배경
- pandas data frame을 사용하는데 어떤경우에는 data frame 형식으로 리턴되고 어떤 경우에는 series로 리턴되길래 이 글을 작성하게 됨
- kaggle
reviews = pd.read_csv(...)
reviews.groupby('taster_twitter_handle') => dataframe이 조각 조각
reviews.groupby('taster_twitter_handle').apply(labmda df : 어쩌고) => 조각조각 dataframe마다 작업
reviews.groupby('taster_twitter_handle').taster_twitter_handle.count() => series, key : taster_twitter_handle의 값들, value : count
reviews = pd.read_csv(...)series로 리턴
case1
best_rating_per_price=reviews.groupby('price').points.max()- 이미 price로 groupby를 하면서 price가 key로 지정되고, points.max()를 value로 붙이는 리스트들이 생성되는 모양임
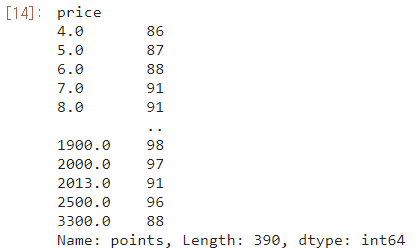
data frame로 리턴
case1
best_rating_per_price=reviews.groupby('price').apply(lambda df : df.loc[df.points.idxmax()]).loc[:,['points']]- price로 groupby가 된 dataframe을 대상으로 작업을 하는 모양임.
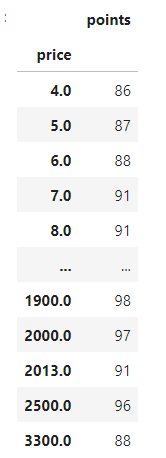
case2
reviews.groupby('variety').price.agg([min,max])- agg라서 그런가?
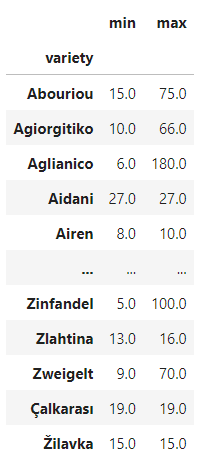
비교
case1
loc이 붙으면 series
series
reviews.groupby('variety').apply(lambda df : df.sort_values(by='price', ascending=True)).loc[:, 'price']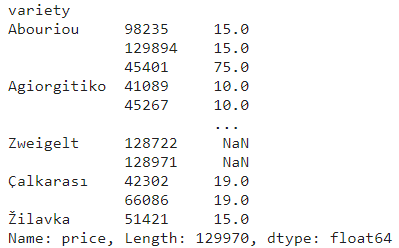
dataframe
reviews.groupby('variety').apply(lambda df : df.sort_values(by='price', ascending=True))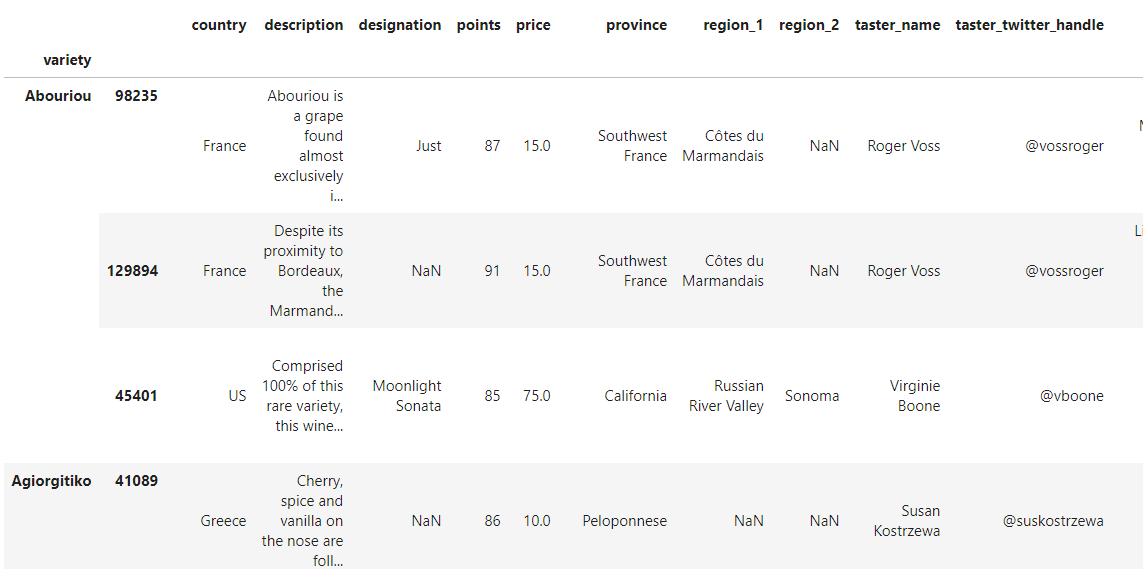
case2
series
dataframe
reviews.groupby(['country', 'variety']).apply(lambda df : df.sort_values(by='points'))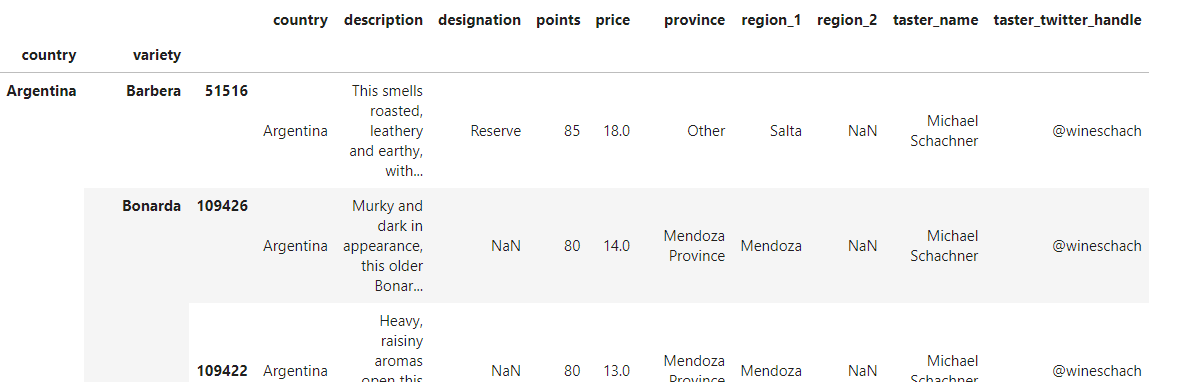
case3
# 대충 csv로 읽은 dataframe
home_data = pd.read_csv(iowa_file_path) series
X = home_data.SalePrice
X = home_data['SalePrice']
dataframe
X = home_data[['SalePrice']]
X = home_data[['SalePrice', 'LotArea]]
features = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']
X = home_data[features]
함수
series
.value_counts()

newbieski