Spring Framework
1. 개념
자바 개발을 편하게 해주는 프레임워크로
- IoC
제어권을 프레임워크로 넘김으로써,
객체 간의 결합도를 줄이고 유연한 코드를 작성할 수 있으며,
가독성 및 코드 중복, 유지 보수에 유리.
기존
-
객체 생성
-
의존성 객체 생성( 클래스 내부에서 생성 )
-
의존성 객체 메소드 호출
스프링 프레임워크
-
객체 생성
-
의존성 객체 주입
제어권을 스프링에게 위임하여 스프링이 만들어놓은 객체를 주입. -
의존성 객체 메소드 호출
스프링이 모든 의존성 객체를 스프링이 실행될 때 다 만들어주고 필요한 곳에 주입시킴으로써 Bean은 싱글톤 패턴이며, 제어의 흐름은 스프링에게 전적으로 위임한다.
- DI
각 레이어 간에 의존성이 존재할 경우 프레임워크가 서로 연결시켜준다.
모듈 간의 결합도가 낮아지고 유연성이 높아진다.
(객체를 직접 생성하는 게 아니라 외부에서 생성한 후 주입 시켜주는 방식)
생성자 주입, 필드 주입, 세터 주입이 있는데, 생성자 주입을 통해서 1. 순환 참조 방지, 2. 불변성, 3. 테스트 용이함.
-
AOP
여러 모듈(시스템의 구성 요소)에서 공통적으로 사용하는 기능의 경우,
해당 기능을 분리하여 관리.
(공통 모듈인 인증, 로깅, 트랜잭션에 용이)
이를 통해서 중복 코드 제거, 재활용성 극대화 -
경량 컨테이너로서 자바 객체를 직접 관리
객체 생성, 소멸과 같은 라이프 사이클을 관리.
2. Spring Boot vs. Spring Framework.
가장 큰 차이는 Auto Configuration이다.
Spring은 프로젝트 초기에 다양한 환경설정을 해야하나,
Spring Boot는 많은 부분을 자동화해서 사용자가 편하게 스프링을 활용할 수 있게 해준다.
3. Spring MVC
-
Model( DAO, DTO, Service )
데이터 관리, 비즈니스 로직 처리 -
View
비즈니스 로직의 처리 결과를 통해 유저 인터페이스가 표현되는 구간 -
Controller
사용자의 요청을 처리하고, Model과 View를 중개하는 역할.
이는 컴포넌트를 분리함으로써, 시스템 간 결합도를 낮추기 위함이다.
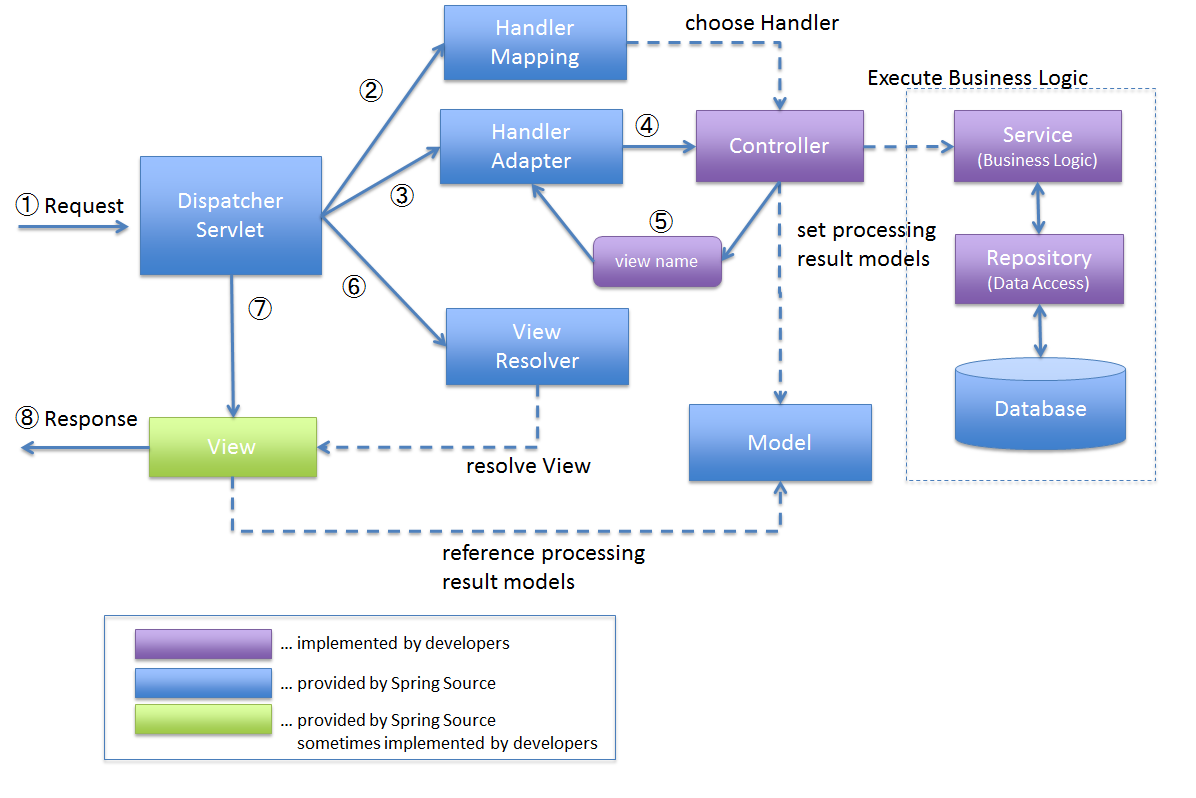
Spring MVC 요청 흐름도
-
DispatcherServlet
클라이언트에게 요청을 받아 응답까지의 MVC 처리과정을 통제한다. -
HandlerMapping
클라이언트의 요청 URL을 어떤 Controller가 처리할지 결정 -
HandlerAdapter
HandlerMapping에서 결정된 핸들러 정보로 해당 메소드를 직접 호출 -
ViewResolver
Controller의 처리 결과를 생성할 view를 결정
-
클라이언트는 URL을 통해 요청을 전송한다.
-
DispatcherServlet은 핸들러 매핑을 통해 해당 요청이 어느 컨트롤러에게 온 요청인지 찾는다.
-
DispatcherServlet은 HandlerAdapter에게 요청의 전달을 맡긴다.
-
HandlerAdapter는 해당 컨트롤러에 요청을 전달한다.
-
Contrller는 비즈니스 로직을 처리한 후 반환할 뷰의 이름을 반환한다.
-
DispatcherServlet은 ViewResolver를 통해 반환할 View를 찾는다.
-
DispatcherServlet은 Controller에서 View에 전달할 데이터를 추가한다.
-
데이터가 추가된 View를 반환한다.
4. 스프링 Bean 등록.
- @Component로 등록
-
class level
-
개발자가 작성
-
@Scope("Prototype")은 싱글톤이 아닌 빈 생성.
- @Configuration클래스 내부에 @Bean 메소드 등록
-
method level
-
외부 라이브러리가 제공하는 객체
빈 라이프 사이클
스프링 IOC 컨테이너 생성 -> 스프링 빈 생성 -> 의존관계 주입 -> 초기화 콜백 메소드 호출 -> 사용 -> 소멸 전 콜백 메소드 호출 -> 스프링 종료.
스프링은 3가지 방법으로 Bean 생명주기 콜백을 관리.
-
인터페이스
-
설정 정보에 초기화 메소드, 종료 메소드 지정
-
@PostConstuct, @PreDestroy 지원
스프링의 싱글톤 패턴
@Bean, @Component 생성하면 싱글톤으로 등록이 되는데,
요청이 들어올 때마다 매번 객체를 생성하지 않고, 이미 만들어진 객체를 공유하기 때문에 효율적인 사용이 가능.
Spring의 Scope "Prototype"
default bean(싱글톤)과 달리 컨테이너에게 빈 요청시 매번 새로운 객체를 생성해서 반환.
@Scope("prototype")
Lombok과 Lombok이 만드는 메소드들이 생성되는 시점은?
메소드를 "컴파일 하는 과정에 개입"해서 추가적인 코드를 만듦 = Annotation Processing
Annotation Processing은 자바 컴파일러가 컴파일 단계에서 annotation을 분석하고 처리하는 기법.
Servlet
클라이언트의 요청을 처리하고, 그 결과를 반환하는 (Servlet 클래스의 구현 규칙을 지킨) 자바 웹 프로그래밍 기술.
Spring MVC에서 "Controller"가 이 역할을 담당한다.
(자바를 사용해 웹을 만들기 위해 필요한 기술.)
1. 특징
-
클라이언트의 요청에 대해 동적으로 작동하는 웹 어플리케이션
-
html을 사용해서 요청에 응답.
-
Java Thread를 이용
-
MVC 패턴 중 Controller에 해당.
-
HttpServlet 클래스를 상속받음.
-
UDP보다 느림.
-
HTML 변경 시 Servlet 재컴파일 해야함.
동적인 페이지를 제공시 사용자가 요청한 시점에 페이지를 생성해서 전달해 주는 것을 의미.
Servlet 동작방식
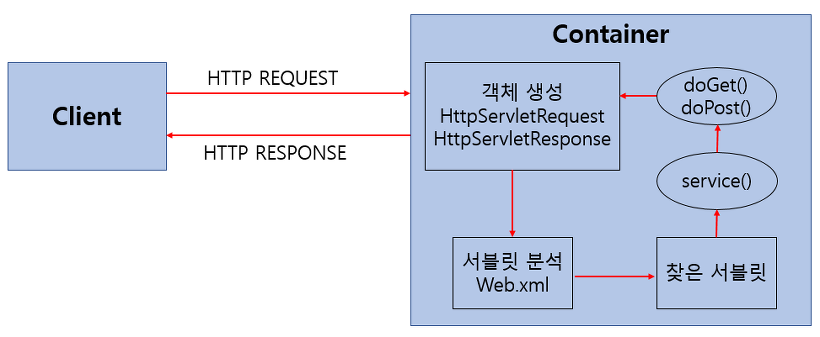
-
사용자가 URL을 입력하면 HTTP Request가 Servlet Container로 전송됨.
-
요청 받은 Servlet Container는 HttpServletRequest, HttpServletResponse객체를 생성
-
web.xml을 기반으로 사용자 요청한 URL이 어느 서블릿(Controller)에 대한 요청인지 찾음.
-
해당 서블릿에서 service메소드를 호출 한 후, GET, POST에 따라 doGet() 또는 doPost()를 호출한다.
-
doGet() or doPost() 메소드는 동적 페이지를 생성한 후 HttpServletResponse객체에 응답
-
응답이 끝나면 HttpServletRequest,httpServletResponse를 종료
참고로, WAS는 요청 정보를 담은 Request 객체와 응답 정보를 담은 Response 객체를 새로 생성
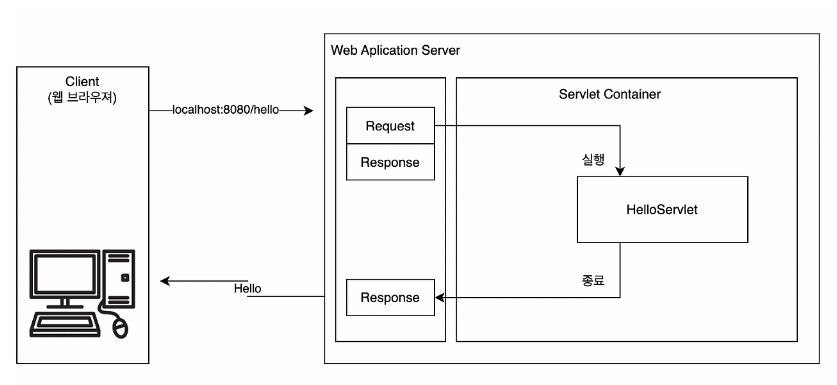
2. Servlet Container
서블릿을 관리해주는 컨테이너.
(서블릿 컨테이너에 의해서 서블릿이 작동한다.)
Ex) Tomcat
Servlet Container 역할
-
웹서버와의 통신 지원
일반적으로 소켓을 만들고 listen, accept 등을 처리해야 하지만,
이런 과정을 서블릿 컨테이너가 담당하며,
개발자는 비즈니스 로직만 처리하면 된다. -
서블릿 생명주기 관리
서블릿 클래스를 로딩하여 인스턴스화하고, 초기화 메소드를 호출하고, 요청이 들어오면 적절한 서블릿 메소드를 호출.
또한 생명이 다하면 GC를 한다. -
멀티쓰레드 지원 및 관리
요청 1개당 스레드 1개(커널과 1대1 관계)를 매핑하는데,
스프링부트에서 스레드 풀을 이용해서 재사용을 하며,
API 연결 시간이 지나면 자동으로 연결을 차단한다. -
선언적인 보안 관리
서블릿 생명주기
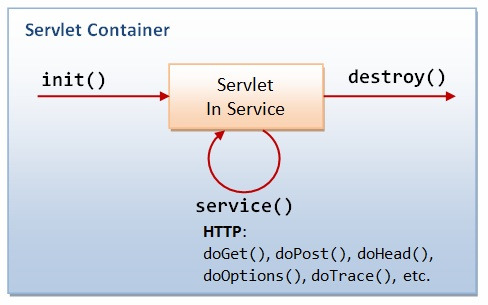
-
클라이언트 요청이 들어오면 컨테이너는 해당 서블릿이 메모리에 있는지 확인하고, 없을 경우 init()메소드를 호출해서 적재한다.
( init메소드는 처음 한번만 실행) -
init()이 호출된 후 클라이언트 요청에 따라 serivce()메소드를 통해 요청에 대한 응답이 doGet(), doPost()로 분기.
또한 들어온 요청에 대해서 HttpServletRequest, HttpServletResponse 생성. -
컨테이너가 서블릿에 종료 요청 -> destroy()호출
Spring Filter vs. Interceptor
1. Filter?
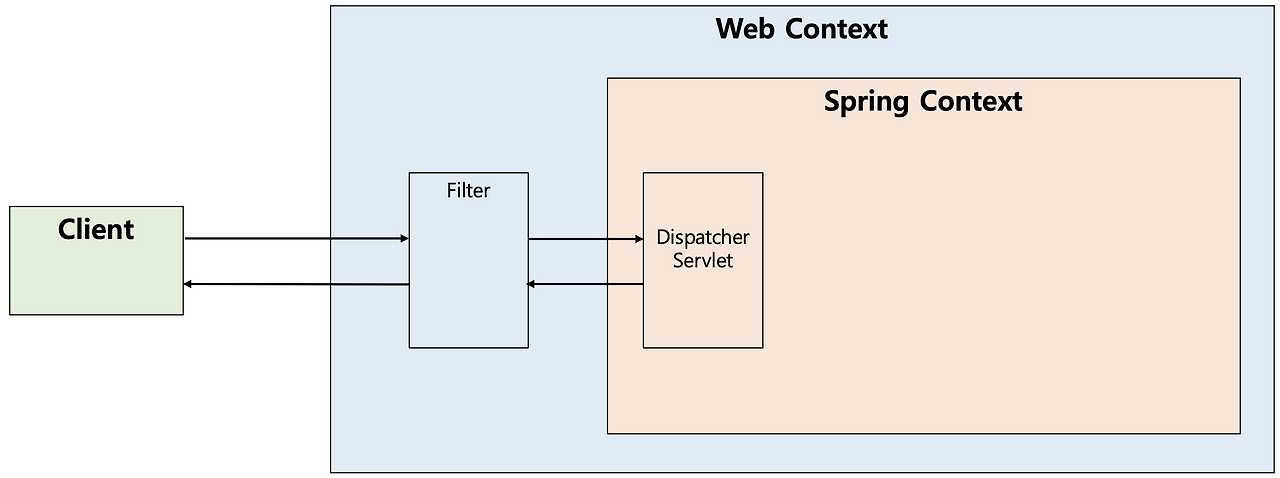
"Dispatcher Servlet에 요청이 전달되기 전/후"에 "url 패턴에 맞는 모든 요청에 대해 부가작업"을 처리할 수 있는 기능.
필터는 Spring Context(범위) 밖에서 처리.
(스프링 컨테이너가 아닌! 웹(서블릿) 컨테이너가 관리.)
-
보안 및 인증/인가
-
모든 요청에 대한 로깅
-
이미지/데이터 압축 및 문자열 인코딩
-
Spring과 분리되어야 하는 기능
만약 필터에서 에러가 발생하면, Spring까지 못가니까 필터에서 처리를 반드시 해야한다.
2. 인터셉터
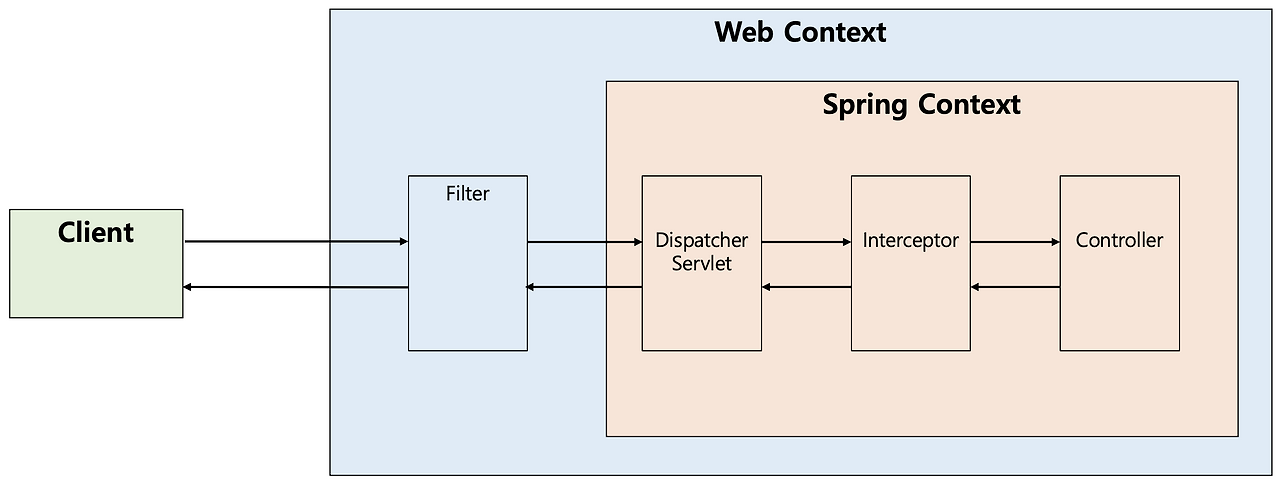
Spring이 제공하는 기술로써, Dispatcher 서블릿이 컨트롤러를 호출하기 전/후 요청과 응답을 참조하거나 가공할 수 있다.
( 스프링 컨텐그스에서 동작 )
따라서, 인터셉터가 있으면 인터셉트를 거쳐서 -> 컨트롤러로 도착.
-
세부적인 보안 및 인증/인가
-
API 호출에 대한 로깅
-
Controller로 넘겨주는 정보 가공.
Dispatcher Servlet?
"HTTP 프로토콜로 들어오는 모든 요청을 가장 먼저 받아"
적합한 컨트롤러에 위임해주는 프론트 컨트롤러.
모든 요청을 프론트 컨트롤러인 Dispatcher Servlet이 가장 먼저 받고,
Dispatcher Servlet은 공통 작업을 먼저 처리한 후, 해당 요청을 처리하는 컨트롤러를 찾아서 작업을 위임한다.
Dispatcher Servlet 장점
기존에서는 모든 서블릿을 URL 매핑을 위해 web.xml에 모두 등록해주어야 했지만,
dispatcher-servlet이 들어오는 모든 요청을 핸들링 및 공통 작업으로 편리.
정적 자원 처리
Dispatcher Servlet이 모든 요청을 처리해서 이미지, html, css, javascript까지 모두 싹다 가로채서 정적 자원을 불러오지 못한다.
그래서 다음과 같이 접근.
-
정적 자원 요청과 애플리케이션 요청을 분리
/app은 Dispatcher Servlet이, /resources는 정적자원으로 처리하게 유도한다.
( 모든 요청에 url을 추가해야 하므로, 지저분 ) -
애플리케이션 요청을 탐색하고 없으면 -> 정적 자원 요청 처리
먼저 컨트롤러 탐색 -> 못 찾으면, 정적 자원 탐색.
VO, BO, DAO , DTO 구분
-
DAO( Data Access Object )
DB의 데이터에 접근을 위한 객체 -
BO( Business Object )
여러 DAO를 활용해 비즈니스 로직을 처리하는 객체 -
DTO( Data Transfer Object )
각 계층간의 데이터 교환을 위한 객체
( Controller, Service, Business, ... ) -
VO( Value Object, read-only )
-
불변성 : setter가 없고, getter만 있다.
한번 생성되면 이후 내부 값을 바꿀 수 없음(final, 원시타입) -
값 동등성( equals ) : 내부 값 동등성 검사
내부의 값이 동일한 두 객체는 동일한 것으로 판단. -
자가 유효성 검사( hashCode ) : 생성자에서 validate
@Transactional (ACID)
1. 의의
method level 또는 class level에서 사용 가능.
모든 public 메소드에 트랜잭션을 적용
해당 메소드를 실행시 트랜잭션을 시작하고,
메소드가 정상적으로 종료 -> 트랜잭션 commit
메소드가 예외를 발생시키면 -> rollback
이를 통해서 ACID를 유지할 수 있다.
그리고 기존의 긴 JDB 트랜잭션을 짧은 코드로 바꿀 수 있다.
// JDBC
Connection conn = dataSource.getConnection();
Savepoint savepoint;
try (connection) {
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
savepoint = conn.setSavepoint("savepoint");
String sql = "Insert into User values (16, 'Rosie', 'rosie@gmail.com')"
stmt.executeUpdate(sql);
conn.commit();
} catch (SQLException e) {
conn.rollback(savepoint);
}// @Transactional
public class UserService{
private final UserRepository userRepository;
@Transactional(readOnly = true)
public List<User> findAll(User user) {
return userRepository.save(user);
}
}
2. 동작원리
-
TransactionAutoConfiguration이 실행
( proxy 생성에 필요 ) -
요청이 올 경우, Spring은 AOP프레임워크를 이용해서 "Proxy"를 생성하고,
특정 메소드 호출을 가로채서 추가 동작을 수행.
( 각 JointPoint에서 동작하는 횡단 관심의 공통 기능을 수행. )
3. 주의사항
-
public 선언
프록시 객체로 외부에서 접근 가능한 인터페이스를 제공해야 함. -
다른 AOP 기능과의 충돌을 고려
@Secured를 통해 권한이 있는 사용자 여부를 확인하는데, 먼저 @Transactional이 수행된다면 권한 검사가 무의미함. -
Service layer 사용
Service layer에서 @Transactional을 Atomic하게 처리.
굳이 Proxy를 쓰는 이유?
메소드 실행을 가로채서, 그 메소드 실행 전후에 트랜잭션을 시작하고 "커밋/롤백"을 위함.
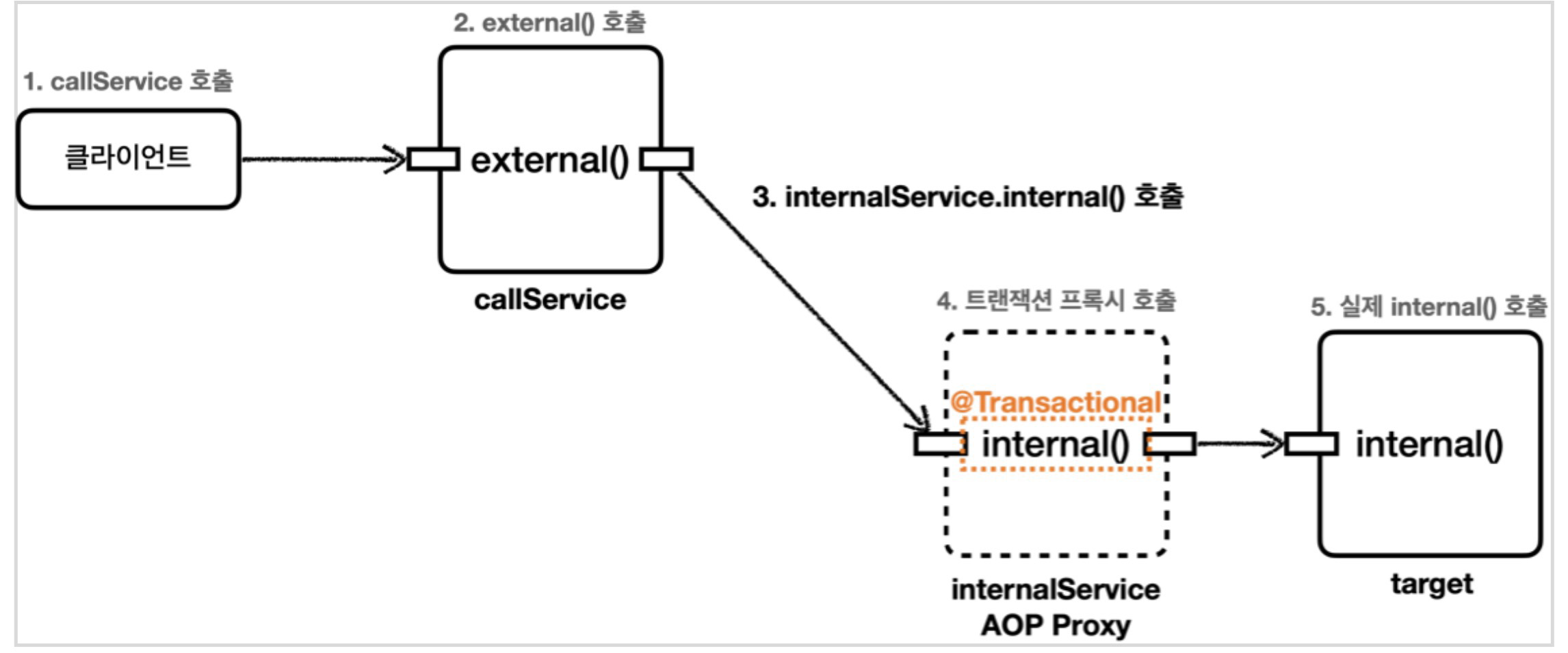
4. 만약 트랜잭션을 내부 호출을 할 경우
@Service
public class MyService {
@Transactional // 트랜잭션 적용
public void methodA() {
// 트랜잭션이 적용되길 기대
...
}
public void methodB() {
methodA(); // 내부에서 자기 자신 호출
}
}프록시는 외부에서 접근할 때만 작동.
-
Spring은 @Transactional을 프록시 객체에 적용.
-
외부(Controller 등)에서 myService.methodA()처럼 호출해야,
프록시 -> 트랜잭션 시작 -> 진짜 메소드 -
동일 클래스 안에서 자가 호출은 작동안함.
트랜잭션 전파
@Service
public class MyService {
@Transactional
public void methodA() {
methodB();
}
@Transactional
public void methodB() {
// 작업 수행
}
}Propagation.REQUIRED를 할 경우
-
호출하는 쪽에 트랜잭션이 있으면 -> 트랜잭션 재사용
-
없으면 새로운 트랜잭션을 만듦.
여기서는 methodA()가 프록시에 의해서 트랜잭션이 시작되고, methodB()가 실행시 이미 있기 때문에 트랜잭션을 재사용을 한다.
트랜잭션 추가설명
트랜잭션은 반드시 Commit/Rollback
- 트랜잭션 시작 및 종료
트랜잭션은 1개의 Connection을 가져와 사용하고 반납하는 일련의 과정.
하나의 트랜잭션이 시작되면 Commit/Rollback이 호출될 때까지 하나의 트랜잭션으로 묶임.
Commit/Rollback으로 트랜잭션을 종료하는 작업 = 트랜잭션 경계 설정.
트랜잭션의 경계는 하나의 Connection을 통해 진행됨 -> 트랜잭션의 경계는 1개의 커넥션이 만들어지고 닫히는 범위 안에 존재.
@Transactional에 read-only를 사용하는 이유
read-only이기 때문이며, 영속성 컨텍스트에서 엔티티를 관리할 필요가 없으며, readOnly를 통해서 메모리 성능을 높일 수 있음.
readOnly 속성이 없으면, 데이터 조회 결과 엔티티가 영속성 컨텍스트에 관리되면,
1차 캐싱부터 변경감지까지 가능하게 된다.
하지만, 조회시 스냅샷 인스턴스를 생성해 보관하기 때문에 메모리 사용량이 증가한다.
JPA와 같은 ORM을 사용하면서 쿼리가 복잡해진다면?
JPA 자체는 정적인 상황에서 사용하는걸 권장하므로,
복잡한 쿼리나 동적 쿼리는 JPQL이나 Querydsl을 쓰자.
MyBatis vs. JPA
! ORM이란?
객체 관계 매핑으로 객체와 DB테이블 간 매핑.
0. JDBC
하나의 파일에 SQL, DB연결, 자바코드 모두 존재해서 재사용성이 좋지 않다.
1. MyBatis
Java 메소드와 SQL 간 매핑( SQL 직접 작성. )
( Java 메소드 선언과 SQL문 생성 -> MyBatis가 자동으로 그 둘 간 연결)
SQL문을 별도로 Java 코드에서 분리 -> 관리 용이.
또한 동적인 SQL 생성 기능을 제공 -> "사용자가 입력한 파라미터에 따라" 서로 다른 SQL 문을 동적으로 생성 가능.
-- title을 입력할 경우
SELECT * FROM BLOG WHERE state = ‘active’ AND title like #{title}
-- title을 입력하지 않을 경우
SELECT * FROM BLOG WHERE state = ‘active’2. JPA(ORM)
ORM은 객체와 DB 테이블간 매핑해주는 기술을 의미한다.
SQL 자동생성 및 DB데이터와 Java 객체를 매핑.
객체 모델과 관계형 DB의 테이블 간 매핑을 자동 처리.
이를 통해서 객체지향적으로 개발 가능하고 DB와 Java 간의 불일치 해소.
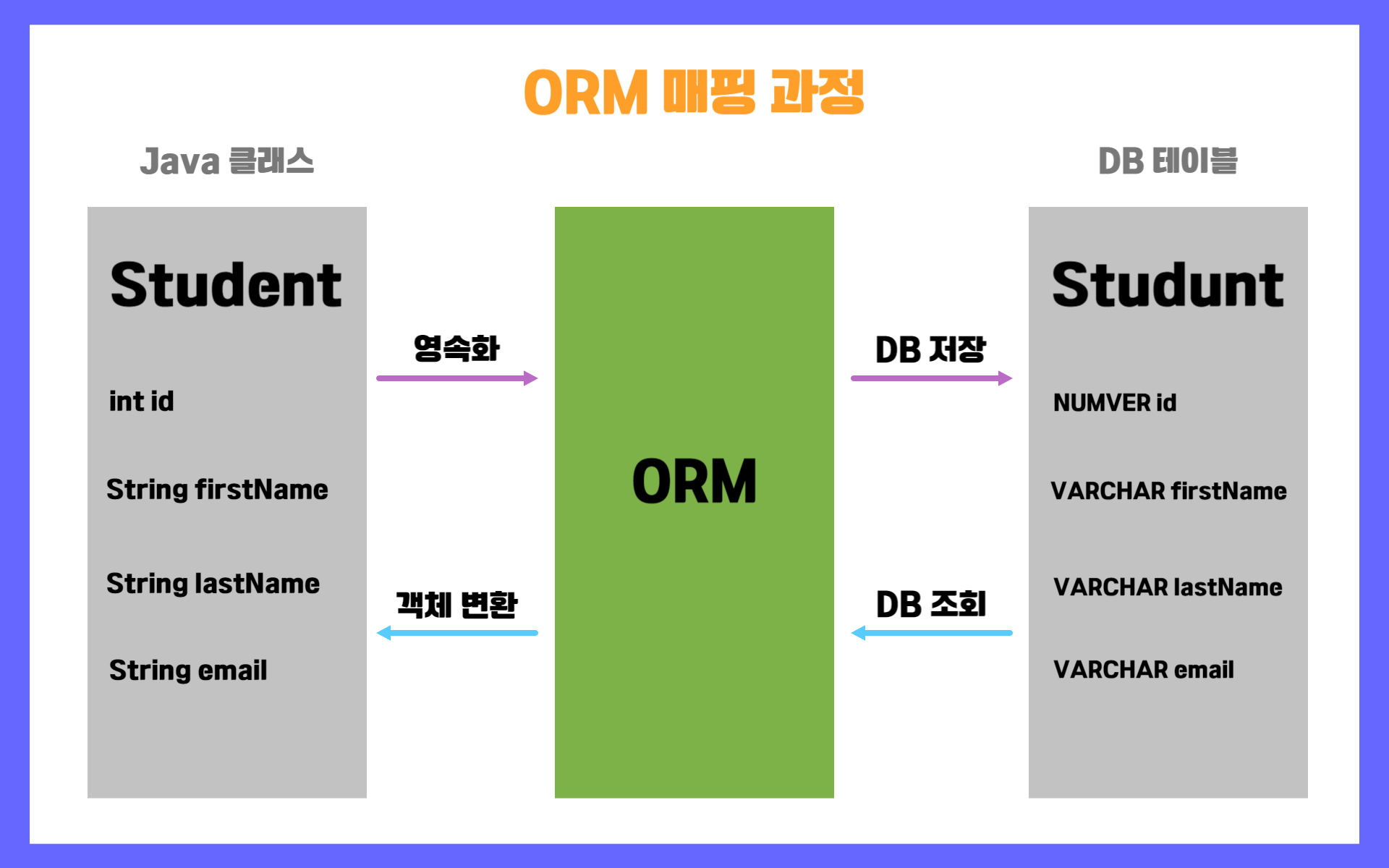
( https://www.elancer.co.kr/blog/detail/231 )
Java와 DB 데이터 간의 매핑을 자동화를 통해서
-
SQL문 작성 필요 x
-
내부적으로 java메소드에 적합한 SQL문이 자동으로 생성.
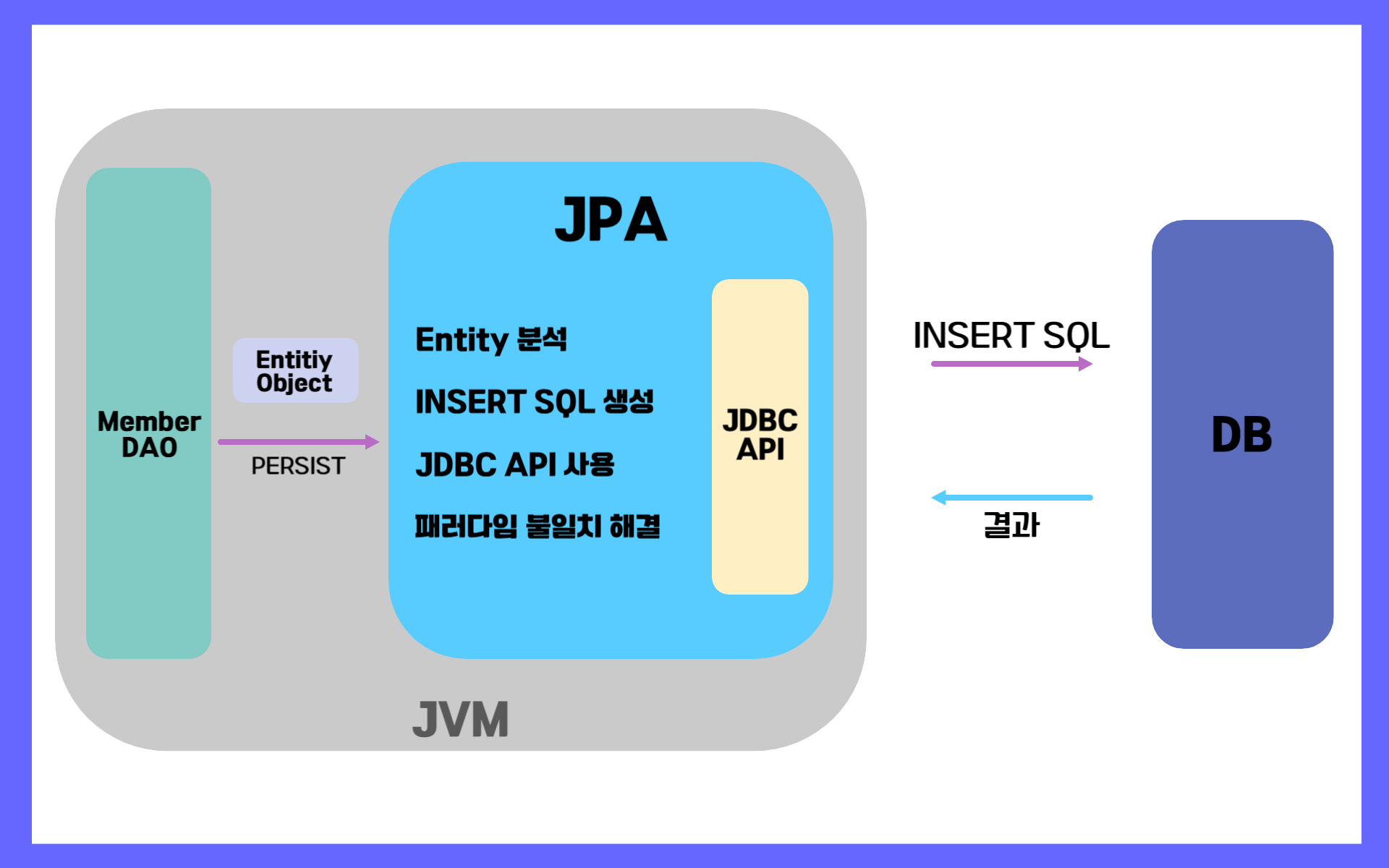
( https://www.elancer.co.kr/blog/detail/231 )
비교 분석
0. JDBC
하나의 파일에 SQL, DB연결, Java언어가 모두 존재 -> 재사용성이 안좋다.
1. Mybatis
장점 및 단점
- SQL 직접 제어
하지만,
-
CRUD 단순 작업에 반복 수작업 필요
-
DB에 종속적( 무조건 DB에 맞게 SQL문이 작성되어 있음. DB바뀌면 전체 수정 )
2. JPA
장점 및 단점
-
자동 매핑으로 개발 및 유지보수성 향상
JPA는 객체와 DB간의 자동 매핑을 지원 -
객체 지향적인 접근
-
DBMS에 독립적
DB가 변경되어도 JPA가 자동으로 적합한 SQL 방언을 만들어준다. -> SQL문을 다시 작성할 필요가 없다.
하지만,
-
복잡한 SQL 생성이 어려움 -> JPQL이나 Querydsl 쓰자
-
성능까지 고려.
JPA vs Hibernate vs Spring Data JPA
-
JPA : 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스( 구현체가 아닌 명세서 )
-
Hibernate : JPA의 구현체( 다른 것을 직접 구현해도 되지만, 굳이??? )
-
Spring Data JPA : @Repository를 이용( JPA를 쓰기 편하게 모은 모듈 )
영속성(Persistence)
-
데이터를 생성한 프로그램이 종료되더라도, 사라지지 않음
-
영속성을 갖지 않는 데이터는 단지 메모리에만 존재 -> 프로그램 종료시, 모두 삭제.
따라서, 파일 시스템, RDBMS에 데이터를 영구적으로 저장하여 영속성을 부여.
영속성 레이어
영속성을 부여해주는 계층으로 간단한 작업만으로 DB와 연동되는 시스템을 빠르게 개발할 수 있으며, 안정적인 구동을 보장.
영속성 컨텍스트
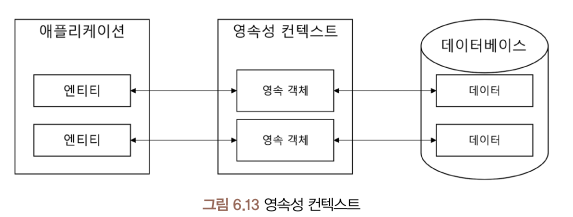
영속성 컨텍스트는 애플리케이션과 DB 사이에서 엔티티와 레코드의 괴리를 해소하는 기능과 객체를 보관하는 기능을 수행.
엔티티 객체가 영속성 컨텍스트에 들어오면 -> JPA는 엔티티 객체의 매핑 정보를 DB에 반영하는 작업을 수행.
엔티티 객체가 영속성 컨텍스트에 들어와 JPA의 관리 대상이 되는 시점부터, 해당 객체를 영속 객체라고 부름.
엔티티 매니저를 통해 영속성 컨텍스트에 접근.
영속성 컨텍스트는 "세션 단위의 생명주기"를 가짐.
즉, DB에 접근하기 위한 세션이 생성되면 -> 영속성 컨텍스트가 만들어지고,
세션이 종료되면 -> 영속성 컨텍스트도 없어진다.
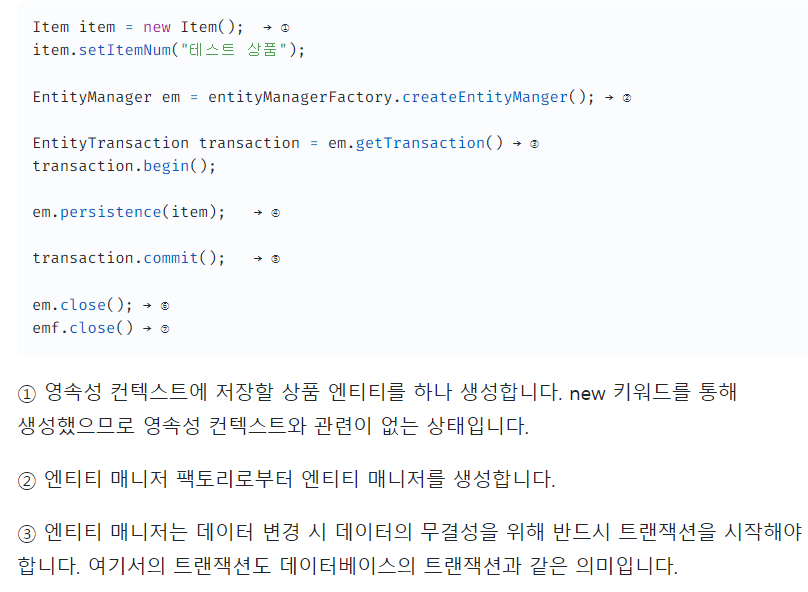
-
비영속(new)
객체 생성인데, 영속성 컨텍스트와 관련이 없음. -
영속
-
엔티티가 영속성 컨텍스트에 저장된 상태로, 영속성 컨텍스트에 의해 관리
-
반드시, 트랜잭션 커밋 시점에 DB에 반영.
-
준영속 상태
영속성 컨텍스트에 엔티티가 저장되었다가 분리 -
삭제 상태
영속성 컨텍스트와 DB에서 삭제된 상태.
영속성 컨텍스트의 특징
-
1차 캐시
: 영속상태의 엔티티는 모두 1차 캐시에 저장되고, 1차 캐시는 @Id를 키로 가지고 있는 Map이 존재한다.
엔티티를 조회시, 바로 DB에 접근하는 것이 아니라, 1차 캐시 조회 후 -> 없는 경우 DB에 접근하여 조회 후, 다시 1차 캐시에 저장. -
동일성 보장
: 영속성 컨텍스트와 엔티티의 식별자가 동일한 경우 -> 동일성이 보장. -
트랜잭션 쓰기지연
: 영속성 컨텍스트에서 DML이 발생시 바로 DB에 저장하지 않고, 트랜잭션이 커밋 시
영속성 컨텍스트의 쓰기지연 SQL 저장소에 모아둔 쿼리들을 한 번에 저장.
이때 쿼리들은 영속성 컨텍스트에 따로 저장이 되며 커밋을 실행하게 되면, flush를 통해
쿼리들을 DB에 저장 -> 최종적으로 commit을 하여 DB에 쿼리를 반영.
- 변경 감지
영속성 컨텍스트의 1차 캐시에는 스냅샷을 통해 엔티티의 변경을 감지.
JPA는 1차 캐시에 "DB에서 처음 불러온" 엔티티의 스냅샷을 가지고 있음.
1차 캐시에 저장된 엔티티와 스냅샷을 비교 후, 변경 내용이 있다면 UPDATE SQL문을 쓰기 지연 SQL 저장소에 담아둔다.
이후, DB 커밋 시점에 변경 내용을 자동으로 반영.(update 호출이 필요없음)
변경감지는 오직 영속 상태의 엔티티에만 적용.

( https://velog.io/@zxzz45/%EA%B8%B0%EC%88%A0-%EB%A9%B4%EC%A0%91JPA#%EC%98%81%EC%86%8D%EC%84%B1persistence )
JPA 사용 이유
-
SQL 중심 -> 객체지향적
-
생산성
-
유지보수성




( https://velog.io/@zxzz45/%EA%B8%B0%EC%88%A0-%EB%A9%B4%EC%A0%91JPA#jpa%EB%9E%80 )
JPA 장점
-
특정 DB에 종속되지 않음.
JPA는 추상화한 데이터 접근 계층을 제공. yml에 어떤 DB를 사용하는지만 알려주면, 해당 DB로 변경 가능. -
객체지향 프로그래밍
-
생산성 향상
DB 테이블에 새로운 컬럼이 추가 -> JPA는 오직 테이블과 매핑된 클래스에 필드만 추가 !
SQL문 직접 작성 대신에 객체를 사용하여 동작함 -> 재사용성 우수. -
지연로딩과 즉시로딩
-
지연 로딩 : 객체가 실제 사용시에만 로딩
-
즉시 로딩 : JOIN SQL로 한번에 연관된 객체까지 미리 조회
JPA 단점
-
복잡한 쿼리 처리
Native SQL을 통해 기존의 SQL문을 사용할 수 있지만, 특정 DB에 종속.
따라서, JPQL을 사용. -
성능 저하 위험.
객체 간의 매핑 설계 실패 -> 성능 저하. -
동적 쿼리를 사용 -> 가독성이 저하.
QueryDsl로 해결 가능.
JPQL
-
객체지향 쿼리언어
-
SQL문과 유사하지만, DB의 테이블에 직접 연결되는 것이 아니라, JPA 엔티티에 대해 동작.
( 테이블이 아닌 엔티티에서 표현하고 있는 컬럼의 이름을 쓴다. )
객체를 검색하는 쿼리.
동작과정
- JPQL을 실행 -> 영속성 컨텍스트로 요청 전송.
- 영속성 컨텍스트는 "1차 캐시의 엔티티 존재 여부 상관없이" DB에 질의
- DB 질의를 통해 조회된 데이터는 영속성 컨텍스트가 다시 받음.
- 데이터를 전달받은 영속성 컨텍스트는 엔티티를 초기화 후, 캐시에 저장.
- 캐시에 저장한 후 -> 엔티티를 반환.
