데이터베이스의 특징
-
여러 사람의 공유 목적 -> 체계화된 통합, 관리
-
이전 파일시스템을 사용했으나, 데이터 종속성, 중복성 무결성의 문제 발생.
-
실시간 접근성
비정형적인 조회에 대하여 실시간 처리에 의한 응답이 가능 -
지속적인 변화
DB는 동적으로 새로운 데이터 삽입, 삭제, 갱신으로 항상 최신의 데이터를 유지 -
동시 공용
서로 다른 목적을 가진 여러 사용자들을 위한 것이므로, 다수의 사용자가 동시에 같은 내용의 데이터를 이용 -
내용에 의한 참조
DB의 데이터를 참조 시, 데이터 레코드의 주소나 위치가 아닌 사용자가 요구하는 데이터 내용을 찾는다.
정형 vs. 반정형 vs. 비정형
-
정형 데이터( 스키마 )
구조화된 데이터, 미리 정해진 구조에 따라 정해진 데이터
ex) 엑셀, 관계형 DB의 테이블 -
반정형 데이터
-
구조에 따라 저장되지만, 데이터 내용 안에 구조에 대한 설명이 함께 존재
-
구조를 파악하는 파싱 과정 필요
ex) HTML, XML, JSON -
파일 형태로 저장
- 비정형 데이터
- 정해진 구조가 없는 데이터
ex) 텍스트, 영상, img, pdf
데이터베이스 언어( DDL, DML, DCL )
-
DDL( Data Definition Language)
DB 구조를 정의, 수정, 삭제하는 언어
ex) alter, crete, drop -
DML( Data Manipulation Language)
DB내의 자료 검색, 삽입, 갱신, 삭제를 위한 언어
ex) insert, select, update, delete -
DCL( Data Control Language)
데이터에 대한 무결성 유지, 병행 수행 제어, 보호와 관리를 위한 언어
ex) commit, rollback, grant, revoke
SELECT 쿼리 실행 순서
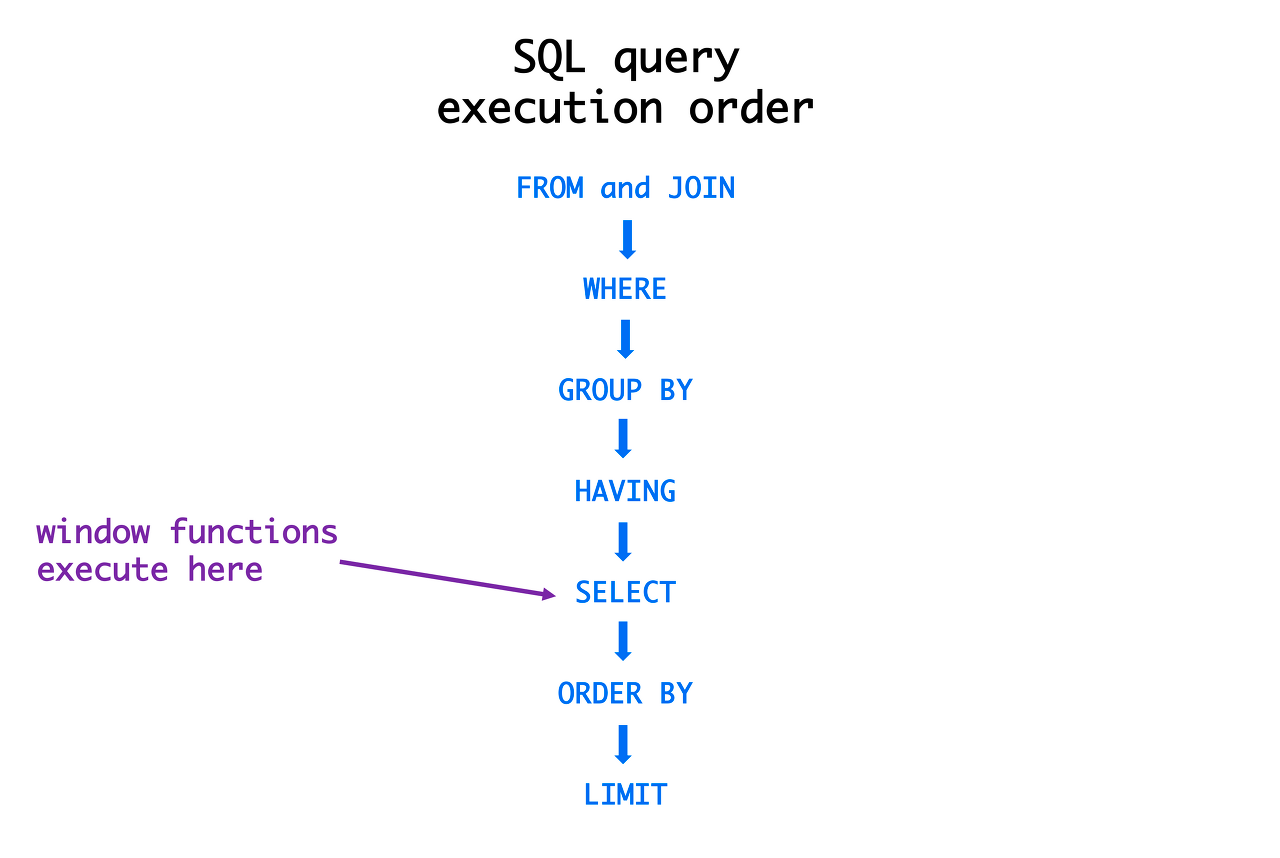
FROM > ON > JOIN > WHERE > GROUP BY > HAVING > SELECT > DISTINCT > ORDER BY > LIMIT
트리거란?
INSERT, DELETE, UPDATE 같은 DML문이 수행되었을 때, 사용자가 아닌 DB에서 자동 실행.
Index란?
테이블을 처음부터 끝까지 검색하는 테이블 풀 스캔이 아닌,
{ Key : Value } 형식으로 원하는 Value를 Key를 이용해서 가져온다.
( 단, 데이터는 Arraylist처럼 별도의 정렬없이 저장이 된다. )
-
인덱스는 항상 정렬된 상태를 유지하기 때문에 SELECT는 빠르지만,
INSERT, UPDATE, DELETE는 포기 -
SELECT의 WHERE 조건절 모두 인덱스로 생성하면,
데이터 저장 성능이 떨어지고 인덱스의 크기가 비대해짐 -> 성능저하
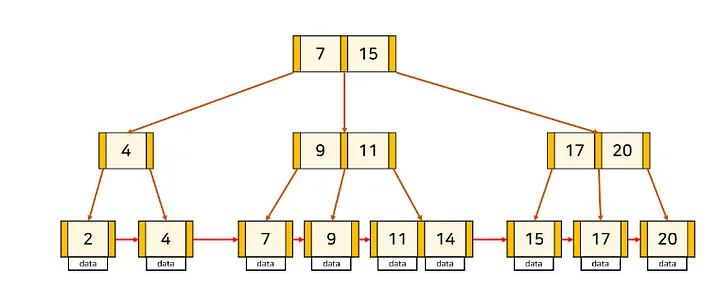
1. Index 자료구조
- B+Tree 인덱스 자료구조
-
자식 노드 2개 이상인 B-Tree를 개선시킨 자료구조
-
B-Tree 리프노드들을 LinkedList로 연결하여 순차 검색에 용이.
( 해시 테이블보다 long2N의 시간복잡도를 갖지만, 일반적으로 사용 ) -
실제 data는 리프 노드에만 저장
- 해시 테이블( key : value)
-
컬럼의 값으로 생성된 해시를 기반으로 인덱스를 구현
-
O(1)의 시간복잡도
-
부등호(<,>)와 같은 연속적인 데이터를 위한 순차 검색이 불가능 -> 부적합.
2. 인덱스 종류와 특징
2.1 PRIMARY KEY
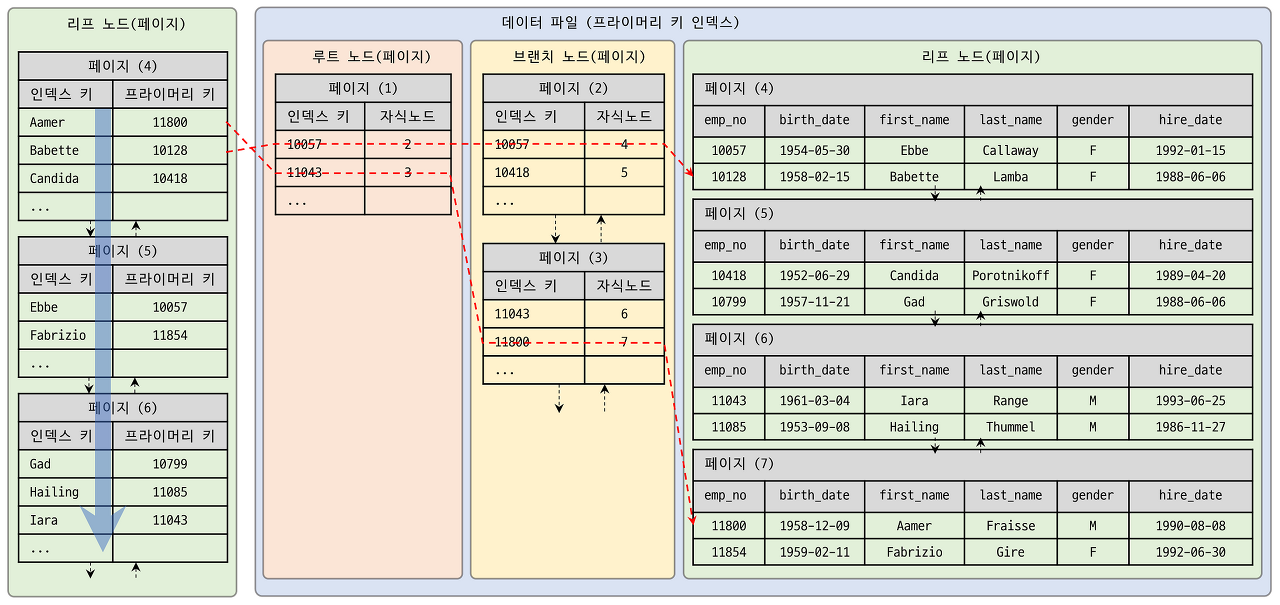
최초성과 유일성을 만족, 테이블 당 오직 1개, NOT NULL + 중복 허용 안함.
( 만약 Secondary Index와 같이 쓰면 B+Tree가 2개이다. )
"InnoDB에서 모든 SECONDARY INDEX 검색에서 레코드를 읽기 위해서는 반드시! PRIMARY KEY를 저장하고 있는 B+Tree 한번 더 거쳐야함."
2.2 SECONDARY INDEX( 보조 인덱스 )
보조 인덱스의 리프는 [ 인덱스 키, PK ]로 구성되어 있다.
2.3 FOREIGN KEY
참조의 무결성
정규화
테이블 간 중복된 데이터 허용하지 않음.( 무결성 유지, DB의 저장 용량 감속 )
[ 제1 정규화 ]
테이블의 컬럼이 Atomic 하게 값을 갖도록 분해
 ( Before )
( Before )
 ( After )
( After )
[ 제2 정규화 ]
제 1 정규화를 진행한 테이블에 대해 완전 함수 종속(기본키의 부분집합이 결정자가 되어선 안됨.)을 만족하도록 테이블을 분해.
( 모든 비프라이머리 속성이 기본키 전체에 대해 완전 함수 종속 )
즉, 현재 테이블의 주제와 관련없는 컬럼을 다른 테이블로 빼는 작업.
🔍 예시:
| 학생ID | 과목코드 | 학생이름 | 과목이름 |
| ---- | ----- | ---- | ---- |
| 1001 | CS101 | 홍길동 | 자료구조 |
| 1001 | CS102 | 홍길동 | 운영체제 |
기본키: (학생ID, 과목코드)
학생이름은 학생ID에만 의존 → 부분 함수 종속.
과목이름은 과목코드에만 의존 → 역시 부분 함수 종속.
→ 제2정규형으로 분해:
학생(학생ID, 학생이름)
과목(과목코드, 과목이름)
수강(학생ID, 과목코드)
[ 제3 정규화 ]
제 2 정규화를 진행한 테이블에 대해 이행적 종속( A -> B, B -> C = A -> C)을 제거
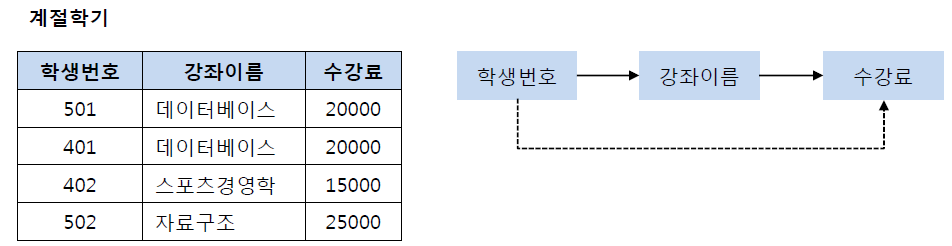 ( Before )
( Before )
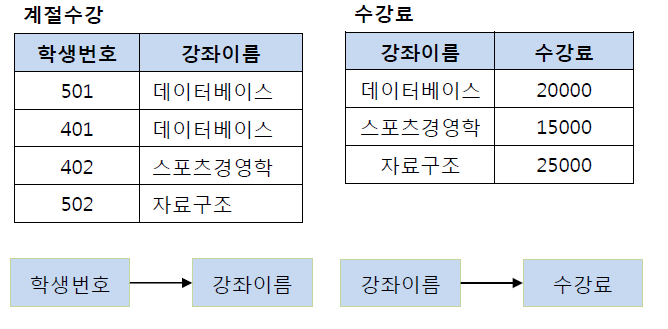 ( After )
( After )
학생번호 -> 강좌이름, 강좌이름 -> 수강료
( 학생번호 -> 수강료 X )
[ BCNF 정규화 ]
제 3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해.
참고자료
-
슈퍼키
테이블 내에서 어떤 컬럼(속성)끼리 묶떤 절대로 중복값이 안 나오고 서로 구별 가능 -
후보키
슈퍼키들 중에서 컬럼(속성)은 최소한의 갯수로 구분 가능한 컬럼. -
기본키
후보키들 중에서 하나를 선택한 키로 최소성과 유일성을 만족하며, 오직 1개. -
대체키
후보키가 2개 이상인 경우, 그 중에서 어느 하나를 기본키로 지정하고 남은 후보키
 ( Before )
( Before )
 ( After )
( After )
정규화 장/단점
1. 장점
-
DB 변경 시 이상현상이 발생하는 문제점 해결 가능
-
DB 구조 확장 시 정규화된 DB는 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다.
2. 단점
- 릴레이션 간의 JOIN연산이 많아진다. 이로 인해 질의에 대한 응답 시간이 느려진다.
참고)
데이터의 중복 속성을 제거하고
결정자에 의해 "동일한 의미의 일반 속성이 하나의 테이블로 집약"되므로, 한 테이블의 데이터 용량이 최소화.
역정규화
정규화된 DB를 다시 중복을 포함하는 형태로 변경함.
-> 테이블을 너무 많이 잘게 쪼개면, 여러 태이블이 모두 동시에 조인을 하게 되기 떄문에 성능 이슈가 발생한다.
이상 현상의 종류
-
삽입 이상
자료를 삽입시, 특정 속성에 해당하는 값이 없어 NULL을 입력 -
갱신 이상
중복된 데이터 중 일부만 수정되어 데이터 모순 -
삭제 이상
어떤 정보 삭제시, 의도하지 않은 다른 정보까지 삭제.
=> 이런 현상을 방지하기 위해서, 데이터 정규화.
SQL Injection
악의적인 의도를 갖는 SQL 구문을 삽입하여 데이터베이스를 비정상적으로 조작하는 코드 인젝션 기법.
방지법
-
입력된 값이 개발자가 의도한 값(유효값)인지 검증
-
저장 프로시저 사용
( Query에 미리 형식을 지정, 지정된 형식이 아니면 실행 안됨. )
RDBMS vs. NoSQL
- RDBMS
모든 데이터를 2차원 테이블 형태로 표현
-
장점
스키마에 맞춰 데이터를 관리하기 때문에 데이터의 정합성을 보장 -
단점
시스템이 커질수록 쿼리가 복잡해지고, 성능 저하( Scale-up만 가능하고 ,Scale-out은 안됨 )
참고
-
Scale-up
기존 서버의 사양을 업그레이드( 스펙업 ) -
Scale-out
서버를 여러 대 추가
부하를 균등하게 해야 하므로, loadbalancing 필수
- NoSQL
데이터간의 관계를 정의하지 않아서,
Schema 없이 좀 더 자유롭게 데이터를 관리할 수 있음.
-
장점
스키마 없이 {key:value}로 데이터를 자유롭게 관리
데이터 분산이 용이 -> scale-up, scale-out 가능 -
단점
데이터 중복 발생
스키마가 없음 -> 데이터 구조 결정이 어려움.
그러면 언제 RDMBS와 NoSQL을 사용?
-
RDBMS는 데이터 구조가 명확하고, 변경될 여지가 없으면 사용
-
NoSQL은 정확한 데이터 구조를 알 수 없고, 데이터가 변경/확장이 될 수 있는 경우 사용.
트랜잭션
하나의 논리적 작업 단위이며, 작업의 완전성을 보장해준다.
또한 하나의 트랜잭션은 Commit 또는 Rollback이 되어, ACID를 보장한다.
ACID
-
A(Atomic)
Commit or Rollback(중간에 절반만 적용되는 경우는 절대 없다.) -
C(Consistency)
실행이 완료되면 언제나 일관성 있는 상태를 유지
트랜잭션이 진행되는 동안 DB가 변경 되더라도 업데이트된 DB로 진행되는 것이 아니라!,
처음 트랜잭션을 진행하기 위해 참조한 DB로 진행되어야 한다. -
I(Isolation)
둘 이상 트랜잭션이 동시에 실행될 경우 서로의 연산에 끼어들 수 없다. -
D(Durability)
완료된 결과는 영구적으로 반영되어야 한다.
DB락
-
공유락( Shared Lock, S-Lock )
트랜잭션이 읽기를 할 때 사용하는 락이며,
데이터를 읽기만하기 때문에 같은 공유락끼리 동시에 접근이 가능 -
베타락( Exclusive Lock, X-Lock )
쓰기락이라고 불리며, 데이터를 변경시 사용하며,
트랜잭션이 완료될 때까지 유지되며, 베타락이 끝나기 전까지 어떤 접근도 허용x
옵티마이져
SQL을 가장 빠르고 효율적으로 수행할 최적의 경로를 생성해줌.
( 알아서 INDEX 사용할지 결정 )
Inner Join vs. Outer Join
-
Inner Join
교집합으로 두 스키마간 공통 부분. -
Outer Join
A여집합 + A와B 교집합으로,
한 쪽에는 데이터가 있고 다른 한쪽에는 데이터가 없는 경우,
데이터가 있는 쪽 전체를 출력하는 방법.
Group By
특정 컬럼을 기준으로 그룹을 만듦.
DELETE, TRUNCATE, DROP의 차이점은?
-
DELETE는 데이터를 지우지만 용량은 줄어들지 않는다 -> 삭제 후 복구 가능
-
TRUNCATE은 전체 데이터를 삭제해서 용량이 줄고, 인덱스도 삭제 -> 테이블 삭제 불가하고, 복구 안됨.
-
DROP은 테이블 자체를 삭제 -> 복구 불가.
Having vs. Where
having은 group by를 필터링 하는데 사용 -> 그룹화, 집계가 발생한 후 필터링
where은 개별 행을 필터링 하는데 사용. -> 그룹화, 집계가 발생하기 전 필터링.
Join에서 On과 Where 차이
ON이 WHERE보다 먼전 실행되어 JOIN을 하기 전에 필터링을 하고
(ON 조건으로 필터링이 된 레코들간 JOIN)
WHERE은 JOIN을 한 후 필터링을 한다.
(JOIN을 한 결과에서 WHERE 조건절로 필터링 발생.)
