지도학습의 빅 픽쳐
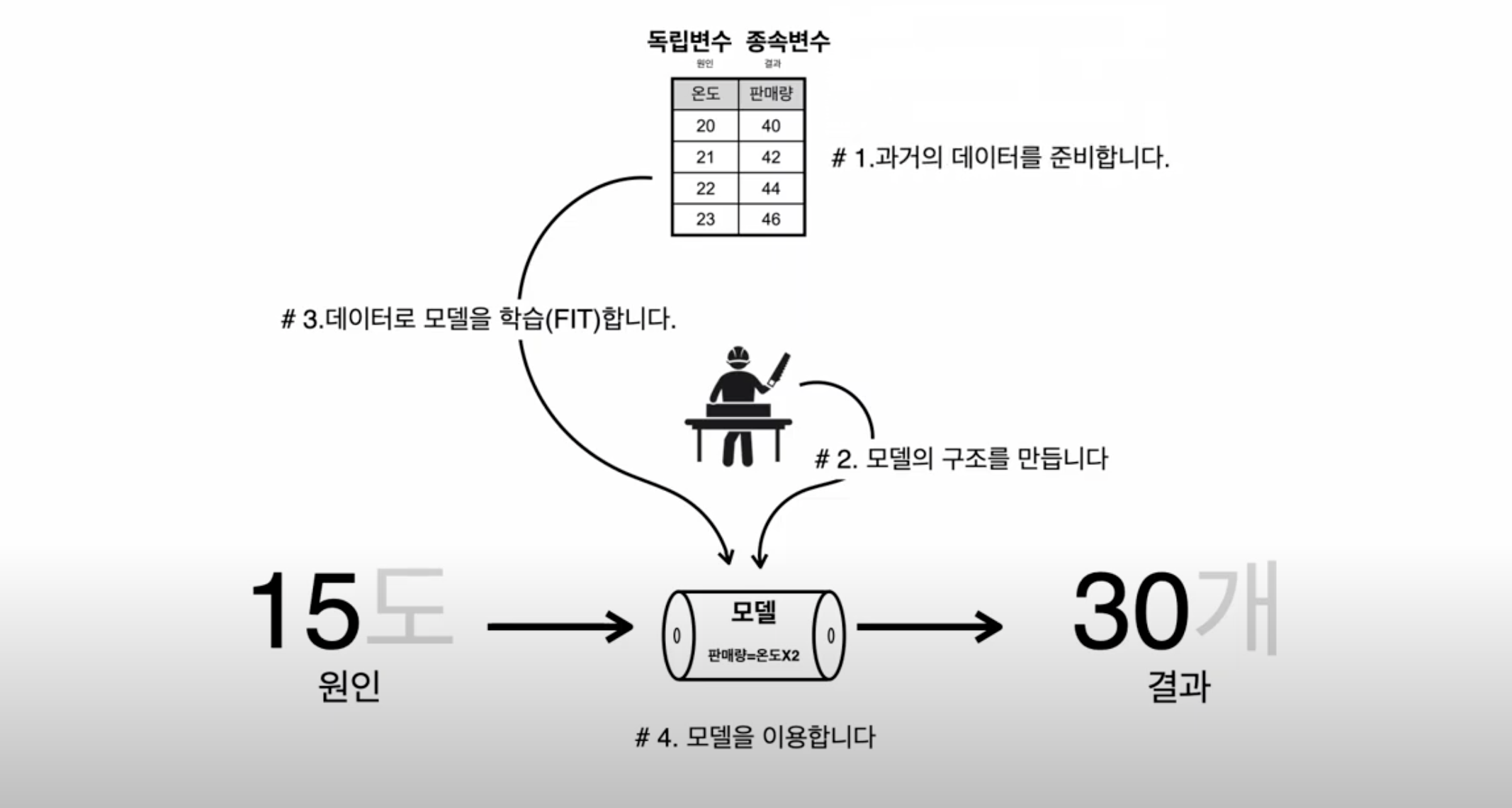
- 과거의 데이터를 준비
- 원인(독립변수)과 결과(종속변수)를 인식
예) 온도 -> 레모네이드 판매량
- 모델의 구조를 만든다.
- X-> Y
- X1,X2, X3 -> Y
- 데이터로 모델을 학습(FIT)한다
- 모델을 이용한다.
loss의 의미
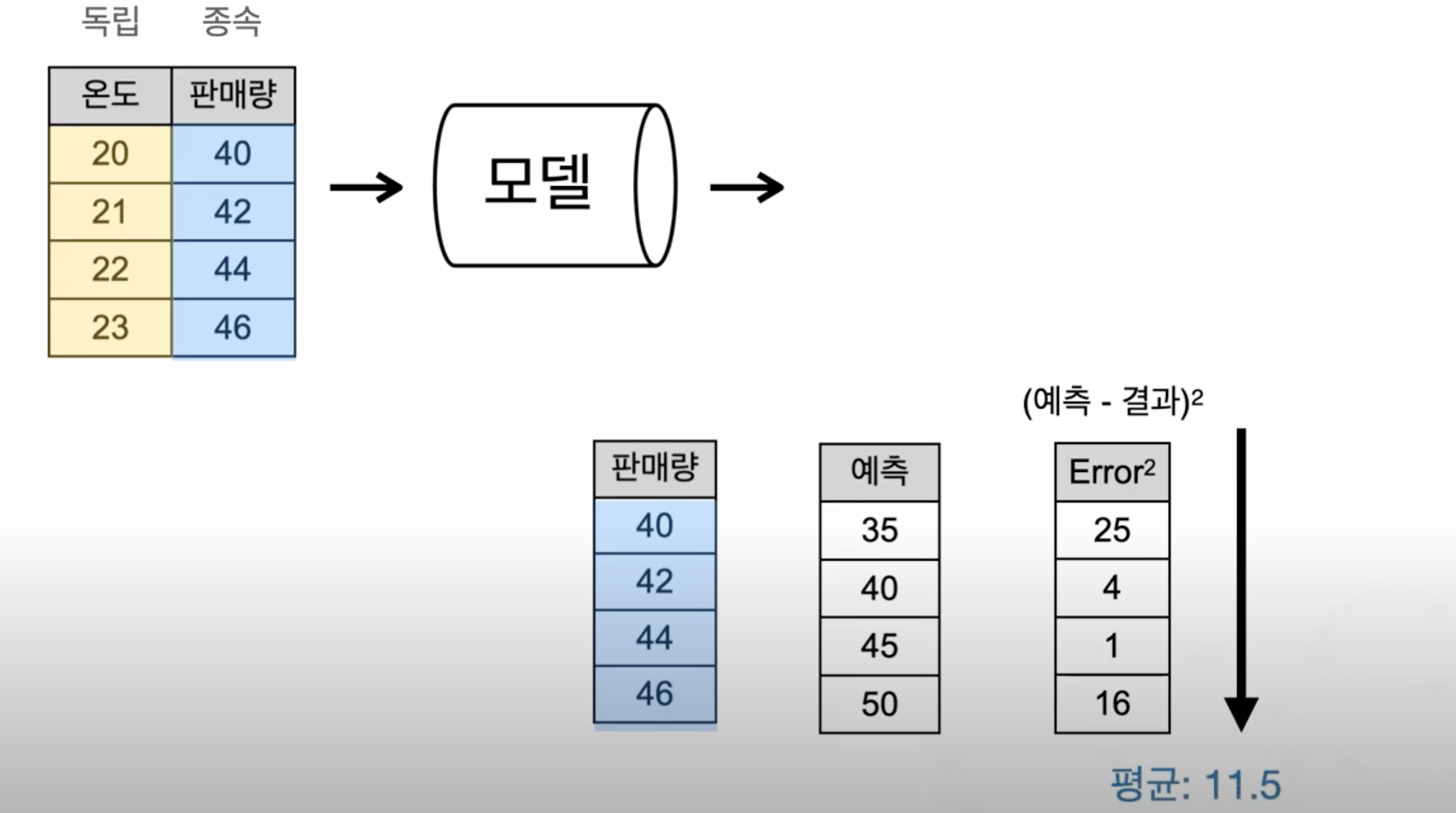
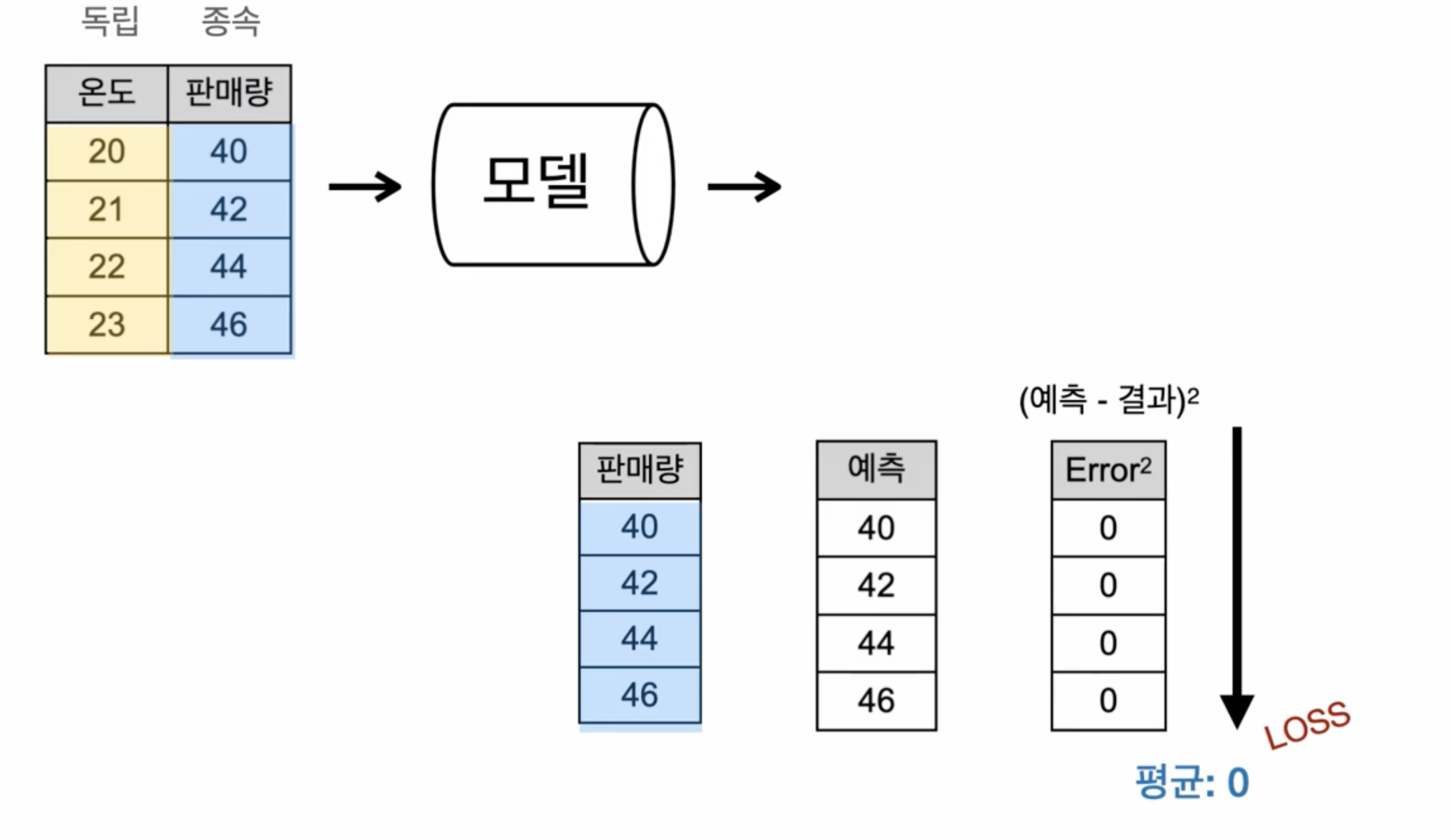
loss가 0에 가까워질수록 학습이 잘 된 것!
레모네이드 판매량 예측
1. 데이터 준비
필요한 라이브러리 가져오기
import pandas as pd
import tensorflow as tf
데이터 불러오기
# 1. 데이터 불러오기
lemonade = pd.read_csv("csv/lemonade.csv")
# 독립변수 종속변수
lemonade_x = lemonade[['온도']]
lemonade_y = lemonade[['판매량']]2. 모델 구조 만들기
모델 만들기
# 2. 모델 만들기
# 1 depth layer
# 독립변수 1개 shape= [1]
X = tf.keras.layers.Input(shape=[1])
# 종속변수 1개 Dense(1)
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X,Y)
model.compile(loss= 'mse')
X = tf.keras.layers.Input(shape=[1])독립변수가 1개이기 때문에 shape = [1]Y = tf.keras.layers.Dense(1)(X)종속변수가 1개이기 때문에 shape = [1]- keras의 모델 인스턴스로 할당
- model loss function 알고리즘은
mse사용 (mean squre error)
3. 데이터로 모델을 학습
학습하기
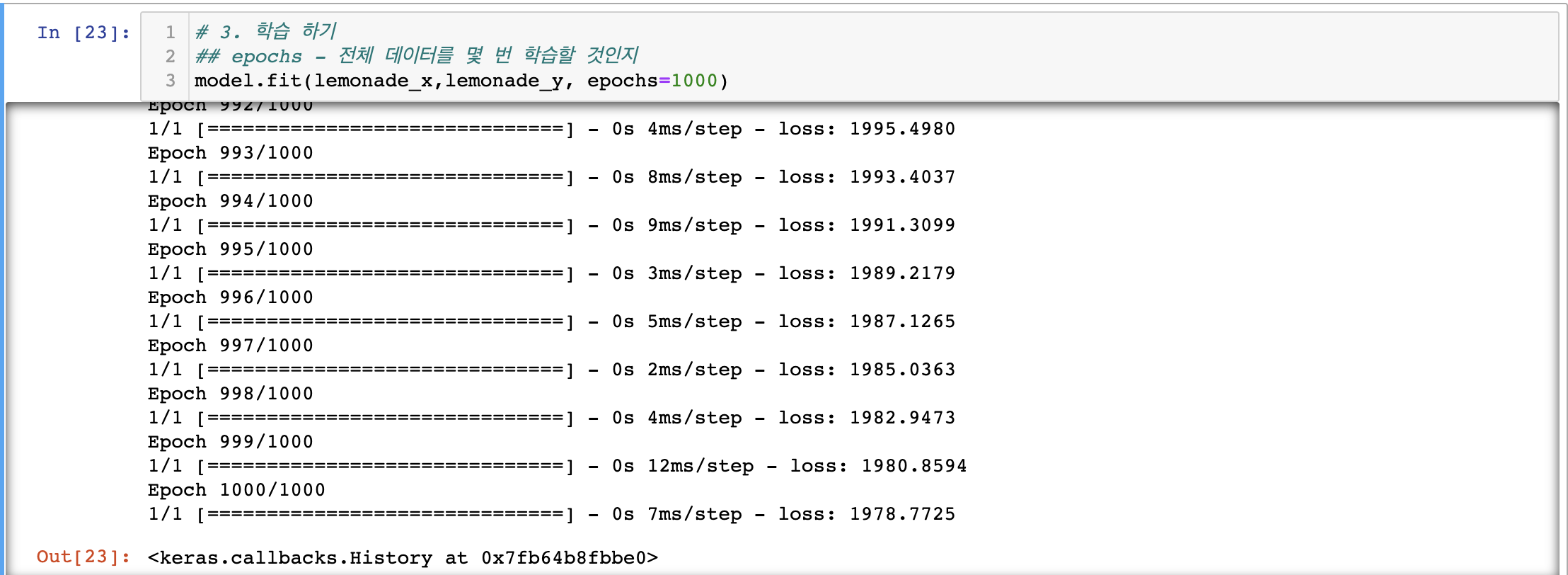
epoch은 전체 데이터를 몇 번 학습할 것인지- 1000번 학습하고 나서 loss는 1978 대
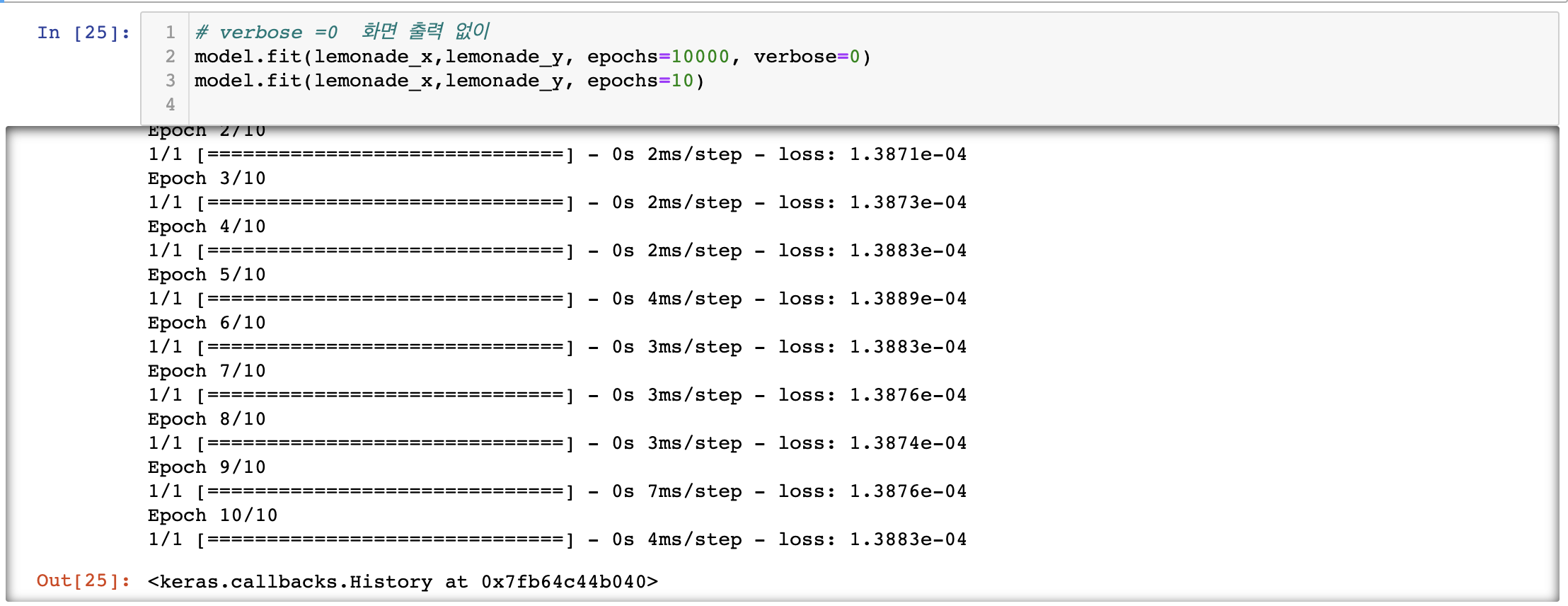
- 10000번 +10 번 학습하고 나서는 loss가 0.00013883(1.3883 * 10^-4)까지 줄어들었음
verbose =0으로 지정하면 해당 학습 과정이 프린트 되지 않음
4. 모델을 이용
예측하기
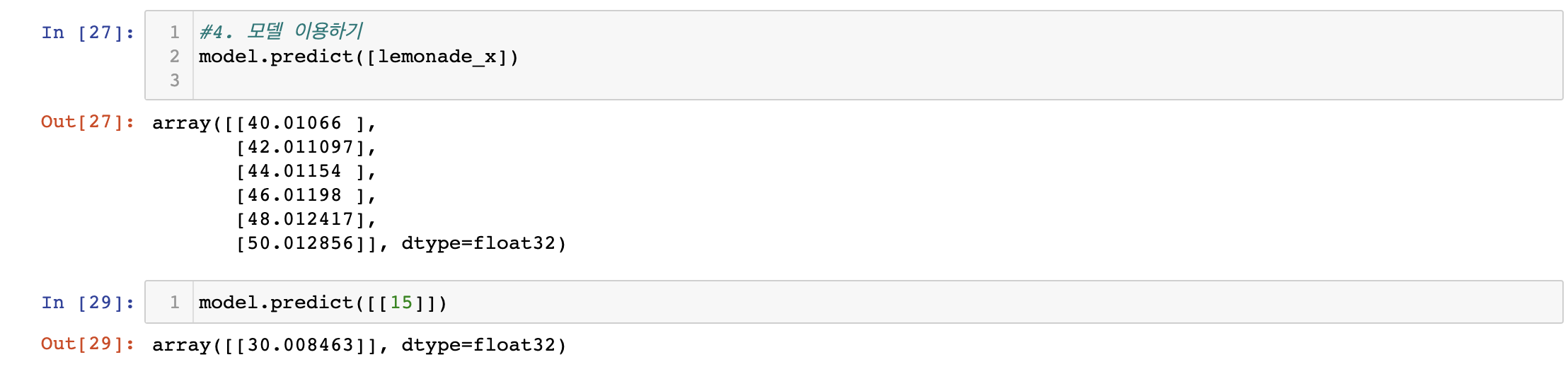
- 독립변수에 값을 넣어주면
학습한 모델에 따라서예측(결과)값을 출력
보스턴 집값 예측
독립변수가 여러개인 모형(퍼셉트론)
1. 데이터 불러오기

독립변수가여러개인 것을 확인 가능- 데이터를 불러오고 나서는 항상
shape과tail(head)로 확인하는 습관 들이기
2. 모델 만들기

- 독립변수가 13개( 2개 이상)이라
shape=[13] - 종속변수는 여전히 1개이니 Dense(1)(x)
3. 학습하기
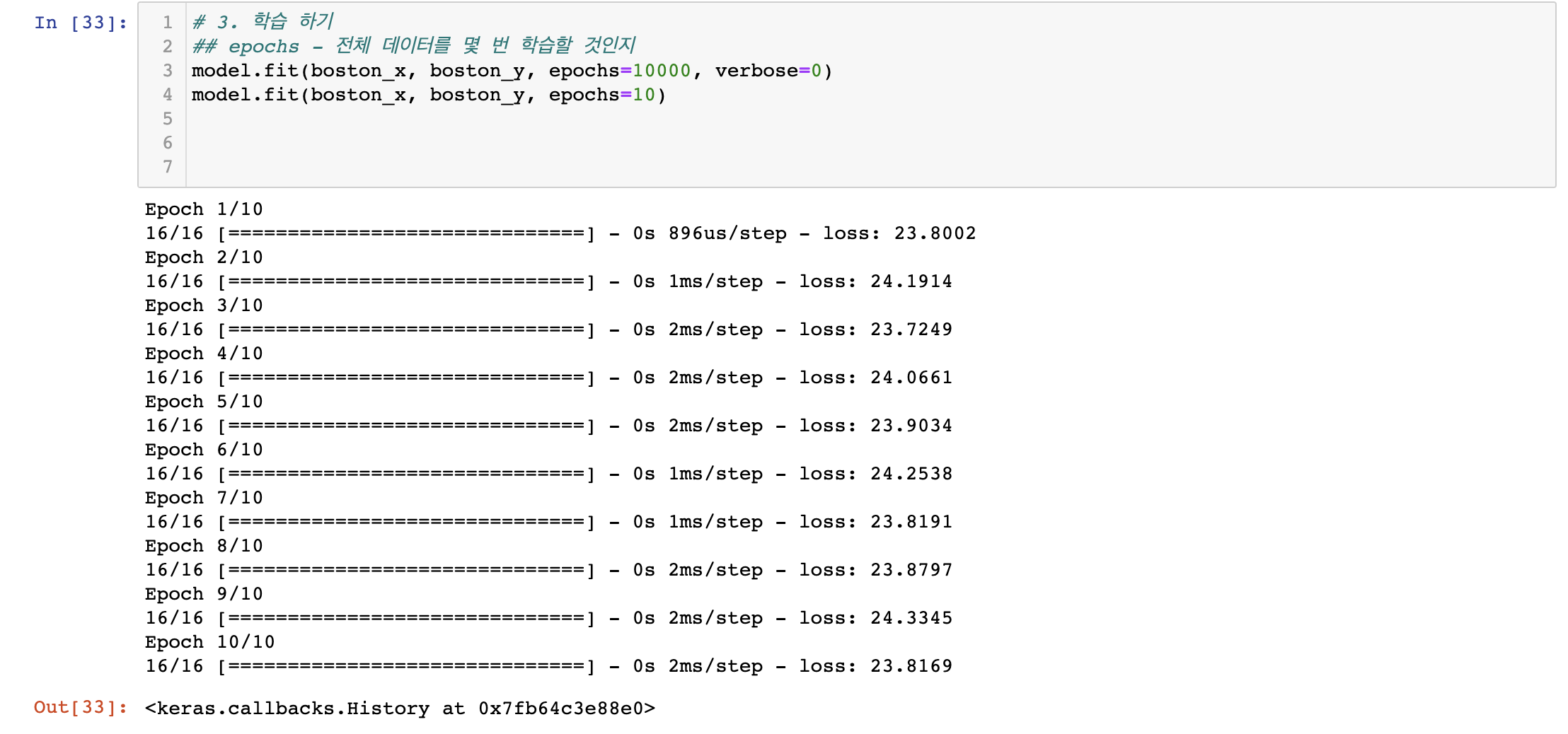
- 전체 506개의 행 중에서 6번째~10까지 자료로 결과 확인
4. 모델 이용하기
예측하기

가중치
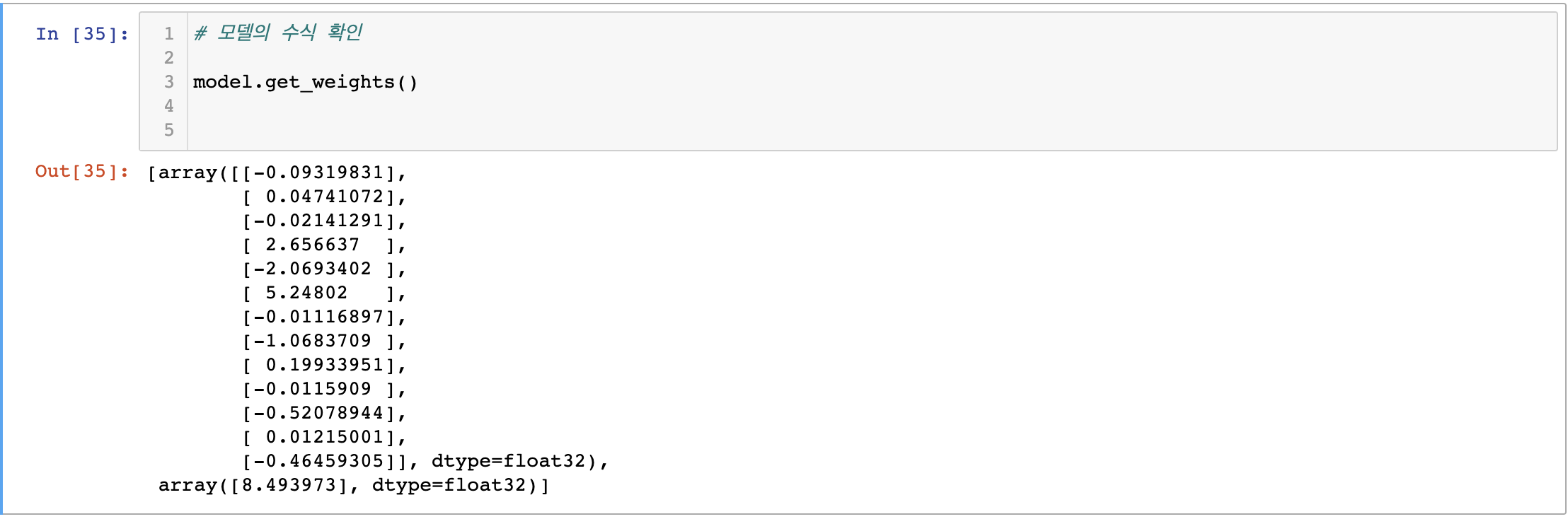
get_weights를 사용하면 각 변수의 weight(계수)를 알 수 있음- 마지막에 8.493973이
bias
Iris 품종 분류
데이터 불러오기
종속변수가 연속형 데이터가 아닌 범주형 데이터
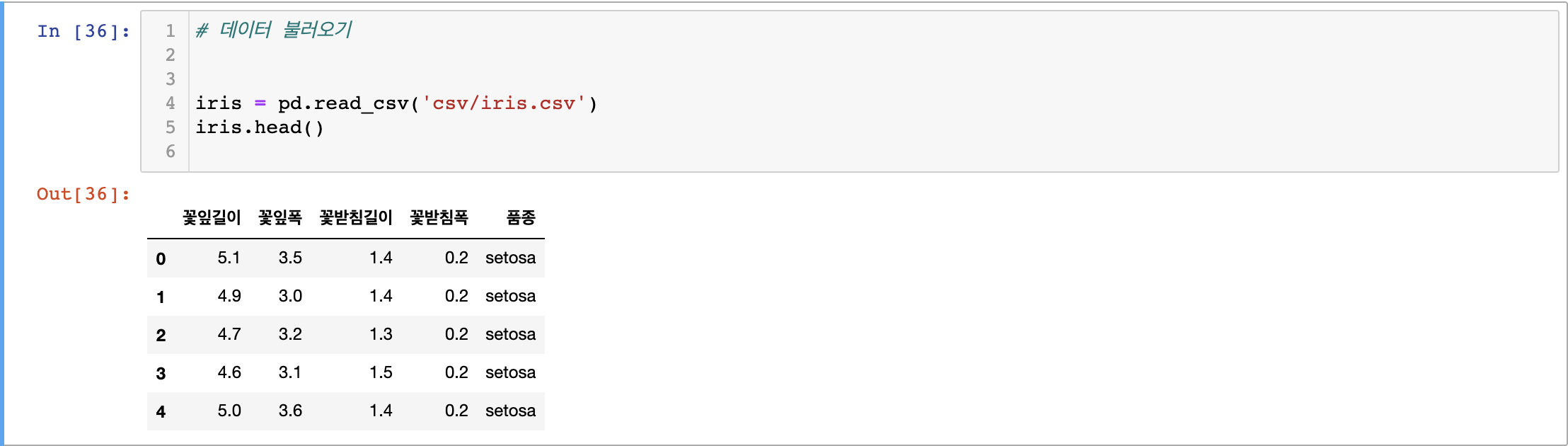
- 품종 column에 setosa, versicolor, virginica로 나뉨
One hot encoding - 범주형 데이터-> 확률로 표현
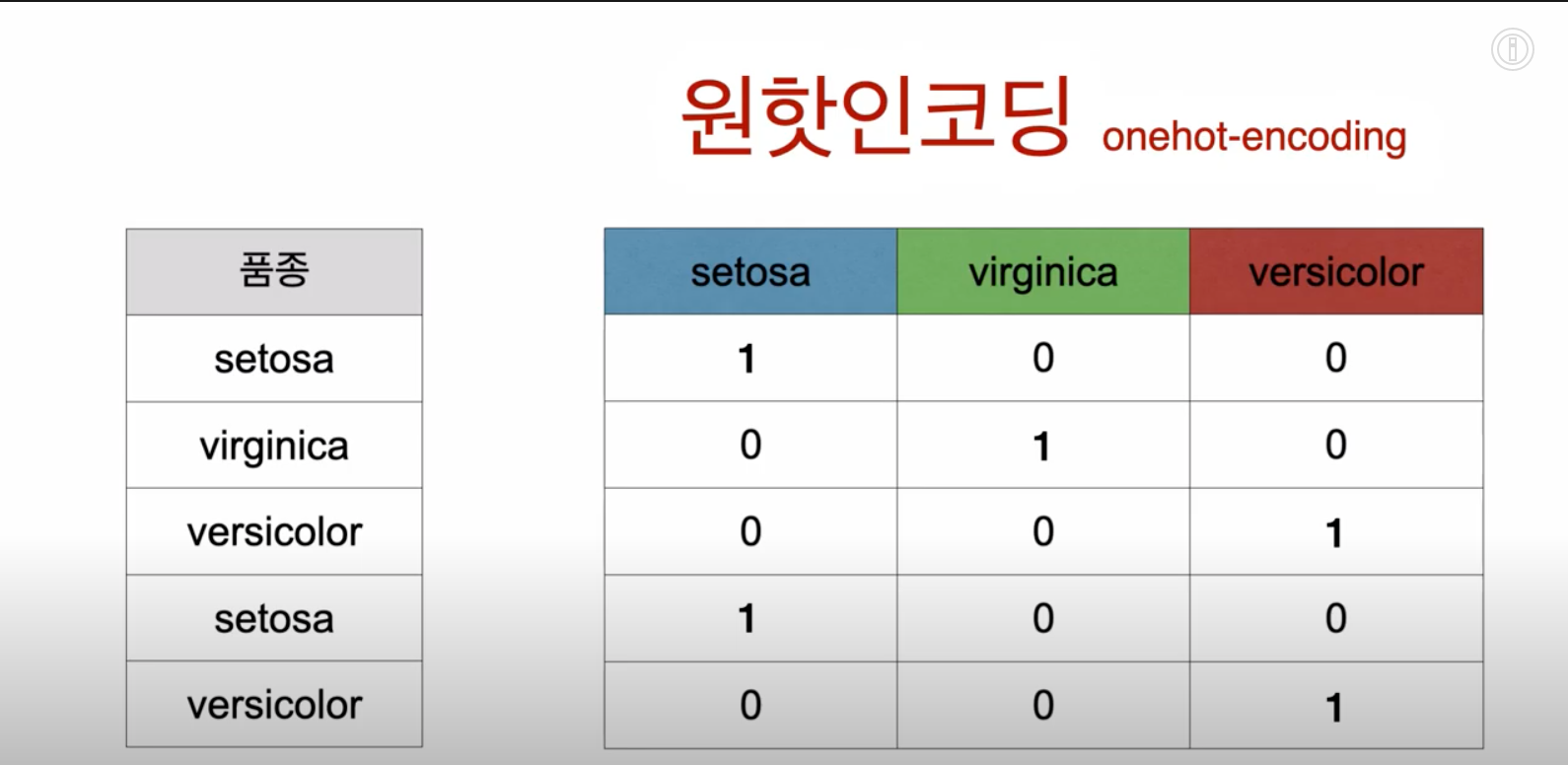
- 범주형 데이터를 각 범주마다 column을 만들어주고 해당하는 자료는 해당 column에 1, 나머지 column에 0을 부여
- 각 범주형 데이터를 각 범주에 속할 확률로 표현
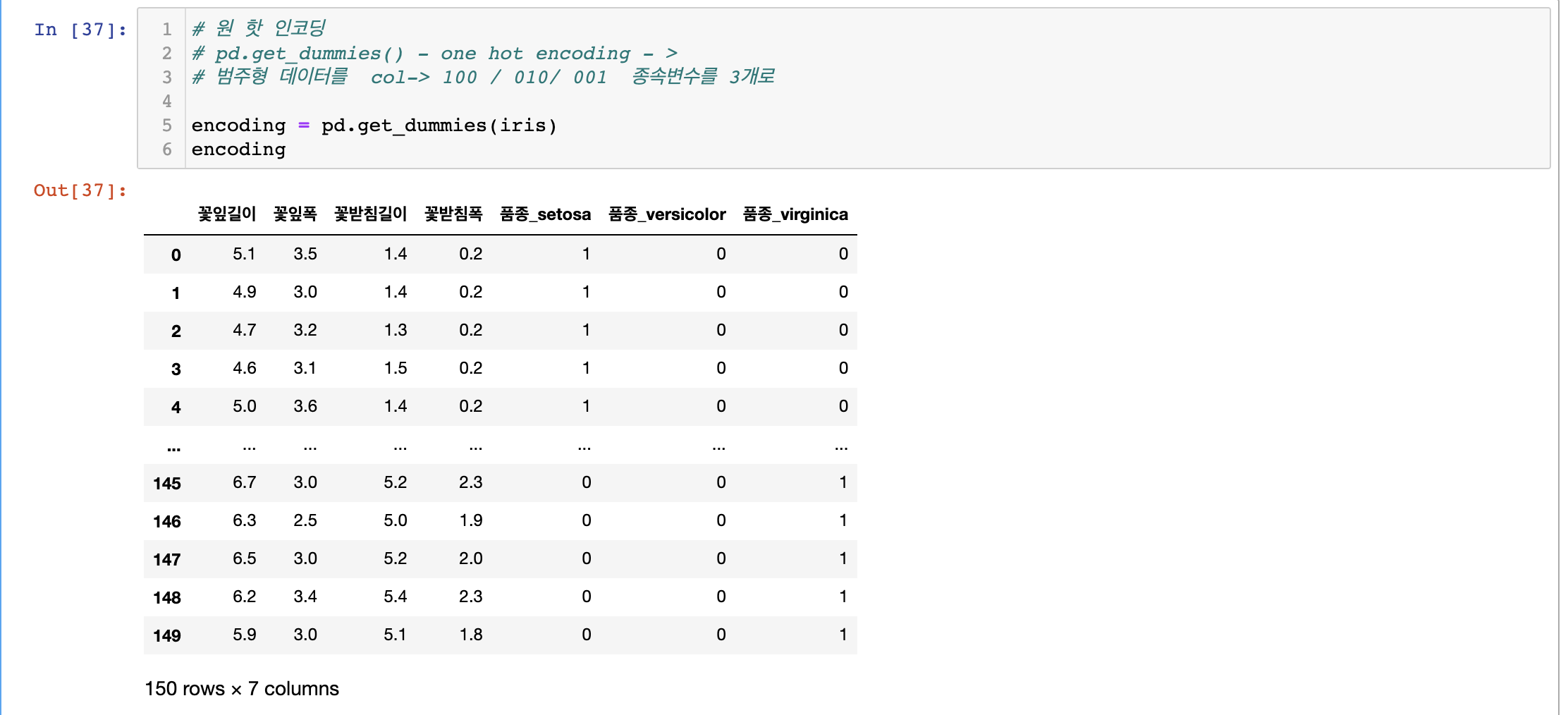
- pandas에서 지원하는
get_dummies로 one-hot-encoding가능

- 원핫인코딩 된 필드를 종속변수로 할당

독립변수 : 4개 (['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭'])
X = tf.keras.layers.Input(shape=[4])
종속변수 : 3개 (['품종_setosa', '품종_versicolor',
'품종_virginica'])
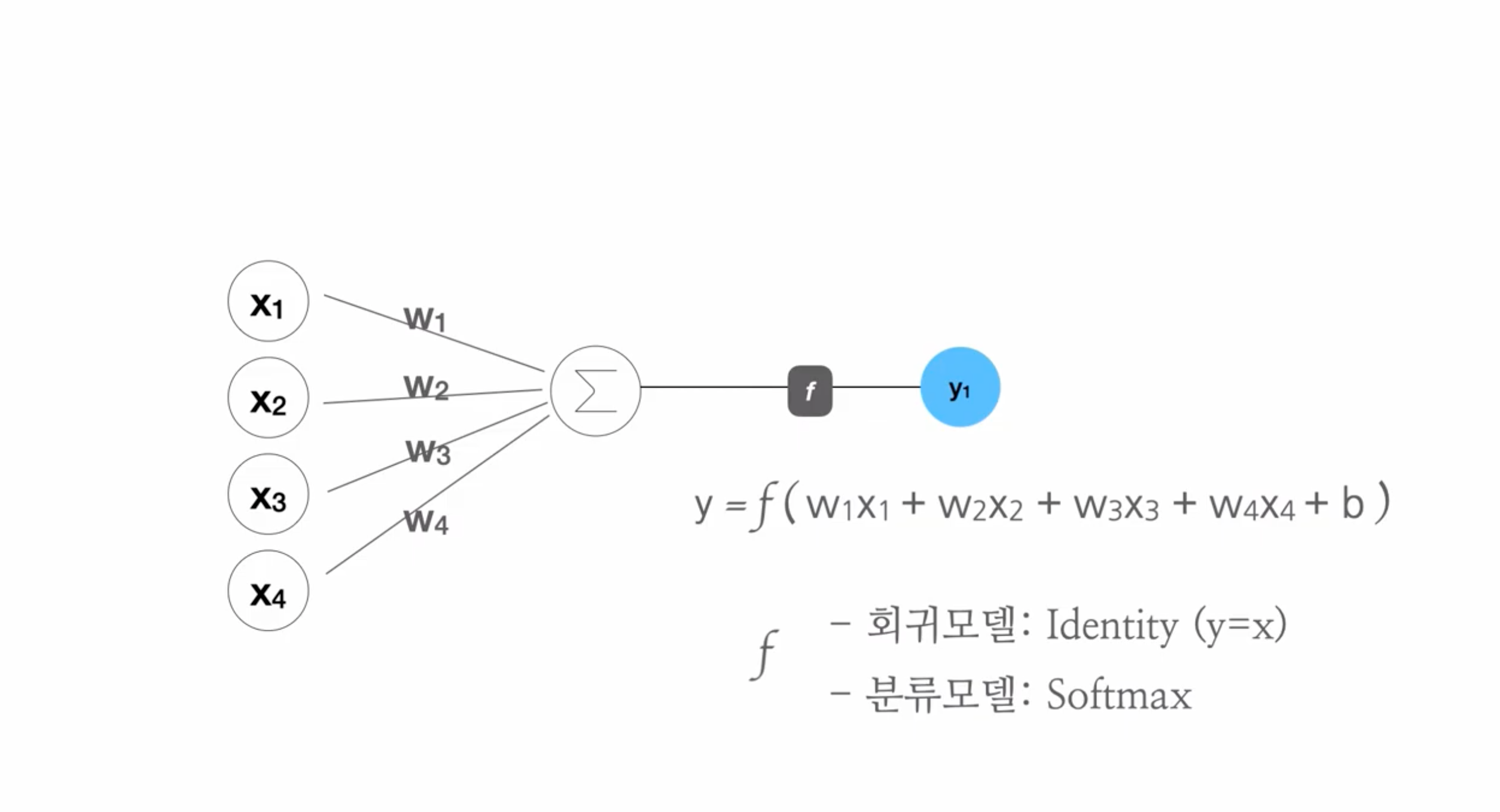
Y = tf.keras.layers.Dense(3, activation="softmax")(X)활성함수(activation function)는softmax를 사용
loss function -
categorical_crossentrophy를 사용
활성함수
인공 신경망에서 입력을 변환하는 함수 - 입력값으로 종속변수의 확률을 추측하는 함수
softmax vs sigmoid
모델 학습하기
모델 학습
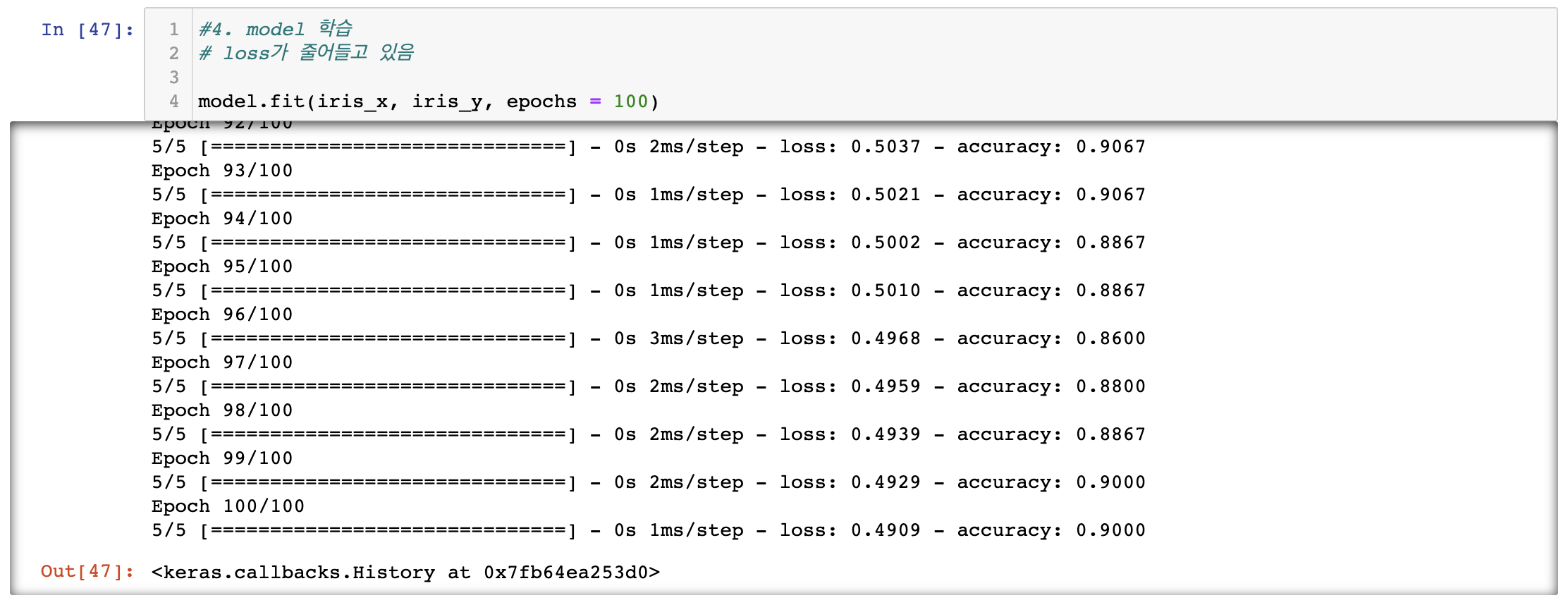
accuracy로 분류를 몇 %의 정확도로 예측하는 지 확인가능
모델 이용하기
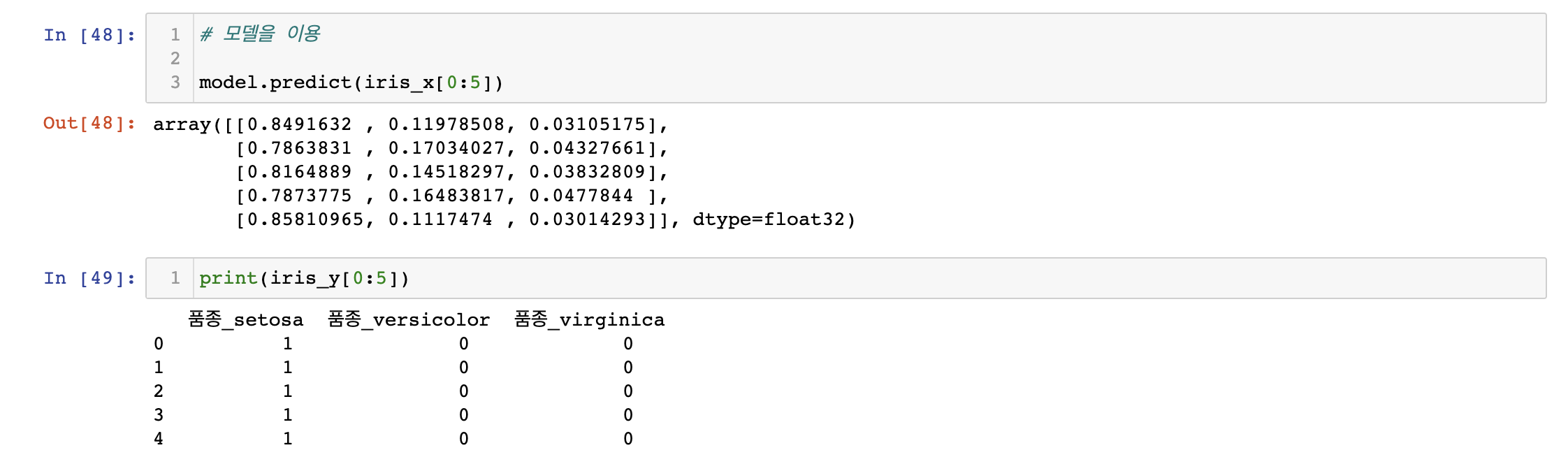
- 결과는 종속변수 (['품종_setosa', '품종_versicolor',
'품종_virginica'])의 각 확률을 표시 품종_setosa가 0.7 ~ 0.8로 확률이 가장 크다는 것을 확인할 수 있음- 실제 결과도 setosa이므로 제대로 예측을 했음을 확인할 수 있음

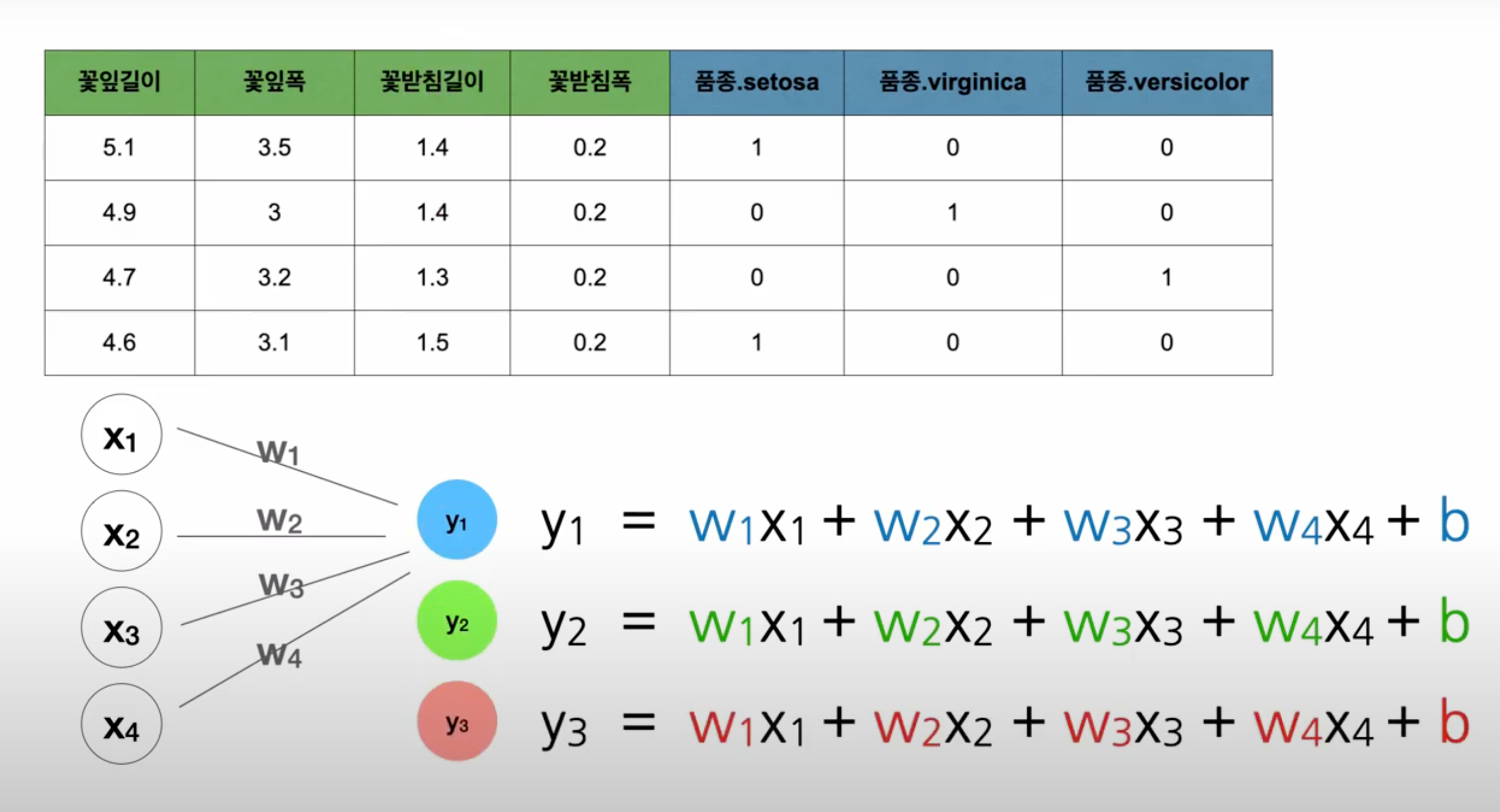
-
각 활성함수는 가중치를 세로의 수로 한다.
-
예시 ) 품종_setosa = 9.8x1 + 6.9x2 + -6.9x3 + -1.39 x4 + 0.1256(bias)
히든레이어
perceptron를 여러개 연결해서 학습 효과를 향상시킬 수 있음
.jpeg)
기록을 통해 한 걸음씩 성장ing!