SpoonOS는 여러 LLM 제공업체에 대한 통합 인터페이스를 제공합니다. 코드를 한 번만 작성하면, 단일 파라미터만 변경하여 OpenAI, Anthropic, Google, DeepSeek, 또는 OpenRouter 간에 전환할 수 있습니다. 코드 재작성도 필요 없고, API 차이를 처리할 필요도 없습니다.
왜 여러 제공업체를 사용해야 할까?
단일 LLM 제공업체에만 의존하는 것은 위험합니다:
- 서비스 중단 — OpenAI가 다운되면, 여러분의 앱도 다운됩니다
- 속도 제한 — 한계에 도달하면 요청이 실패합니다
- 비용 — 모델마다 가격이 다릅니다
- 능력 — 어떤 모델은 코드에 뛰어나고, 다른 모델은 분석에 뛰어납니다
SpoonOS는 다음과 같이 이 문제를 해결합니다:
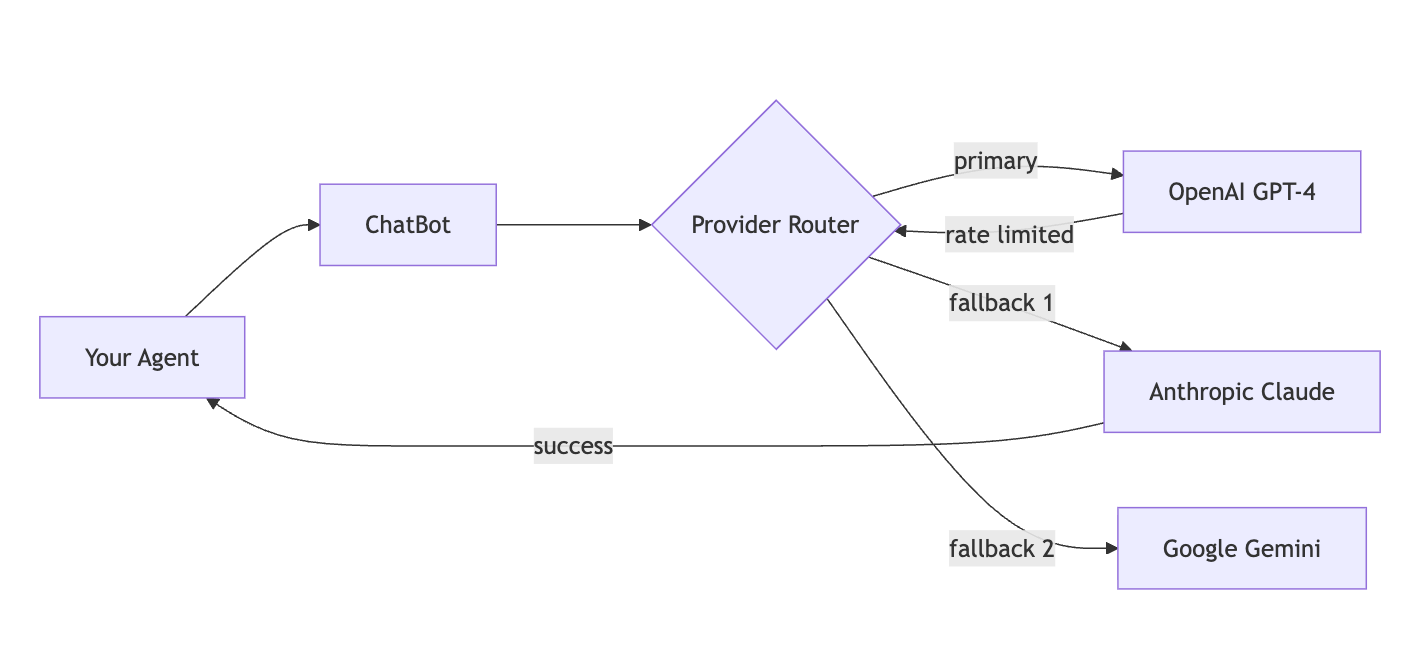
자동으로 여러 제공업체 간에 전환하며, 한 제공업체가 실패하면 다음으로 넘어갑니다. 이렇게 하면 서비스 안정성과 유연성을 확보할 수 있습니다.
제공업체 비교
각 제공업체는 고유한 강점을 가지고 있습니다:
| 제공업체 | 최적 용도 | 컨텍스트 | 강점 |
|---|---|---|---|
| OpenAI | 범용, 코드 | 128K | 가장 빠른 반복, 최고의 Tool 호출 |
| Anthropic | 긴 문서, 분석 | 200K | 프롬프트 캐싱, 안전 기능 |
| 멀티모달, 비용 효율적 | 1M | 가장 긴 컨텍스트, 빠른 추론 | |
| DeepSeek | 복잡한 추론, 코드 | 64K | 코드에 대한 최고의 비용/성능 |
| OpenRouter | 실험 | 다양함 | 100개 이상의 모델, 자동 라우팅 |
핵심 기능
SpoonOS의 통합 인터페이스는 다음과 같은 강력한 기능들을 제공합니다:
| 기능 | 기능 설명 |
|---|---|
| 통합 API | 모든 제공업체에 대해 동일한 ChatBot 클래스 |
| 자동 폴백 | 제공업체 체인: GPT-4 → Claude → Gemini |
| 스트리밍 | 모든 제공업체에서 실시간 응답 |
| Tool 호출 | 일관된 함수 호출 인터페이스 |
| 토큰 추적 | 자동 카운팅 및 비용 모니터링 |
빠른 시작
먼저 필요한 패키지를 설치하고 API 키를 설정합니다:
pip install spoon-ai
export OPENAI_API_KEY="your-key"이제 간단한 예제를 살펴보겠습니다:
import asyncio
from spoon_ai.chat import ChatBot
# 모든 제공업체에 대해 동일한 인터페이스—model_name과 llm_provider만 변경하면 됩니다
llm = ChatBot(model_name="gpt-5.1-chat-latest", llm_provider="openai")
async def main():
response = await llm.ask([{"role": "user", "content": "Explain quantum computing in one sentence"}])
print(response)
asyncio.run(main())제공업체를 변경하려면 llm_provider 파라미터만 바꾸면 됩니다. 코드는 그대로 유지됩니다!
지원되는 제공업체
OpenAI
- 모델: GPT-5.1, GPT-4o, o1, o3 등 (최신 모델 확인)
- 기능: 함수 호출, 스트리밍, 임베딩, 추론 모델
- 최적 용도: 범용 작업, 추론, 코드 생성
from spoon_ai.chat import ChatBot
# 기본 모델을 사용한 OpenAI 설정
llm = ChatBot(
model_name="gpt-5.1-chat-latest", # 최신 모델 이름은 문서를 확인하세요
llm_provider="openai",
temperature=0.7
)Anthropic (Claude)
- 모델: Claude 4.5 Opus, Claude 4.5 Sonnet 등 (최신 모델 확인)
- 기능: 큰 컨텍스트 윈도우, 프롬프트 캐싱, 안전 기능
- 최적 용도: 긴 문서, 분석, 안전이 중요한 애플리케이션
# 기본 모델을 사용한 Anthropic 설정
llm = ChatBot(
model_name="claude-sonnet-4-20250514", # 최신 모델 이름은 문서를 확인하세요
llm_provider="anthropic",
temperature=0.1
)Google (Gemini)
- 모델: Gemini 3 Pro, Gemini 2.5 Flash 등 (최신 모델 확인)
- 기능: 멀티모달 기능, 빠른 추론, 큰 컨텍스트
- 최적 용도: 멀티모달 작업, 비용 효율적인 솔루션, 긴 컨텍스트
# 기본 모델을 사용한 Google 설정
llm = ChatBot(
model_name="gemini-3-pro", # 최신 모델 이름은 문서를 확인하세요
llm_provider="gemini",
temperature=0.1
)DeepSeek
- 모델: DeepSeek-V3, DeepSeek-Reasoner 등 (최신 모델 확인)
- 기능: 고급 추론, 코드 전문 모델, 비용 효율적
- 최적 용도: 복잡한 추론, 코드 생성, 기술 작업
# 기본 모델을 사용한 DeepSeek 설정
llm = ChatBot(
model_name="deepseek-reasoner", # 최신 모델 이름은 문서를 확인하세요
llm_provider="deepseek",
temperature=0.2
)OpenRouter
- 모델: 하나의 API를 통해 여러 제공업체에 접근
- 기능: 모델 라우팅, 비용 최적화
- 최적 용도: 실험, 비용 최적화
# OpenRouter 설정
llm = ChatBot(
model_name="anthropic/claude-3-opus",
llm_provider="openrouter",
temperature=0.7
)통합 LLM Manager
LLM Manager는 자동 폴백과 함께 제공업체에 독립적인 접근을 제공합니다:
from spoon_ai.llm.manager import LLMManager
from spoon_ai.schema import Message
import asyncio
# LLM Manager 초기화
llm_manager = LLMManager()
# fallback_chain이 우선순위를 갖도록 default_provider 지우기
llm_manager.default_provider = None
# 폴백 체인 설정 (주 제공업체 먼저, 그 다음 폴백)
llm_manager.set_fallback_chain(["gemini", "openai"])
async def main():
# 메시지 생성
messages = [Message(role="user", content="Explain quantum computing in one sentence")]
response = await llm_manager.chat(messages)
print(f"Response: {response.content}")
print(f"Provider used: {response.provider}")
if __name__ == "__main__":
asyncio.run(main())이렇게 하면 첫 번째 제공업체가 실패하면 자동으로 다음 제공업체로 전환됩니다.
설정
환경 변수
# 제공업체 API 키
OPENAI_API_KEY=sk-your_openai_key_here
ANTHROPIC_API_KEY=sk-ant-your_anthropic_key_here
GEMINI_API_KEY=your_gemini_key_here
DEEPSEEK_API_KEY=your_deepseek_key_here
OPENROUTER_API_KEY=sk-or-your_openrouter_key_here
# 기본 설정
DEFAULT_LLM_PROVIDER=openai
DEFAULT_MODEL=gpt-5.1-chat-latest
DEFAULT_TEMPERATURE=0.3런타임 설정
{
"llm": {
"provider": "openai",
"model": "gpt-5.1-chat-latest",
"temperature": 0.3,
"max_tokens": 32768,
"fallback_providers": ["anthropic", "deepseek", "gemini"]
}
}고급 기능
응답 캐싱
중복 API 호출을 피하기 위해 응답 캐싱을 활성화할 수 있습니다:
from spoon_ai.llm.cache import LLMResponseCache, CachedLLMManager
from spoon_ai.llm.manager import LLMManager
from spoon_ai.schema import Message
import asyncio
# 중복 API 호출을 피하기 위해 응답 캐싱 활성화
cache = LLMResponseCache()
llm_manager = LLMManager()
cached_manager = CachedLLMManager(llm_manager, cache=cache)
async def main():
messages = [Message(role="user", content="Explain quantum computing in one sentence")]
response1 = await cached_manager.chat(messages)
print(response1)
if __name__ == "__main__":
asyncio.run(main())스트리밍 응답
실시간 상호작용을 위해 응답을 스트리밍할 수 있습니다:
# 실시간 상호작용을 위한 응답 스트리밍
import asyncio
from spoon_ai.chat import ChatBot
async def main():
# ChatBot 인스턴스 생성
llm = ChatBot(
model_name="gpt-5.1-chat-latest",
llm_provider="openai",
temperature=0.7
)
# 메시지 준비
messages = [{"role": "user", "content": "Write a long story about AI"}]
# 청크별로 응답 스트리밍
async for chunk in llm.astream(messages):
# chunk.delta에는 이 청크의 텍스트 내용이 포함됩니다
print(chunk.delta, end="", flush=True)
if __name__ == "__main__":
asyncio.run(main())함수 호출
모델이 호출할 함수를 정의할 수 있습니다:
# 모델이 호출할 함수 정의
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
"required": ["location"]
}
}
}
]
response = await llm.ask_tool(
messages=messages,
tools=tools
)모델 선택 가이드
작업 기반 추천
사용 사례에 맞는 올바른 모델을 선택하세요. 최신 모델 기능은 공식 문서를 확인하세요.
코드 생성
- 추천: DeepSeek (비용 효율적), OpenAI GPT 모델 (빠른 반복)
- 대안: Anthropic Claude (강력한 추론)
분석 및 추론
- 추천: OpenAI o-시리즈 모델, DeepSeek Reasoner, Claude
- 대안: Gemini Pro
비용에 민감한 작업
- 추천: DeepSeek 모델, Gemini 모델
- 대안: 제공업체 비교를 위한 OpenRouter
긴 컨텍스트 작업
- 추천: Gemini (가장 큰 컨텍스트), Claude (큰 컨텍스트)
- 대안: 각 제공업체의 최신 컨텍스트 윈도우 제한 확인
성능 비교
참고: 모델 기능과 가격은 자주 변경됩니다. 최신 정보는 항상 공식 문서를 확인하세요:
| 제공업체 | 모델 예시 | 컨텍스트 윈도우 | 최적 용도 |
|---|---|---|---|
| OpenAI | gpt-5.1-chat-latest | 문서 확인 | 범용, Tool 호출 |
| Anthropic | claude-sonnet-4-20250514 | 문서 확인 | 분석, 긴 문서 |
| gemini-2.5-pro | 문서 확인 | 멀티모달, 비용 효율적 | |
| DeepSeek | deepseek-reasoner | 문서 확인 | 추론, 코드 생성 |
| OpenRouter | Various | 다양함 | 여러 제공업체 접근 |
오류 처리 및 폴백
자동 폴백
프레임워크는 제공업체 간 자동 폴백과 함께 내장된 오류 처리를 제공합니다:
"""
LLMManager와 폴백 체인 데모 - 자동 제공업체 폴백을 시연합니다.
"""
from spoon_ai.llm.manager import LLMManager
from spoon_ai.schema import Message
import asyncio
# LLM Manager 초기화
llm_manager = LLMManager()
# fallback_chain이 우선순위를 갖도록 default_provider 지우기
llm_manager.default_provider = None
# 관리자는 다음 순서로 제공업체를 시도합니다: gemini -> openai -> anthropic
llm_manager.set_fallback_chain(["gemini", "openai", "anthropic"])
async def main():
# 메시지 생성
messages = [Message(role="user", content="Hello world")]
response = await llm_manager.chat(messages)
print(response.content)
if __name__ == "__main__":
asyncio.run(main())오류 유형 및 복구
프레임워크는 깔끔한 오류 처리를 위해 구조화된 오류 유형을 사용합니다:
from spoon_ai.llm.errors import RateLimitError, AuthenticationError, ModelNotFoundError
# 특정 오류 유형을 사용한 간단한 오류 처리
response = await llm.ask([{"role": "user", "content": "Hello world"}])
# 프레임워크가 일반적인 오류를 자동으로 처리합니다:
# - 속도 제한: 백오프와 함께 자동 재시도
# - 네트워크 문제: 폴백과 함께 자동 재시도
# - 인증: 명확한 오류 메시지
# - 모델 가용성: 대체 모델로 폴백우아한 성능 저하
# 프레임워크는 우아한 성능 저하 패턴을 제공합니다
llm_manager = LLMManager()
llm_manager.default_provider = "openai"
llm_manager.set_fallback_chain(["openai", "deepseek", "gemini"]) # 비용 효율적인 폴백
# 주 제공업체가 실패하면 자동으로 폴백 사용
# 수동 오류 처리가 필요 없습니다
messages = [Message(role="user", content="Complex reasoning task: Explain quantum computing and its applications")]
await llm_manager.chat(messages)모니터링 및 메트릭
사용량 추적
from spoon_ai.llm.monitoring import MetricsCollector, get_metrics_collector
# 전역 메트릭 수집기 가져오기
collector = get_metrics_collector()
# LLM 호출 중 메트릭이 자동으로 추적됩니다
response = await llm.ask([{"role": "user", "content": "Hello"}])
# 제공업체별 수집된 통계 가져오기
stats = collector.get_provider_stats("openai")
print(f"Total requests: {stats.total_requests}")
print(f"Successful requests: {stats.successful_requests}")
print(f"Failed requests: {stats.failed_requests}")
print(f"Success rate: {stats.success_rate:.2f}%")
print(f"Average duration: {stats.average_duration:.3f}s")
print(f"Total tokens: {stats.total_tokens}")
print(f"Total cost: ${stats.total_cost:.6f}")성능 모니터링
# MetricsCollector는 자동으로 다음을 추적합니다:
# - 요청 수 및 성공/실패율
# - 토큰 사용량 (입력/출력)
# - 지연 시간 통계 (평균, 최소, 최대)
# - 제공업체별 오류 추적
# 제공업체별 통계에 접근
for provider in ["openai", "anthropic", "gemini"]:
stats = collector.get_provider_stats(provider)
if stats and stats.total_requests > 0:
print(f"{provider}: {stats.total_requests} requests, {stats.failed_requests} errors")
# 모든 제공업체 통계에 접근
all_stats = collector.get_all_stats()
if all_stats:
print(f"\n📈 All Providers Summary:")
for provider_name, provider_stats in all_stats.items():
print(f"{provider_name}: {provider_stats.total_requests} requests, "
f"{provider_stats.success_rate:.1f}% success rate")모범 사례
제공업체 선택
- 여러 제공업체 테스트: 특정 사용 사례에 대해 여러 제공업체를 테스트하세요
- 비용 vs 품질 고려: 트레이드오프를 고려하세요
- 폴백 사용: 프로덕션 안정성을 위해 폴백을 사용하세요
설정 관리
- API 키 안전하게 저장: 환경 변수에 안전하게 저장하세요
- 설정 파일 사용: 쉬운 전환을 위해 설정 파일을 사용하세요
- 사용량 및 비용 모니터링: 정기적으로 모니터링하세요
성능 최적화
- 응답 캐싱: 적절한 경우 응답을 캐싱하세요
- 스트리밍 사용: 긴 응답에 대해 스트리밍을 사용하세요
- 요청 일괄 처리: 가능한 경우 요청을 일괄 처리하세요
오류 처리 철학
SpoonOS 프레임워크는 "빠르게 실패하고, 우아하게 복구" 접근 방식을 따릅니다:
- 자동 복구: 일반적인 오류(속도 제한, 네트워크 문제)는 자동으로 처리됩니다
- 구조화된 오류: 일반 예외 대신 특정 오류 유형을 사용하세요
- 폴백 체인: 자동 장애 조치를 위해 여러 제공업체를 구성하세요
- 최소한의 Try-Catch: 프레임워크가 오류를 처리하도록 하고, 커스텀 로직이 필요할 때만 catch하세요
# 선호되는 방법: 프레임워크가 오류를 처리하도록 하기
messages = [Message(role="user", content="Hello world")]
response = await llm_manager.chat("Hello world")
# 커스텀 비즈니스 로직을 위해서만 명시적 오류 처리 사용
if response.provider != "openai":
logger.info(f"Fell back to {response.provider}")마무리
SpoonOS의 통합 LLM 인터페이스는 여러 제공업체를 하나의 API로 통합하여 개발자에게 유연성과 안정성을 제공합니다. 자동 폴백, 스트리밍, 함수 호출, 모니터링까지 모든 기능이 포함되어 있어 프로덕션 환경에서도 안심하고 사용할 수 있습니다.
이제 여러분도 여러 LLM 제공업체의 장점을 활용하여 더 강력하고 안정적인 AI 애플리케이션을 구축해보세요!
다음 단계
- Agents - 에이전트가 LLM을 사용하는 방법 알아보기
- MCP Protocol - 동적 Tool 통합
- Configuration Guide - 상세 설정 지침
