학교를 다닐 때 행정계량, 금융계량 강의를 들으면서 지겹게 공부를 했는데 말로 이야기하려니 딱 설명할 수 없어서 따로 정리를 하려고 한다. 사회조사 분석사 딸때만 해도 서술형 때문이라도 줄줄 이야기할 수 있었는데..... 지금 제대로 정리해서 기록을 해두면 나중에도 이야기할 수 있을 것이다.
변수와 상수
변수 - 상수
변수 : 값이 달라질 수 있는 것
상수 : 값이 달라지지 않는 것
독립변수 - 종속변수
독립변수 : 원인이 되는 것 , 설명변수
종속변수 : 결과가 되는 것 , 반응변수
질적변수 - 양적변수
질적변수 - 수치로 나타낼 수 없는 변수 - 성, 혈액형, 직종
- 명목변수 : 자료의 특성을 서로 다른 범주로 구분 (단순분류)
성별 , 혈액형
-서열변수 : 자료의 특성에 서열을 매기기 위해 수치 사용 (분류+ 서열)
삶의 만족도 ( 1. 매우만족, 2. 만족, 3. 보통, 4.불만, 5. 매우 불만)
양적변수 - 수치로 나타낼 수 있는 변수 - 체중 키 온도
-
등간 변수 : 특성에 서열 + 상대적인 차이까지 제시
'0'의 의미 : 사람이 인위적으로 만든 0, IQ가 0이라고 지능이 0은 아니다. -
비율 변수 : 특성에 서열 + 상대적인 차이 + 절대 영점
'0'의 의미 : 절대적인 0으로 존재, 소득이 0이면 0이고 무게가 0이면 0이다.
예시 - 연령 / 무게 / 시간 / 거리 / 소득 / 교역량
이산변수 - 연속변수
이산변수 - 하나하나 셀 수 있는 정수값을 가지는 변수- 학생 '수'
연속변수 - 소수점 이하의 값을 가질 수 있는 변수 - 체중 키 온도
기술통계량
중심
평균 (mean)
전체합 / 전체 갯수
- 일반적으로 산술평균을 이르는 말
중위값(median)
자료를 작은값(큰 값)부터 정렬했을 때 빈도로 가운데에 놓이는 자료
- 어떤 주어진 값들을 크기의 순서대로 정렬했을 때 가장 중앙에 위치하는 값을 의미
- 값이 짝수개일 때에는 중앙값이 유일하지 않고 두 개가 될 수도 있다. 이 경우 그 두 값의 평균을 취한다. 예를 들어 1, 10, 90, 200 네 수의 중앙값은 10과 90의 평균인 50이 된다.
- 이상치의 영향으로 왜곡되는 평균값을 대체하기 위해 사용
최빈값 (mode)
가장 빈도수가 많은 자료
- 유일한 값이 아닐 수 있다. ( 1, 2,2, 5,5)에서 최빈값은 2와 5
- 주어진 자료나 관측치의 값이 모두 다른 경우에는 존재하지 않는다.
- 평균이나 중앙값 구하기 어려운 경우에 이용
절사평균(Trimmed Mean)
가장 큰 부분과 작은 부분을 제거 후 평균을 산출
-
이상치가 존재하는 자료의 경우 이상치의 영향을 배재하기 위해서, 자료의 총 개수에서 일정비율만큼 가장 큰 부분과 작은 부분을 제거 후 평균을 산출한다.
-
10% 절사평균 : 상위 10% 하위 10% 위치한 값 삭제한 뒤 산술평균을 구한다.
-
20% 절사평균 : 상위 20%, 하위 20% 위치한 값 삭제한 뒤 산술평균을 구한다.
-
예시 : 올림픽 심사위원 최고점 최저점 제외하고 평균
산포도
범위 (Range)
최대값 - 최소값
- 최대값- 최소값이 이상치인 경우 왜곡되게 된다.
4분위수
전체 데이터를 4등분했을 때의 각 부분값 , 1/4, 2/4, 3/4 , 4/4
- 자주 사용되는 것은 1QR(1/4), 3QR(3/4)이 사용
- 사분위 범위 : 3QR- 1QR = 2Q
- 준사분위범위 : 사분위 범위의 절반, 분산도를 대략적으로 파악하는데 사용
- 2QR은 중앙값과 일치
분산
확률변수가 기댓값으로부터 얼마나 떨어진 곳에 분포하는지를 가늠하는 숫자
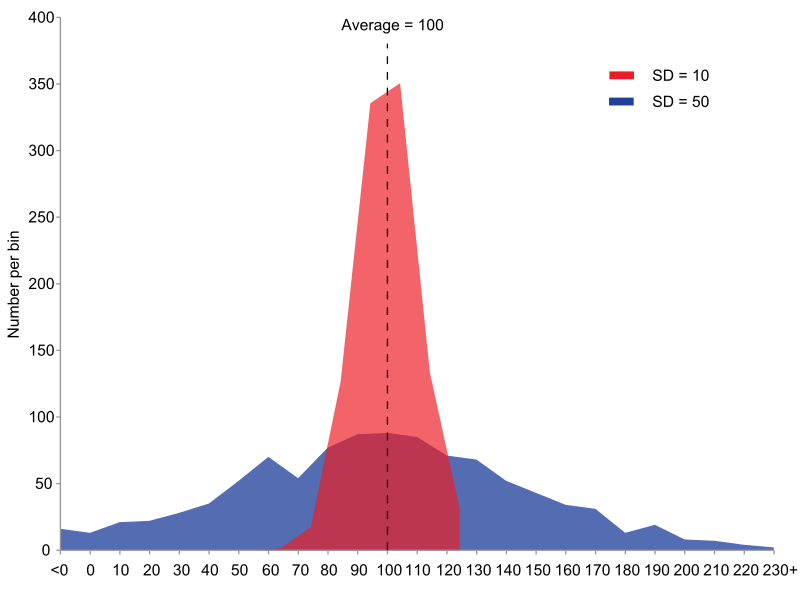

- 구하는 법 : 관측값에서 평균을 뺀 값을 제곱하고, 그것을 모두 더한 후 전체 개수로 나눠서 구한다. 즉, 차이값의 제곱의 평균이다. 관측값에서 평균을 뺀 값인 편차를 모두 더하면 0이 나오므로 제곱해서 더한다.
표준편차
분산의 음이 아닌 제곱근

- 모 표준 편차(population standard deviation )는 모집단의 표준 편차
- 표본 표준 편차(sample standard deviation) 는 표본의 표준 편차
평균절대편차 (mean absolute deviation)
평균과 개별 관측치 사이 거리의 평균
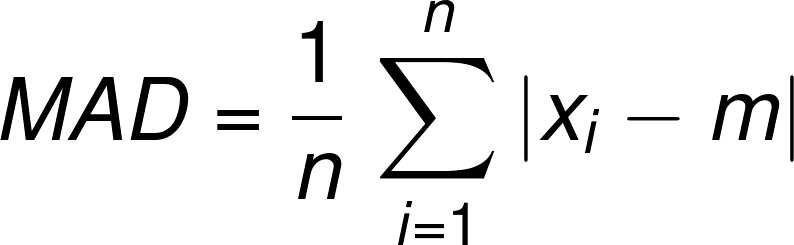
중위값절대편차 (median absolute deviation)
중위값과 개별 관측치 사이 거리의 평균
분포의 모양
첨도 (kurtosis)
확률분포의 꼬리가 두꺼운 정도를 나타내는 척도
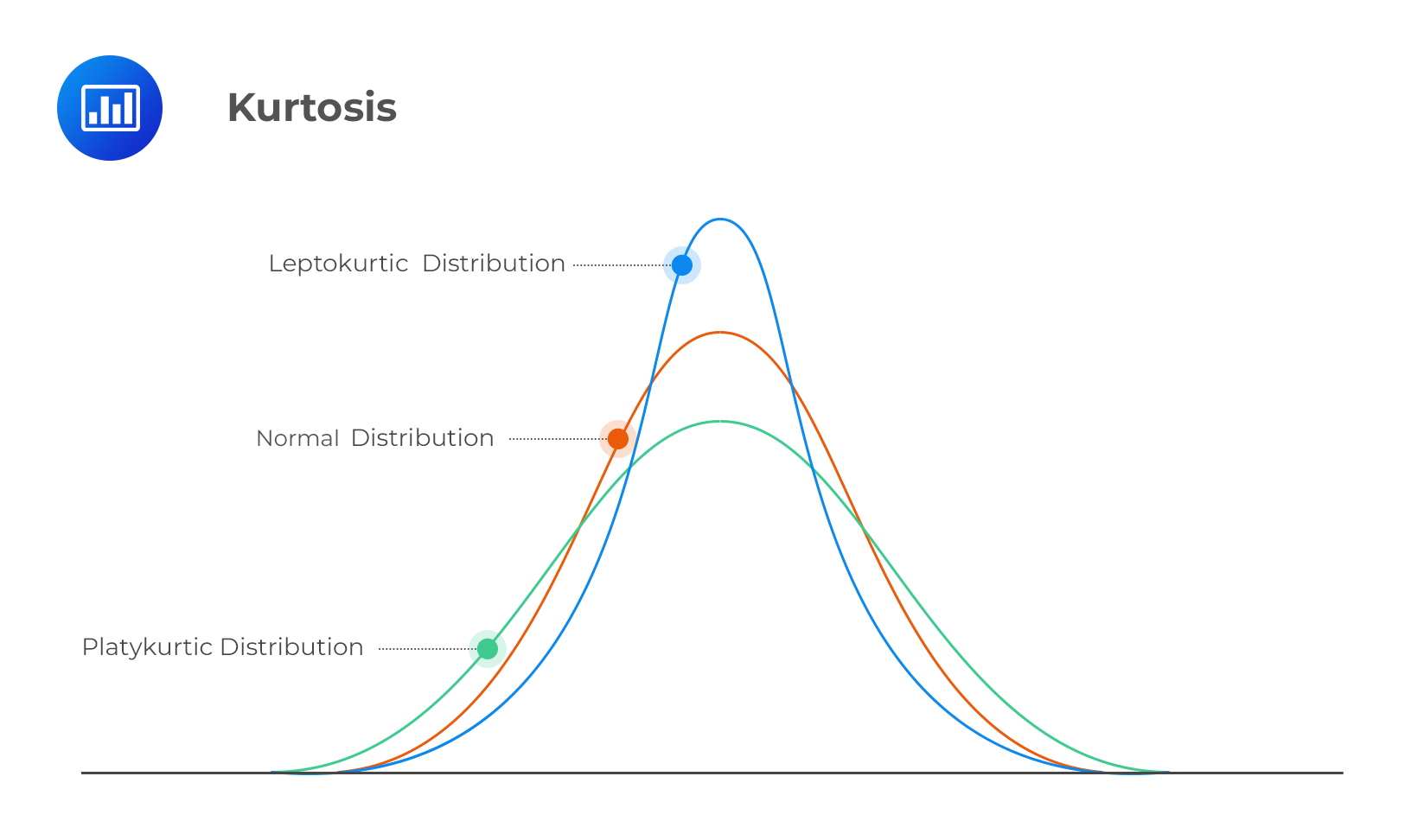
- k(첨도값) = 3이면 정규분포에 가깝다.
- k>3 : leptokurtosis (lepto-그리스어로 "날씬한", "가느다란")
- k < 3 : platykurtosis(platy - 그리스어로 "넓은", "뚱뚱한")
왜도 (Skewness)
분포가 정규분포에 비해 얼마나 비대칭인지 나타내는 척도

- 왜도 -2~ 2 정도는 (절대값 3미만) 왜도가 크지 않다고 판단.
- 왜도 > 0
왼쪽으로 몰려있음 - mode < median < mean - 왜도 < 0
오른쪽으로 몰려있음 - mean< median < mode - 조금 더 복잡한 방법이 있지만 pearson 비대칭 계수는 다음과 같다.
3(mean- medain)/ sd
참고 문서
위키백과
[강의정리] 기초통계2:기술통계량
검정
비모수 검정 / 모수 검정
기본개념
귀무가설
- 우리가 증명하고자 하는 가설의 반대되는 가설, 효과와 차이가 없는 가설을 의미
- 검정을 통해서 기각을 하는 것이 목적
- 예를 들어 기온과 아이스크림간의 상관관계가 있다고 증명을 하고싶다면 귀무가설은
H0 = 기온 과 아이스크림은 상관관계가 없다이다.
대립가설
-
연구와 실험을 통해서 입증, 규명하고자 하는 가설
-
양측 대립가설 : 두 집단은 같지 않다. (H1: A ≠ B)
-
단측 대립가설 : A집단이 B집단보다 크다 (H1: A > B)
1종오류/ 2종오류

- 1종오류 : H0 가
참- H0를기각 - 2종오류 : H0 가
거짓- H0를채택
유의확률(p-value)
-
귀무가설이 참이라 가정했을 때얻은 검정 통계량보다 크거나 같은 값을 얻을 수 있을 확률을 의미한다. -
통계분석의
sampling적인 특성에서 기인 -
모든 데이터를 확인할 수 없기 때문에 샘플을 뽑아서 해당 데이터에 관해서만 분석을 진행
-
뽑아온 데이터의 평균이 실제 모평균과는 다를 가능성이 존재!
-
유의확률의 정의는 두가지 부분으로 구성
귀무가설이 참이라 가정/얻은 검정 통계량보다 크거나 같은 값을 얻을 수 있을 확률 -
확률이 낮은 사건이 일어난 경우우연히 일어났다고 가정하기 보다는일어날만한 이유가 있었을 것이다라고 생각을 하게 된다. -
그러면
평균과는 차이가 큰 자료가 낮은 확률로 샘플링되었다(확률이 낮은 사건) 면 이 경우평균이 잘못되었다(귀무가설이 잘못되었다)생각을 하여 귀무가설을 기각하고 대립가설을 채택하게 되는 것이다.
참고 : https://adnoctum.tistory.com/332
집단 간 비교 검증
모집단의 평균에 대한 검정
t-검정
- 모집단의 수가 1개/2개일 때
- 대응 표본 : 모집단의 수가 1개라면 일정한 조건이 바뀐 경우 전/후를 비교
- 독립 표본 : 모집단의 수가 2개라면 동일한 시점의 두 집단의 결과를 비교
- 30개 이하의 검정에 사용 -> 30개 초과는 정규분포에 가까워져 z 검정 가능
- 모집단의 표준편차(σ) 를 알 수 없을 때 사용 ( 표본의 표준편차 s) 사용
참고 : https://m.blog.naver.com/sendmethere/221333164258
z- 검정
- 표본 크기가 30보다 클 때 사용
- 데이터가 서로 독립적 (데이터가 서로 영향 주지 않음)
- 각각의 데이터는 모집단에서 동일한 확률로 선택
참고 : https://bioinformaticsandme.tistory.com/186
분산분석
- 모집단의 수가 3개 이상일 때
- t-test를 여러번 사용하면 1종오류가 증가하게 됌(다중검정오류- 가설의 갯수 * 잘못된 판단 확률(유의확률) = 가설의 수에 따라 1종오류 범활 확률 늘어남)
- 종류
- 일원분산분석 : 독립변인 1개 --> 종속변인 1개
- 이원분산분석 : 독립변인 2개 --> 종속변인 1개
- 다원변량분산분석 : 독립변인 1개 --> 종속변인 2개 /독립변인 2개 --> 종속변인 2개
- 공분산분석 : 특정 독립변인 중점 , 나머지는 공변량
- 사후검정이 필요 : 집단 간 평균이 서로 같지 않다는 것은 알 수 있지만 집단이 서로 어디와 차이나는 지는 확인이 안되기 때문에 ( Tukey 검정, Scheff검정, 최소유의차검정(LSD)
모집단의 분산에 대한 검정
카이제곱 검정(교차분석)
- 모집단의 수가 1개일 때
F검정
모집단의 수가 2개 이상일 때
변수 간 관련성 검증
상관분석
-
두 변수간의 상관관계를 분석
-
상관계수( -1<=r<=1 )를 통해 얼마나 관련이 되어있는 지 확인 가능
-
r > 0 : 양의 상관관계
-
r =0 0 : 상관관계 없음
-
r > 0 : 음의 상관관계
회귀분석
- 두 변수간의 인과관계를 분석
- 결정계수 (R^2) 가 1의 가까울수록 예측이 잘된 회귀모형
- 결정계수 : 독립변수가 종속변수를 얼마나 설명하는지 ( 실제 관측치와 회귀모형의 차이)
.jpeg)