Diffusion
딥러닝의 급속한 발전과 함께 VAE, GAN, Flow Based 모델과 같이, Diffusion Model 이전에도 좋은 성능을 보여준 생성모델들이 기존에 존재하였습니다.
기존의 생성모델과 Diffusion의 차이점은 다음과 같습니다.
1. 기존의 생성모델보다 훨씬 더 사실적이면서 정교한 이미지를 생성해 준다.
2. 텍스트를 이미지로 즉각 변환해 주는 것과 같이 다양한 영역(Domain)의 입력값을 받아 이를 바탕으로 이미지를 생성해준다.
3. GAN에 비하여 학습 및 생성에 안정적인 모습을 보여준다.
Diffusion 이란?
Diffusion(확산) 현상이 어떻게 진행될지 예측하는 것은 매우 어렵다.
그렇기에 이를 정확하게 예측하기 보다 확률적으로 예측하고자 하는 방법들이 고안되었다.
이렇게 확산의 형태를 확률적으로 예측하고자 하는 기존의 방법을 활용한 것이 Diffusion Model이다.
매우 어질러진 방을 깨긋한 방으로 되돌리는 과정을 생각할 때 방청소의 목표는 어질러진 방(Noise 주입 및 확산이 많이 이루어진 상태)를 우리가 원하는 깨끗한(Noise가 주입되기 전 혹은 확산이 이루어지기 전 상태)로 되돌리는 것이다.
하지만 최대한 비슷하게 방을 처음의 상태로 되돌려 놓고자 하더라도, 과거의 방과 완전히 똑같이 돌리는 것은 사실상 불가능하다.
Diffusion Model은 오히려 이러한 미세한 차이로 인하여 기존에 존재하지 않은 새로운 이미지 데이터를 만들어 낼 수 있다.
또한 방이 한번에 치워지지 않고 여러번 손을 거친 끝에 깨끗해지듯, Diffusion Model 역시 여러번의 반복적인 작업을 통해 이루어진다.
"반복적인 단순 작업을 통하여 어지럽혀진 방을 깨끗하게 치운다"
Diffusion 모델의 두가지 가정
- 이산 마코프 가정(Discrete Markov Process Assumption)
- 정규분포(Normal Distribution)
Discrete Markov Process Assumption
- Markov : "특정 상태의 확률은 오직 현재()의 상태에 의존한다"
- 이산 확률과정 : 이산적인 시간(0초,1초,2초,...) 속에서의 확률적 현상
정규 분포
'특정 데이터가 정규분포를 따를 것이다' 라는 정규성 가정을 사용하는 이유는 이미 특성을 잘 이해하고 있는 가장 대표적인 분포인 정규분포만을 고려한다면 풀어야 하는 문제가 간단 명료해지기 때문이다.
정규분포 그래프는 평균과 표준편차()라는 두가지 모수에 의해 결정되는 정규분포 그래프로서 Diffusion Model에서는 각 확률 단계가 다음과 같이 Normal Distribution을 따를 것이라고 가정
두 가정을 결합
이미지의 경우 단순한 정규분포 형태로 데이터의 분포를 나타내기에는 부족하다.
하지만 이러한 단순한 형태의 정규분포라도 이를 깊은 층으로 쌓아올린다면 이미지와 같은 복잡한 데이터의 분포를 잘 표현 할 수 있다.
이러한 점을 이용하여 간단한 분포를 단계별로 활용하여 점차 복잡한 데이터를 표현하는 것이 Diffusion Model의 핵심이다.
특히 Markov 가정을 통하여 많은 단계를 동시에 고려하는 것이 아니라 이전단계의 분포 만을 단계적으로 차근차근 고려해가며 복잡한 분포를 쌓아 올리기 때문에, 어려운 문제를 보다 쉬운 여러개의 문제로 분할하여 풀 수 있다.
그렇기에 각 단계에서는 정규 분포의 평균과 분산, 즉 두가지 특성(모수)를 맞춰야 한다.
Forward Process, Reverse Process
방을 잘 치우게 하기위해 단순한 방법인 일부로 어지럽힌 다음 어지러진 방을 치우고, 다시 어지럽히고 치우는 과정을 반복합니다.
Diffusion Model의 관점에서는 이러한 행위는 다음과 같습니다.
방을 일부로 어지럽힌다 -> 데이터에 노이즈를 주입 -> Forward Process
방을 치운다 -> 데이터에서 노이즈를 제거한다 -> Reverse Process

위의 사진은 사진은 실제 고양이 이미지에 Diffusion Model의 Forward, Reverse Process를 적용한 예시입니다.
이러한 과정을 통해 Diffusion Model은 고양이이의 이미지의 개념(데이터 분포)를 깨달아 가는 것입니다.
Forward Process
Forward Process는 임의의 노이즈를 주입하여 데이터를 어지럽히는 과정입니다.
이러한 노이즈는 Diffusion Model의 큰 두가지 가정 중, 정규성 가정에 따라 정규분포 형태를 따르는 임의의 Gaussian Noise가 주입됩니다.
Gaussian Noise가 한,두 차례 주입될 때 까지는 원래 데이터의 형태를 보존하지만 이것이 반복되어 주입된다면 점차 그 형태를 알아 볼 수 없게됩니다.
이렇게 단계별로 Gaussian Noise를 주입하는 것이 Diffusion Model의 Forward Process입니다.
이렇게 이전 단계(t-1)에서 다음단계(t)로 노이즈가 주입되며 변화되는 과정은 다음과 같습니다.
위의 수식에서 유의해서 살펴보아야 할 부분은 조건부 확률분포를 나타내고 있다는 점입니다.
Gaussian 가정은 한가지 확률 변수에 대한 가정이 아니라 이전단계의 확률분포와 함께 고려되었을 때 의미가 있는 조건부 정규분포 가정(Conditional Gaussian Distribution)이라는 점이다.
Reverse Process
Reverse Process는 아래의 그림과 같이 주입된 노이즈를 되돌리는 과정입니다.
앞선 설명과 같이 오차 없이 원래상태로 방을 되돌리는 것은 불가능합니다.
노이즈가 주입된 데이터도 마찬가지입니다.
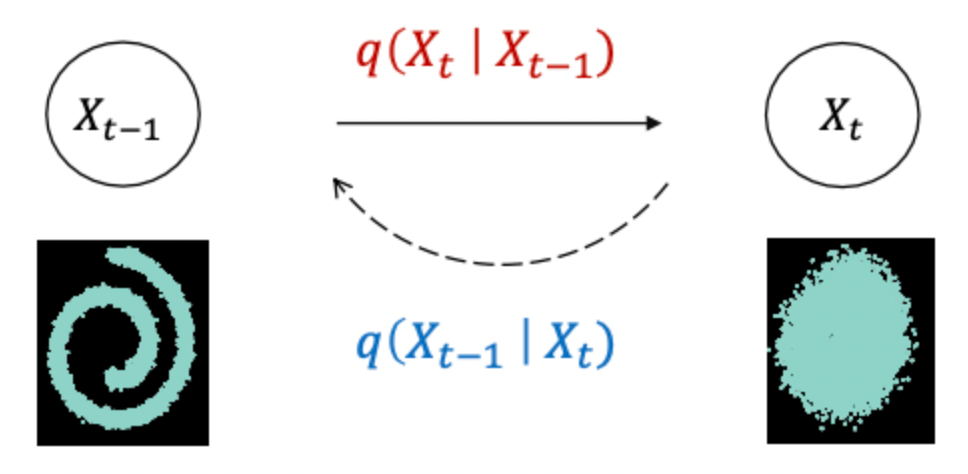
그렇기에 완벽하게 이전상태로 되돌리는 참된 분포 가 아닌 가정을 만족하면서도 와 최대한 유사한 분포 를 대신해서 찾게 됩니다.

이러한 과정은 Diffusion 모델의 Loss function 중 일부인 아래의 항을 통하여 알 수 있다.
그리고 이는 VAE와 마찬가지로 Regularization 항과 Reconstruction 항이 추가된 3개의 항으로 구성됩니다.
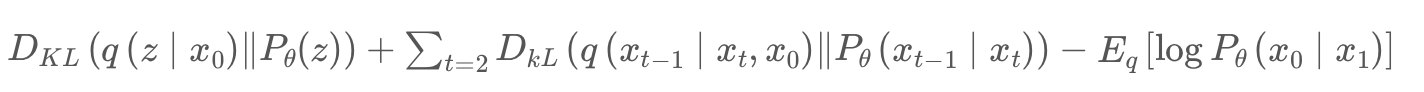
항이 3개나 되기에 간단하게 손실함수를 사용할 수 없습니다.
그렇기에 DDPM을 통해 훨씬 단순한 방법으로 Diffusion model을 구성하였고 DDIM을 통해 더 빠른 속도로 Diffusion process를 진행하였습니다.
DDPM(Denoising Diffusion Probabilistic Models)
발췌:Denoising Diffusion Probabilistic Models
발췌:Denoising Diffusion Probabilistic Modaels 논문 리뷰
DDPM은 Diffusion Model을 활용한 이미지 생성모델을 제시한 논문이다.
이는 기존 Diffusion Model의 loss term과 parameter estimation 과정을 더 학습이 잘 되는 방향을 발전시킨 논문이다.
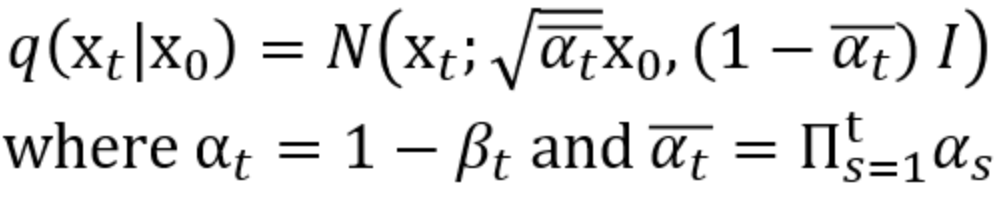
DDPM의 forward process는 기본적은 diffusion model과 같이 data에 gaussian noise를 더하는 형태로 정의한다. 이 때 는 미리 정해진 상수로 정의한다. 이 값을 learnable parameter로 둘 수 있지만 상수로 두어도 큰 차이가 없기 때문이다.
이 때 노이즈만 더하지 않고 로 스케일링 하는 이유는 noise를 더한 이후에 variance를 unit으로 유지하기 위해서이다.
를 곱한 뒤에는 variance가 가 되고, 이 때 variance가 인 noise와 더해지면 unit variance가 된다.
이 때 는 reverse process의 input이므로 모든 에 대해 값이 일정하게 bound 하기 위해 스케일링을 한다.
또한 를 얻기 위해 에서 번의 샘플링을 거치는 것이 아니라 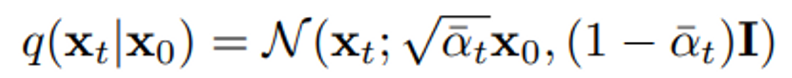
해당 수식으로 한번에 나타낼 수 있다.
이를 통해 번의 forward process를 수행한 뒤에 loss를 계산하는 것이 아닌 한 번에 를 만들고 거기서 loss를 구한 뒤에 에 대해 expectation을 구하는 식으로 학습할 수 있다.
해당 수식들을 기반으로 목적함수의 을 에 대한 식으로 치환한다.
이는 를 통해 을 예측하고 있는데 해당 태스크가 너무 어렵기에 을 맞추는 태스크로 변경하여 Noise를 regression 문제로 바꾼다.
이를 통해 을 로 변경한다.
이는 결국 을 잘 정리하여 학습 효율을 높였다고 할 수 있을 것 같다.
DDIM
발췌:DDIM: Denoising Diffusion Implicit Models 논문 리뷰
DDPM은 adversarial training 없이도 image generation이 잘됨을 증명하였다. 그러나 markov chain을 이용하여 모델을 학습하고 추론하기 때문에 sample을 생성하려면 많은 step(거의 수천 step)을 거쳐야한다는 문제가 있다.
DDIM에서는 좀 더 빠르게 sample을 생성하기 위해 non-markovian diffusion process로 DDPM을 일반화한다. non-Markovian process를 통해 좀더 deterministic한 generative process를 학습시킬 수 있으며, high quality의 sample을 보다 빠르게 생성할 수 있게 되었다.
DDIM에서는 diffusion model의 속도를 빠르게 하게 위해 implicit probabilistic model을 제안하였다. (DDPM과 objective function은 동일)
DDPM의 경우 가 바로 이전 step의 값 에 의해 결정되는 markovian chain이지만
DDIM은 가 바로 이전 step 값 에 의해 결정되는 non-markovian chain이다.
(추가 예정..)
발췌 : 마이즈앤컴퍼니 블로그
