MLOps란
프로젝트를 진행하다보면 Validation Dataset에서는 잘 작동되던 모델이 실제 환경에서는 좋은 성능을 내지 못하는 경우를 마주하게됩니다.
이를 해결하기 위해 2,3번째로 성능이 좋았던 모델을 사용하고자 하면 재현 및 테스트에 오랜 시간이 걸리곤 합니다.
또한 여러명이 함께하는 프로젝트에서 데이터의 버전 및 모델 버전, 개발 환경등을 통일해야합니다.
그렇기에 일반적인 프로젝트 순서인 데이터 준비, 모델 구현, 모델 배포의 사이에는 많은 디테일이 필요합니다.
그렇기에 기존 DevOps의 Ops를 ML에 차용하여 MLOps의 개념이 도입되었습니다.
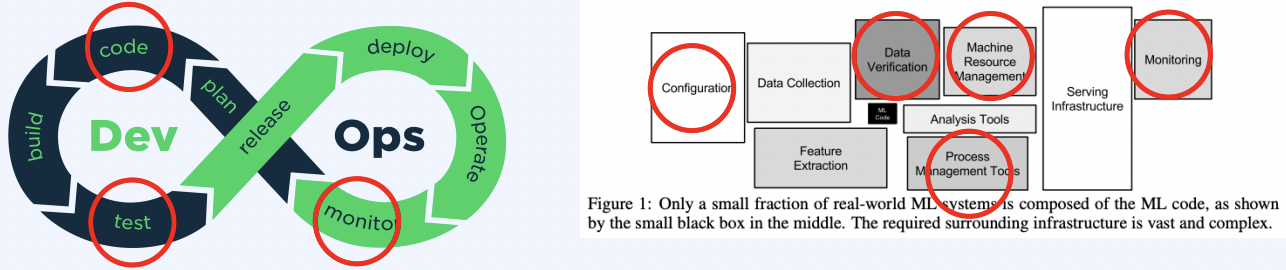
정리하자면
MLOps란 "ML을 효율적으로 개발하고 성공적으로 서비스화하고 운영할 때 필요한 모든 것을 다루는 분야"입니다.
그렇기에 이를 데이터,모델,서빙으로 나누면 다음과 같은 요소들이 필요합니다.
| 데이터 | |
|---|---|
| 데이터 수집 파이프라인 | Sqoop,Flume,Airflow |
| 데이터 저장 | MySQL,Hadoop |
| 데이터 관리 | TFDV,DVC,Feast |
| 모델 | |
|---|---|
| 모델 개발 | Jupyter Hub,Docker,Kubeflow |
| 데이터 저장 | Git,Mlflow,jenkins |
| 데이터 관리 | Grafana,Kubernetes |
| 서빙 | |
|---|---|
| 모델 패키징 | Docker,Flask,FastAPI,Kubeflow |
| 서빙 모니터링 | Prometheus,Grafana |
| 파이프라인 매니징 | Kubeflow,Airflow |
이를 전체적으로 할 수 있는 AWS SageMaker,GCP Vertex AI, Azure Machine Learning 등이 존재합니다.
이처럼 다양한 요소를 만족하기 위해서는 다양한 툴을 공부해야합니다.
그렇기에 해당 시리즈에서는 이에 대해 알아보고자 합니다.

AI 새싹