.jpeg)
자료를 시계열 단위로 취합해서 확인을 하려고 하니 많은 블로그 게시글들이 판다스의 resample기능을 이용하면 쉽다고 하였다.
우선 자료의 형태와 최종 변환 형태를 확인해보자.
Raw data의 형태
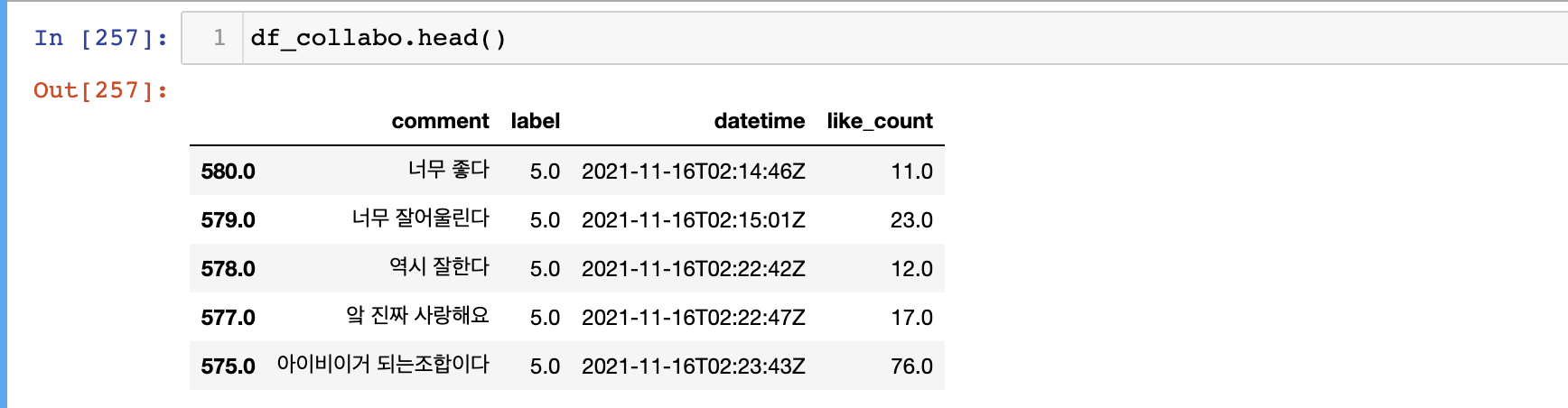
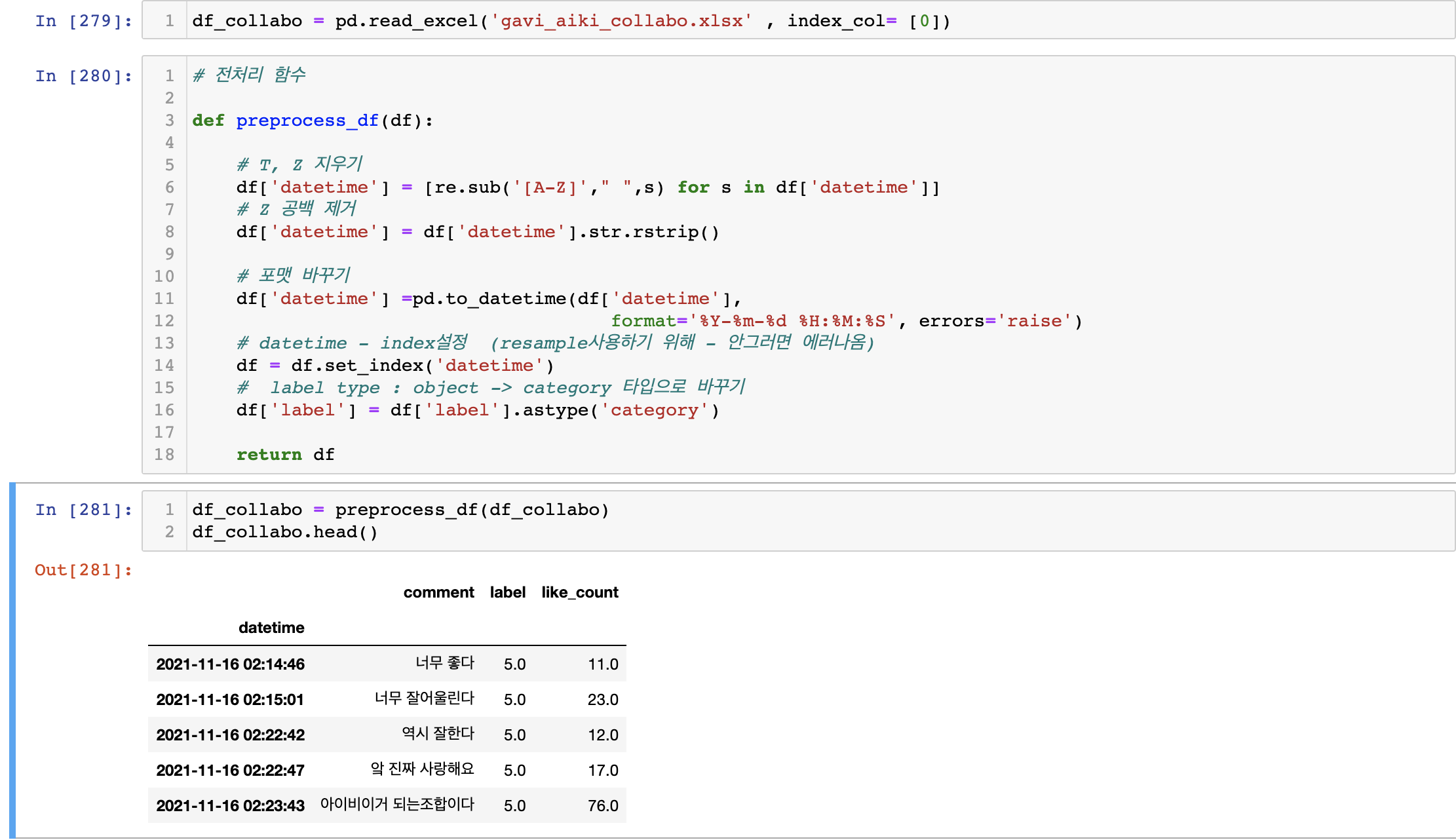
Raw Data는 현재 index, comment , label, datetime, like_count로 구성된 데이터프레임이다.
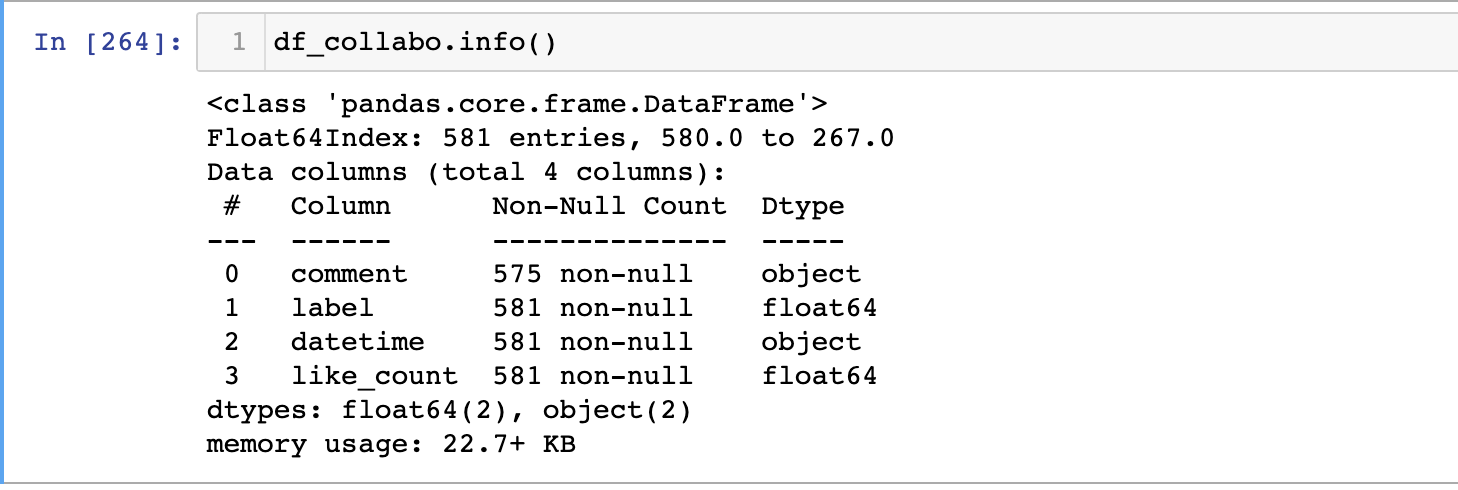
df.info()을 통해서 확인을 해보면 label은 float이고 datetime 은object 타입인 것을 알 수 있다. 이 타입은 나중에 원하는 형태로 그룹핑을 해주려면 타입을 바꿔줘야 한다.
변환 목표
Datetime -> Day별로 합치자
df.resample로 Day별로 합칠 수가 있다. 이 함수를 쓰려면 Datetime을 꼭 인덱스로 지정을 해주어야 한다는 것이다. 그렇지 않으면 TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of 'Float64Index' 에러가 발생한다

따라서 datetime을 인덱스로 만들어주는 과정이 필요하다. 과정이 여러단계가 있어서 별도의 함수를 만들었다.
# 전처리 함수
def preprocess_df(df):
# T, Z 지우기
df['datetime'] = [re.sub('[A-Z]'," ",s) for s in df['datetime']]
# Z 공백 제거
df['datetime'] = df['datetime'].str.rstrip()
# 포맷 바꾸기
df['datetime'] =pd.to_datetime(df['datetime'],
format='%Y-%m-%d %H:%M:%S', errors='raise')
# datetime - index설정 (resample사용하기 위해 - 안그러면 에러나옴)
df = df.set_index('datetime')
# label type : object -> category 타입으로 바꾸기
df['label'] = df['label'].astype('category')
return df
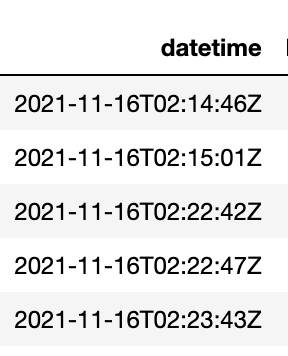
- 현재 Datetime은
2021-11-16T02:14:46Z이런 형식으로 표시가 된다.
# T, Z 지우기
df['datetime'] = [re.sub('[A-Z]'," ",s) for s in df['datetime']]
# Z 공백 제거
df['datetime'] = df['datetime'].str.rstrip()
# 포맷 바꾸기
df['datetime'] =pd.to_datetime(df['datetime'],
format='%Y-%m-%d %H:%M:%S', errors='raise')- Object 형태를 Datetiem으로 바꿔줄 때는
pd.to_datetime을 이용하는데 format 뒤에 나온 형태와 일치해야 한다. 따라서 같은 형태로 바꿔주는 과정을 거친다.
# datetime - index설정 (resample사용하기 위해 - 안그러면 에러나옴)
df = df.set_index('datetime')
# label type : object -> category 타입으로 바꾸기
df['label'] = df['label'].astype('category')- 변환한 datetime을 인덱스설정을 해주고 label도 카테고리 형태의 데이터로 바꿔준다.
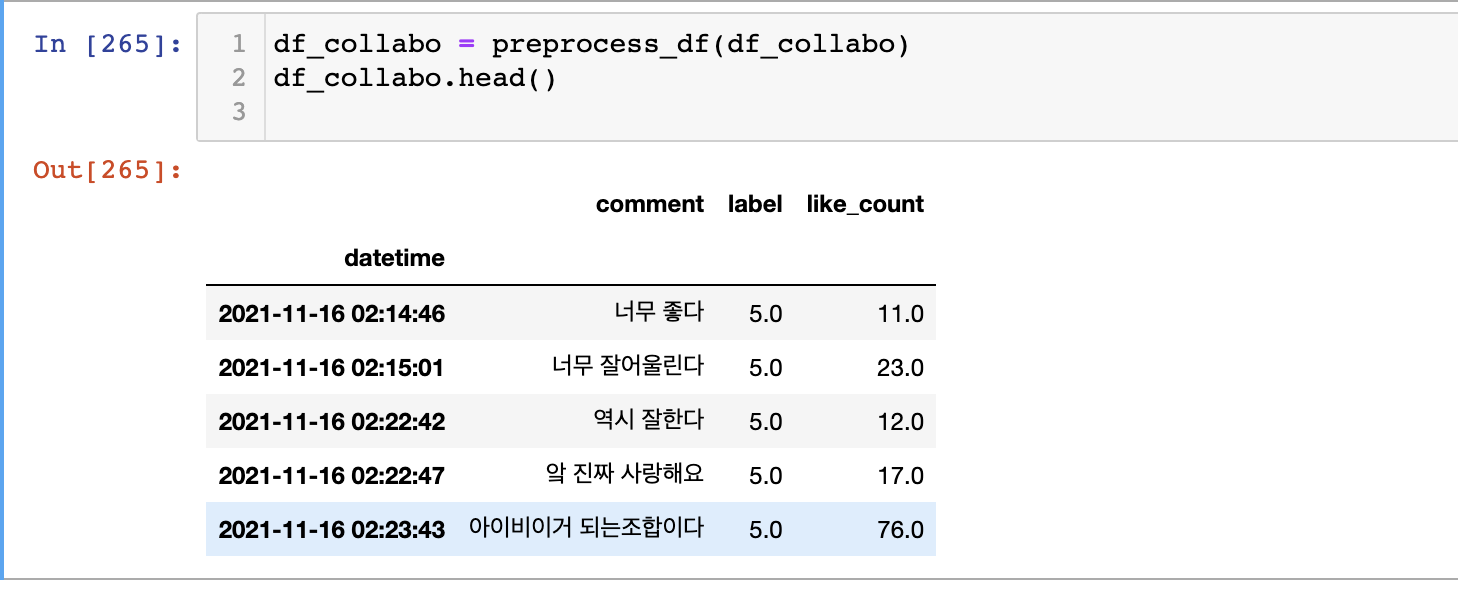
- preprocess 함수를 거치고 나면 위와 같은 형태로 나오게 된다.
Resample
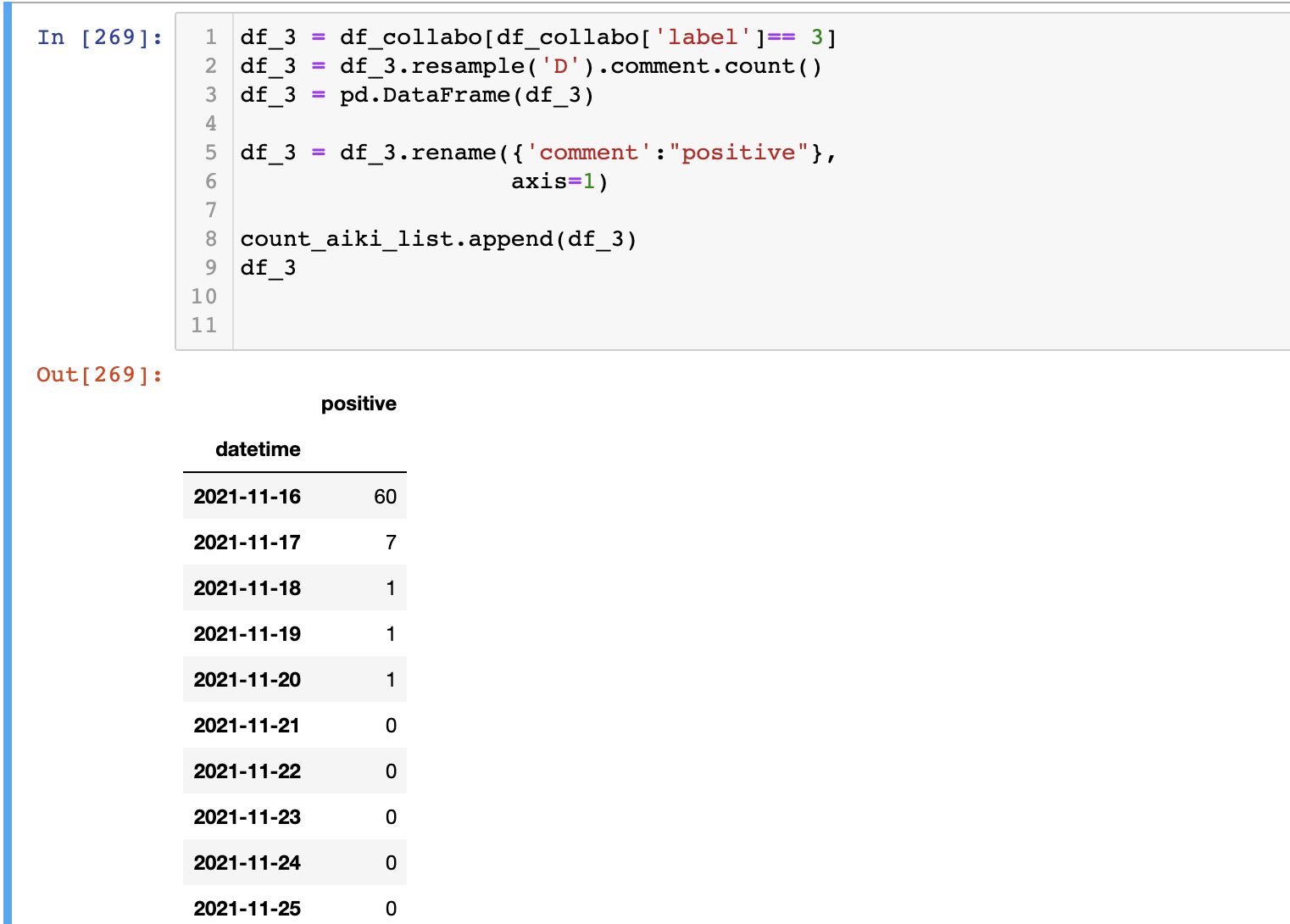
위의 이미지는 label== 3인 자료에 대해서 일별로 취합을 한 결과이다.
- df에서 label이 특정 조건에 해당하는 경우만을 필터링한다.
df.resample('D')을 이용하여 인덱스를일별로 댓글의 개수(고유값) 취합을 한다.- 만들어진 데이터프레임의 컬럼은 자동으로 원래 colname인
comment가 되기 때문에 이걸df.rename으로 postive로 지정해준다.
참고 : https://seong6496.tistory.com/85
근데 이렇게 각 라벨별로 6번 그리고 raw data마다 반복을 하려니 현타가 왔다. 그래서 함수를 만들어서 한 번에 만들어보기로 했다.
함수
def count_label (df, label_num, label_name, result_list):
df = df[df['label'] == label_num ]
df = df.resample('D').comment.count()
df = pd.DataFrame(df)
df = df.rename({'comment':label_name},
axis=1)
result_list.append(df)
return result_list
def concat_label_count(df, label_name):
list_name = []
category = df.label.cat.categories.tolist()
for i in range(len(category)):
count_label(df,i+1,label_name[i],list_name)
df = pd.concat(list_name, axis =1)
return df
우선 전체적인 구조는 concat_count_label 함수 내부에서 count_label 함수를 호출하는 구조이다.
concat_label_count
이 함수는 각각 라벨별로 집계된 DF를 하나의 DF로 합치는 과정을 담고 있다. 합치는 과정에서 DF의 column내용을 각 라벨별로 지정을 할 수 있어 최종 DF가 가독성이 좋아진다.

중간에 df.label.cat.categories.tolist()는 카테고리의 라벨의 종류를 한 리스트에 담아주어 동적으로 작업이 가능하도록 해준다.
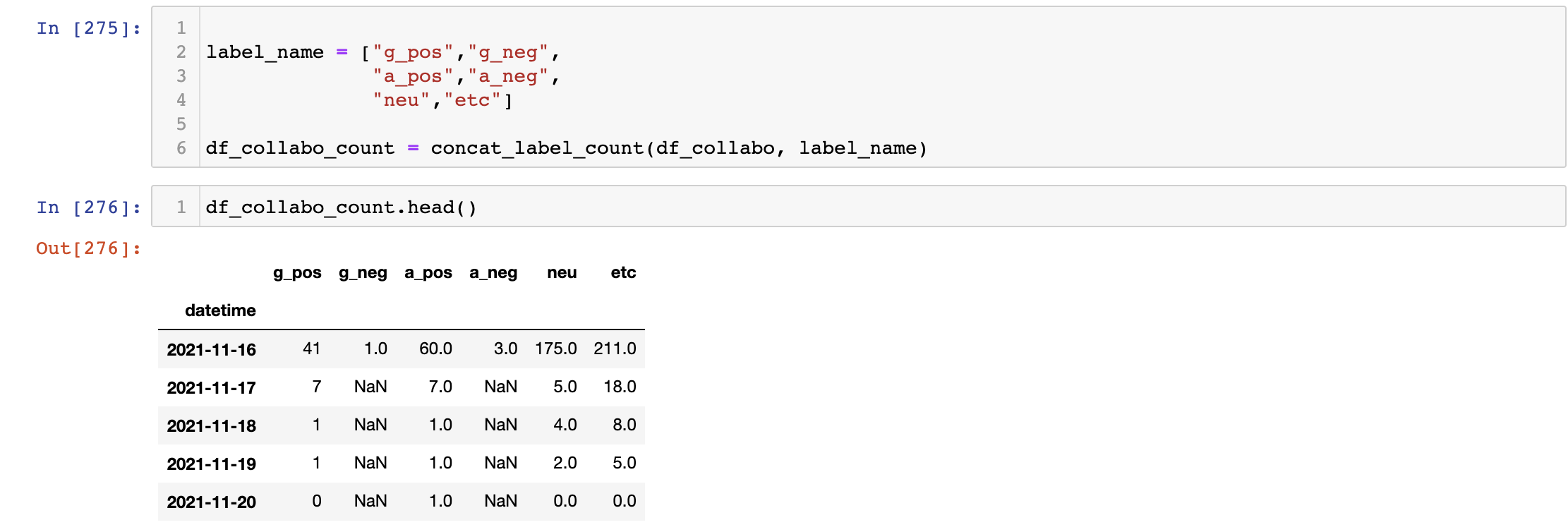
그리고 합치는 경우 특정 날짜에 데이터가 없는 경우 에러가 나오지 않고 해당 col 자료는 NaN이 된다. (예를 들어 2021-11-21에 g_pos가 존재하지만 g_neg가 존재하지 않으면 해당 날짜에 g_neg는 NaN )
count label
우선 이 함수는 위에 나와있는 과정을 일반화하는 함수를 만든 것이다. label_num은 뒤에 나오는 concat_label_count 함수에서 loop의 인덱스를 받아서 입력 받는다. 그리고 최종 만들어진 결과는 concat_label_count함수의 list_name에 담기게 된다.
최종 결과
데이터 불러오기 + 전처리
라벨별 함수 집계
.jpeg)