해당 논문 리뷰를 읽기 전 이전에 작성한 LoRA와 QLoRA 리뷰를 읽어보는 것을 추천드립니다.
해당 논문은 QLoRA와 같이 LoRA와 양자화를 함께 사용하는 방법을 제시합니다.
또한 기존의 LoRA의 weight 초기화를 통해 양자화로 인해 잃은 정보를 보안하는 방안을 제시합니다.
이는 기존의 양자화 방식을 통해 multi-task learning을 진행했을 때 양자화로 인한 정보 손실이 누적되는 문제점을 해결할 수 있는 포텐셜이 있다고 생각됩니다.
LoftQ
Abstract
양자화는 LLM serving에 필수인 기술이며, 최근에는 LoRA와 함께 사용되고 있습니다.
해당 논문에서는 양자화와 LoRA를 함께 사용하여 학습하는 시나리오에 초점을 맞췄습니다.
저자는 LoftQ라는 새로운 양자화 framework를 제안하였고 이는 LLM을 양자화하면서 적절한 low-rank initialization을 찾아줍니다.
이러한 초기화를 통해 양자화된 모델과 full-precision 모델의 discrepancy를 완화하며 downstream tasks의 일반화에 도움을 줍니다.
해당 논문의 실험을 통해 기존 양자화 기법보다 2-bit와 2/4-bit mixed precision에서의 뛰어난 성능을 보여줍니다.
Introduction
Pre-trained Language Models(PLMs)의 도래는 다양한 applications에 다용도 솔루션이 되며 NLP 필드에 큰 변화를 일으켰습니다.
이러한 모델들은 전형적으로 수백만 혹은 수십억의 파라미터를 가지고 있는데 이는 비싼 계산비용과 메모리를 요구하게 됩니다.
이러한 요구사항을 완화하기 위해 양자화는 중추적인 압축 테크닉으로 사용됩니다.
특히 16-bit format으로 저장된 모델을 4-bit integer format으로 양자화 했을 때 75%의 storage overhead를 줄이는 결과를 보였습니다.
또한 LoRA는 기학습된 모델이 downstream tasks에 효율적으로 작동하도록 하는 viable approach입니다.
pre-trained models을 양자화할 때 사람들은 양자화 기법에 집중하여 의도치 않게 LoRA fine-tuning의 중요성을 간과하는 경우가 있습니다.
예로, QLoRA는 LoRA에서 사용된 fixup initialization을 계승합니다.
(attached zero initialized low-rank adapters)
이러한 불일치(fixup initialization을 통한 초기화)는 특히 저비트 상황에 악영향을 끼칩니다.
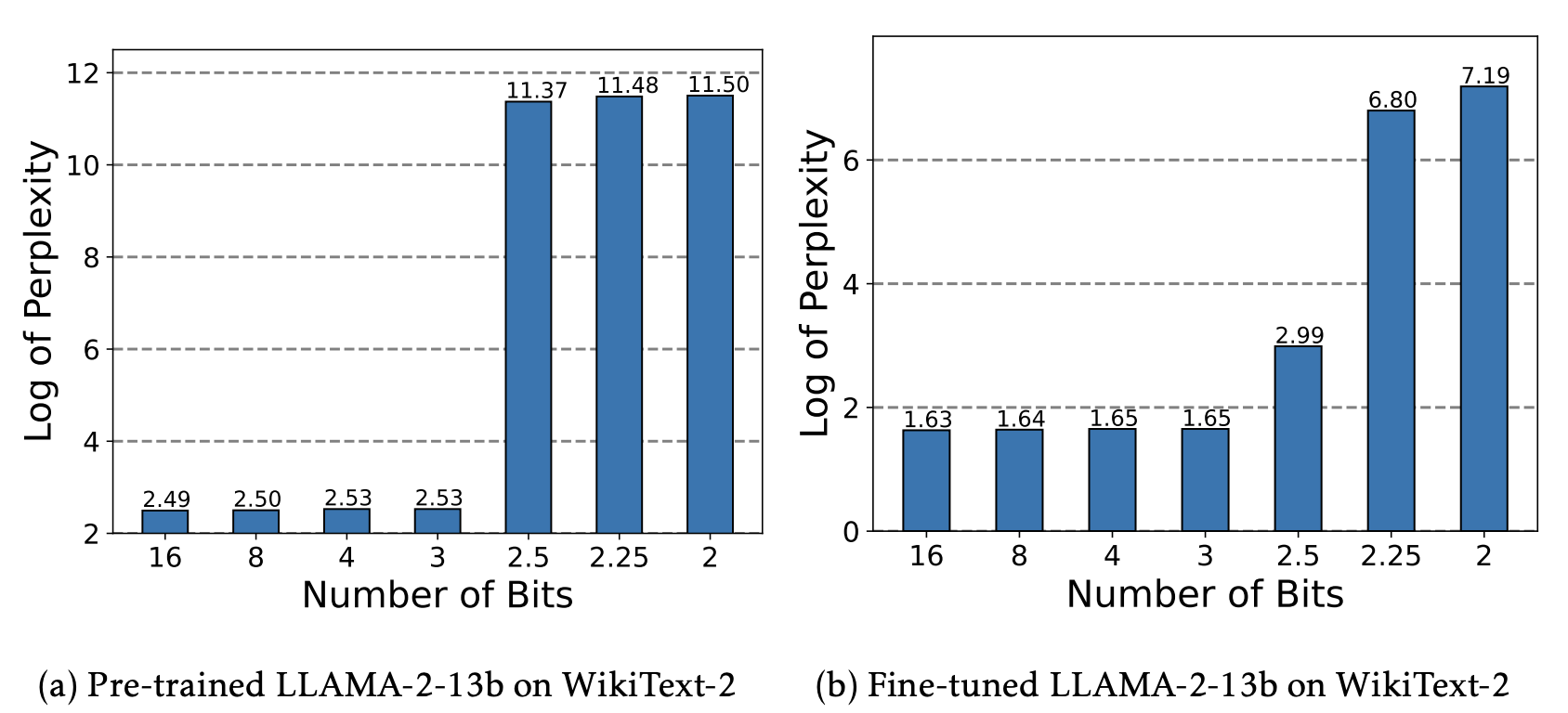
- (a) QLoRA를 통해 초기화할 경우, Bits가 낮아질 때 PPL이 높아지는 것을 확인할 수 있습니다.
- (b) QLoRA를 통해 학습할 경우, Bits가 낮아질 때 PPL이 높아지는 것을 확인할 수 있습니다.
해당 논문에서는 새로운 양자화 framework인 LoRA-Fine-Tuning-aware Quantization (LoftQ)를 소개합니다.
해당 프레임워크는 low-rank 근사를 actively하게 결합함과 같이 양자화를 진행합니다.
이 시너지는 아래 표와 같이 원본 pre-trained 모델의 weights와의 alignment를 크게 향상시킨다.
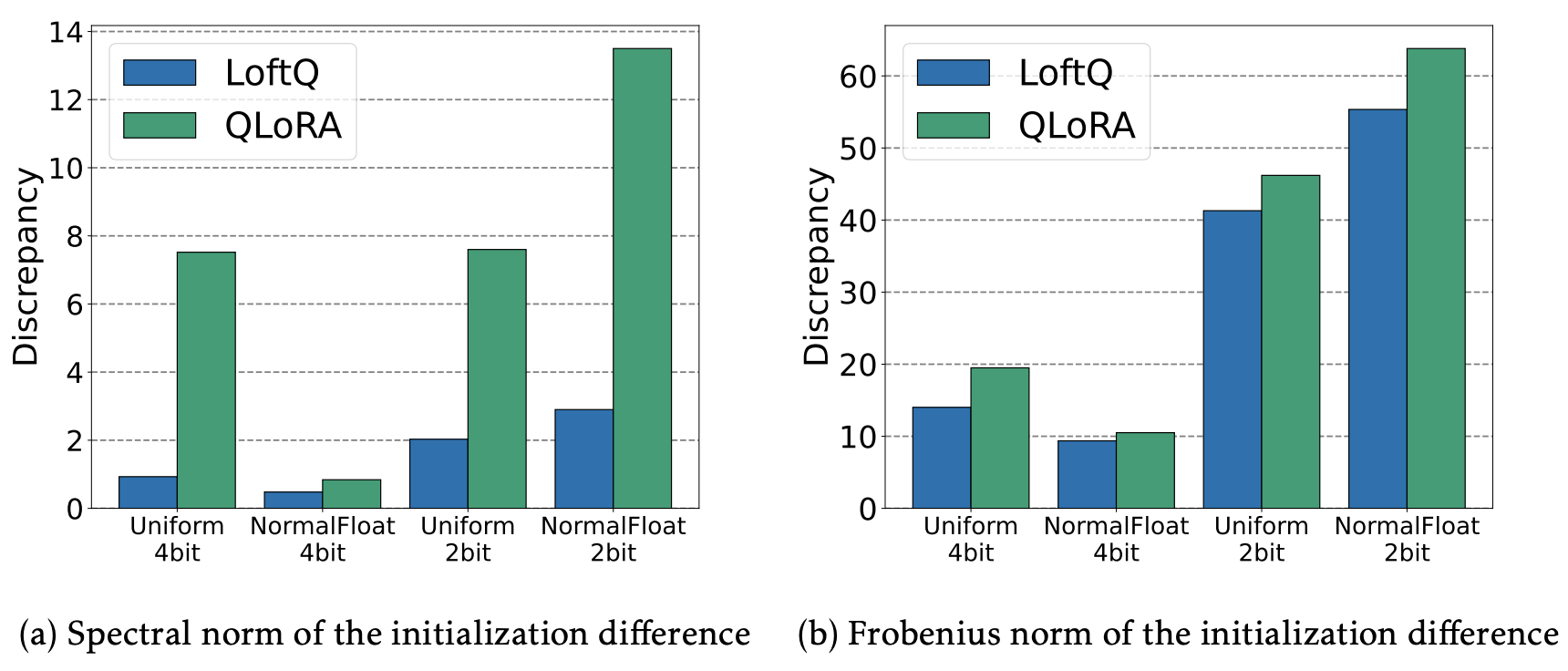
결과적으로, LoftQ는(초기화 기법) LoRA fine-tuning에 유리한 초기화 포인트를 주며 이는 downstream-tasks 성능 향상에 도움이 된다.
Method
저자는 original pretrained weights를 양자화와 low-rank approximation를 교대로 적용하여 근사합니다.
LoftQ는 quantization discrepancy in QLoRA를 완화하며 downstream task의 일반화를 향상하는 promising initialization을 제공한다.
LoRA-Aware Quantization

objective(6)을 풀어서 설명하면 다음과 같이 나타낼 수 있다.
1. : original high-precision weight인 와 의 차이를 구한다. 즉 양자화된 weight에 LoRA 어뎁터를 추가한 것과 원본의 차이를 구한다.
2. : 원본과의 차이를 Frobenious norm으로 구하고 이를 최소화 한다.
즉, 원본 weight를 로 근사하고자 한다. 이를 통해 quantization discrepancy에 의한 downstrem task의 성능 하락을 막고자 한다.
Alternation Optimization
앞서 (6)에서 언급한 최소화를 SVD를 통해 해결하고자 한다.
양자화를 진행하면 필연적으로 정보를 잃어버릴 수 밖에 없다.
해당 알고리즘은 정보를 잃어버리는 것을 최소화하는 방향으로 LoRA의 weight를 초기화하고자 한다.
즉, 기존의 LoRA 초기화의 경우 A는 랜덤 가우시안 분포 B는 0으로 초기화하는데 이가 아닌 양자화의 정보손실을 최소화하는 방향으로 LoRA를 초기화하고자 하는 것이다.

해당 알고리즘을 처음 실행하면 SVD()는 원본 weight와 양자화된 weight의 차의 특이 벡터와 특이값을 얻을 수 있다.
즉, 원본 weight에서 양자화를 진행하며 잃은 정보의 특징을 추출한다.
이후 알고리즘을 반복하며 양자화를 진행하며 잃은 정보의 중요한 특징을 근사하는 LoRA weight를 정한다.
이를 통해 가 를 근사하여 (6)에서 언급한 최소화를 달성한다.
여기서 주목할 것은 가 1일 때이다.
이 때 은 QLoRA를 통해 얻은 quanitzed weight이며 LoRA weight인 은 의 잔차에 SVD를 적용해서 얻은 값이다.
해당 알고리즘은 가 1일때도 잘 작동한다.
LoftQ의 computational cost또한 개별 weight에 병렬 적용할 수 있기에 크지 않다.
또한 다른 task를 학습할 때도 한번 LoftQ 알고리즘을 적용한 모델을 재사용할 수 있다.
저자는 가 exact solution은 아니지만 효율적인 근사를 한다고 말한다.
Experiments
저자들은 LoftQ를 NLU와 NLG task를 통해 평가했다.
DeBERTaV3-base, BART-large, LLAMA-2 모델을 사용했다.
Implementation Details
저자는 Adaptive budget allocation for parameter-efficient fine-tuning 논문의 방식대로 모든 backbone weight를 freeze하고 모든 MHA와 FFN layer에 low-rank adapter를 추가했다. 또한 추가한 low-rank adapters또한 양자화 하였다.
Quantization Methods
저자는 Uniform quantization와 NF4, NF2를 사용했다.
저자는 2-bit, 4-bit 양자화를 통해 25-30%, 15-20%의 compression ratios를 달성했다.
Baseline
- Full fine-tuning
- Full precision LoRA
- QLoRA
Decoder-only Model: LLAMA-2
LoftQ는 DeBERTaV3-base, BART-large에서 QLoRA를 상회하는 성능을 보여준다.
특히 LLAMA-2에서 QLoRA는 2-bit precision에서 수렴을 실패하는 모습을 보이는 반면 LoftQ는 수렴을 성공하는 모습을 보여준다.
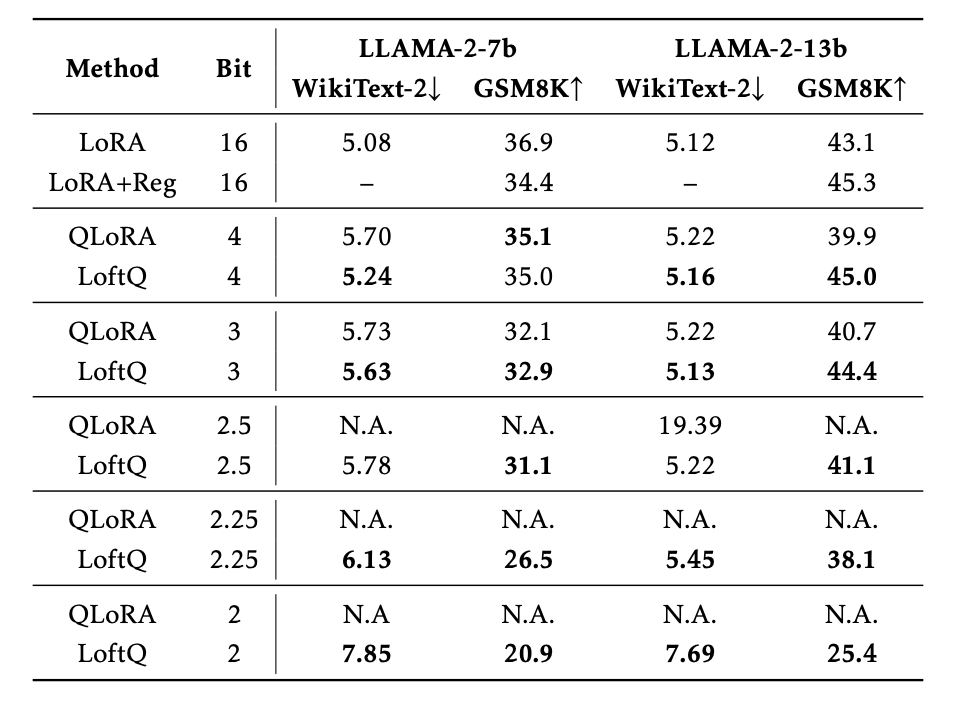
학습 후 PPL 측정
저자들은 GSM8K에서 full-precision LoRA보다 LoftQ의 성능이 높은 것을 확인하고 이를 regularization의 부재로 인한 overfitting의 가능성을 제시한다.
그렇기에 weight decay를 추가하며, 이는 양자화가 overfitting을 방지하는 implicit regularization을 수행했다고 말한다.
또한 mixed-precision quantization을 사용하여, 처음 4 layers에는 4 bits 양자화를 진행하고 다른 matrices에는 2 bits 양자화를 진행했을 때 5.9%의 accuracy가 GSM8K dataset에서 증가했다.
이는 mixed-precision에서의 LoftQ의 잠재력을 보여준다고 말한다.
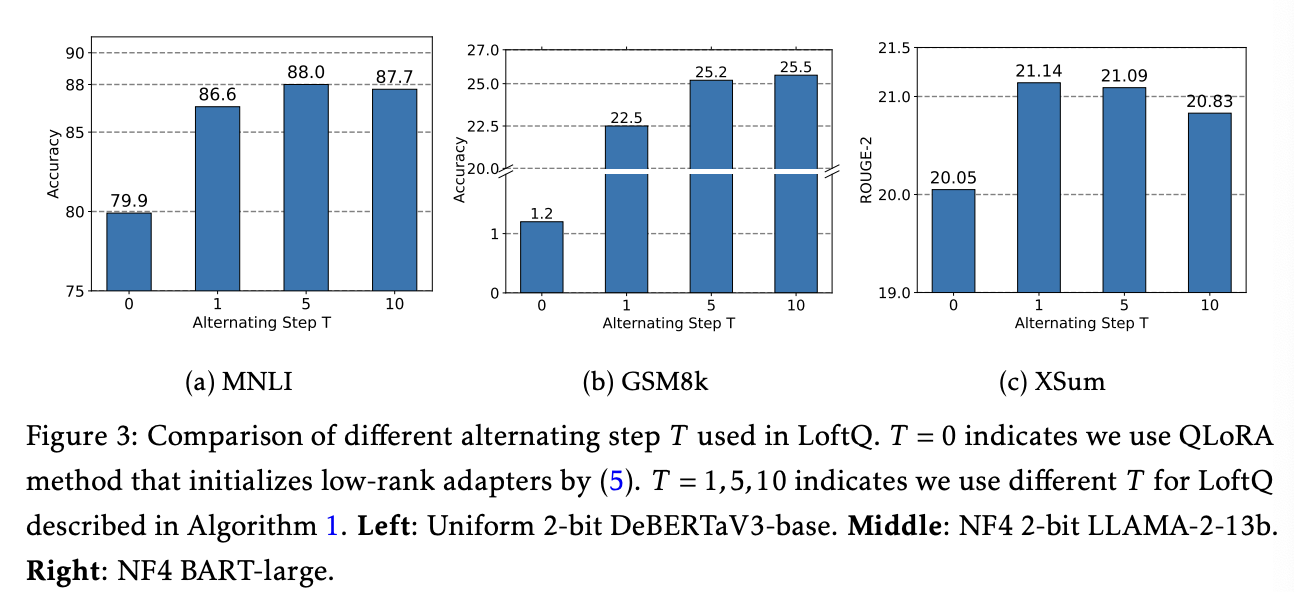
또한 의 step이 적어도 상당한 성능 향상을 나타냈으며, 이는 양자화된 weights와 pre-trained weight의 discrepancy를 빠르게 줄일 수 있기에 LoftQ를 쉽게 적용할 수 있다고 한다.
또한 특정 step 이상을 적용할 때 성능이 떨어지는 경향이 있는데 이는 gap이 줄어들며 매 스텝에서 gap을 최소한의 상태로 유지하기 어렵기 때문이라고 한다. 이는 양자화 방식에 내재된 문제로 인해 발생한다고 말한다.
그럼에도 step T에 대해 민감하게 작동하지는 않는다고 말한다.