목적
learning rate가 남의 다른 사람 이야기인줄 알았는데, 간단한 사례에서 경험해본 시행착오를 정리해본다
해보려고 했던 것
- (x, y) 로 표현되는 데이터의 간단한 선형회귀를 경사하강법을 이용해서 간단하게 python으로 구현해보려고 함.
- 데이터는 다음과 같이 생김. 딱 봐도 선형회귀 잘 될 것처럼 생김
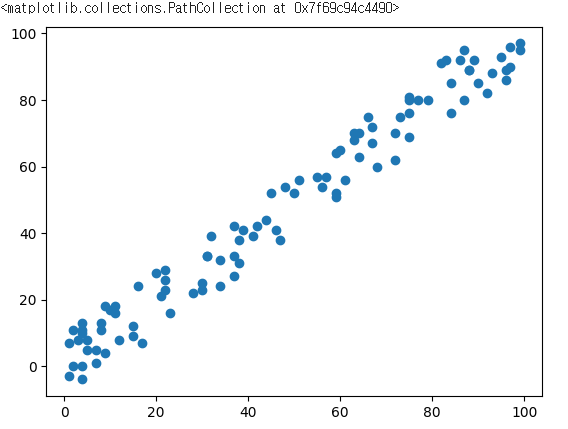
- 에러를 "제곱 오차의 합"으로 정의하고, 에서 를 조절하여 제곱 오차의 합을 최소로하는.....
- 머신러닝 배우면 기본으로 배우는 경사하강법의 이상도 이하도 아님
안되던 것
- 공부했던 것을 떠올리면서 하나씩 python으로 구현을 해봄.
- 나중에 정리된 전체 코드를 보여주기 전에, 간단하게 제시하면 다음과 같음
def mygradient(x, y) :
global errors, w, b
hy = w * x + b;
d = y - hy
g = x.dot(d)
w += g * learning_rate
b += d.sum() * learning_rate
print(g, w, b)
err = d ** 2
errors.append(err.sum())- w, b는 0~1 사이 랜덤 실수로 정함
- learning_rate는 너무 작으면 발산한다고 해서 0.001정도로 해보고
- 반복횟수는 100번정도로 했음
- 그런데 실행해보니 오류도 나고, 그래프를 찍어보면 영 이상한 값들이 나옴
- 나중에 돌이켜보니 오류는 제곱 오차의 합이 너무 커서 발생하던 것
- 결국 "발산" 하고 있었던 것이었음
- 왜 learning_rate가 0.001인데 발산하지? 0.0001, 0.00001 에서도 계속 발산을 해서 코딩을 잘못했다고 판단하였음
- 결국 learning_rate를 0.0000001로 하니까 수렴하는 그래프를 얻을 수 있었음
learning_rate별로 그려보자
- 그래서 궁금해서 learning_rate 별로 선형회귀 학습이 어떻게 되는지 한번 실험을 해봤음
data
X : 0 ~ 100까지 정수 100개
Y : X에서 -10 ~ +10 의 차이를 갖는 값
코드
import pandas as pd
from io import StringIO
import numpy as np;
import matplotlib.pyplot as plt
np.random.RandomState(1)
X = np.random.randint(100, size=100)
DY = np.random.randint(-10, 10, size=100)
Y = X + DY
plt.scatter(X, Y)parameter
w와 b는 0 ~ 1 사이 실수
코드
w = np.random.rand()
b = np.random.rand()
print(w, b)
0.8764259753937205 0.890855917746639learning_rate는 0.1, 0.01, .... 10개
epochs는 모두 50개
코드
learning_rate = [0.1]
epochs = [50]
for _ in range(9) :
learning_rate.append(learning_rate[-1] / 10)
epochs.append(50)선형 회귀
여러번 실험을 하려고 클래스로 잘 정리해보았음
gradient를 계산해서 w, b를 갱신하는 부분과
epoch만큼 반복하는 부분
학습한 값으로 예측하는 부분임
class myperc:
def __init__(self, w, b, lr, epochs) :
self.w_ = w
self.b_ = b
self.lr_ = lr
self.epochs_ = epochs
self.errors_ = []
def mygradient(self, x, y) :
hy = self.w_ * x + self.b_;
d = y - hy
g = x.dot(d)
self.w_ += g * self.lr_
self.b_ += d.sum() * self.lr_
err = d ** 2
self.errors_.append(err.sum())
def train(self, x, y) :
for _ in range(self.epochs_) :
self.mygradient(x, y)
def pred(self, x) :
pp = self.w_ * x + self.b_;
return pp결과
- learning_rate가 부터 되는 것 같다.
- 이 값보다 작으면 발산한다.(y축 값을 보면 엄청나다)
- 오차 제곱의 합은 대략 3500 근처에서 수렴하는 것 같다
- 학습률이 직선처럼 보이는 부분은 반복횟수를 더 늘려서 확인을 해보면 다를수도 있겠다
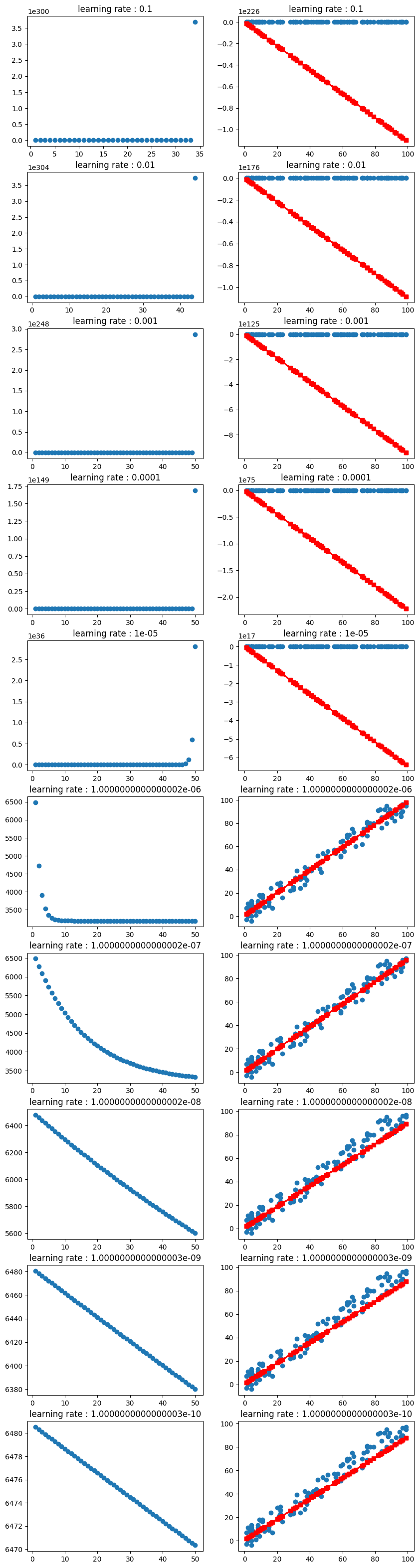
추가 실험
- 학습률이 직선처럼 보이는 값 대상으로 epoch를 50 -> 1000으로 늘려서 실험해봤다
learning_rate = [0.00000001]
epochs = [1000]
for _ in range(4) :
learning_rate.append(learning_rate[-1] / 10)
epochs.append(50)
tr = []
YY = []
for i in range(len(learning_rate)) :
obj = myperc(w, b, learning_rate[i], epochs[i])
obj.train(X, Y)
tr.append(obj)
YY.append(obj.pred(X))결과
은 수렴하는 것 처럼 보인다
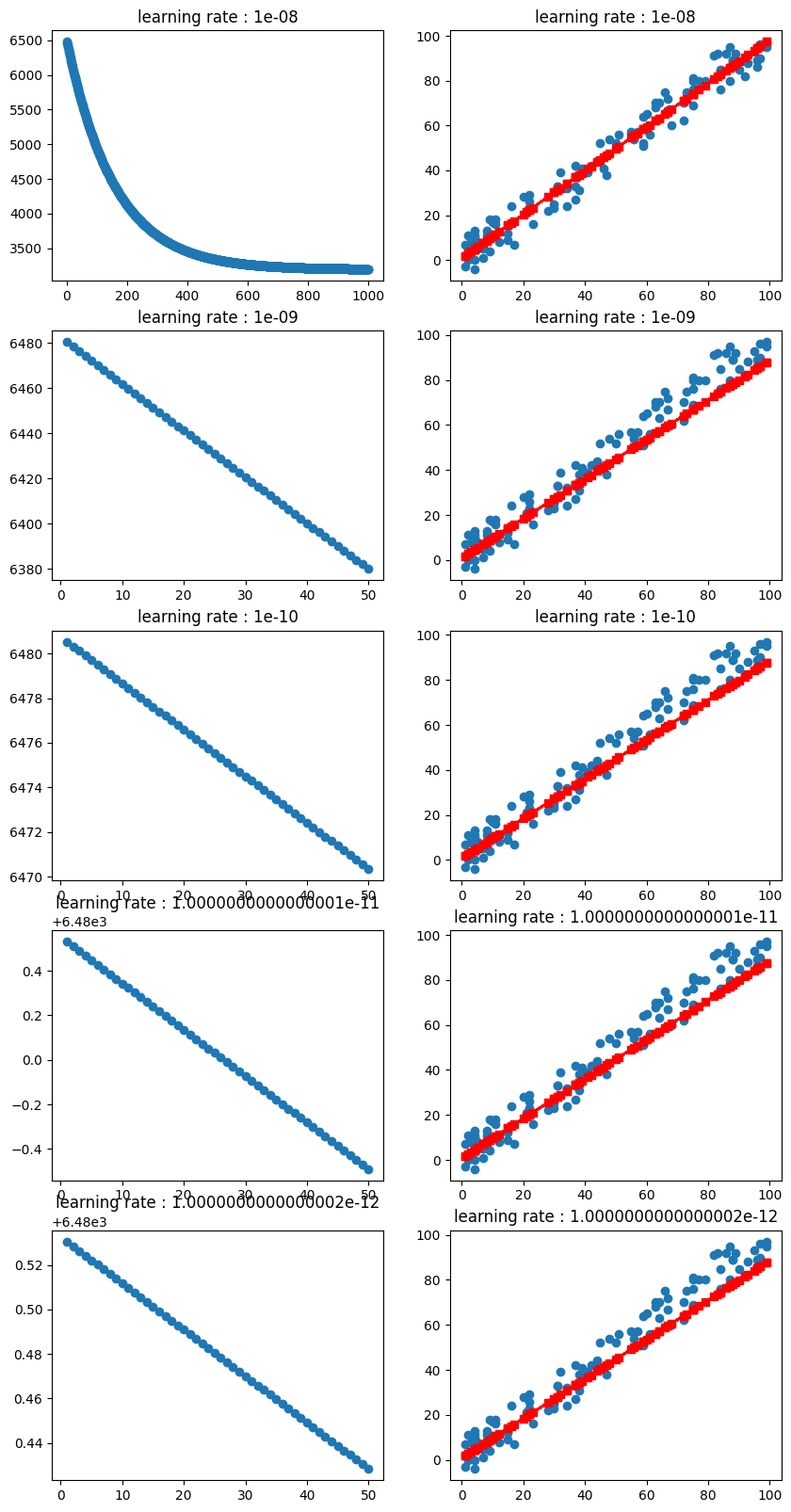
추측
- w, b 값이 0 ~ 1 사이 실수라서 learing_rate도 영향을 받는게 아닌가 싶다.
전체코드
import pandas as pd
from io import StringIO
import numpy as np;
import matplotlib.pyplot as plt
np.random.RandomState(1)
X = np.random.randint(100, size=100)
#Y = np.random.randint(100, size=100)
DY = np.random.randint(-10, 10, size=100)
#X = np.array([1,2,3,4,5,6,7,8,9,10])
#Y = np.array([1,2,3,4,5,6,7,8,9,10])
Y = X + DY
plt.scatter(X, Y)
class myperc:
def __init__(self, w, b, lr, epochs) :
self.w_ = w
self.b_ = b
self.lr_ = lr
self.epochs_ = epochs
self.errors_ = []
def mygradient(self, x, y) :
hy = self.w_ * x + self.b_;
d = y - hy
g = x.dot(d)
self.w_ += g * self.lr_
self.b_ += d.sum() * self.lr_
#print(g, w, b)
err = d ** 2
self.errors_.append(err.sum())
def train(self, x, y) :
for _ in range(self.epochs_) :
self.mygradient(x, y)
def pred(self, x) :
pp = self.w_ * x + self.b_;
return pp
w = np.random.rand()
b = np.random.rand()
print(w, b)
learning_rate = [0.1]
epochs = [50]
for _ in range(9) :
learning_rate.append(learning_rate[-1] / 10)
epochs.append(50)
tr = []
YY = []
for i in range(len(learning_rate)) :
obj = myperc(w, b, learning_rate[i], epochs[i])
obj.train(X, Y)
tr.append(obj)
YY.append(obj.pred(X))
plt.figure(figsize=(10, 40))
for i in range(len(learning_rate)) :
plt.subplot(len(learning_rate), 2, i * 2 + 1)
plt.title("learning rate : " + str(learning_rate[i]))
plt.scatter(range(1, tr[i].epochs_ + 1), np.array(tr[i].errors_))
plt.subplot(len(learning_rate), 2, i * 2 + 2)
plt.title("learning rate : " + str(learning_rate[i]))
plt.scatter(X, Y)
plt.plot(X, YY[i], "rs-")
learning_rate = [0.00000001]
epochs = [1000]
for _ in range(4) :
learning_rate.append(learning_rate[-1] / 10)
epochs.append(50)
tr = []
YY = []
for i in range(len(learning_rate)) :
obj = myperc(w, b, learning_rate[i], epochs[i])
obj.train(X, Y)
tr.append(obj)
YY.append(obj.pred(X))
plt.figure(figsize=(10, 20))
for i in range(len(learning_rate)) :
plt.subplot(len(learning_rate), 2, i * 2 + 1)
plt.title("learning rate : " + str(learning_rate[i]))
plt.scatter(range(1, tr[i].epochs_ + 1), np.array(tr[i].errors_))
plt.subplot(len(learning_rate), 2, i * 2 + 2)
plt.title("learning rate : " + str(learning_rate[i]))
plt.scatter(X, Y)
plt.plot(X, YY[i], "rs-")
newbieski