머신러닝, AI
1.딥러닝 환경 준비

환경을 준비해본다https://tutorials.pytorch.kr/beginner/blitz/cifar10_tutorial.htmlhttps://www.anaconda.com/products/distributionhttps://colab.r
2.경사하강법
어쩌다보니 경사하강법. 하지만 꼭 하긴 해야함kaggle -> 머신러닝 -> jupyter notebook -> pytorch -> quickstart -> 어렵네 -> 예제로 배우는 파이토치(PYTORCH) -> 이해가 안감https://tutorials.p
3.linear regression
선형회귀? 암튼.검색하면 공부할 내용은 많을테고, 내가 깨달은 점 위주로 기록데이터의 분포를 "선"으로 표현하려고함데이터 차원이 많아지면 선 -> 면 -> 고차원의 면 이런 식일 것임대충 모델링한 식과 진짜 값의 차이들이 있을 것임차이를 절대값 씌우고 더하고 하기보다
4.MLE
Maximul Likelihood Estimation찾아보면 공부할 내용은 많고, 내가 느낀점만 기록와닿을듯 아닐듯 이해하기 힘들었는데 이렇게 이해해보자원래 어떤 분포가 있음 성공/실패, 발생/안발생 두 가지 사건이 있다고 치고p/(1-p)의 확률로 사건이 일어나는 세
5.python graph
python으로 그래프 그리는 비슷비슷한 것을 자꾸 검색하는 것 같아서 정리해본다.
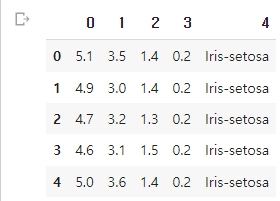
6.Pandas Data Frame
pandas data frame을 사용하는데 어떤경우에는 data frame 형식으로 리턴되고 어떤 경우에는 series로 리턴되길래 이 글을 작성하게 됨kaggle
7.numpy boolean index
numpy boolean index를 기록해보려고 한다.값과 같으면 True, 다르면 False로 해서, numpy.ndarray를 새로 만듬대괄호 안에 인자를 넣는데 row, column을 의미함row는 slicing 표현도 가능하고, array도 가능함ndarray
8.learning rate
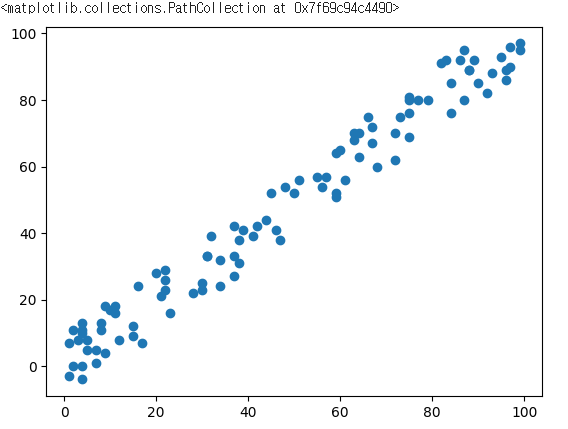
learning rate가 남의 다른 사람 이야기인줄 알았는데, 간단한 사례에서 경험해본 시행착오를 정리해본다(x, y) 로 표현되는 데이터의 간단한 선형회귀를 경사하강법을 이용해서 간단하게 python으로 구현해보려고 함.데이터는 다음과 같이 생김. 딱 봐도 선형회귀
9.컬럼 별 유니크 값
컬럼별 유니크 값 처리하는 코드가 마음에 들어서 기록해봄https://www.kaggle.com/code/goooora/exercise-categorical-variables/edit앞에서 csv로부터 pandas 객체를 만들어서 X_train 까지 만들어 놓
10.타입별 컬럼 처리하는 코드
pandas 객체에서 타입별로 컬럼을 추출해서 처리하는 코드가 마음에 들어서 가져옴X_train_full은 pandas 객체숫자 컬럼을 추출숫자가 아닌데, 값의 가지수가 10개 미만인 컬럼 추출이런 컬럼들만 다룰꺼야cname으로 배열을 만들꺼야cname은 X_train
11.kaggle 제출 하는 부분 코드
kaggle에서 제출하는 쪽 코드만 기록해봄"집값 예측" 문제로 설명https://www.kaggle.com/competitions/home-data-for-ml-course데이터를 적절히 예측한 결과를 제출하면되는데(ID, 예측값) 형태의 csv 파일을 만들
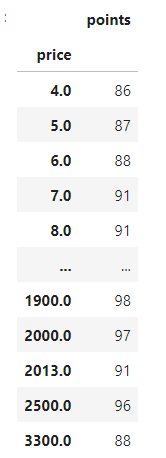
12.pandas iloc으로 column 분리할 때 미묘한 차이
iloc으로 똑같이 컬럼을 분리한다고 생각하지만, shape가 다른 경우가 있다이번에는 .values를 사용해서 numpy로 변환해서 확인해보자4를 붙이면 진짜 column 별로 떼어서 dataframe을 만든다
13.norm 연습
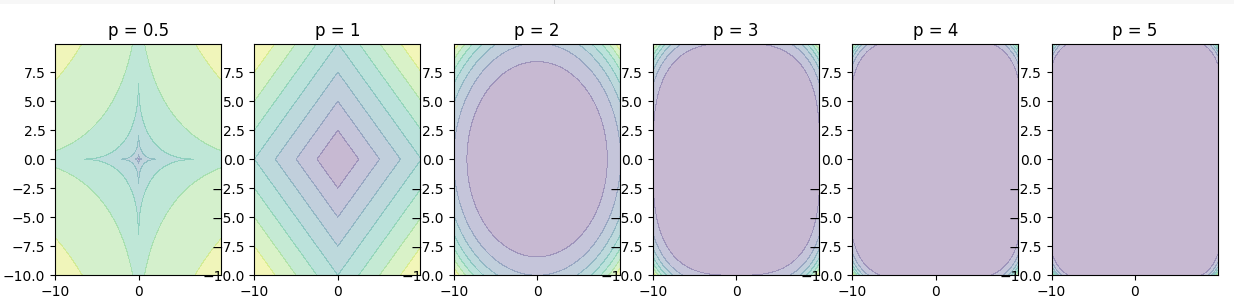
연습으로 norm을 시각화해봄https://ekamperi.github.io/machine%20learning/2019/10/19/norms-in-machine-learning.html
14.entropy, gini 비교
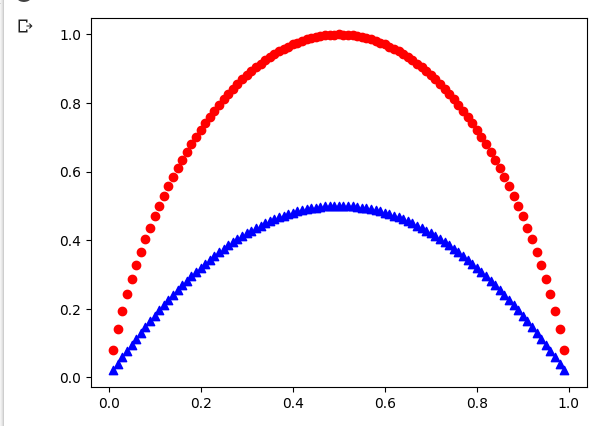
impurity 지표인 entropy랑 gini를 비교해서 그려봄(두 개의 분류가 있다고 가정)${entropy : -\\sum{p(i|t)log_2p(i|t)}}$${gini : 1-\\sum{p(i|t)^2}}$