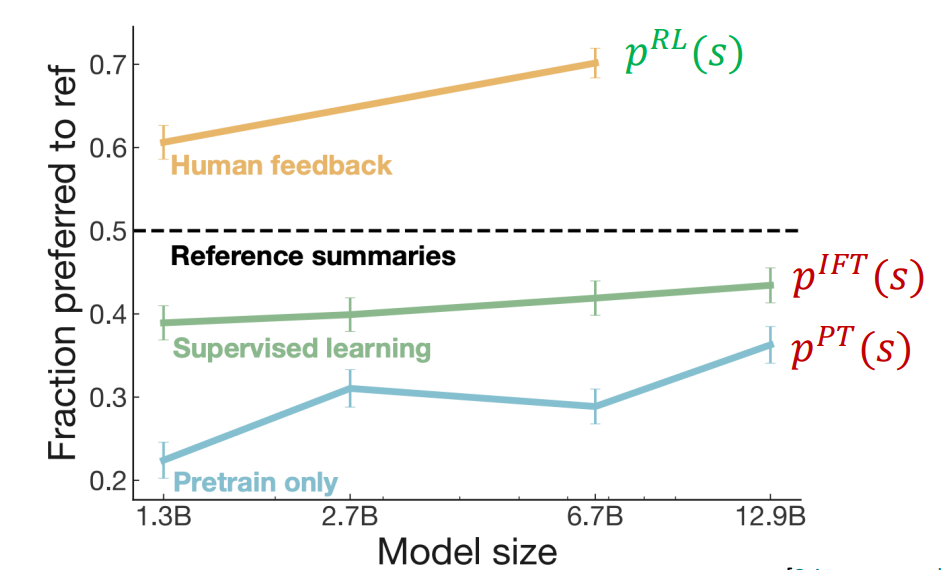
이러한 방식을 통해 성능을 크게 개선했지만 RLHF에도 단점은 존재합니다.
-
Human preferences를 신뢰하기에는 명확하지 않습니다.
1.1 명확하지 않은 보상체계(preference) 때문에 잘못된 방향으로 학습하는 문제(Reward hacking)가 발생할 수 있고 이는 RL에서 흔히 나타나는 문제점입니다.
1.2 챗봇은 진실과 관계없이 그럴 듯한 대답을 생성하기에 hallucinations와 같은 문제점을 야기할 수 있습니다. -
Human preferences를 학습하여 예측하는 모델또한 신뢰하기 힘듭니다.
다음과 같이 차이가 나는 것을 볼 수 있습니다.
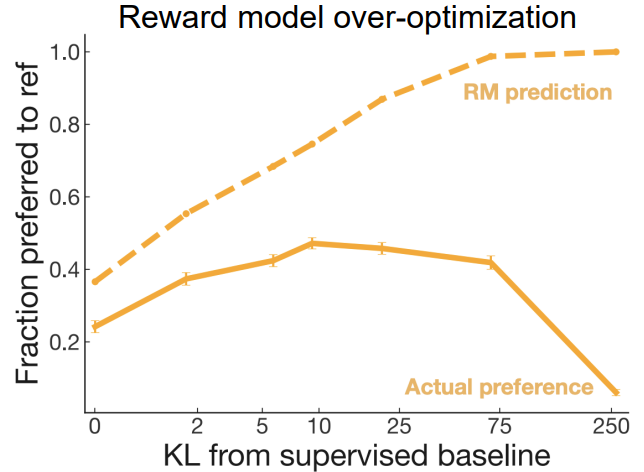
정리하자면, Reward hacking과 명확하지 않은 기준으로 인해 잘못된 방향으로 학습될 수 있다는 단점이 존재합니다.
RLHF는 instruction tuning보다 "alignment" 측면에서 뛰어나며 빠르게 연구되는 분야이기에 이러한 단점을 이겨낼 포텐셜이 존재합니다.
또한 RLHF의 단점인 비싼 데이터 비용의 경우도 "RL from AI feedback [Bai et al., 2022]", Finetuning LMs on their own outputs [Huang et al., 2022; Zelikman etal.,2022]와 같이 활발하게 연구 중입니다.
이는 이후 포스트인 LLM fine-tuning에서 다룰 예정입니다.
하지만 LM의 근본적인 문제인 Size, hallucination을 아직까지는 개선할 수는 없는 한계점 또한 존재합니다.
How?
그렇다면 RLHF를 어떻게 적용하는걸까요?
OpenAI 블로그에서 소개한 ChatGPT에 적용된 RLHF입니다.
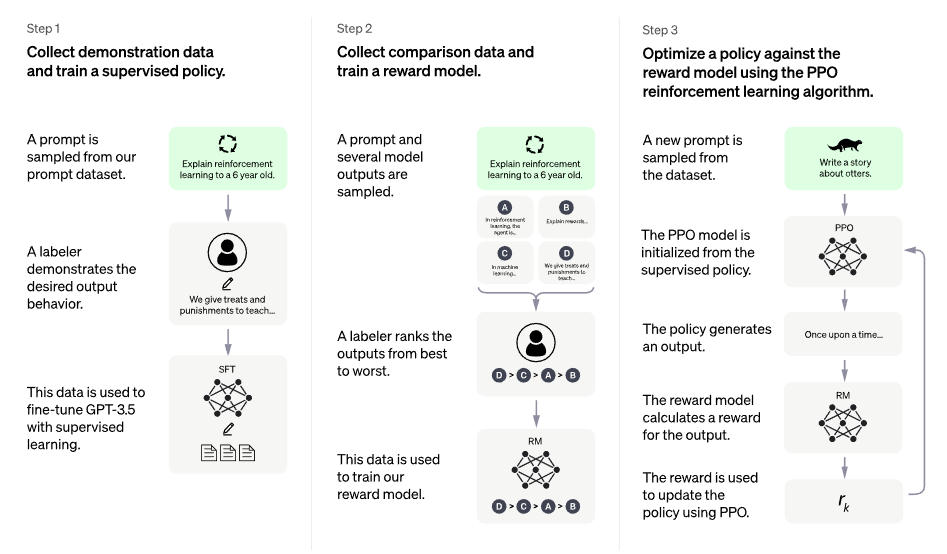
이는 위 그림과 같이 3 step으로 구성되었습니다.
발췌 : ChatGPT에 적용된 RLHF(인간 피드백 기반 강화학습)의 원리
1. Supervised Learning
원하는 의도와 맞게 학습을 진행하기 위해 데이터셋에서 적합한 데이터를 추출 후 Pre-trained LM에 지도 학습을 진행합니다.(Supervised Instruction Tuning)
학습을 위한 데이터셋을 수집하기 위해 다음과 같은 방법을 사용했습니다.
1) Labler or 개발자가 준비한 프롬프트와 직접 기록한 예상 답변
2) OpenAI API를 통해 문의한 프롬프트
해당 방법을 통해 데이터의 양은 적지만(12~15K) 고품질의 데이터 셋을 얻을 수 있었습니다.
이렇게 얻은 데이터셋을 통해 GPT 3.5 모델을 학습하였습니다.
2. Reward Model
학습된 모델이 생성한 여러 답변의 랭킹을 매기고 이를 기반으로 강화학습 모델(RM)을 학습합니다.
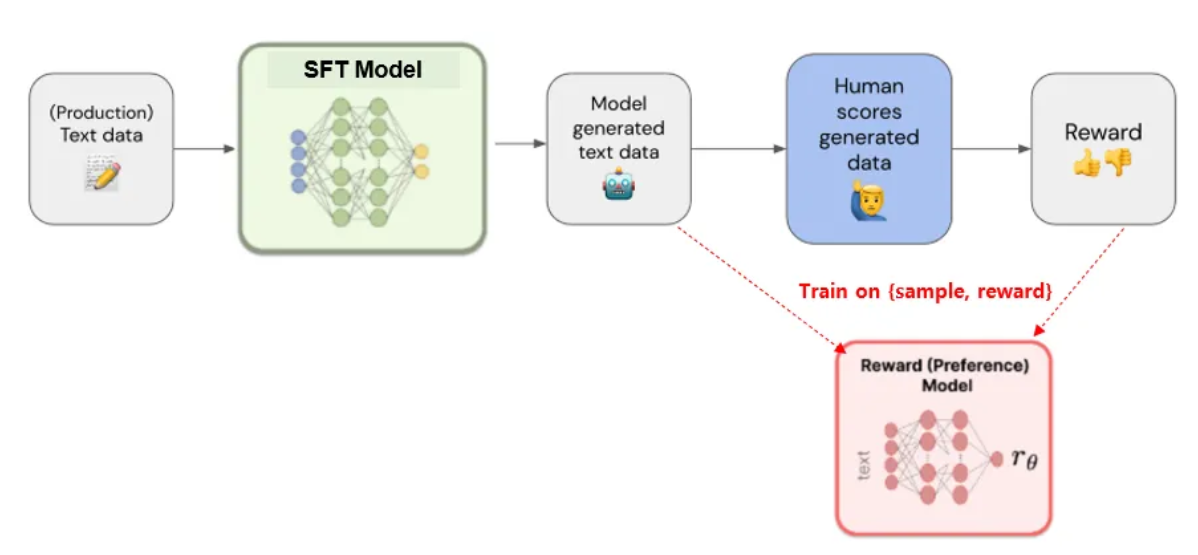
이 때 모델은 (text, reward) 쌍으로 학습이 진행됩니다.
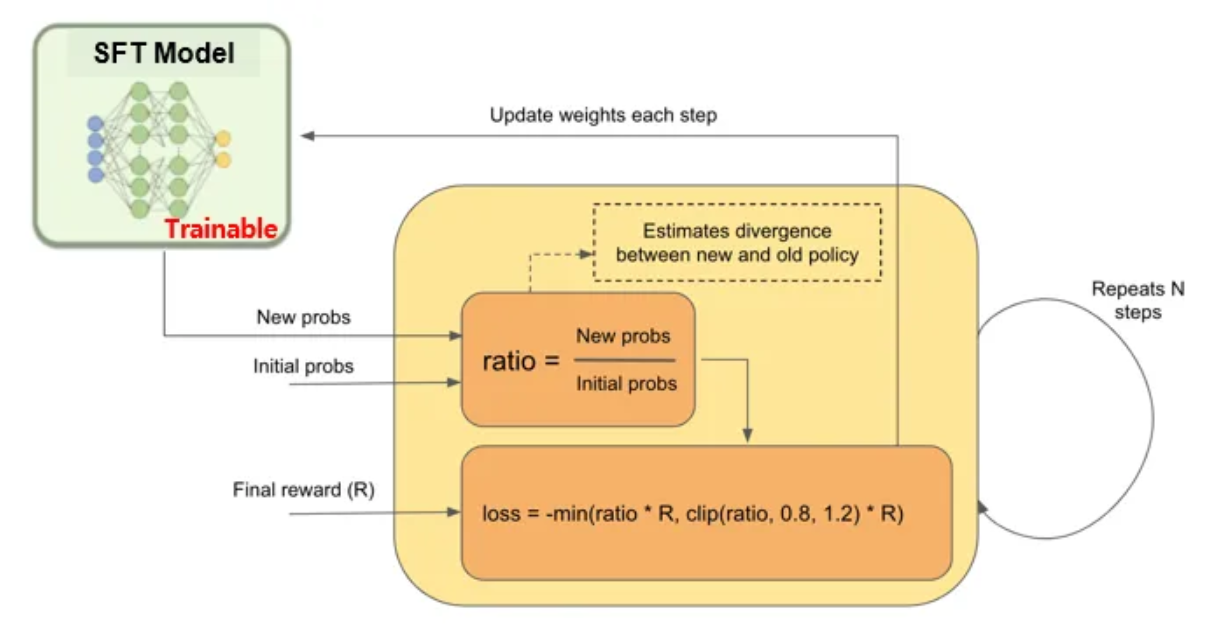
3. Reinforcement learning(PPO)
모델과 RM을 함께 상호 작용하며 강화학습을 진행합니다.
해당 단계에서는 앞서 학습한 RM 모델의 reward를 통해 Model을 학습합니다.
- 학습 모델의 copy 모델에 weight를 freeze하여 준비한다.
- Frozen 모델과 학습 모델의 출력(text)간 KL divergence(출력 확률 차이)를 계산한다.
- 앞서 얻은 KL divergence와 RM 모델의 reward를 합쳐 Final reward를 생성한다.
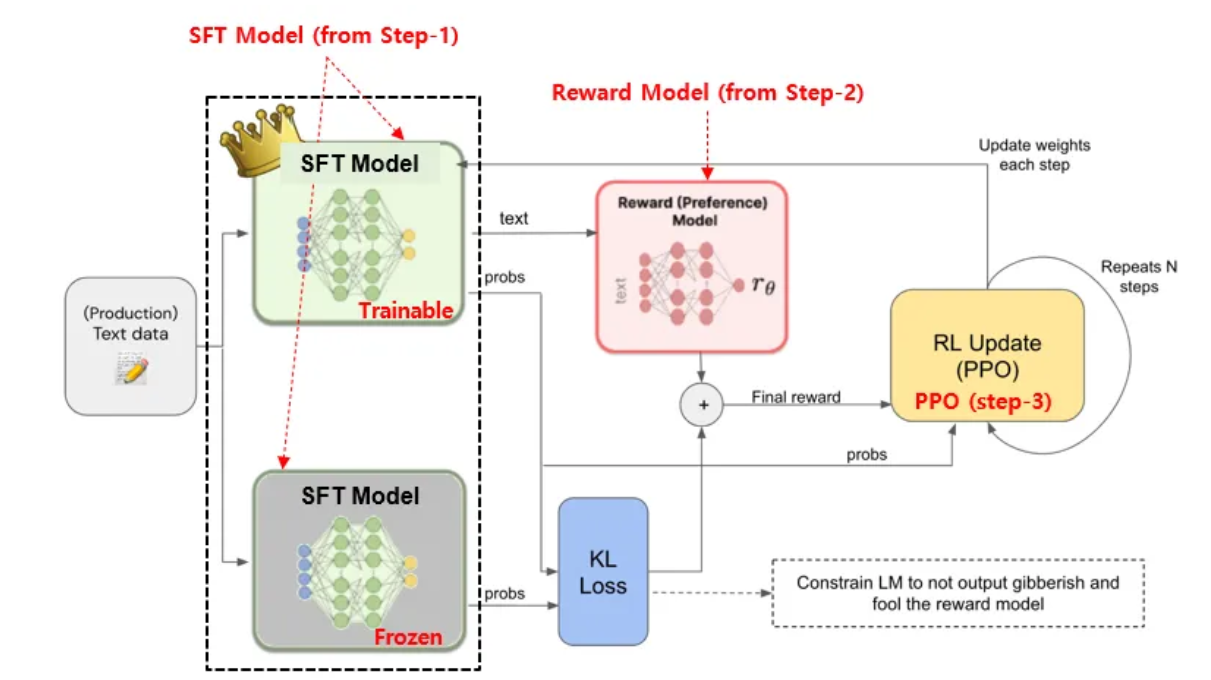
이후 PPO 알고리즘에 따라 loss를 계산하여 모델 weight를 업데이트 합니다.