생성모델이란?
생성모델 : 입력 받은 데이터와 유사한 분포를 따르는 새로운 데이터를 생성하는 모델
생성모델의 학습 또한 모델이 주어진 '데이터의 분포'를 얼마나 잘 학습 하는지를 고려합니다.
생성모델은 많은 사람들에게 활발하게 연구되고 있는 분야입니다.
Variational Auto Encoder(VAE) 부터 Generative AdversarialNetwork(GAN), Flow Model, Diffusion Model 등, 다양한 연구가 이루어지고 있습니다.
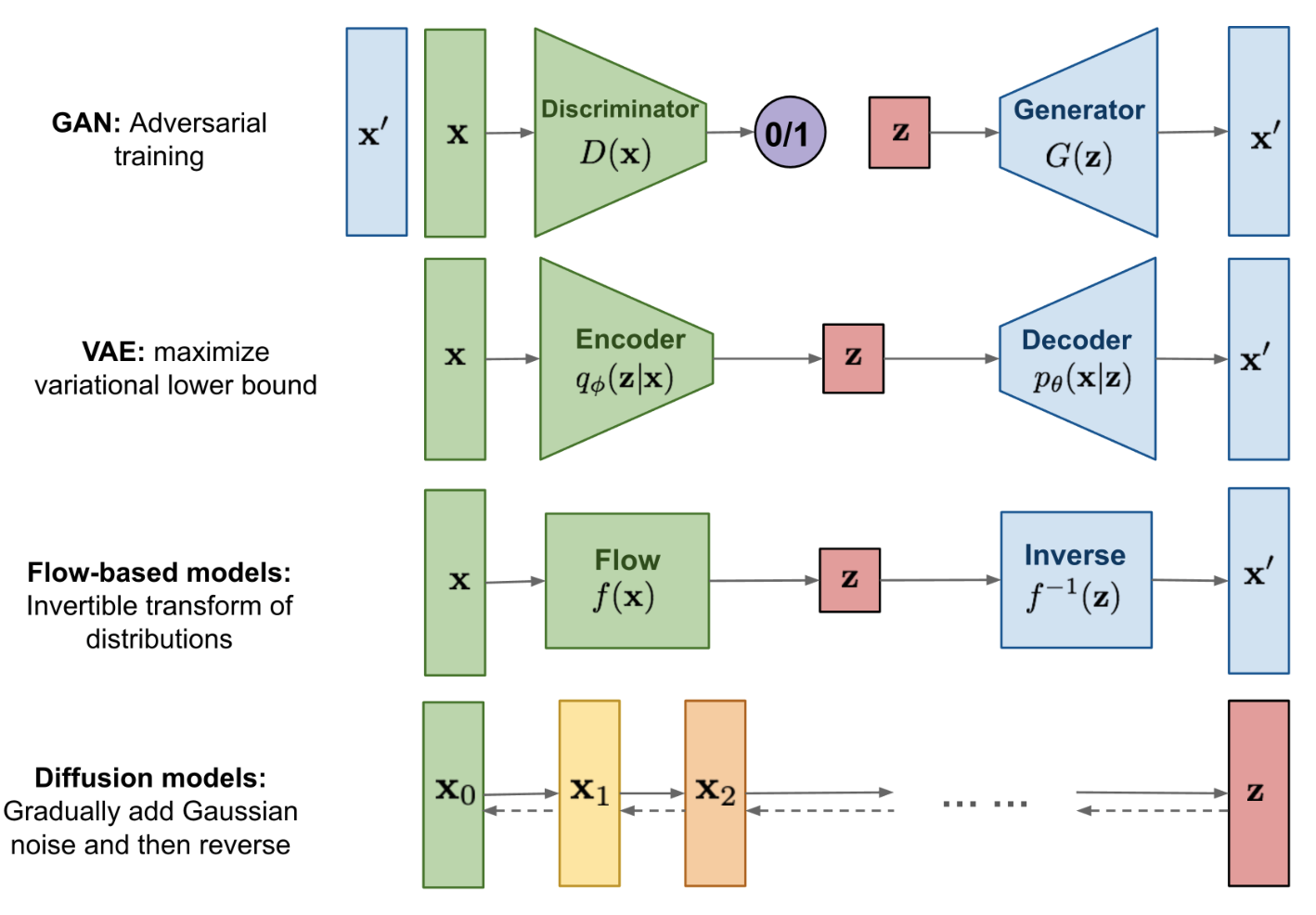
VAE
VAE : 우리가 쉽게 알기 어려운 사후확률(Posterior)분포 를 다루기 쉬운 분포로 근사하는 변분법적 추론(Variatinal Inference)을 활용한 딥러닝 생성 모델
- 변분법 : 범함수(함수를 입력으로 받아 스칼라를 내어놓는 함수)의 최소,최대를 찾는 방법
VAE는 Encoder, Decoder 두 부분으로 구성되었습니다 - Encoder는 입력 데이터 를 요약하여 잠재변수(Latent Variable) 를 만들어내는 역할을 합니다.
- Decoder는 잠재변수 를 다시 최대한 유사하게 로 복원하는 역할을 합니다.
즉 를 정확하게 알 수 없다면, 이미 우리가 잘 알고 있으면서, 다루기 쉬운 분포 중 최대한 비슷한 분포를 찾아내어 이를 활용하는 방식을 택한 것이 VAE의 핵심 아이디어입니다.
수식에 관한 부분은 정보량부터 VAE에 설명되어있기에 의미위주로 알아보겠습니다.
먼저 를 대신하여 를 구하게됩니다. 이 때 는 학습을 통해 얻는 최적의 파라미터 입니다.
이는 다음과 같은 과정을 통해 이루어집니다. =
즉 두 분포간의 차이를 좁히는 방향으로 학습이 진행됩니다.
이를 최소화하기 위해 ELBO의 값을 최대로하는 방향(KL Divergence를 최소로)으로 학습을 진행합니다.
VAE는 탄탄한 수학적 배경을 가지고 있기에 안정적인 학습이 가능하지만 다양한 가정을 바탕으로 생성이 이루어지는 만큼 그 결과물이 흐릿하다는 단점을 가지고 있습니다.
GAN
발췌 : 유재준 교수님 블로그
VAE가 Explicit density의 가지에서 뻗어나왔다면, GAN은 Implicite density 가지에서 뻗어나왔습니다.
- Implicite density : 간접적인 방식
- 어떤 model에 대해 틀을 명확히 정의하는 대신 확률 분포를 알기 위해 sample을 뽑는 방법
- 예시 Markov Chain 사용하는 방법, GAN
- GAN
- 확률 모델을 명확히 정의하지 않아도 모델 자체가 만드는 분포로 부터 sample을 생성할 수 있으며 MCMC와 달리 별다른 input 없이 한 번에 sample을 만들 수 있다.
- Explicit density : 와 같이 model을 명확히 정의하여 이를 최대화
- 예시 Monte Carlo 근사
- model을 정의했기에 다루기가 비로적 편하고 모델의 움직임 예측이 가능하지만 우리가 아는 것 이상으로는 결과를 낼 수 없다.
GAN은 VAE의 Normal Distribution과 같은 가정이 포함되지 않기에 유연한 데이터 분포를 학습 가능하다.
VAE에게 Encoder와 Decoder가 있다면 GAN은 생성자 G와 식별자 D가 존재한다.
- 식별자
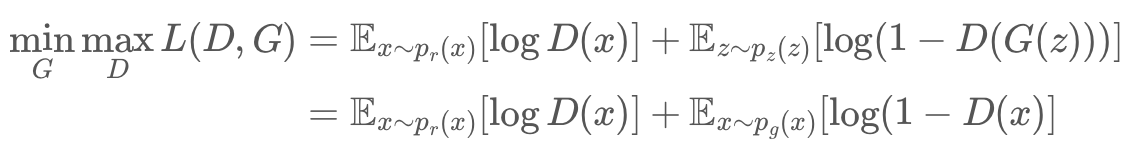
- 위의 식에서 는 원본 데이터 는 생성자에 대한 input으로 가짜 데이터를 만들기 위한 데이터이다.
- 가 입력되면 높은 확률 -> 를 높임
- 가 입력되면 낮은 확률 -> 를 낮춘다. -> 높이는 방향
- 생성자
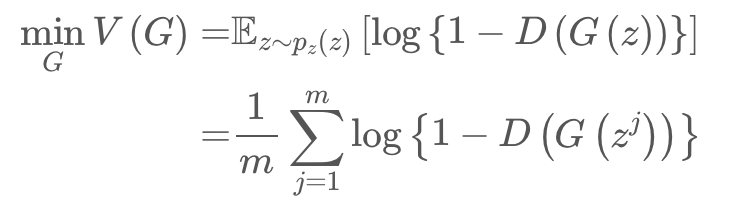
- 가짜 데이터 를 에 넣었을 때, 실제 데이터처럼 확률이 높게 나오도록 를 높임 -> 를 낮추는 방향
이러한 방식을 통해 학습되는 GAN은 결과물의 퀄리티가 보장되지 않습니다.
Generator와 Discriminator의 균형있는 학습이 어렵고 다양한 생성물이 나오는 것이 아닌 D를 잘 속일 수 있는 한가지 생성물만 반복적으로 만들어 내는 등(collapse) 학습 난이도가 높다.
정리
딥러닝 생성 모델은 주어진 '데이터 분포'를 학습하는 모델이다.
