
유튜브의 댓글을 바탕으로 프로젝트를 진행하고자 했다. 막연히 크롤링을 해야 하나 생각을 하고 있을 떄 한 게시물을 접하게 되었다.
참고 게시글 : 유튜브 API 사용법
이 분의 게시글을 참고해서 해당 영상링크와 API KEY를 넣으면 자동으로 댓글의 자료를 모아 데이터프레임으로 만들어주는 함수를 만들었다.
대부분의 코드는 위 게시글의 코드를 참고했다. 다만 추가된 부분이 약간 있어서 그 부분을 정리하려고 한다.
코드
# 필요 라이브러리 import
## 데이터 프레임 다루기 위해
import pandas as pd
## 구글 api(유튜브) 연결
from googleapiclient.discovery import build
## 진행상황 파악
from tqdm import tqdm
우선은 필요한 라이브러리를 import 해준다. 설치가 안되어있다면 한 번 설치를 진행한 후에 import를 해준다.
def collect_comments (video_list, result_list, api_key) :
#tqdm 적용
video_list = tqdm(video_list)
# api 연결
api_obj = build ('youtube', 'v3', developerKey = api_key)
# 각 video의 댓글이 잘 합쳐졌는지 확인하기 위해서
shape_count = list()
for video in video_list:
video_id = video[17:]
video_list.set_description ("Collecting Comments from youtube....")
response = api_obj.commentThreads().list(part='snippet,replies',
videoId = video_id,
maxResults = 100). execute()
# 각 비디오의 댓글
comments = list()
while response:
for item in response['items']:
comment = item['snippet']['topLevelComment']['snippet']
comments.append([comment['textDisplay'], comment['publishedAt'],comment['likeCount']])
if item['snippet']['totalReplyCount']>0:
for reply_item in item['replies']['comments']:
reply = reply_item['snippet']
comments.append([reply])
comments.append([reply['textDisplay'], reply['publishedAt'], reply['likeCount']])
# page 넘겨가면서 댓글 조회
if 'nextPageToken' in response:
response = api_obj.commentThreads().list(part='snippet,replies', videoId=video_id, pageToken=response['nextPageToken'], maxResults=100).execute()
else:
break
# 데이터 프레임으로 만들어주기
df = pd.DataFrame(comments, columns = ["comment","datetime","like_count"])
# na 값 제거
df = df.dropna(axis=0)
# 각 비디오별 자료개수 파악
print(f"{video_id} : {df.shape}")
# 합계할 리스트에 삽입
shape_count.append(df.shape[0])
# 최종 df로 만들기 전에 리스트에 삽입
result_list.append(df)
# 최종 df로 합쳐주기
result_list = pd.concat(result_list,ignore_index=True)
if sum(shape_count) == result_list.shape[0]:
print("합계가 일치합니다.")
return result_list
else:
print(f"sum : {sum(shape_count)} / {result_list.shape[0]} 합계가 일치하지 않습니다.")
return result_list
여러 비디오 자료 가져오기
우선 기존 블로그에 포스팅은 한번에 하나의 영상만 가져올 수 있었다. 그래서 영상여러개를 한 번에 작업하는 함수를 만들고 싶었다. 그래서 영상의 주소가 들어있는 리스트를 넣게 되면 해당 리스트에서 고유 영상 id값을 추출해서 자동으로 df을 만들고 최종적으로 하나의 df로 합쳐주는 함수를 만들었다.
tqdm
#tqdm 적용
video_list = tqdm(video_list)
video_list.set_description ("Collecting Comments from youtube....")
이 패키지는 iterable한 객체에 적용을 하게 되면 이 객체를 대상으로 반복문을 돌리게 되면 각 진행상황을 % 형태로 표시를 해준다.
아무래도 여러 영상의 자료가 많아지게 되면 어느정도 진행되고 있는지 확인을 할 필요가 있기 떄문에 tqdm을 찾아 적용을 하였다.
video_list.set_description ("Collecting Comments from youtube....")이렇게 설명을 지정해주면 해당 작업을 할 때 설명이 같이 찍어져서 나오게된다. 조금 더 깔끔하게 진행상황을 파악할 수 있다.
각 영상의 자료를 합치기
# 데이터 프레임으로 만들어주기
df = pd.DataFrame(comments, columns = ["comment","datetime","like_count"])
# na 값 제거
df = df.dropna(axis=0)
# 각 비디오별 자료개수 파악
print(f"{video_id} : {df.shape}")
# 합계할 리스트에 삽입
shape_count.append(df.shape[0])
# 최종 df로 만들기 전에 리스트에 삽입
result_list.append(df)
# 최종 df로 합쳐주기
result_list = pd.concat(result_list,ignore_index=True)각 영상의 자료를 각각 comments라는 list의 저장해두고 그 자료를 입력받은 결과 리스트에 넣어준다. 그리고 그 리스트에 들어있는 각각의 df를 concat을 이용해 하나의 DF로 만들어준다.
각 영상 자료 갯수 비교
# 각 video의 댓글이 잘 합쳐졌는지 확인하기 위해서
shape_count = list()
# 각 비디오별 자료개수 파악
print(f"{video_id} : {df.shape}")
# 합계할 리스트에 삽입
shape_count.append(df.shape[0])
if sum(shape_count) == result_list.shape[0]:
print("합계가 일치합니다.")
return result_list
else:
print(f"sum : {sum(shape_count)} / {result_list.shape[0]} 합계가 일치하지 않습니다.")
return result_list
이 로직은 중간에 각각의 자료개수와 전체의 자료갯수가 일치하지 않는 경우가 발생을 해서 만들었다. 원인을 확인해보니 합치는 과정에서 누락되는 자료가 있었고 이 부분이 차이를 만들었었다. 그래서 각각 comments DF의 자료의 갯수를 임시 리스트에 저장하고 전체리스트와 임시리스트 자료의 개수를 비교해서 결과를 반환한다.
함수 출력결과
collect_comment(영상링크 리스트, 댓글 정보들이 담길 리스트, 구글에서 발급받은 API KEY)

리스트(list_test)에 원하는 유튜브 영상의 링크를 넣어주면 된다. 유튜브 영상의 링크는 공유하기를 통해서 생성되는 링크를 기준으로 헀다.

위의 링크를 복사해서 저 리스트에 넣어주면 각각 영상의 댓글을 따로따로 모아서 최종적으로 합쳐준다.
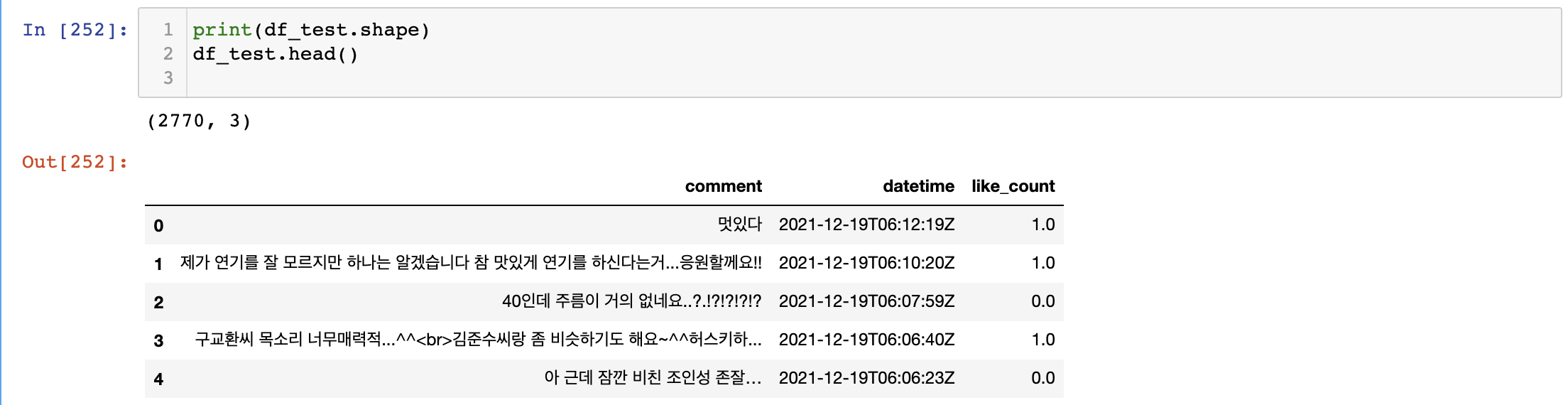
shape을 해보면 자료가 잘 합쳐진 데이터 프레임 형태로 나타나는 것을 확인할 수 있다.
.jpeg)