
📗 segmentation의 의미와 목적
Semantic Segmentation 의 정확한 의미와 목적을 알아보겠습니다. 컴퓨터 비젼의 가장 많이 다뤄지는 문제들은 아래와 같은 것들이 있습니다.
- Classification (분류): 인풋에 대해서 하나의 레이블을 예측하는 작업.
AlexNet, ResNet, Xception 등의 모델 - Localization/Detection (발견): 물체의 레이블을 예측하면서 그 물체가 어디에 있는지 정보를 제공. 물체가 있는 곳에 네모를 그리는 등
YOLO, R-CNN 등의 모델 - Segmentation (분할): 모든 픽셀의 레이블을 예측
FCN, SegNet, DeepLab 등의 모델
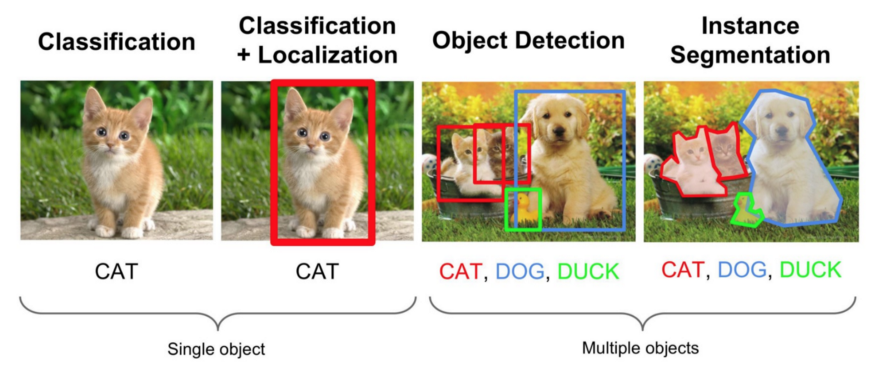
Semantic Image Segmentation의 목적은 사진에 있는 모든 픽셀을 해당하는 (미리 지정된 개수의) class로 분류하는 것입니다. 이미지에 있는 모든 픽셀에 대한 예측을 하는 것이기 때문에 dense prediction 이라고도 불립니다.
📗 R-CNN
R-CNN : Regions with CNN features
- 객체 탐지에 사용된 초기 모델
- 주요 객체를 바운딩 박스로 표현하여 정확히 식별하는게 목표
- 객체 탐지가 주요 목적 - Selective Search를 통해 다양한 크기의 박스를 만들고, region proposal 영역 생성
- region proposal 영역을 warp하여 표준화된 크기로 변환
- AlexNet을 개량한 CNN 모델을 이용하고, 마지막 층에 SVM을 통해 객체 분류
- warped region : 정사각형 형태로 바운딩박스를 변형한 것
- AlexNet 특징이 정방형이기 때문에 - SVM : 클래스 분류를 위한 벡터
📗 Fast-RCNN
- R-CNN의 단점인 느린 속보를 개선
- ROI(Region of Interest) 풀링을 통해 한 이미지의 subregion에 대한 forward pass 값을 공유
- R-CNN은 CNN 모델로 image feature를 추출, SVM 모델로 분류, Regressor 모델 bounding box를 맞추는 작업으로 분류되어 있지만, Fast R-CNN은 하나의 모델로 동작
- Top layer에 softmax layer를 둬서 CNN 결과를 class로 출력
- Box regression layer를 softmax layer에 평행하게 두어 bounding box 좌표를 출력
- ROI(Region of Interest)
- 이미지나 영상 내에서 관심있는 부분을 뜻한다.
이미지 상의 특정 오브젝트나 특이점을 찾는 것을 목표로 할 때 쓴다.
관심영역을 지정하여 불필요한 영역에 대한 이미지 처리를 방지할 수 있다.
📗 Faster-RCNN
- Fast R-CNN은 가능성 있는 다양한 bounding box들, 즉 ROI를 생성하는 과정인 selective search가 느려 region proposer에서 병목이 발생
- 이미지 분류(classification)의 첫 단계인 CNN의 forward pass를 통해 얻어진 feature들을 기반으로 영역을 제안
- CNN 결과를 selective search 알고리즘 대신 region proposal에 이용
- k개의 일반적인 비율을 지닌 anchor box를 이용하여 하나의 bounding box 및 score를 이미지의 위치별로 출력
📗 Mask-RCNN
- pixel 레벨의 세그멘테이션
- ROIPool에서 선택된 feature map이 원래 이미지 영역으로 약간 잘못된 정렬이 발생한 부분을 ROIAlign을 통해 조정하여 정확하게 정렬
- Mask R-CNN은 Mask가 생성되면, Faster R-CNN으로 생성된 classifiaction과 bounding box들을 합쳐 정확한 세그멘테이션 가능
📗 U-Net 기반 세그멘테이션
- 사용된 모델은 수정된 U-Net
- U-Net이라 불리는 인코더(다운샘플링)와 디코더(업샘플링)를 포함한 구조는 정교한 픽셀 단위의 segmentation이 요구되는
biomedical image segmentation task의 핵심요소 - Encoder-decoder 구조 또한 semantic segmentation을 위한 CNN 구조로 자주 활용
- Encoder 부분에서는 점진적으로 spatial dimension을 줄여가면서 고차원의 semantic 정보를 convolution filter가 추출해낼 수 있게 함(핵심 정보만 남기는 의미)
- Decoder 부분에서는 encoder에서 spatial dimension 축소로 인해 손실된 spatial 정보를 점진적으로 복원하여 보다 정교한 boundary segmentation을 완성
- U-Net은 기본적인 encoder-decoder 구조와 달리 spatial 정보를 복원하는 과정에서 이전 encoder feature map 중 동일한 크기를 지닌 feature map을 가져와 prior로 활용함으로써 더 정확한 boundary segmentation이 가능하게 함

개발도상인 냄비짱