
7-1 인공 신경망
학습 목표
- 딥러닝과 인공 신경망 알고리즘을 이해하고 텐서플로를 사용해 간단한 인공 신경망 모델을 만들어 봅니다.
1) 패션 MNIST 데이터 확인
📕 데이터 준비
- 데이터 불러오기
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
▶
(60000, 28, 28) (60000,)
print(test_input.shape, test_target.shape)
▶
(10000, 28, 28) (10000,)- 결과
train set과 test set은 각각 60,000개, 10,000개의 이미지로 이루어져 있으며,
각 이미지의 크기는 28*28이다.
📕 데이터 확인
- 이미지 시각화
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1,10,figsize=(10,10))
for i in range(10) :
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off') # on일시 격자와 격자의 크기가 나타남
plt.show();-
결과 이미지

-
이미지별 target 확인
print([train_target[i] for i in range(10)])
▶
[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]- 레이블 당 데이터 개수 확인
import numpy as np
print(np.unique(train_target, return_counts=True))
▶
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))- 각 레이블의 의미
- 샘플 개수는 레이블별 6,000개씩 총 60,000개
| 레이블 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 패션 아이템 | 티셔츠 | 바지 | 스웨터 | 드레스 | 코트 | 샌달 | 셔츠 | 스니커즈 | 가방 | 앵클 부츠 |
2) 로지스틱 회귀로 패션 아이템 분류하기
📕 데이터 전처리
-
패션 MNIST 데이터의 train set은 60,000개나 되기 때문에
샘플을 하나씩 꺼내서 모델을 훈련하는 방법이 더 효율적으로 보인다.
따라서 확률적 경사 하강법을 사용할 것이다. -
패션 MNIST의 경우 각 픽셀은 0~255 사이의 정숫값을 가지므로 픽셀마다 256으로 나누어 0~1 사이의 값으로 정규화한다.
-
사이킷런 모델은 2차원 numpy 배열만 사용가능하기에 3차원인 데이터를 2차원으로 reshape해주어야 한다.
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
print(train_scaled.shape)
▶
(60000, 784)- 결과
0~1 사이의 값을 갖는 784개의 픽셀로 이루어진 60,000개의 샘플 준비 완료
📕 모델링 및 성능 확인
- 교차 검증을 통한 성능 확인
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1) # 기본값은 1이고 -1로 모든 코어를 사용
print(np.mean(scores['test_score']))
▶
0.8195666666666668- 결과
반복횟수(max_iter)를 늘려도 성능이 크게 향상되지는 않는다.
과소적합으로 인해 모델 성능이 잘 나오지 않음
❗ discussion
로지스틱 회귀 공식은 다음과 같다
이 식을 패션 MNIST 데이터에 맞게 변형하면 다음과 같다.
9개의 레이블이 있으므로 9개의 z값을 구하는 선형 방정식이 존재한다.
모든 레이블의 선형 방정식은 동일한 784개의 픽셀값을 그대로 사용하지만,
해당 레이블에 대한 출력을 계산하기 위해 가중치(계수)와 절편은 다른 값을 사용한다.
3) 인공 신경망
📕 인공 신경망이란?
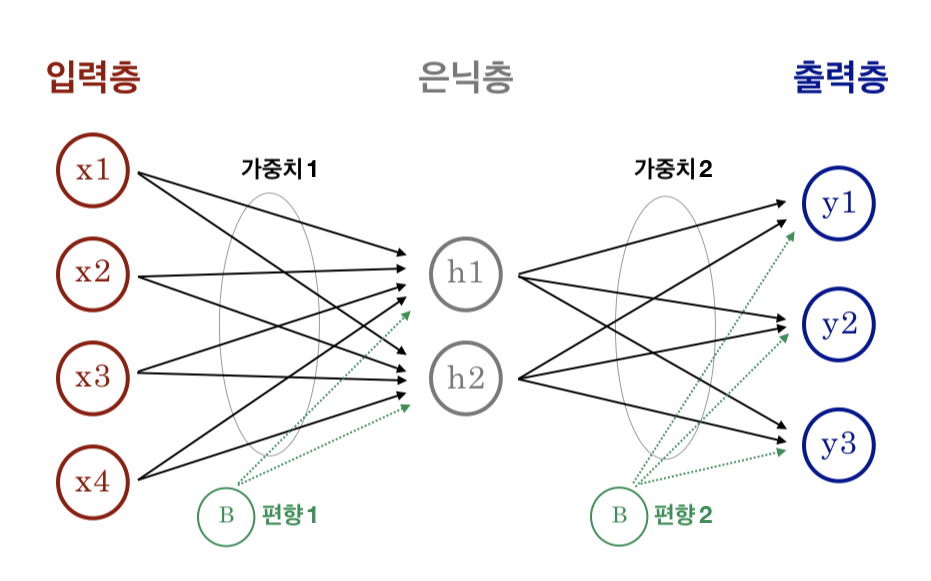
입력층이라고 부르는 각 픽셀에 있는 데이터를 통해 ~을 계산하고 이를 바탕으로 클래스를 예측하기 때문에 신경망의 최종 값을 만든다는 의미에서 출력층이라고 부른다.(지금은 중간 은닉층은 생략한다.)
📕 인공 신경망으로 모델 만들기
- 데이터 준비
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
print(train_scaled.shape, train_target.shape)
▶
(48000, 784) (48000,)
print(val_scaled.shape, val_target.shape)
▶
(12000, 784) (12000,)- 밀집층 생성 및 신경망 모델링
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,)) # 뉴런 개수(클래스 개수), 적용할 함수, 입력 크기(input data 크기)
# 이 밀집층을 가진 신경망 모델 만들기
model = keras.Sequential(dense)-
밀집층 모식도
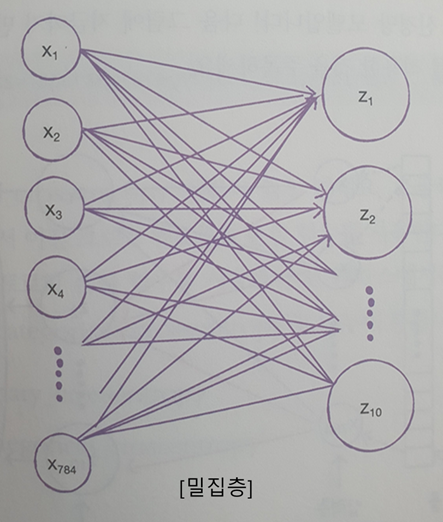
-
Sequential 클래스의 객체로 만들어진 인공 신경망 모델 모식도
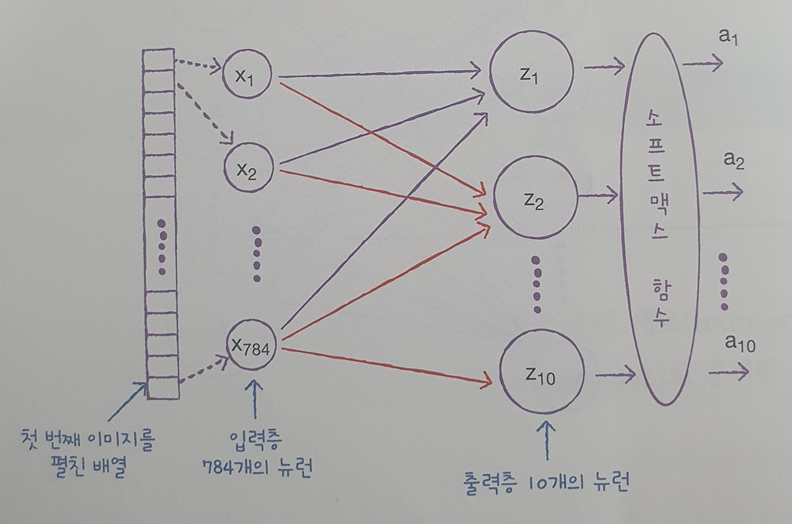
📕 인공 신경망으로 패션 아이템 분류하기
- compile() 메서드 이용 손실 함수 지정
model.compile(loss='sparse_cateorical_crossentropy', metrics='accuracy')❗ discussion
'sparse~' 손실 함수는 원-핫 인코딩을 하지 않은 타깃값에 대한 크로스 엔트로피 손실함수이다.
원-핫 인코딩을 진행한 경우엔 'categorical_crossentropy'로 지정해준다.
- 모델에 train set 훈련
model.fit(train_scaled, train_target, epochs=5)
▶
Epoch 1/5
1500/1500 [==============================] - 6s 2ms/step - loss: 0.6146 - accuracy: 0.7919
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4796 - accuracy: 0.8387
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4583 - accuracy: 0.8475
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4447 - accuracy: 0.8520
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4364 - accuracy: 0.8551
<keras.callbacks.History at 0x7f46cc3c2690>-
결과
epoch가 지남에 따라 정확도가 점점 높아진다. -
test set에 대한 모델 성능 확인
model.evaluate(val_scaled, val_target)
▶
375/375 [==============================] - 1s 2ms/step - loss: 0.4467 - accuracy: 0.8487
[0.4467184543609619, 0.8487499952316284]-
결과
train set의 정확도보다 약간 낮은 84%의 정확도를 나타냈다.
로지스틱 회귀 모델의 정확도인 82%보다 약간 높게 나타난다. -
사이킷런 모델과 케라스 모델의 구성 코드 차이

📕 키워드 정리
인공신경망
생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘으로 종종 딥러닝이라고도 불린다.
텐서플로
구글이 만든 딥러닝 라이브러리로, CPU와 GPU를 사용해 인공 신경망 모델 구축과 서비스에 필요한 다양한 도구를 제공한다.
밀집층
가장 간단한 인공 신경망의 층으로 여러 종류의 층이 있으며 밀집층에서는 뉴런들이 모두 연결되어 있기 때문에 완전 연결 층이라고도 부른다.
특히 출력층에 밀집층을 사용할 때는 분류하려는 클래스와 동일한 개수의 뉴런을 사용한다.
원-핫 인코딩
정수값을 배열에서 해당 정수 위치의 원소만 1이고 나머지는 모두 0으로 변환한다.
7-2 심층 신경망
학습 목표
- 인공 신경망에 층을 여러개 추가하여 패션 MNIST 데이터셋을 분류하면서
케라스로 심층 신경망을 만드는 방법을 자세히 배웁니다.
1) 은닉층 생성
📕 데이터 준비
- 패션 MNIST 데이터 불러오기
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()- train set, test set 나누기
from sklearn.model_selection import train_test_split
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1,28*28)
train_scale, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)📕 인공 신경망 모델에 층 추가
- 입력층과 출력층 사이에 은닉층이라는 밀집층을 추가해보자.
- 이때 은닉층과 함께 활성화 함수층도 추가가 된다. 은닉층의 활성화 함수는 비교적 자유롭게 선택이 가능하며 대표적으로 시그모이드 함수와 렐루 함수 등을 사용한다.
❗ discussion
클래스 분류를 위한 확률을 출력하기 위해 활성화 함수를 사용하기에
회귀의 출력은 임의의 숫자이므로 활성화 함수를 적용할 필요가 없다.
Dense 층의 activation 매개변수에 아무런 값을 지정하지 않고 출력층의 선형 방정식 계산을 그대로 출력한다.
- 시그모이드 활성화 함수를 사용한 은닉층과 소프트맥스 함수를 사용한 출력층 생성
# dense1 : 100개의 뉴런을 가진 밀집층인 은닉층. 활성화 함수는 'sigmoid', dlqfurrkqtdms (784,)
dense1 = keras.layers.Dense(100,activation='sigmoid', input_shape=(784,))
# dense2 : 10개의 클래스를 구분하는 10개의 뉴런을 가진 출력층. 활성화 함수는 'softmax
dense2 = keras.layers.Dense(10, activation='softmax')- 은닉층을 추가한 모델 모식도
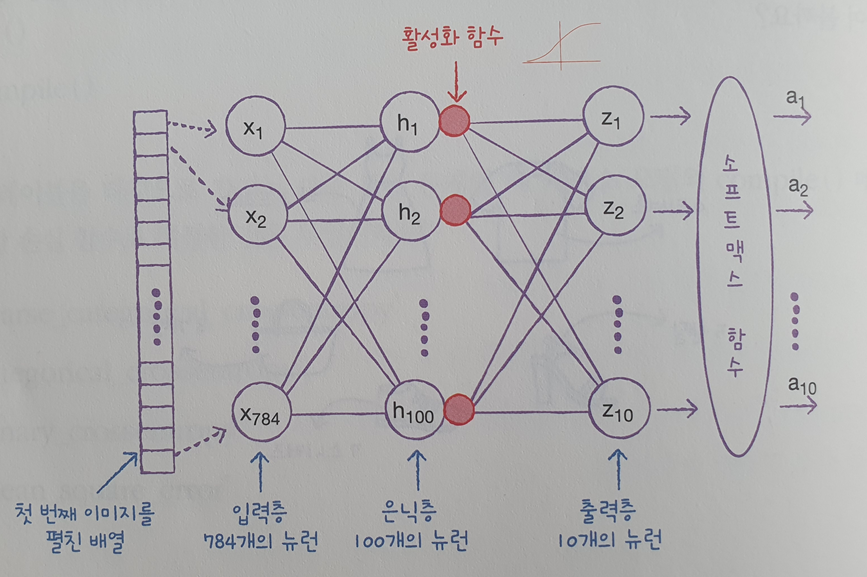
📕 심층 신경망 만들기
- Sequential 클래스 활용 심층 신경망 만들기
# 은닉층 -> 출력층 순서로 기입
model = keras.Sequential([dense1,dense2])
model.summary()
▶
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 100) 78500 # 784*100 + 100(절편)
dense_3 (Dense) (None, 10) 1010 # 100*10 + 10(절편)
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________- Sequential 클래스의 생성자 안에서 바로 밀집층 만들기
model = keras.Sequential([keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')], name = '패션 MNIST 모델')
model.summary()
▶
Model: "패션 MNIST 모델"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hidden (Dense) (None, 100) 78500
output (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________❗ discussion
생성자 안에서 바로 Dense 클래스의 객체를 만들면 모델의 이름과 층 이름을 설정해줄 수 있어서 많은 층을 사용할때 유용하다.
- Sequential 클래스 객체에 밀집층 추가하기
model = keras.Sequential()
model.add(keras.layers.Dense(100,activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(100,activation='softmax'))
model.summary()
▶
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 100) 78500
dense_7 (Dense) (None, 100) 10100
=================================================================
Total params: 88,600
Trainable params: 88,600
Non-trainable params: 0
_________________________________________________________________- 모델 훈련
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
▶
Epoch 1/5
1500/1500 [==============================] - 6s 2ms/step - loss: 0.6142 - accuracy: 0.7984
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4115 - accuracy: 0.8519
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3766 - accuracy: 0.8631
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3535 - accuracy: 0.8725
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3379 - accuracy: 0.8776
<keras.callbacks.History at 0x7fb6407ed7d0>- 결과
앞서 두개의 층만으로 만들었던 모델의 정확성(0.8487)에 비해
은닉층을 추가한 모델의 정확성(0.8776)이 높아졌다.
2) ReLU & Flatten
📕 ReLU 함수
-
은닉층의 활성화 함수로 시그모이드 함수를 쓰게 된다면
오른쪽, 왼쪽 끝의 그래프가 완만하기 때문에 올바른 출력을 만드는데 대응이 신속하지 못하고, 특히 층이 많을 수록 그 효과가 누적되어 학습이 어려워진다. -
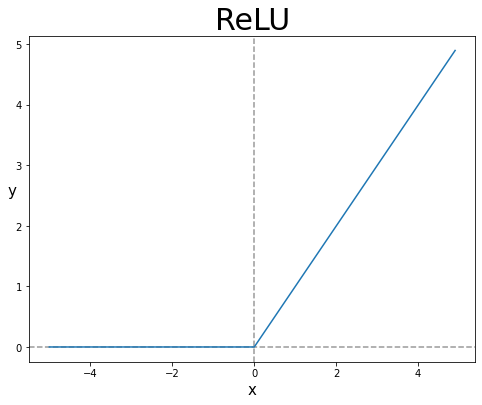
이러한 단점을 극복하기 위해 렐루라는 활성화 함수가 등장하였다.
입력이 양수일 경우 그대로 통과시키고, 음수의 경우 0으로 만드는 함수이다.
📕 Flatten
- 배치 차원을 제외한 나머지 입력 차원을 모두 일렬로 펼치는 함수로,
입력에 곱해지는 가중치나 절편이 없다.
Flatten 층은 입력층 바로 뒤에 추가해야한다.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
▶
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_12 (Dense) (None, 100) 78500
dense_13 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________-
결과
flatten 클래스의 모델 파라미터는 0개이다.
flatten 층을 모델에 추가하면, 앞서 모델들에서 볼 수 없던 입력값의 차원을 확인 가능하다. -
reshape하지 않은 훈련 데이터들 다시 준비해서 모델을 훈련해보자.
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
▶
Epoch 1/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.5292 - accuracy: 0.8123
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3903 - accuracy: 0.8588
Epoch 3/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.3525 - accuracy: 0.8749
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3345 - accuracy: 0.8812
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3185 - accuracy: 0.8863
<keras.callbacks.History at 0x7fb6300a8950>
# 검증 set 성능 확인
model.evaluate(val_scaled, val_target)
▶
375/375 [==============================] - 1s 3ms/step - loss: 0.3520 - accuracy: 0.8783
[0.3519577980041504, 0.878250002861023]- 결과
train set 정확성, val set 정확성이 각각 0.8863, 0.8783으로 또 높아졌다.
3) 옵티마이저
- 하이퍼파라미터 중 하나인 손실함수를 지정해주는 메서드인 compile()을 통해 여러 경사 하강법 알고리즘 중 하나를 선택 가능하다
이들을 옵티마이저라고 한다.
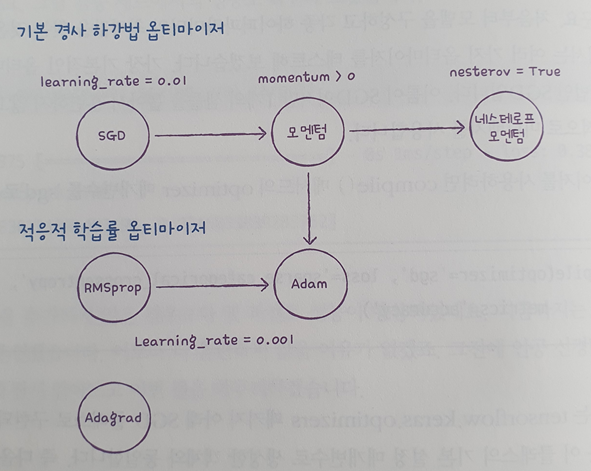
케라스의 기본 경사하강법 알고리즘은 RMSprop 이다.
📕 SGD 옵티마이저
- 가장 기본적인 옵티마이저인 확률적 경사하강법(SGD)
- 이름은 SGD이지만 기본적으로 미니배치를 사용한다.
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
# 위 방법은 tensorflow.keras.optimizers 패키지 아래 구현된 SGD 클래스와 동일하다.
sgd = keras.optimizers.SGD() # learning_rate=0.1 과 같은 식으로 매개변수 지정 가능
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')❗ discussion
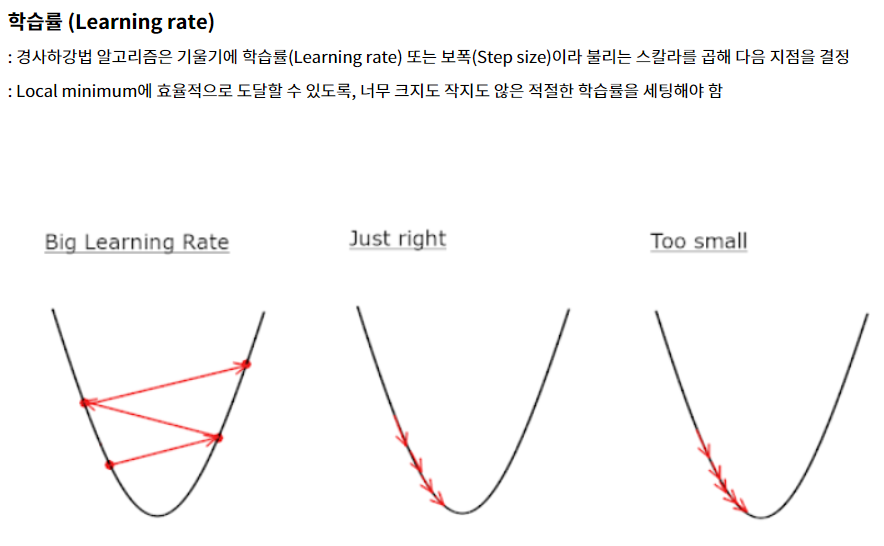
학습률의 개념
-
주로 사용하는 옵티마이저들은 다음과 같다
-
기본 경사 하강법 옵티마이저는 모두 SGD 클래스에서 제공한다.
SGD 클래스의 momentum 매개변수의 기본값은 0이다.
이를 0보다 큰 값으로 지정하면 이전의 그레디언트를 가속도처럼 사용하는 모멘텀 최적화를 사용한다. 보통 momentum 매개변수는 0.9 이상을 지정한다.
📕 네스테로프 모멘텀 최적화
- SGD 클래스의 nestrov 매개변수를 기본값 False에서 True로 바꾸면 네스테로프 모멘텀 최적화을 사용한다.
- 네스테로프 모멘텀은 모멘텀 최적화를 2번 반복하여 구현한다.
- 대부분의 경우 네스테로프 모멘텀 최적화가 기본 SGD보다 더 나은 성능을 보인다.
sgd = keras.optimizers.SGD(momentum = 0.9, nesterov = True)📕 적응적 학습률
-
모델이 최적점에 가까이 갈수록 학습률(보폭)을 낮춘다면
이를 통해 안정적으로 최적점에 수렴할 것이다.
이런 학습률을 적응적 학습률이라고 한다. -
이 방식은 학습률 매개변수를 튜닝하는 수고를 덜 수 있다.
-
RMSprop(옵티마이저 기본값)
rmsprop = keras.optimizers.RMSprop()
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy',
metrics = 'accuracy')- Adagrad 옵티마이저
adagrad = keras.optimizers.RMSprop()
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy',
metrics = 'accuracy')📕 Adam optimizer
- 모멘텀 최적화와 RMSprop의 장점을 접목한 것이 Adam이다.
- 많은 딥러닝 모델에서 널리 사용되고 있는 옵티마이저이다.
- 모델링
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
▶
[31]
17초
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Epoch 1/5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.5287 - accuracy: 0.8166
Epoch 2/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3953 - accuracy: 0.8585
Epoch 3/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3553 - accuracy: 0.8707
Epoch 4/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3264 - accuracy: 0.8805
Epoch 5/5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3070 - accuracy: 0.8859
<keras.callbacks.History at 0x7fb5c204ebd0>- 모델 평가
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 1s 3ms/step - loss: 0.3459 - accuracy: 0.8747
[0.3459301292896271, 0.874666690826416]- 결과
train set, test set 각각 0.8859, 0.8747로 0.8863, 0.8783으로 소폭 정확성이 하락했으나, 통상적으로 RMSporp 보다 조금 나은 성능을 낸다고 알려져있다.
📕 키워드 정리
심층 신경망
2개 이상의 층을 포함한 신경망.
렐루 함수
이미지 분류 모델의 은닉층에 많이 사용하는 활성화 함수이다.
시그모이드 함수는 층이 많을수록 활성화 함수의 양쪽 끝에서 변화가 작기 때문에 학습이 어려워진다.
옵티마이저
신경망의 가중치와 절편을 학습하기 위한 알고리즘 또는 방법으로,
케라스에는 다양한 경사 하강법 알고리즘이 구현되어 있다.
대표적으로 SGD, 네스테로프 모멘텀, RMSprop, Adam 등이 있다.
7-3 신경망 모델 훈련
학습 목표
- 인공 신경망 모델을 훈련하는 모범 사례와 필요한 도구들을 살펴본다.
- 이런 도구들을 다뤄보면서 텐서플로와 케라스 API에 더 익숙해지자.
1) 손실 곡선
📕 데이터 준비 및 모델링
- 패션 MNIST 데이터 불러오기
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
▶
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
40960/29515 [=========================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 0s 0us/step
26435584/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
16384/5148 [===============================================================================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
4431872/4422102 [==============================] - 0s 0us/step- modeling 함수 만들기
def model_fn(a_layer=None) :
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
if a_layer :
model.add(a_layer)
model.add(keras.layers.Dense(10,activation='softmax'))
return model
model = model_fn()
model.summary()
▶
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 100) 78500
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________- 손실 함수 정한 후 fit() 메서드의 결과를 history 변수에 초기화
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=5, verbose=0)
print(history.history.keys())
▶
dict_keys(['loss', 'accuracy'])- 결과
history 객체에는 훈련 측정값이 담겨있는 history 딕셔너리가 들어있고,
이 딕셔너리에는 손실과 정확도가 포함되어 있다.
케라스는 기본적으로 에포크마다 손실을 계산한다.
❗ discussion
verbose 매개변수는 훈련 과정 출력을 조절한다.
기본값은 1로, 에포크마다 진행 막대와 함께 손실 등의 지표가 출력된다.
0은 훈련과정 표시 X, 2는 진행 막대 빼고 출력을 의미한다.
📕 history 객체 시각화
- matplotlib 활용 epoch별 손실 확인
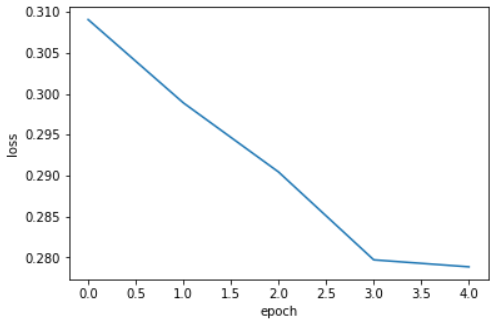
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show();-
결과 이미지
-
matplotlib 활용 epoch별 정확도 확인
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show();-
결과 이미지
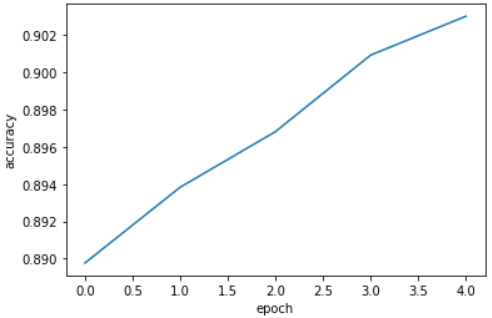
-
결과
에포크마다 손실이 감소하고 정확도가 향상한다. -
에포크 횟수를 20으로 늘려서 모델을 훈련하고 손실 그래프를 그려보자.
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0)
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show();-
결과 이미지
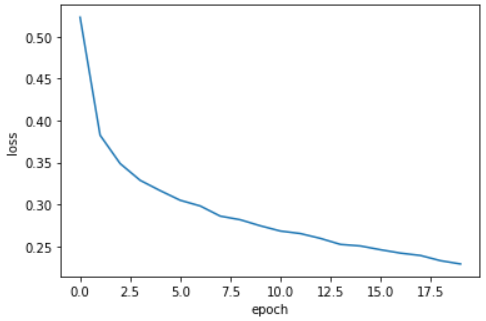
-
결과
에포크가 5일때보다 손실이 잘 감소하며 최종 손실도 작다.
2) 검증 손실
📕 validation set 손실 곡선 확인
- 확률적 경사 하강법으로 최적화된 인공 신경망에서 에포크에 따른 과대적합과 과소적합을 파악하려면, train set에 대한 점수 뿐만 아니라 val set(검증 세트)에 대한 점수도 필요하다.
- 각 set에 대한 에포크에 따른 손실 함수의 예상 모식도는 다음과 같다.
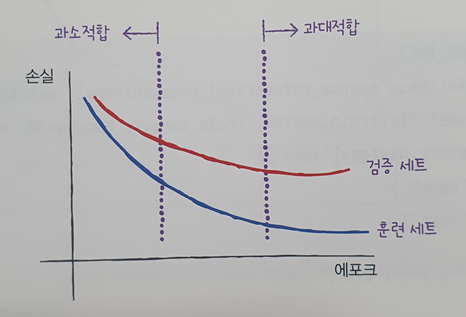
❗ discussion
인공 신경망 모델이 최적화하는 대상은 정확도가 아니라 손실 함수기 때문에,
손실 감소에 비례하여 정확도가 높아지지는 않는다.
따라서 모델의 훈련도를 판단하려면 정확도보다는 손실 함수의 값을 확인해야한다.
- validation set 모델 훈련 및 손실 시각화
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
print(history.history.keys())
▶
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
plt.plot(history.history['loss'], label='train set')
plt.plot(history.history['val_loss'], label='validation set')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show();- 결과 이미지
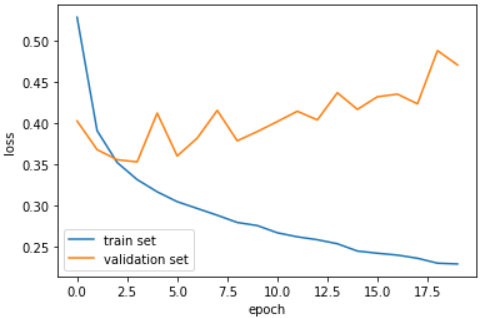
- 결과
초기에 검증 손실이 감소하다가 세번째 에포크만에 다시 상승하기 시작한다.
그에 반해 훈련 손실은 꾸준히 감소하기 때문에 과대적합 모델이 만들어진다.
❗ discussion
검증 손실이 상승하는 시점을 뒤로 늦추면 검증 set의 손실과 정확도가 모두 증가할 것이다.
3) generalization(과대적합 방지)
📕 옵티마이저 변경
- 기본 RMSprop 옵티마이저에서 Adam 옵티마이저 변경
* Adam은 적응적 학습률을 사용하기 때문에 에포크가 진행되면서 학습률의 크기를 조정할 수 있다.
model = model_fn()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show();- 결과 이미지
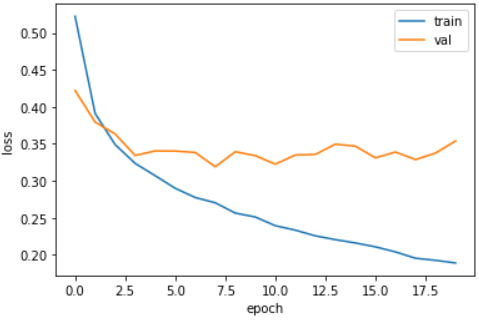
- 결과
검증 손실 그래프에 여전히 요동이 남아있지만 열번째 에포크까지 전반적인 감소 추세가 이어지고 있다.
이를 통해 Adam 옵티마이저가 이 데이터셋에 잘 맞는다는 것을 보여준다.
📕 드롭아웃
-
훈련 과정에서 층에 있는 일부 뉴런을 임의로 꺼서 가중치에 대한 과한 의존성을 줄일 수 있다.
-
샘플 마다 드롭아웃되는 뉴런이 달라지게 된다. 꺼지는 뉴런의 수는 drop rate라는 하이퍼 파라미터로 조정가능하다.
-
평가나 예측을 수행할 때는 훈련된 모델이 자동으로 드롭아웃을 적용하지 않는다.
-
dropout 층 추가
model = model_fn(keras.layers.Dropout(0.3))
model.summary()
▶
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_6 (Flatten) (None, 784) 0
dense_12 (Dense) (None, 100) 78500
dropout_1 (Dropout) (None, 100) 0
dense_13 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________-
결과
은닉층 뒤에 추가된 드롭아웃 층은 모델 파라미터가 존재하지 않으며 출력을 0으로 만들지만 전체 출력 배열의 크기를 바꾸지는 않는다. -
손실 곡선 시각화
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='val')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show();- 결과 이미지
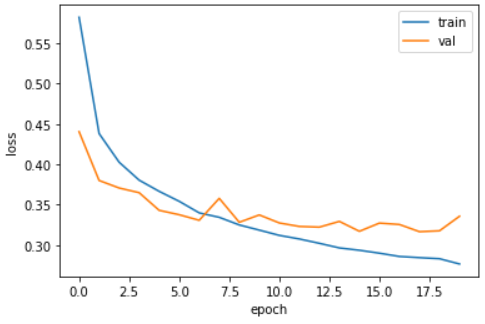
- 결과
과대적합이 확실히 줄어들었다.(두 data set간 손실점수 차이가 줄어듦)
4) 모델 저장과 복원
📕 파라미터 및 모델 구조 저장
- 과대적합 방지를 위해 에포크 횟수를 10으로 줄여서 재훈련
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=10, verbose=0, validation_data=(val_scaled, val_target))- 저장(save_weights vs save)
# 모델의 파라미터를 저장
model.save_weights('model-weights.h5')
# 모델 구조와 모델 파라미터를 함께 저장
model.save('model-whole.h5')
# 저장된 파일 확인
!ls -al *.h5
▶
-rw-r--r-- 1 root root 333448 Sep 5 17:56 model-weights.h5
-rw-r--r-- 1 root root 982664 Sep 5 17:56 model-whole.h5📕 모델 파라미터 읽어서 사용하기
- 훈련을 하지 않은 새로운 모델을 만들고 훈련된 모델 파라미터를 읽어서 사용하기
model = model_fn(keras.layers.Dropout(0.3))
model.load_weights('model-weights.h5')- 검증 정확도 확인을 위해 predict() 메서드 사용
해당 메서드는 샘플마다 10개의 클래스에 대한 확률을 반환한다.
따라서 검증 세트의 12,000개 샘플에 대해 각각 10개 클래스의 대한 확률을 반환하므로
총 (12000,10) 크기의 배열을 반환한다. - 10개의 확률 중에서 가장 큰 값의 인덱스를 골라 타깃 레이블과 비교하여 정확도를 계산해보자.
import numpy as np
val_labels = np.argmax(model.predict(val_scaled), axis=-1) # 배열에서 가장 큰 값의 인덱스를 반환
print(np.mean(val_labels == val_target))
▶
0.8814166666666666📕 모델 구조를 가져와서 사용하기
model = keras.models.load_model('model-whole.h5')
model.evaluate(val_scaled, val_target)
▶
375/375 [==============================] - 1s 2ms/step - loss: 0.3330 - accuracy: 0.8814
[0.3329712748527527, 0.8814166784286499]- 결과
같은 모델을 저장하고 다시 불러들였기 때문에 위와 동일한 정확도를 얻었다.
5) 콜백
📕 모델에 콜백 적용
- 콜백은 훈련 과정 중간에 어떤 작업을 수행할 수 있게 하는 객체로,
keras.callbacks 패키지 아래에 있으며, fit()메서드의 callbacks 매개변수에 리스트로 전달 한다. - save_best_only=True 매개변수를 지정하여 최적의 모델을 저장한다.
# 드롭아웃 층 포함한 모델 생성
model = model_fn(keras.layers.Dropout(0.3))
# 모델 옵티마이저, 손실함수, 측정값 입력
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
# 콜백 체크포인트 저장
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5', save_best_only=True)
# 모델 훈련
model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb])- 모델 훈련 후 최상의 검증 모델을 읽어와서 예측 수행
model = keras.models.load_model('best-model.h5')
model.evaluate(val_scaled, val_target)
▶
375/375 [==============================] - 1s 2ms/step - loss: 0.3178 - accuracy: 0.8889
[0.31775301694869995, 0.8889166712760925]📕 조기종료
-
콜백을 통해 최적의 모델을 찾은 후에는 남은 에포크를 진행할 필요가 없다.
이렇게 과대적합이 시작되기 전에 훈련을 미리 중지하는 것을 조기종료 라고 한다. -
keras에는 조기 종료를 위한 EarlyStopping 콜백을 제공한다.
- patience 매개변수 : 검증 점수가 향상되지 않더라도 중지하지 않고 계속 진행할 에포크 횟수이다.- restore_best_weights 매개변수 : True 지정 시 최적의 모델 파라미터로 되돌린다.
-
EarlyStopping 콜백과 ModelCheckpoint 콜백을 모두 사용
# 드롭아웃 층 포함한 모델 생성
model = model_fn(keras.layers.Dropout(0.3))
# 모델 옵티마이저, 손실함수, 측정값 입력
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
# 콜백 체크포인트 저장
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5', save_best_only=True)
# 콜백 얼리스타핑 설정
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
# 모델 훈련
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
# 몇번째 에포크에서 훈련이 중지되었는지 확인
print(early_stopping_cb.stopped_epoch)
▶
7- 훈련 손실과 검증 손실 확인
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show();-
결과 이미지
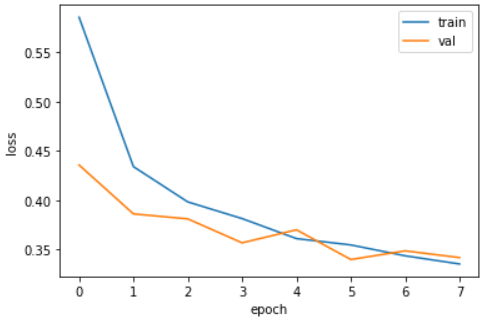
-
결과
patience = 2이므로 최상의 모델은 5번째 에포크일 것이고,
실제 훈련 및 검증 손실 그래프에서도 5번째 에포크에서 모델 성능이
손실 점수가 낮고 과대적합과 과소적합의 사이에 형성되어있다. -
검증 세트에 대한 성능 확인
model.evaluate(val_scaled, val_target)
▶
375/375 [==============================] - 1s 4ms/step - loss: 0.3399 - accuracy: 0.8757
[0.3398755192756653, 0.8756666779518127]📕 키워드 정리
드롭아웃
은닉층에 있는 뉴런의 출력을 랜덤하게 꺼서 과대적합을 막는 기법으로,
훈련 중에 적용되며 평가나 예측에서는 적용해선 안된다. 텐서플로는 이를 자동으로 처리한다.
콜백
케라스 모델을 훈련하는 도중에 어떤 작업을 수행할 수 있도록 도와주는 도구로
최상의 모델을 자동으로 저장해주거나, 검증 점수가 더이상 향상되지않으면 조기 종료를 할 수 있다.
조기 종료
검증 점수가 더 이상 향상되지 않고 과대적합이 일어나면 훈련을 계속 진행하지 않고 멈추는 기법이다.
