[Paper Review] m6Anet;Detection of m6A from direct RNA sequencing using a multiple instance learning framework
m6Anet
- a neural-network-based MIL model (기존의 MIL 문제를 해결함.)
- non-DRACH motifs는 후보군에서 모두 제외함.
- two modules
1) read-level encoder
각 read로부터 signal 이랑 sequence의 특징을 입력받아 high-dimensional representation으로 변환한 뒤, 각 read가 m6A로 변형되었을 확률을 예측함. 이 read-level 확률들은 해당 site의 modified 여부를 pooling 을 통해 추정한다.
2) pooling layer
어떤 site에 적어도 하나 이상의 변형된 read가 존재할 확률을 표현.
-
Modulation of model parameters
-
training data consisting of labels (modified/unmodified)
-
direct RNA-Seq reads
(m6ACE-Seq 에서 얻은 lables 이용함.)
(m6A modifications는 unmodified sites보다 드물게 나타나므로, 균형을 맞추기 위해 modified sites를 oversample 함.) -
Contribution of signal and sequence features
-
signal intensity of the center base가 가장 영향력이 큰 특징임.
-
dwell time은 가장 작은 영향력이 작은 특징임.
-
전반적으로 모든 features가 modified 와 unmodified sites를 구분하는데 필요했음.
-
neighboring bases가 nanopore current signal 에 영향을 끼치는 지 알아보기 위해, 좌우 5개의 flanking base pairs로 수행함.(5-fold cross validation)
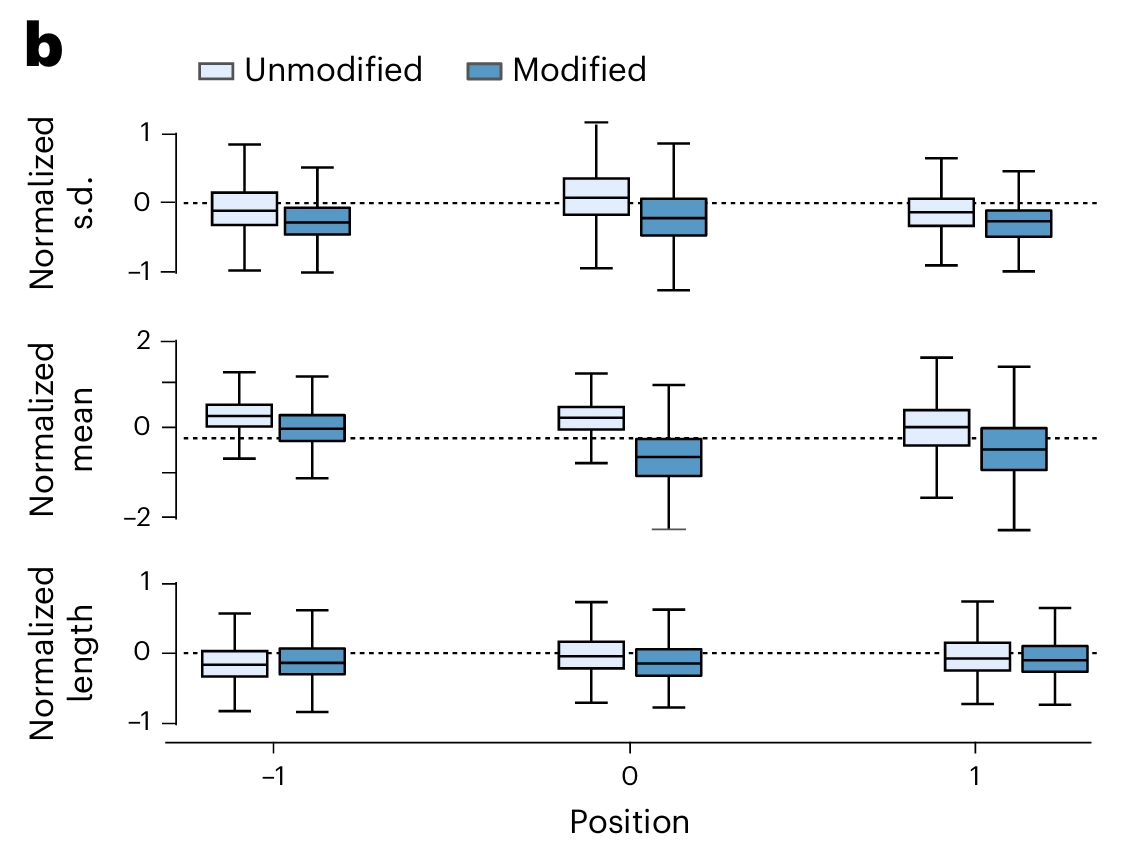
- x축인 position은 염기의 상대적 위치. ‘0’은 modification이 일어난 center base임.
- Normalized s.d. (표준 편차):
신호의 흔들림이나 잡음 정도 - Normalized mean (평균 신호 세기): signal intensity
- Normalized length (신호 지속 시간): dwell time
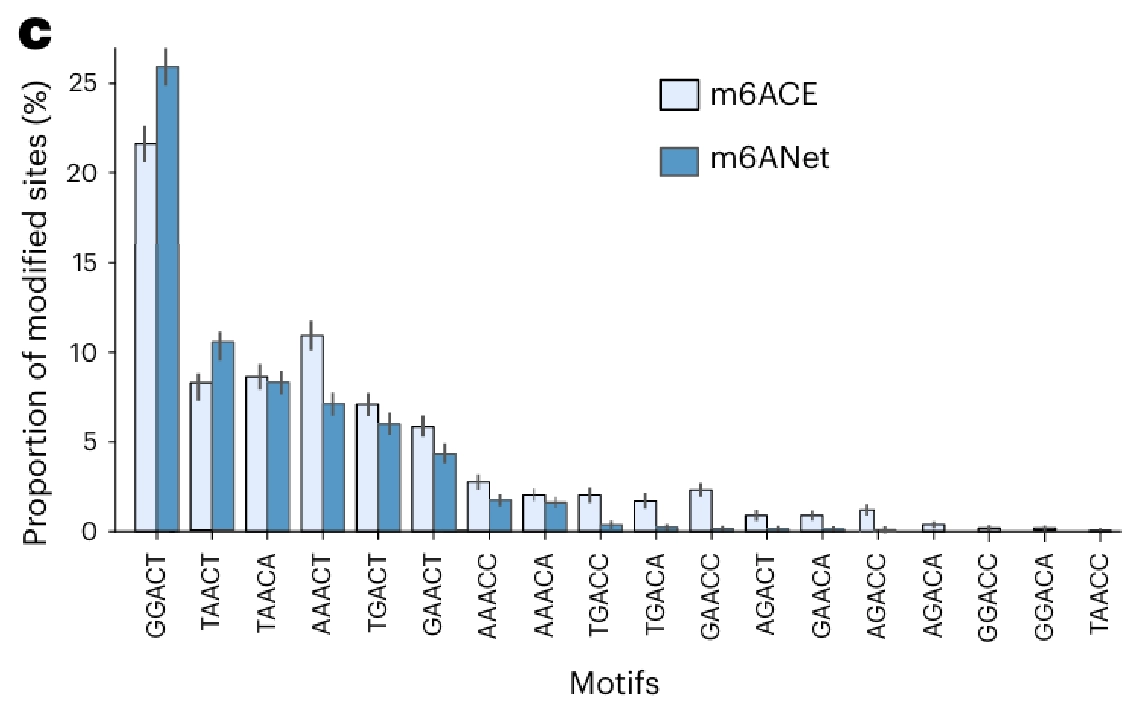
- 훈련데이터로 사용하지 않은 m6ACE-Seq data와 비교해본 결과 거의 비슷한 modification rates 를 보여주고 있음.
- m6Anet generalizes to new cell lines and species
- m6Anet-specific predictions are sensitive to METTL3 knockout
- m6Anet achieves high precision among top predicted sites
- m6Anet provides single-molecule m6A predictions → m6A stoichiometry
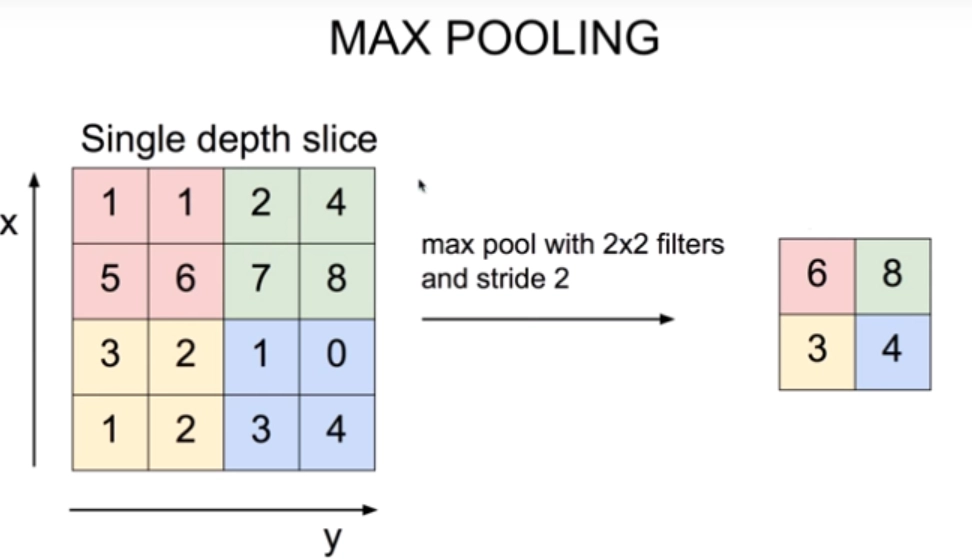
*pooling
- Max Pooling (최댓값 추출_CNN 등 이미지 처리 네트워크에서 주로 사용함)
- Min Pooling (최솟값 추출)
- Mean Pooling (평균 추출)
*end-to-end model
- 약한 supervised learning(지도 학습)
- 중간 처리 단계 없이 입력 데이터에서 출력 데이터로 직접 작업을 수행하는 방법을 학습하는 머신러닝 모델
- 수작업으로 만든 특징이나 전처리 단계에 의존하지 않고 원시 데이터를 입력으로 받아 원하는 출력을 직접 생성.
- 원시 입력 데이터와 해당 출력 데이터를 모델에 공급하고 예측 출력과 실측 출력 간의 차이를 측정하는 손실 함수를 최소화하기 위해 모델의 매개변수를 조정하는 과정이 포함됨
*K겹 교차 검증 (K-Fold Cross Validation)
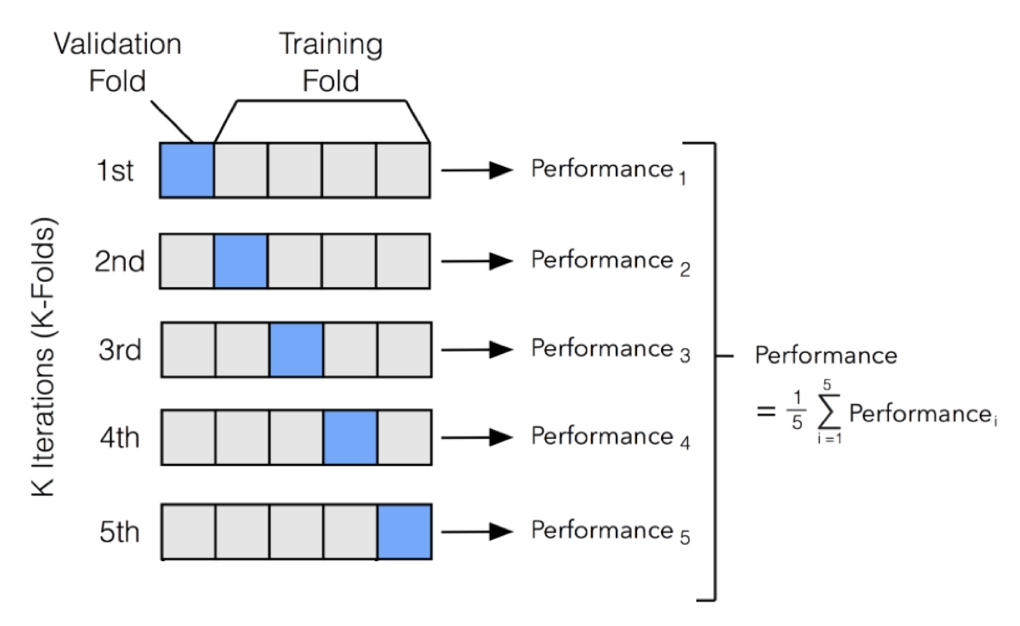
- 가장 보편적으로 사용되는 교차 검증 기법으로, K개의 데이터 폴드 세트를 만들어서 K번만큼 각 Fold set에 학습과 검증 평가를 반복적으로 수행하는 방법.
*ROC Curve vs PR Curve
| ROC Curve | PR Curve | |
|---|---|---|
| X축 | FPR | Recall |
| Y축 | TPR | Precision |
| 핵심 질문 | negative와 얼마나 잘 구분하나? | |
| (분리능력) | 예측한 positive를 얼마나 믿을 수 있나? | |
| (양성 예측의 신뢰도) |
*AUC: Area Under the Curve(곡선 아래 면적)
