
안녕하세요! NewCodes 개발자입니다.
NewCodes는 기술 블로그 큐레이팅 서비스입니다.
각 기업의 최신 기술 블로그를 모아서 한 번에 보여주고 있어요!
2025년 5월부터 저 혼자 군대에서 만들기 시작했어요!
현재에도 계속해서 서비스를 개선하며 운영하고 있습니다 😊
저번 글에서는 검색어 자동완성 API 최적화에 대해 다뤘었는데요.
이번 글에서는 검색 기능을 고도화한 경험에 대해 공유하려 합니다.
단순한 키워드 매칭이 아니라, 사용자의 쿼리를 이해하는 검색을 구현했습니다.
해당 글이 주로 다루는 점
- 사용자의 검색어를 이해하기 위한 여러 기술
- 하나의 기능을 고도화하기 위해 필요한 고민과 흐름
- PostgreSQL을 기반으로 벡터 검색을 8초 → 1초로 최적화한 과정
한 피드백이 왔다!
2025년 11월 24일, 사용자로부터 한 피드백이 왔다.
처음에 해외카테고리 선택후 '아마존'이라 검색했는데 결과가 1개 나오고, 'amazon'이라 해야 많이 나오네요.
검색이 메인이니 자동완성이나 연관검색 기능 등 있으면 좋을것 같습니다.
해당 피드백이 트리거가 되어 검색 전반의 기능을 개선하고자 했다.
2025년 11월 24일부터 검색 기능을 고도화하기 시작해서 군대에서의 3달을 투자했다.
개선하기로 한 이유
사용자의 피드백을 수용했던 건 프로젝트의 목적에 부합했기 때문이다. NewCodes는 좋은 글을 널리 알리기 위해 존재한다.
-
현재에는 최신 글만 잘 노출해주고 있었다. 과거의 좋은 글은 그저 묻히는 문제가 있었다. 검색은 이러한 문제를 해결할 수 있는 NewCodes의 핵심 기능이다.
-
또한, 검색은 테마별 글 모음 기능을 구현하는 데에도 기반이 된다. 다른 사용자에게 이런 피드백도 있었다.
Featured Section(특정 목적을 가지고 선별된 글 모음)을 두어 유저의 콘텐츠 탐색 시간을 줄일 것. 지금처럼 그냥 뿌려두면 원래 해결하고자 했던 문제가 그대로 있음.
이를 보고 테마별 글 모음 기능을 고안했다. 각 테마에 맞는 글을 모으기 위해서는 검색이 잘 되어야 한다. 그래야 빠르고 정확하게 해당 기능의 완성도를 높일 수 있다.
-
또한, 사용자가 글 하나를 읽을 때 그와 관련된 다른 글도 추천해주는 기능도 만들 수 있다.
이렇게 검색 기능을 고도화했을 때 얻을 수 있는 기대 효과가 크기에 리소스를 투입하는 건 합리적이라 판단했다.
AS-IS
'아마존'이라고 검색해보자.
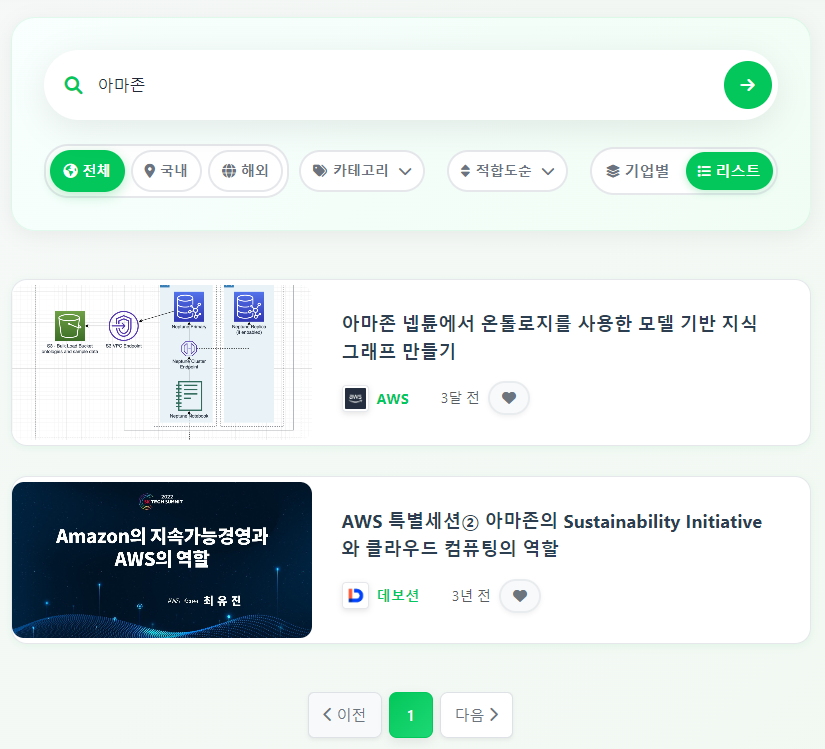
제목에 '아마존' 키워드가 포함된 글만 노출된다.
사용자는 원하는 결과가 나오지 않자 amazon이라 검색했을 것이다.
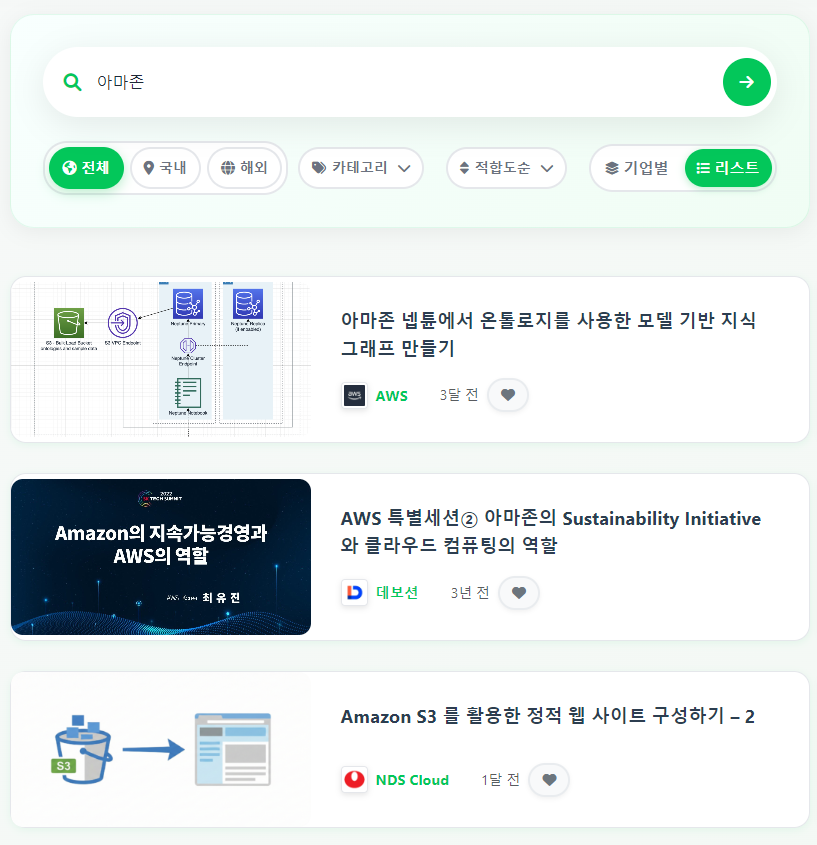
TO-BE
'아마존' 검색 시, 'amazon'까지 찾는 모습이다.
또한, 구체적인 의미를 담은 쿼리도 검색이 되어야 한다.
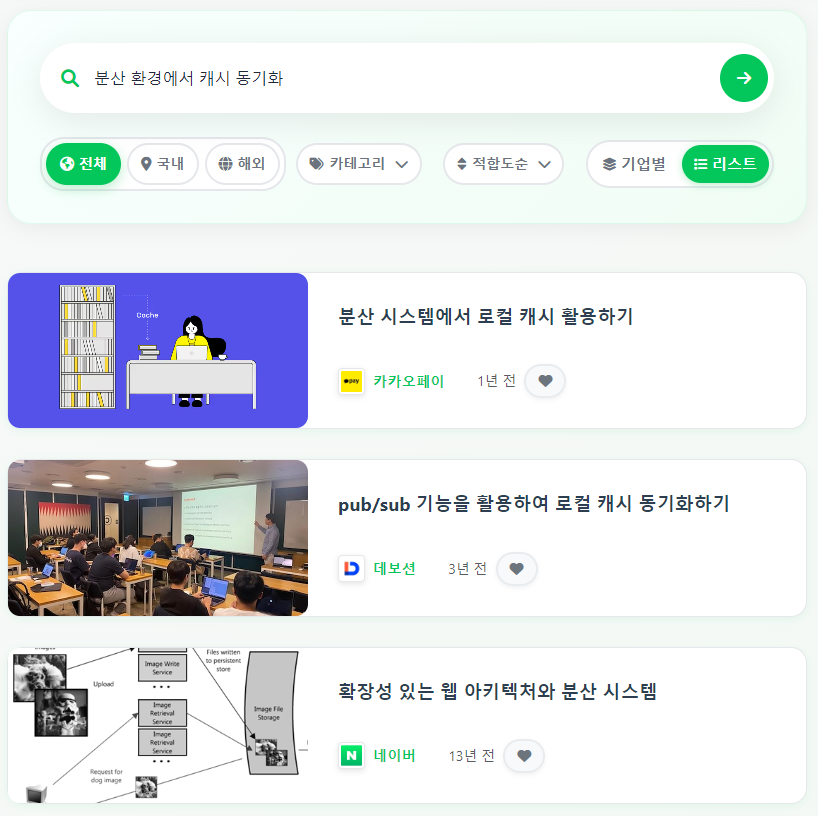
키워드가 제목에 포함되어 있지 않아도 본문의 내용과 유사하면 검색이 된다.
본문의 내용까지 고려함으로써 사용자가 원하는 주제의 글을 더욱 빠르게 찾을 수 있다. 이를 위해 Semantic Search를 도입하려 한다.
- Semantic Search: 사용자의 검색 의도를 이해하고 맥락을 파악하는 검색을 의미한다. 이를 위해 주로 머신러닝 혹은 인공지능의 도움을 받는다.
- Semantic Search를 위해서 대게는 임베딩과 같은 기술을 사용하여 사용자의 쿼리를 이해하고 결과를 보여준다.
- 임베딩이란 텍스트의 의미를 숫자로 표현한 걸 의미한다. 이 숫자는 고차원 공간 내에서 특정 위치를 가리킨다. Vector끼리 얼마나 가깝냐, 얼마나 비슷한 각도이느냐에 따라서 유사도를 판별할 수 있다.
1. 새로운 검색 시스템을 설계해보자!
1) 사용자가 NewCodes에서 검색하는 유형
NewCodes에서 사용자는 다음과 같은 정보를 얻기 위해 검색할 수 있다.
- 개인 블로그가 아닌 신뢰도 있는 정보
- 기업의 실제 사례, 실무를 토대로 한 정보
이 정보를 토대로 특정 기능을 구현 및 개선하기 위한 배경지식을 쌓을 수 있다. 기술적인 선택에 대한 검토를 할 수도 있으며, 개발문서에 레퍼런스로 첨부할 수도 있다.
그렇다면 사용자는 구체적으로 어떤 검색어들을 입력할까?
사용자의 검색 케이스를 아래와 같은 유형으로 분류할 수 있다.
- Single-term Query
Redis
- Multi-term Query
Redis 캐시
- Specific Intent Query
Redis TTL 설계 방법
- Exploratory Query
대규모 트래픽에서 캐시를 어떻게 설계해야 하나
- Conversational Query
Redis 캐시를 붙였는데 갱신 타이밍 때문에 데이터가 자꾸 틀려. 실무에서 안전하게 설계한 사례 글을 찾아줘.
NewCodes에서는 어떤 유형의 검색어까지 지원할 지 정해야 한다. 이에 대한 기준을 먼저 잡아야 어떤 기술을 어떻게 쓸 지 선택할 수 있기 때문이다.
NewCodes에서는 3번까지 지원하기로 했다. 우선 1, 2, 3번이 완성도 높게 구현이 되어야 4, 5번을 원활하게 진행할 수 있다.
4, 5번의 검색 품질을 높이기 위해서는 LLM을 기반으로 한 기술이 필요하다. 이를테면 RAG(Retreival-Augmented Generation)를 사용해서 검색 결과를 요약 및 가이드해줄 수 있다.
LLM을 포함한 RAG와 같은 기술을 염두에 두되, 우선 1, 2, 3번을 위한 검색 완성도를 높여보자.
2) 외부 검색 서비스 검토
외부 검색 서비스를 사용해 쉽고 빠르게 검색 기능을 업그레이드하는 선택지도 있다.
라이브러리나 프레임워크 활용하듯이 이미 있는 걸 잘 활용할 줄 알아야 한다. 구현 시간을 단축하고, 유지보수 및 운영에 들이는 노력을 줄일 수 있기 때문이다. 그래서 탐색해봤다.
대표적으로 구글에서 지원하는 서비스 2가지가 있다.
- Programmable Search Engine By Google
- 구글 검색 엔진을 빌려서 검색하게 해주는 서비스
- 웹 페이지 URL을 통해 인덱싱 시키고 해당 URL 내에서만 검색하게 함
- 가격: 무료 버전(광고 포함), 유료 버전(1,000개 당 5달러)
- 이를 사용하는 서비스: geeknews
- Vertex AI Search
- 구글 클라우드에서 제공하는 완전 관리형 AI 검색 서비스
- Hybrid Search, RAG 등 지원
- 직접 데이터를 넘겨서 인덱싱 시키는 방식
- 가격: Standard Edition 기준 쿼리 1,000개 당 약 $1.5 (Generative Answers 포함 시 더 높은 과금 구조)
- 이를 사용하는 서비스: 컬리
이러한 장점에도 위 서비스를 선택하지 않았다. 그 이유는 다음과 같다.
- 제어권의 상실 -> 세부적인 튜닝이나 확장하기 어려운 구조
- 랭킹 로직을 세밀하게 튜닝하기 어렵다.
- 검색 로그를 완전하게 수집/분석하기 어렵다.
- 정책 변경 및 서비스 지속성 측면에서 장기적인 불확실성이 존재한다. 실제로 Programmable Search Engine By Google의 유료 API는 2027년 1월 1일에 지원 중단된다고 한다.
- 직접 만들어보며 학습하는 방법 실천 -> 백엔드 개발자로서의 역량 쌓기
- 이러한 검색 시스템을 만들고 운영하는 측면에서도 의미가 있다. 이러한 시스템을 운영하고 개선하면서 최적화하는 게 백엔드 개발자로서 중요한 역할이기 때문이다. 또, 검색은 단순 기능이 아니라 NewCodes의 핵심 기능에 해당한다.
- 무언가를 학습할 때 그걸 해부하는 게 아니라 직접 만들어보는 게 더 도움이 많이 된다. 이는 네이버 부스트캠프 때 배웠던 태도 중의 하나이다. 검색 시스템을 학습하기 위해서는 직접 만드는 게 낫다고 생각했다.
그러나 위 서비스는 매력적인 선택지인 건 분명하다. 만약 해당 프로젝트에서 검색이 단순 부가 기능이거나, 빠르게 도입해야 하는 상황이었다면 외부 검색 서비스를 선택했을 것 같다. 다음에 다른 프로젝트에서 검색을 구현한다면 해당 기술을 쓰는 걸 적극 고려할 것이다.
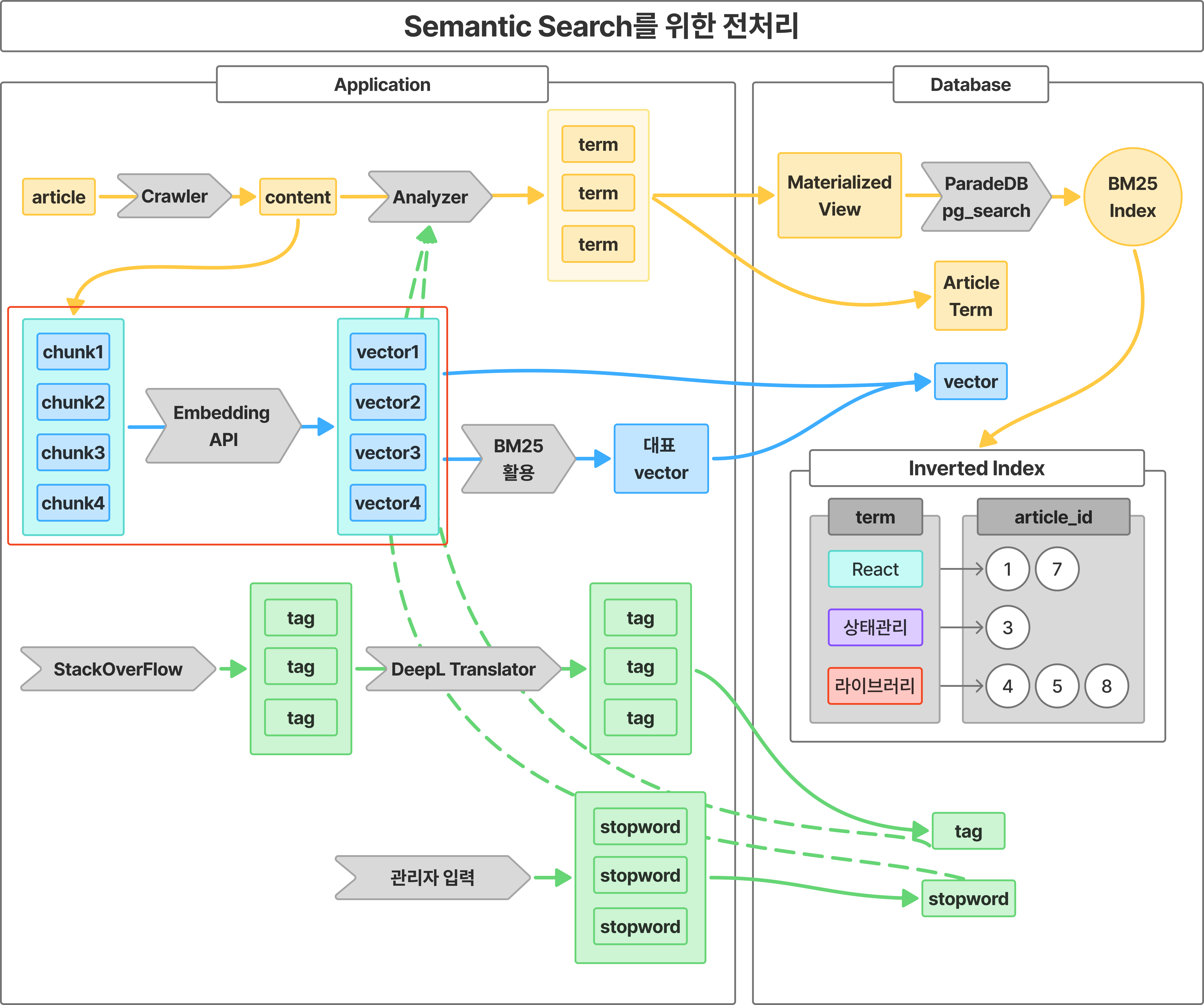
3) Semantic Search를 위한 전처리
Semantic Search를 위해서는 사용자의 검색 이전에 많은 전처리 작업이 필요하다. 전체적인 그림은 아래와 같다.
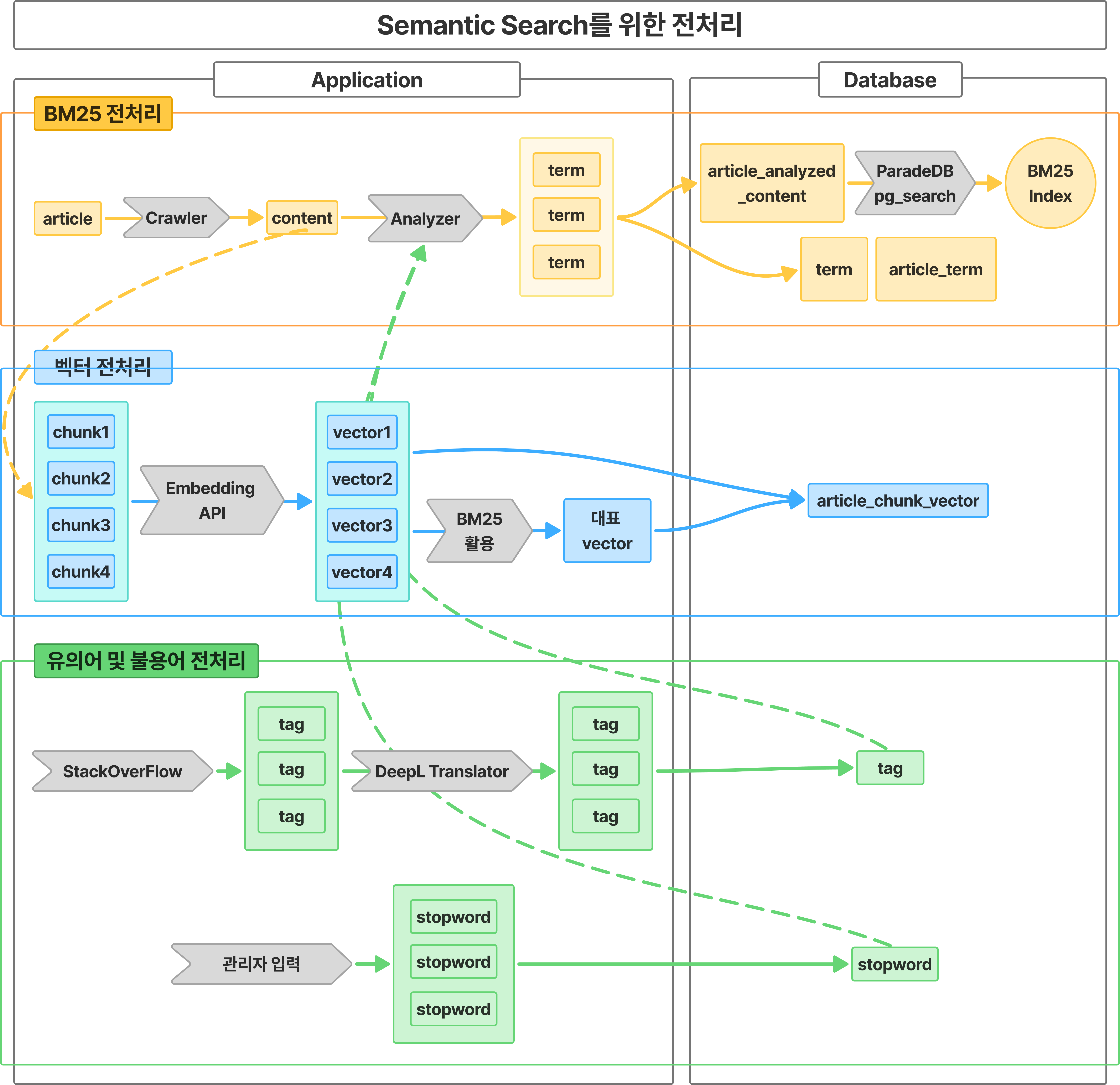
위를 어떻게 구현했는지는 뒤에서 차차 살펴보자.
물론 처음부터 이렇게 완성도 있게 설계를 한 건 아니다. 직접 구현하면서 시행착오를 겪고 구체화한 부분도 있다.
핵심은 BM25와 임베딩 벡터 두 가지를 활용한다는 점이다.
임베딩 벡터를 도입한 이유
사용자 검색어의 의미를 이해하기 위함이다. 임베딩 벡터는 단순 키워드 매칭이 아니라 검색어와 의미가 유사한 글을 찾게 해준다.
현재 임베딩 모델은 문장 및 문단 수준의 의미를 안정적으로 표현할 수 있을 정도로 발달되었다. API로 제공하는 서비스들도 많기에 선택지도 다양하다.
Semantic Search를 위해서 대안은 물론 존재한다. 문서 간 관계를 그래프로 구축하여 의미 네트워크를 형성하는 방식이 있다. 그러나 이 방식은 관계 정의와 업데이트 비용이 크고, 문서 수가 증가할수록 관리 복잡도가 급격히 높아진다. 지속적으로 새로운 글이 추가되는 NewCodes의 특성상 이러한 접근은 적합하지 않았다.
BM25를 도입한 이유는 뒤에서 더 알아보자.
4) 검색 시 내부에서 일어나는 일
위에서의 전처리 작업을 바탕으로 검색하면 내부 모습은 이러하다.

그림에서 보다시피 BM25와 임베딩 벡터를 이용해 article을 찾고 rerank를 한다.
각각을 어떻게 구현했고 어떤 고민이 있었는지는 차차 살펴보자.
2. MySQL -> PostgreSQL 마이그레이션 결정
벡터 검색을 지원하기 위해 기존에 쓰고 있던 MySQL에서 PostgreSQL로 마이그레이션 하기로 했다.
PostgreSQL로 결정한 이유
이유를 먼저 정리하자면 이러하다.
- ElasticSearch와 같은 검색 엔진을 별도로 두기에는 인프라 비용 부담
처음에는 ElasticSearch가 매력적인 선택지로 보였다. 하지만 이를 위해서는 새로운 클라우드 비용 월 2~3만 원을 추가로 더 지불해야 했다. 현재 사용자가 많은 편도 아닌 상태에서 인프라를 추가로 두는 건 부담이 되었다. 또, RDB와 벡터 DB 사이의 데이터 동기화 비용도 있다.
- 기존에 사용하던 DB인 MySQL에서는 vector 컬럼을 지원하긴 하지만 성숙도가 낮음
기존에 사용하던 DB인 MySQL에서는 9.0 버전부터는 vector 컬럼을 지원한다. 하지만, MySQL 9.3 버전 기준 vector 열은 어떤 유형의 키로도 사용할 수 없다고 한다. 그러므로 인덱스를 사용하지 못한다고 볼 수 있다. 더불어 MySQL vector 관련 자료도 많지 않다.
- PostgreSQL에서는 RDB로서의 역할을 함과 동시에 vector 검색의 지원이 풍부함
PostgreSQL은 나의 상황에 딱 맞는 선택지였다. RDB로서의 역할을 하면서도 vector search를 지원해준다. 확장 플러그인 pg_vector를 통해 다양한 vector 타입, vector 연산자, ANN 인덱스 등을 지원한다.
레퍼런스도 꽤 있는 편이다. 실 서비스에서 사용하는 케이스도 꽤 있다. - 1인 개발 체제에서 관리의 일원화로 오는 장점 (아키텍처 단순화)
큰 장점이다. ElasticSearch 인프라를 추가로 도입했을 때는 처음에는 검색 구현 속도가 빠를 수 있다. 하지만 혼자서 지속적으로 운영하고 개발하는 데 있어 아키텍처를 단순화하는 게 도움이 될 것이다.
PostgreSQL에서 pg_search를 추가한 이유
ParadeDB에서 만든 pg_search는 FTS 성능을 높여주는 Postgres 확장 익스텐션이다. 내부적으로는 Rust로 만든 Tantivy 엔진을 쓰고 있다.
- FTS: Full-Text Search의 약자이다. 말 그대로 모든 text를 고려해서 검색한다는 뜻이다. title, author 등 메타데이터만 활용해서 검색하는 게 아니라 문서의 전체 본문을 통해서 검색한다. 이를 위해 본문을 term 단위로 쪼개고 이를 인덱싱한다.
- term: 검색의 기본이 되는 단위이다. 검색에서 쓰이는 가장 작은 정보의 단위라고 보면 된다. 예를 들어, "redis 부하로 인한 DB 장애" 이와 같은 텍스트가 있으면 term은 "redis", "부하", "DB", "장애"가 된다.
사실 pg_search가 없어도 PostgreSQL만으로도 FTS를 구현할 수 있다. tsvector, GIN를 활용하면 된다. 이 둘을 활용하면 본문을 term 단위로 쪼개고 인덱싱할 수 있다.
- tsvector: FTS를 위한 자료형이며, 검색에 최적화된 term 단위로 쪼개준다.
- GIN(Generalized Inverted iNdex): 역인덱스로 다양한 컬럼에 대해 지원한다.
- Inverted Index: 해당 데이터가 위치한 곳과 해당 데이터 일부를 함께 저장한다. 전공책 맨 뒷 장에 있는 사전을 생각하면 편하다. 각 단어마다 어느 페이지에 나오는지가 나와있다.
그런데도 굳이 pg_search라는 확장 익스텐션을 사용하는 이유는 다음과 같다.
- 가볍고 빠르다.
- PostgreSQL의 FTS보다 대체로 빠름
- Rust로 작성된 고성능 검색 라이브러리인 Tantivy를 기반으로 함
- BM25 인덱스를 지원한다.
- BM25 전용 인덱스가 있으며, LSM 트리를 기반으로 해서 빠른 속도를 지원
- Log Structured Merge Tree는 데이터를 디스크에 랜덤하게 쓰지 않고, 메모리에 모았다가 정렬된 상태로 한 번에 기록한 뒤 병합하는 구조
- 쓰기 성능에 최적화되어 있어 검색 인덱스에 적합함
- 'SQL + 보조테이블'만으로는 BM25를 구현하는 건 속도가 느리다고 함
- 오픈소스로 현재에도 활발히 업데이트되고 있다.
- ParadeDB에서 활발히 관리하고 있는 모습이다.
- ParadeDB에서 활발히 관리하고 있는 모습이다.
마이그레이션한 과정
마이그레이션한 주요 과정을 간략히 정리하자면 아래와 같다. MySQL 서버가 띄워져 있는 상태에서 PostgreSQL 서버를 별도로 띄워서 잘 되는지 확인 후 MySQL 서버를 삭제하는 방식으로 했다.
- mysqldump 통해 DDL, DML 담긴 SQL 추출
- SQL을 PostgreSQL에 맞게 전처리
- MySQL 특화 구문 제거 (/!.../ 주석, LOCK TABLES 등)
- 백틱 따옴표(`) → 쌍따옴표(") 변환
- PostgreSQL 트랜잭션 구문 추가 (BEGIN, COMMIT)
- 타임존 및 인코딩 설정
- Foreign key 체크 비활성화/재활성화
- INSERT 문을 PostgreSQL 호환 형식으로 변환
- PostgreSQL 서버 생성 후 SQL 실행
- 외래키 제약조건 설정 및 시퀀스 초기화
- 잘 돌아가는지 테스트한 뒤, MySQL에서 PostgreSQL로 이전
3. 전처리 - 글 본문에서 term 추출
Semantic Search를 지원하기 위해서는 글 본문을 바탕으로 한 정보도 필요했다. 그래서 글을 크롤링할 때 본문을 가져와서 analyzer를 통해 term 단위로 추출했다.
Analyzer의 필요성
본문을 가져왔으면 이를 term 단위로 분석해야 한다. 분석을 도와주는 게 바로 analyzer이다.
analyzer는 보통 크게 3가지 과정으로 term을 추출한다.
- Character-Filtering: 개별 문자에 대해 치환하거나 삭제 (전처리)
- HTML Strip:
<b>Hello</b>→Hello(HTML 태그 제거) - Mapping:
&→and(특수문자 치환)
- HTML Strip:
- Tokenizing: 전처리가 끝난 문장을 단어 단위(term)로 쪼갬
- 형태소 분석:
redis 부하로 인한 DB 장애=>redis,부하,로,인하,ㄴ,DB,장애
- 형태소 분석:
- Token-Filtering: 특정 term을 삭제하거나 변형
- Lowercase: 모든 문자를 소문자로 변환 (
Apple→apple) - Stop Filter: "a", "the", "is"와 같은 불용어를 제거
- Stemming/Lemmatization: 단어의 원형 (
running→run) - Synonym Filter: 유의어 처리 (redis 검색 시 레디스도 나오게 함)
- 한국어 기준: 지정한 품사 태그에 해당하는 토큰을 제거, 한자로 된 토큰을 한글 형태로 변환
- Lowercase: 모든 문자를 소문자로 변환 (
Analyzer 선택 - Nori
Analyzer로는 Nori를 선택했다. Nori는 ElasticSearch 6.6 버전부터 공식적으로 제공하는 한국어 형태소 분석기이다. Nori는 Apache Lucene 라이브러리에서 제공된다.
analyzer로는 은전한닢 프로젝트의 mecab이 유명하다. 하지만 현재 업데이트는 중단된 상태이다. 그래서 이를 기반으로 새롭게 개선해서 만든 게 Nori이다.
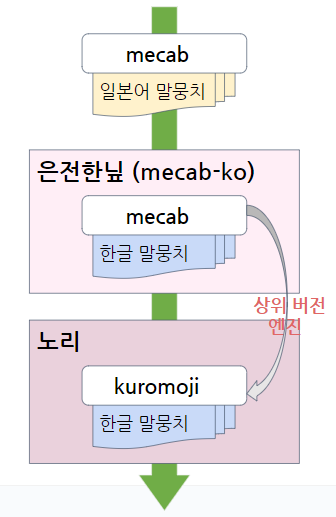
Nori는 mecab-ko-dic 사전을 사용한다. mecab-ko-dic이란 형태소 분석 엔진인 MeCab을 한국어에 맞게 최적화한 한국어 형태소 사전이다.
MeCab 기반인 Nori를 선택한 이유는 다음과 같다.
- 형태소 분석 품질이 좋고, 속도 또한 빠름
- 여러 실험에서 다른 분석기보다 MeCab의 품질이 좋고 속도도 빠름 (개인블로그 실험1, 개인블로그 실험2, ES 공식블로그 실험3)
- 이러한 장점으로 ElasticSearch에서도 MeCab을 기반으로 Nori 공식 지원
- Apache Lucene에서 지원하기에 자바 프로젝트에서 라이브러리 쉽게 추가 가능
- build.gradle 내
implementation 'org.apache.lucene:lucene-analysis-nori:9.12.3'
- build.gradle 내
- 라이브러리의 지속적인 관리, 업데이트
대안 선택지인 Komoran 분석기와 비교해보자.
Komoran
"redis 부하로 인한 DB 장애" => "redis", "부하", "로", "인하", "ㄴ", "DB", "장애"Nori
"redis 부하로 인한 DB 장애" => "redis", "부하", "인하", "db", "장애"Komoran은 위 결과처럼 자소 단위로 분리를 한다. 검색에서는 불필요한 분석이다. 또한, 정확히 측정은 못했지만 Komoran이 Nori보다 메모리를 더 많이 잡아먹었던 걸로 기억한다.
또한, Nori의 장점은 계속해서 관리가 되는 라이브러리라는 점이다.
애플리케이션 단에서 분석하는 이유
PostgreSQL 익스텐션 pg_search에서도 한국어 analyzer를 지원한다. pg_search의 korean_lindera는 Nori와 동일한 mecab-ko-dic 기반이라 분석 품질 자체는 유사하다. 그럼에도 DB가 아닌 애플리케이션 단에서 형태소 분석을 하는 이유는 분석 품질의 제어권 때문이다.
한국어 형태소 분석기는 "스프링부트"를 "스프링" + "부트"로 분리한다. 또, "race condition"을 "race", "condition"으로 분리한다. 하나의 의미를 가진 단어가 이런 식으로 분절되면 기술 키워드의 정확한 의미를 담을 수가 없는 문제가 있다.
이를 막으려면 사용자 정의 사전에 "스프링부트", "race condition"을 등록해 단일 token으로 처리해야 하는데, korean_lindera는 사용자 정의 사전을 SQL 인터페이스로 노출하지 않는다.
그래서 애플리케이션 단에서 분석하기로 결정했다. 그리고 애플리케이션의 analyzer에 기술 키워드 1700개를 사용자 정의 사전에 포함시켜 정확도를 높였다.
더불어 애플리케이션에서 분석했을 때 DB 서버에서 분석을 하지 않기에 DB 부하를 조금이라도 더 덜 수 있는 장점도 있다.
4. 전처리 - 유의어 미리 등록
사용자 검색 시 아래와 같이 미리 등록해둔 유의어를 통해 여러 term으로 확장해서 검색한다.

유의어를 미리 등록해둔 이유
임베딩 기반 검색은 문장/문단 수준의 의미 검색에는 강했지만, 짧은 기술 키워드(특히 영문↔한글 표기, 약어, 고유명사)에서는 기대만큼 안정적으로 매칭되지 않는 경우가 있었다.
앞에서 언급했던 것처럼 "race condition" 분석 시 "race"와 "condition"으로 나뉘는 문제가 있다. 또, "spring boot" 검색 시 "스프링부트"도 검색되게 해야 한다. 그래서 키워드 구간에서는 유의어/정규화 기반 확장을 별도로 두어 정확도를 보강했다.
사용자 검색어 로그를 직접 보면서 관련 유의어를 수동으로 등록하곤 했었다. 하지만, 수동으로 일일이 입력하는 건 한계가 있기에 다른 수를 떠올렸다.
StackOverFlow에서 기술 키워드 가져오기 -> 번역하기
여러 기술 키워드를 가져와서 번역기를 돌려 유의어를 등록하면 되겠다고 생각했다. 이러면 대표적인 기술 키워드에 대해서는 유의어를 처리할 수 있다.
기술 키워드를 어디서 가져와야 할까 고민하던 중 StackOverFlow를 발견했다.
StackOverFlow에서는 위와 같이 인기순으로 기술 tag를 제공한다. 또한, 이를 API로 제공해준다! 안 쓸 이유가 없다!
그리고 이를 DeepL 번역기로 번역한 term까지 유의어로 등록했다. DeepL 번역 API는 품질도 꽤 좋은 편이며 한 달에 500,000 character가 무료로 주어진다.
위와 같이 해서 유의어를 총 1800개 등록했다.
번역된 유의어 품질 검수
아래와 같이 stackoverflow의 tag가 deepl로 번역된 모습이다.

대부분 잘 된 모습을 볼 수 있다. 간혹 번역이 잘못 된 건 수동으로 수정했다. 예를 들면, spring이 '봄'으로 잘못 번역되는 케이스이다.
5. 임베딩 벡터 검색 도입
글을 통째로 임베딩 하면 안 되는 이유
제일 이상적인 임베딩을 생각해보자. 하나의 문서를 임베딩 했을 때 하나의 vector가 리턴된다. 이 하나의 vector만으로 어떤 문서인지 명확히 의미를 담을 수 있다면 얼마나 좋을까?
하지만 현실은 그렇지 않다. 문서 전체를 임베딩하면 검색 정확도가 떨어진다.
글에는 여러 아이디어와 주제가 포함되어 있기 마련이다. 이를 하나의 벡터로 압축하는 과정에서 특정 단락의 의미가 희석된다. 또한 사용자 검색어는 짧고, 문서는 길기에 이를 매칭하면 정합성이 다소 떨어질 수 있다.
그래서 우리는 임베딩할 문서를 여러 단위로 쪼개거나, 다른 형태로 임베딩해야 한다. 떠올린 방법들을 정리하자면 아래와 같다.
임베딩을 어떤 방식으로 해야할까?
- 제목을 임베딩
- 한계: 블로그 글들을 보면 제목이 핵심을 온전히 담지 않는 경우가 있음
- 예를 들면, 20년 레거시를 넘어 미래를 준비하는 시스템 만들기
- 레거시가 무슨 레거시인지, 어떤 시스템을 만드는지 제목만 보고는 알 수가 없음
- 글의 핵심을 담은 제 3의 제목을 만들어서 임베딩
- 위 문제점을 보완하는 해결 방법임
- 한계: 제목만으로 요약하다보면 분명 글의 핵심 내용을 놓칠 수 있게 됨
- 간결한 요약본을 만들어서 임베딩
- 위 문제점을 보완하는 해결 방법임
- 하지만, 문서 전체를 읽고 요약을 해야 하는데 AI 요약 API는 비용이 높은 편
- 그래서 저렴한 모델인
gpt-5-nano써봤는데 품질이 낮음 - 한계: 향후 RAG 구현을 고려했을 때 글의 세부내용까지 짚어내기는 어려움
- 하나의 문서를 여러 단위(chunk)로 나눠서 임베딩
- 하나의 문서를 빠짐 없이 임베딩하기에 문서의 내용을 놓치지 않고 검색 가능
- 임베딩 API는 저렴한 편이라 하나의 글에서 여러 번 호출해도 부담이 덜함
- 이걸로 결정!
chunk를 나누는 기준
chunk를 나누는 기준에는 여러 가지가 있다.
- Fixed-size Chunking
- 고정된 크기만큼 나누는 방식
- Content-aware Chunking
- 두 가지 방식이 있음
\n\n(단락) →\n(줄바꿈) →- 문장 단위(
.,?,!)로 나누는 방식
- Semantic Chunking
- 문장 간 유사도 비교하면서 흐름이 끊기는 부분이 있을 때 나누는 방식
- 참고로 ncloud clova의
문단 나누기 API가 이 방식을 사용함
- Contextual Chunking
- chunk는 전체 맥락이 없이 쪼개진 단위라는 문제 의식에서 출발한 방식
- 전체 문서와 chunk를 함께 프롬프트 함. Contextual RAG에서 사용하는 방식
- Voyage의
voyage-context-3모델이 이 방식을 사용함
결론부터 말하자면 Fixed-size Chunking + Content-aware Chunking으로 결정했다. 결정하게된 과정은 아래와 같다.
- Semantic Chunking에서 ncloud clova의
문단 나누기 API를 사용해서 검색 테스트를 간단하게 해봤다. 그런데 생각보다 검색 정확도가 높지 않았다. 오히려 Fixed-size 방식이 더 나았다. 아마도 문단 나누기 API에서는 overlap을 두지 않아서 정확도가 더 낮았을 거라 추정한다. - Contextual Chunking 또한
voyage-context-3를 사용해서 테스트를 해봤지만, 오히려 Fixed-size가 더 좋게 나왔다. Contextual RAG를 구현하기에는 좋은 모델이 될 수 있지만 현재 벡터 단위 검색으로써는 점수가 살짝 아쉬웠다. - Fixed-size Chunking은 문단, 문장의 의미가 훼손될 수 있다는 단점이 있다. 이걸 보완할 수 있는 게 Content-aware Chunking이다.
fixed한 size에 근접한 부분&&문장이 끝나는 부분에서 chunk를 나누는 것이다.
chunk 크기와 overlap 크기를 정해보자!
- overlap: 청크 경계에서 문맥 단절을 줄이는 용도다. 정해진 크기로 나누다 보면 원래의 문맥 의미가 끊길 수 있기 때문이다.
기본 설정은 512 token + 200 token overlap(약 40%)로 했다.
일반적으로는 10~25%가 많지만, 기술 블로그 글의 특성 상 긴 코드 블록과 문맥 단절 비용이 커서 overlap을 더 크게 잡았다.
- 기술 문서 특성상 긴 코드 블록이 나올 수 있음
- 최적의 overlap은 문서의 특성마다 다름
- 이는 향후 RAG 정확성에도 도움될 것
- overlap을 증가시켜 Recall을 조금이나마 높여 검색 품질 향상
- overlap을 높였을 때 recall이 대체로 오르는 경향이 있다는 걸 이용
- Recall = (찾아낸 관련 문서 수) / (전체 관련 문서 수)
overlap을 25%에서 40%로 늘렸을 때 저장 공간은 20% 정도 더 늘어난다. 하지만, 검색 품질을 우선하기 위해 이 trade-off를 선택했다.
해당 값을 선택하게 된 건 한 논문을 보고나서였다. COINS 2025에서 발표된 논문이다. 여기서는 SentenceSplitter를 기반으로 chunk를 512 token으로 나누고, overlap을 200으로 뒀을 때가 가장 점수가 높았다.
또한, microsoft 연구에서도 overlap을 높였을 때 recall이 오르는 결과가 있었다.
| Chunk boundary strategy | Recall@50 |
|---|---|
| 512 tokens, break at token boundary | 40.9 |
| 512 tokens, preserve sentence boundaries | 42.4 |
| 512 tokens with 10% overlapping chunks | 43.1 |
| 512 tokens with 25% overlapping chunks | 43.9 |
다만 내가 설정한 값은 아직 휴리스틱이며, 이후에는 실제 검색 로그와 정량 평가로 다시 검증할 계획이다.
embedding model 선정
모델을 직접 돌리는 건 서버 비용과 관리 부담이 생겨서 Embedding API를 사용하는 걸로 결정했다. 직접 돌리는 것보다 API를 쓰는 게 더 저렴하고 관리하기 용이하다.
| 제공사 | 모델 | 가격(USD) | 비고 |
|---|---|---|---|
| OpenAI | text-embedding-3-large | $0.13 | 배치(Batch) API 이용 시 $0.065 |
| Clova | 임베딩v2 | 약 $0.14 | 1,000토큰당 0.2원 (환율 1,430원 기준 환산) |
| Gemini | Gemini (유료 등급) | $0.15 | 무료 등급 사용 가능 (단, 데이터가 제품 개선에 사용됨) |
| Voyage AI | voyage-context-3 | $0.18 | 2억 토큰 무료 제공 |
Embedding API는 위 4가지 후보군이 있었다. 참고로 Clova는 내부적으로 BGE-M3 모델을 사용한다.
제일 이상적인 건 기술 블로그 데이터에 어떤 Embedding API가 제일 좋은지 실험해보는 것이다. 정확히 테스트하는 건 시간이 오래 걸리는 것 대비 우선순위가 낮다고 판단해 생략했다.
그래서 claude code를 통해 간단히나마 테스트해봤다. 5개 쿼리에서 각각의 적합한 글을 미리 설정해두고, 누가 더 recall이 높은지 테스트했다. 그 결과로는 Clova가 제일 나았다.
그래서 Clova를 선택했다. 토큰 비용은 모두 다 비슷하기에 비용은 크게 고려하지 않았다. 참고로 오늘의집 검색에서도 BGE-M3를 쓴다고 한다.
clova의 또 하나의 장점은 BGE-M3를 쓰고 있기에, 나중에 API가 아니라 로컬로 모델을 돌리고 싶을 때 쉽게 변환이 가능하다는 점이다. 장기적인 운영에 있어 이점이 있다.
2단계 벡터 검색 쿼리 구현
위에서 빨간 부분을 구현했다. 구현하면서 신경을 썼던 부분이 있었다.
- 벡터 점수 0.52 미만인 경우는 임베딩 검색 결과에서 필터링
- 벡터 검색을 여러 번 해보며 체감 상 관련이 없는 글들은 점수가 몇인지 살펴봤다. 그 결과 0.52 미만은 사용자 쿼리와 크게 관련이 없는 경우가 거의 대부분이어서 이 점수 미만은 필터링했다.
- 벡터 검색 속도 개선
- 12만 개 벡터 검색을 위해 속도를 개선했다. 뒤에서 더 자세히 다룰 예정이다!
6. 추가로 BM25를 도입
처음에는 Embedding만으로 잘 될 줄 알았는데
처음에는 Embedding만으로 Semantic Search가 될 줄 알았다. 그래서 Embedding을 NewCodes에 일부 도입해서 검색을 해봤다. 하지만 아쉬운 부분이 있었다.
검색한 키워드가 직접적으로 포함된 글을 우선적으로 찾지 못하는 경우가 꽤 있었다.
그래서 이를 보완하기 위해 BM25를 도입했다.
BM25가 뭐길래 도입했는가?
BM25는 키워드 단위 검색의 품질을 높여주는 랭킹 함수이다.
세상에 나온지 30년도 넘은 함수이다. 30년도 넘었지만 현대 웹 검색엔진에서는 아직까지도 보편적으로 쓰이고 있다. ElasticSearch도 BM25를 default로 채택해서 사용하고 있다.
무엇이 BM25를 오랜 세월 동안 자리를 지키게 했을까?
BM25 함수를 보면 그 이유가 자연스레 납득이 된다.
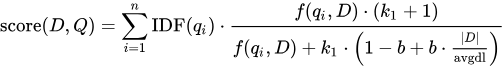
수식을 먼저 차분하게 관찰해보자. 어떤 의미일지 추론해보며 읽어보자.
- Score(D, Q): 쿼리에 따라 검색된 특정 문서의 점수
- D: 검색된 문서
- Q: 사용자의 쿼리 (키워드 q1 ~ qn을 포함하는 쿼리)
- IDF: Inverse Document Frequency, 흔하게 등장하는 단어에 대한 가중치를 낮추는 역할
- qi: 사용자 쿼리 중 키워드
- f(qi, D): 문서에서 해당 키워드 등장 횟수 = TF(Term Frequency)
- |D|: 문서 D의 길이
- avgdl: 여러 문서들의 평균 길이
- 파라미터
- k1: TF로 인한 점수 상승 폭을 제어 (보통 1.2에서 2.0, 높을수록 TF의 중요도 높아짐)
- b: 문서의 길이로 인한 점수 폭을 제어 (보통 0.75, 높을수록 문서 길이의 중요도 높아짐)
BM25의 주요 요소
1. TF: 키워드 등장 빈도
2. IDF: 역 문서 빈도
3. 문서 길이
BM25는 위와 같이 합리적인 변인을 토대로 각 글에 대한 순위를 매긴다. 키워드가 얼마나 등장하며, 이 키워드가 총 문서 내에서 얼마나 희소성 있는 키워드인지를 판별한다.
또한, 문서 길이가 짧을 때 점수를 더욱 높여준다. 문서 길이가 길면 여러 키워드가 존재하므로 해당 키워드가 핵심 주제가 아닐 수 있기 때문이다.
BM25 인덱스 걸기
-- 1. BM25 index를 위한 materialized view 생성
CREATE MATERIALIZED VIEW article_search_view AS
SELECT
a.id,
a.title,
a.published_at,
a.corporation_id,
a.category_id,
terms.title_terms,
terms.content_terms
FROM article a
LEFT JOIN (
SELECT
at.article_id,
STRING_AGG(CASE WHEN at.source IN ('TITLE', 'BOTH') THEN t.term END, ' ' ORDER BY at.score DESC) AS title_terms,
STRING_AGG(CASE WHEN at.source IN ('CONTENT', 'BOTH') THEN t.term END, ' ' ORDER BY at.score DESC) AS content_terms
FROM article_term at
JOIN term t ON at.term_id = t.id
GROUP BY at.article_id
) terms ON a.id = terms.article_id
WHERE a.deleted_at IS NULL;
-- 2. BM25 index 생성
CREATE INDEX CONCURRENTLY article_search_view_bm25_idx ON article_search_view
USING bm25 (id, title_terms, content_terms)
WITH (
key_field='id',
text_fields='{
"title_terms": {"analyzer": "whitespace"},
"content_terms": {"analyzer": "whitespace"}
}'
);BM25 인덱스를 걸기 위해 글 본문을 담은 별도의 뷰/테이블이 필요했었다.
- pg_search를 이용해서 BM25 index를 만들 때에는 명시한 text_fields에 있는 필드가 자동으로 analyze됨
- 쉽게 말하면 pg_search에서는 인덱스를 만들 때 '글 본문'을 기대하고 있음
- 글 본문만 인덱스 걸면 알아서 analyze하고 나온 term에 대해 자동으로 bm25를 위한 인덱스를 만들어냄
- 그런데 DB가 아닌 애플리케이션에서 analyzer를 사용하기로 결정했었음
- 애플리케이션에서 분석한 term을 토대로 BM25 index를 걸 수 있는 방법을 모색함
- pg_search에서 지원하는 analyzer를 찾아보니 공백을 기준으로 split해서 term을 분석하는 게 있었음
- 이걸 활용하면 되겠다고 판단함
- 그래서 BM25 index를 만들 때 활용하기 위한 목적의 테이블을 만들어야겠다고 판단함
- 참고사항
- analyzer로 분석된 term은 term, article_term 테이블에서 저장함
- 해당 테이블 본래의 목적은 검색어 자동완성을 위해 만들어진 테이블임
- 그러므로 BM25 index를 위해서는 term, article_term을 읽어서 테이블/뷰를 만들면
처음에는 Materialized View로 구현했다. REFRESH 하나로 간단하게 정합성이 자동으로 보장되기 때문이다. term과 관련해서 수정할 일이 있을 때 정합성 보장하기가 쉬워진다. 갱신에 30초가 걸렸지만 기술 블로그 모음 서비스 특성상 높은 실시간성이 필요하지 않아 허용 가능한 수준이라고 판단했다.
읽기 잠금 문제는 REFRESH MATERIALIZED VIEW CONCURRENTLY로 해결했다. CONCURRENTLY는 REFRESH 중에도 기존 데이터를 계속 읽을 수 있도록 락 없이 갱신한다. 내부적으로 새 데이터를 전체 계산한 뒤 기존 데이터와 diff를 비교해 변경분만 적용하는 방식이다.
그런데 락 문제는 해결됐지만 더 근본적인 문제가 남아있었다. CONCURRENTLY는 락을 없애줄 뿐, 전체 데이터를 재계산하고 diff를 비교하는 과정은 그대로라 Disk IO 부하 자체는 줄어들지 않는다. Grafana 모니터링에서 REFRESH 시 Disk IO가 74%까지 치솟으면서 다른 쿼리가 지연되는 문제가 발생했다. 메모리도 순간적으로 44MB 증가했다.
전체 데이터를 메모리에 올리는 것이기에 메모리 및 IO에 부담이 되고, 전체 데이터가 증가할수록 비용이 선형으로 늘어나는 문제가 있다.
-- 1. BM25 index를 위한 테이블 생성
CREATE TABLE article_analyzed_content (
id BIGINT PRIMARY KEY REFERENCES article(id) ON DELETE CASCADE,
title TEXT,
published_at TIMESTAMP,
corporation_id BIGINT,
category_id BIGINT,
title_terms TEXT,
content_terms TEXT,
updated_at TIMESTAMP NOT NULL DEFAULT NOW()
);
-- 2. BM25 index 생성
CREATE INDEX article_analyzed_content_bm25_idx ON article_analyzed_content
USING bm25 (id, title_terms, content_terms)
WITH (
key_field='id',
text_fields='{"title_terms": {}, "content_terms": {}}'
);결국 트레이드오프를 감수하고 일반 테이블을 별도로 두는 방식으로 전환했다. 정합성은 term/article_term을 조작하는 코드에 대해서는 article_search_content 반영과 함께 하나의 트랜잭션으로 묶어 보장한다. term/article_term CRUD마다 동기화 로직이 필요하다는 운영 부담이 생겼지만, 이는 PostgreSQL 단일 스택으로 Elasticsearch 없이 BM25를 구현하기로 한 결정 때문에 생긴 부담이기도 하다.
위 과정을 표로 정리해보자.
| 항목 | Materialized View | 일반 테이블 |
|---|---|---|
| 데이터 일관성 | 뷰 정의가 정합성 자동 보장 | 불용어·사용자 정의 term·글 추가 및 삭제 등 변경 시 정합성 수동 유지 |
| 데이터 삽입 속도 | term, article_term 전체 테이블에 대해 SELECT를 다시 해야하기에 속도가 느림 (현재 데이터에서 30초 걸림) → 실시간 반영에 불리하며, 데이터 증가 시 REFRESH 비용 선형적으로 증가 | 새로운 게시글 수만큼 INSERT 하면 되기에 view에 비해서는 속도가 빠른 편임 |
| 서버 부하 | 모니터링 결과 REFRESH 시 DB 서버 메모리 44MB 증가, CPU iowait 36%, Disk IO 74%로 인해 다른 쿼리 지연 유발 | 새로운 게시글 수만큼 INSERT 하면 되기에 부하가 view에 비해서는 매우 적은 편 |
| 운영 편의성 | REFRESH 명령어만 실행하면 돼서 운영 복잡도 낮음 | term, article 관련된 CRUD 작업에서 추가 로직 필요 |
pg_search를 통해 BM25 index를 걸면 일어나는 일
BM25 index는 내부적으로 역색인(inverted index)을 사용한다. 역색인이 무엇인지부터 살펴보자.
역색인을 통해 각 term이 어느 article에 속해있는지를 빠르게 파악할 수 있다. 문서 전체를 탐색할 필요가 없어 I/O를 획기적으로 줄여준다.
자 그러면 BM25 index를 걸면 내부에서 일어나는 과정을 살펴보자.
- 스키마 정의
- 해당 컬럼들을 Tantivy의 필드로 등록
- key field 설정: PostgreSQL의 행과 Tantivy의 문서를 연결하는 고유 식별자 설정
- tokenizer로 term 추출
- 대문자에서 소문자로 통일
- 불용어 제거
- 단어의 어근 추출
- BM25 수식을 위한 데이터 계산
- TF, IDF, 문서의 길이
- term을 역색인 형태로 저장
- 인덱스 데이터를 PostgreSQL의 표준 테이블 파일이 아닌, 별도의 세그먼트 파일 단위로 디스크에 저장
BM25 검색 쿼리
/**
* BM25 알고리즘을 사용한 전문 검색 (ArticleTerm 기반)
* Materialized View인 article_search_view를 사용하여
* 형태소 분석된 정제 키워드로 검색합니다.
*
* @param searchQuery pg_search 검색 쿼리
* @param limit 최대 결과 수
* @return BM25 스코어 순으로 정렬된 Article ID 리스트
*/
@Query(value = "SELECT id, " +
"paradedb.score(id) as bm25_score, " +
"published_at " +
"FROM article_search_view " +
"WHERE article_search_view @@@ paradedb.parse(:searchQuery) " +
"ORDER BY bm25_score DESC " +
"LIMIT :limit",
nativeQuery = true)
List<Object[]> searchByBM25(
@Param("searchQuery") String searchQuery,
@Param("limit") int limit
);검색 시에는 다음과 같은 과정이 일어난다.
- Tantivy 엔진이 BM25 점수 제일 높은 id 목록 뽑음
- key_field='id'를 통해 테이블에서 실제 데이터 찾아서 반환
SQL 주요 설명
paradedb.parse(:searchQuery)
- 문자열을 ParadeDB 쿼리 객체로 변환@@@
- ParadeDB inverted index에서 매칭 수행
- BM25 점수 계산paradedb.score(id)
- 해당 문서의 BM25 점수 반환
7. 임베딩 벡터 + BM25 -> Rerank
앞서 임베딩 벡터와 BM25 검색 두 가지를 구현했다.
이 두 가지 각각에 대한 결과를 사용자에게 보여주기 위해서는 하나의 결과로 내야 한다.
즉, 리랭킹을 해야 한다.
RRF(Reciprocal Rank Fusion)
처음에 Rerank 함수로 RRF(Reciprocal Rank Fusion)를 사용했다. Reciprocal은 역수를 의미한다. 순위를 역수로 바꾸어 점수를 재계산한다.
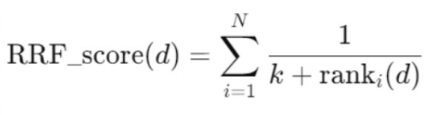
위는 RRF 공식이다. k는 상수인데 보통 60을 둔다.
BM25로 검색한 결과에 대한 순위와 Vector로 검색한 결과에 대한 순위를 계산해서 더하면 RRF 점수가 된다.
순위는 작을수록 더 좋은 결과를 의미한다. 그렇기에 역수를 취해 점수를 계산한다. 또한, 역수를 함으로써 상위권 점수를 우대한다.
RSF(Relative Score Fusion)
RRF의 단점은 Score의 높고 낮음을 있는 그대로 반영하지는 못한다는 점이다.
반면, RSF는 Score의 상대적인 차이를 고려한다.
RRF는 Rank에 대해서 집계를 한다.
반면, RSF는 Score에 대해 집계를 한다.
이러한 장점으로 RSF가 RRF보다 recall이 약 6% 향상되었다는 weaviate 실험도 있다.
RSF의 계산 절차는 어떨까?
- 정규화: 가장 큰 점수는 1, 가장 낮은 점수는 0으로 설정
- 모든 항목은 최대값과 최소값까지의 상대적 거리에 따라 스케일링됨
- ex) [5, 2.6, 2.3, 0.2, 0.09] -> [1.0, 0.511, 0.450, 0.222, 0.0]
- 각각의 지표에 대해 정규화한 점수를 글 별로 더하기
아래 예시를 보면 RRF와 RSF의 차이가 명확히 보일 것이다.
이 파트의 핵심은 RRF는 순위만 반영하고, RSF는 점수 간격까지 반영한다는 점이다.
그래서 BM25 점수가 유독 강한 문서를 RSF가 더 잘 살릴 수 있었다.
BM25, Vector 검색 결과
글 id와 각각에 대한 score가 나와있다.
| Search Type | (id): score | (id): score | (id): score | (id): score | (id): score |
|---|---|---|---|---|---|
| BM25 | (1): 5 | (0): 2.6 | (2): 2.3 | (4): 0.2 | (3): 0.09 |
| Vector | (2): 0.6 | (4): 0.598 | (0): 0.596 | (1): 0.594 | (3): 0.009 |
RRF로 변환한 점수
| Type | (id): score | (id): score | (id): score | (id): score | (id): score |
|---|---|---|---|---|---|
| BM25 | (1): 0.016393 | (0): 0.016129 | (2): 0.015873 | (4): 0.015625 | (3): 0.015385 |
| Vector | (2): 0.016393 | (4): 0.016129 | (0): 0.015873 | (1): 0.015625 | (3): 0.015385 |
| RRF(BM25 + Vector) | (2): 0.032266 | (1): 0.032018 | (0): 0.032002 | (4): 0.031754 | (3): 0.030769 |
RSF로 변환한 점수
| Type | (id): score | (id): score | (id): score | (id): score | (id): score |
|---|---|---|---|---|---|
| BM25 | (1): 1.000000 | (0): 0.511202 | (2): 0.450102 | (4): 0.022403 | (3): 0.000000 |
| Vector | (2): 1.000000 | (4): 0.996616 | (0): 0.993232 | (1): 0.989848 | (3): 0.000000 |
| RSF (BM25 + Vector) | (1): 1.989848 | (0): 1.504433 | (2): 1.450102 | (4): 1.019019 | (3): 0.000000 |
RRF <-> RSF
| Algorithm Type | (id): score | (id): score | (id): score | (id): score | (id): score |
|---|---|---|---|---|---|
| RRF | (2): 0.032266 | (1): 0.032018 | (0): 0.032002 | (4): 0.031754 | (3): 0.030769 |
| RSF (sum) | (1): 1.989848 | (0): 1.504433 | (2): 1.450102 | (4): 1.019019 | (3): 0.000000 |
특징을 살펴보면 RSF에서는 1번 글이 더 고평가되었다. 그 이유는 다른 글들에 비해 Vector 점수는 비슷하지만 BM25 점수가 월등히 높기 때문이다.
8. 검색 품질 개선
사용자 입장에서 여러 쿼리를 직접 검색해보면서 문제를 찾고 개선해나갔다.
1) 쿼리 복잡도에 따라 가중치 변경
문제1: MySQL 검색 시 PostgreSQL 나오는 문제
MySQL 글이 차고 넘치는 데도 PostgreSQL 글이 노출되는 이유는 뭘까?
그건 '한눈에 살펴보는 PostgreSQL'에서 비교군으로 MySQL을 자주 언급하기 때문이다.
사용자가 단순한 키워드를 입력했다면 그것과 직접적으로 연관된 글을 보고 싶을 것이다.
직접적으로 연관된 글을 찾기 위해서는 본문보다는 제목을 우선시해야 한다.
해결1: 단순 키워드일 시 제목 매칭을 우선시
그래서 'MySQL', "Redis"와 같이 단순 키워드 입력일 때는 제목에 대한 가중치를 높여서 해결했다.
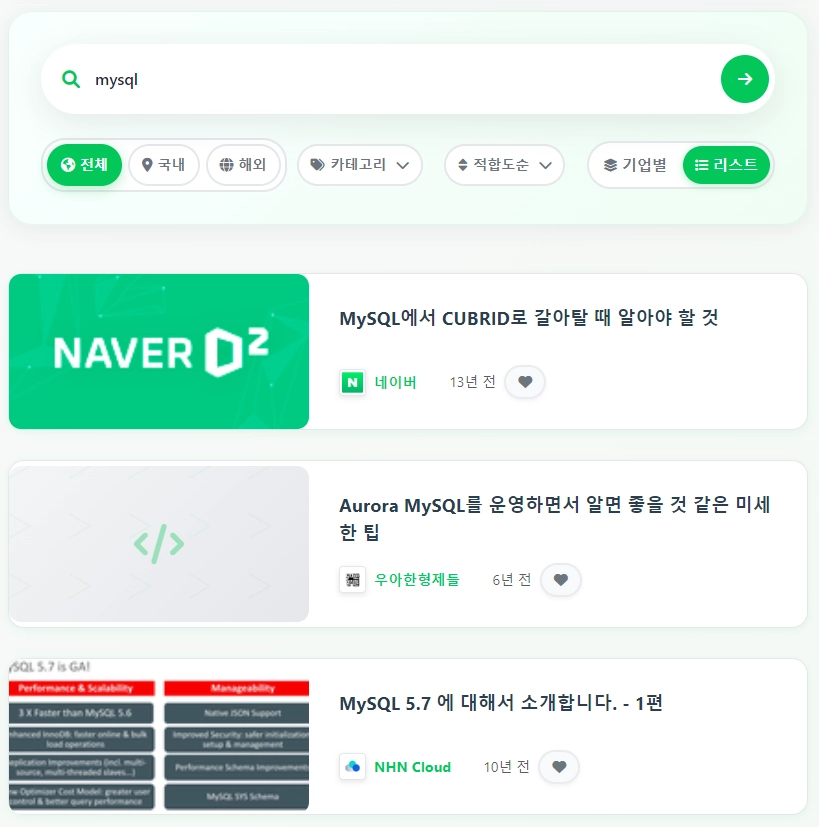
문제2: 쿼리가 복잡할 때 노이즈 생기는 문제
반대로 복잡한 쿼리에 대해서는 제목을 과하게 고려했다가 노이즈가 생긴다.
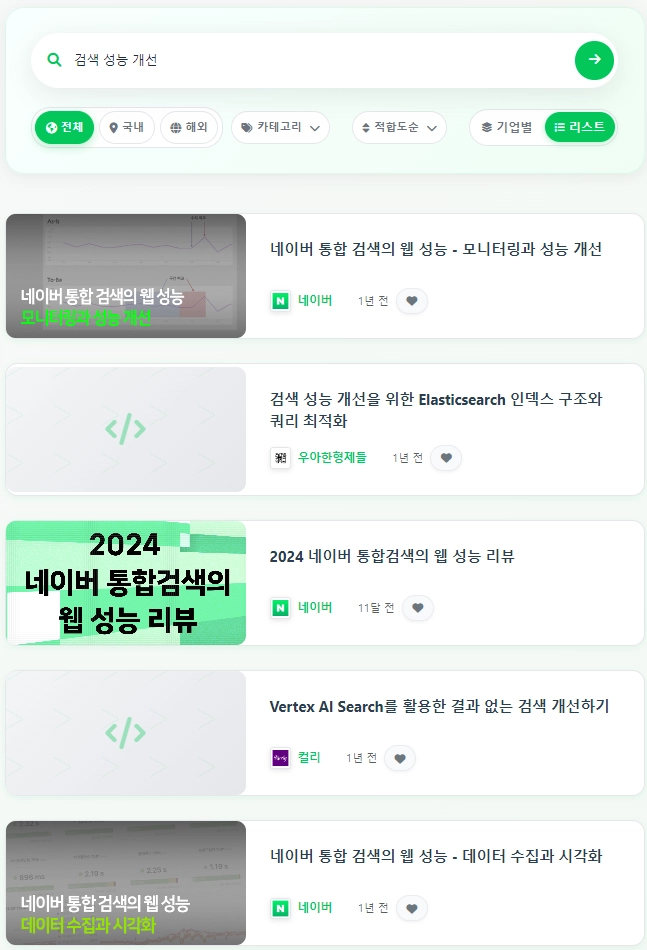
'FE 성능개선기'는 사용자 검색어의 의미와는 다소 거리가 있는 글이다.
'검색 성능 개선'에서는 '검색'이 핵심 키워드이다. 그런데 '성능'과 '개선'에 의해 노이즈가 생겨버린 것이다.
해결2: 복합 키워드일 시 벡터 결과를 우선시
이를 해결하기 위해 복합 키워드일 때는 RSF에서 벡터 결과의 가중치를 높였다.
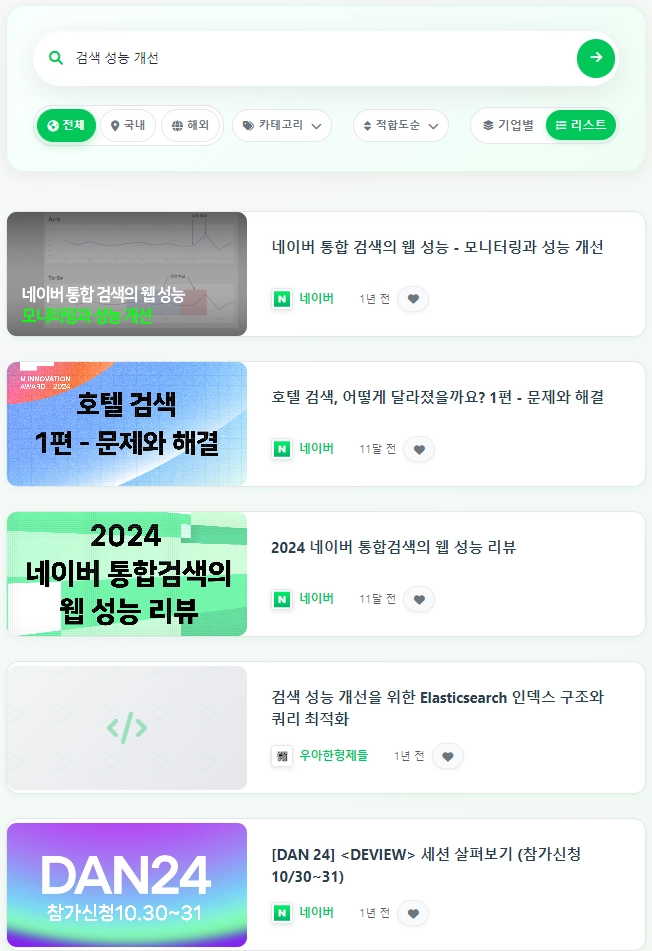
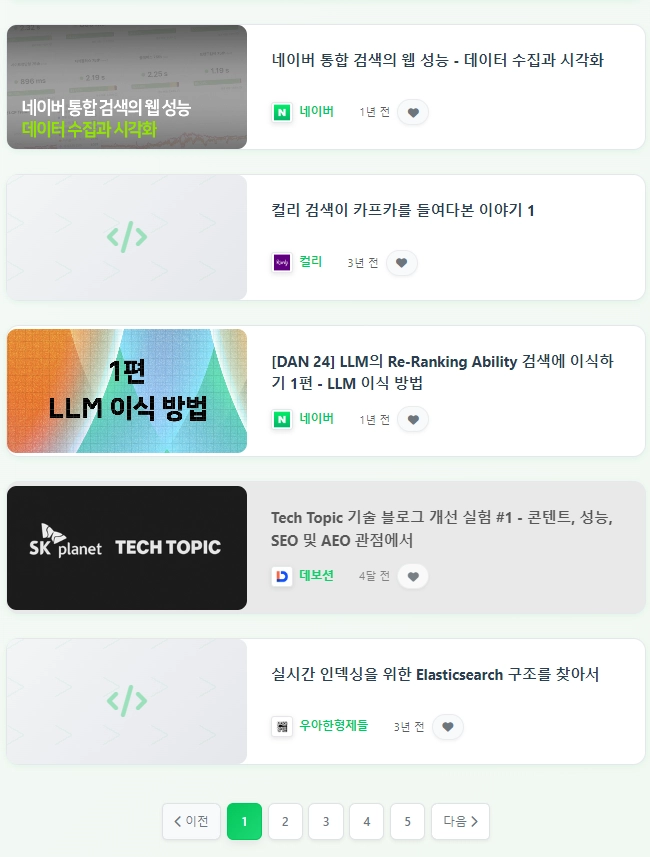
보시다시피 '검색'과 관련된 주제가 더 많이 나왔다.
2) "" 정밀 검색 추가
키워드를 정확히 일치하게 하는 검색 방식을 추가했다. 키워드를 ""으로 감싸서 검색하면 글 제목에 해당 키워드가 무조건 포함된 글만 검색한다.
이를 추가한 이유는 아래와 같은 경우 때문이다.
'마이크로프론트엔드' -> Nori analyzer로 분석 -> '마이', '크로', '프론트엔드'
마이크로프론트엔드가 하나의 의미인데도 불구하고 여러 단위로 쪼개어진다. 물론 이는 사용자 정의 사전에 '마이크로프론트엔드'를 추가하면 해결될 일이다.
하지만, 이러한 키워드들을 하나하나 다 추가하긴 한계가 있다. 그래서 추가한 것이다.
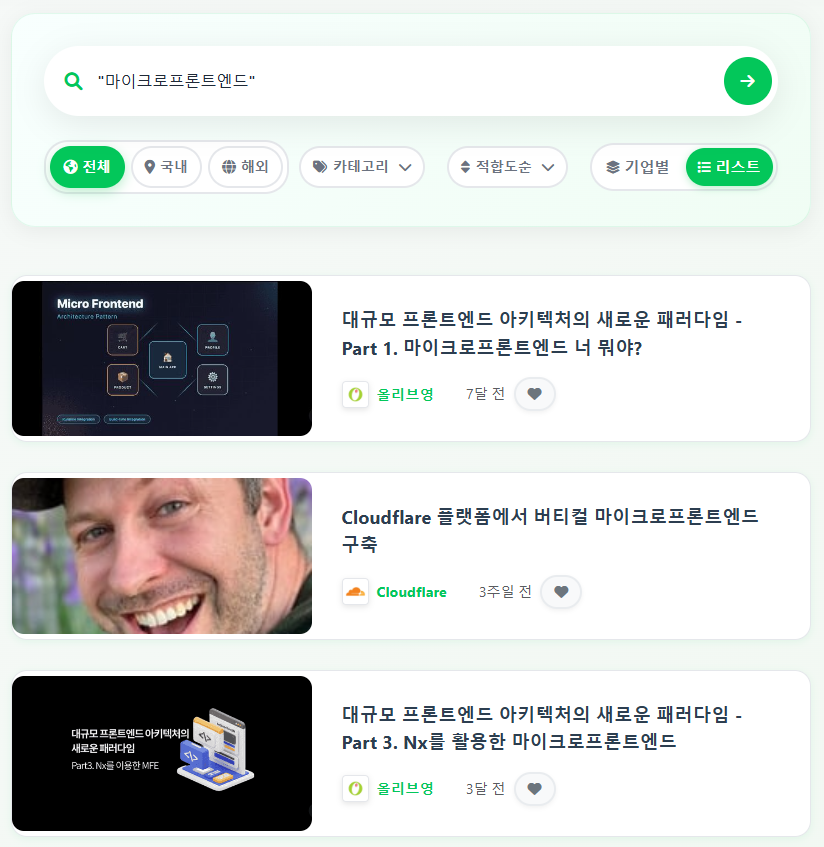
위와 같이 잘 검색되는 모습이다.
처음에는 "" 검색을 지원하지 않고 검색 결과에 LIKE 검색도 함께 포함시키는 방식으로 하려 했었다.
하지만, 이는 노이즈가 생길 수 있다. rerank 시에 이미 제목에 대한 term 일치를 가중치로 두고 있다. 여기서 LIKE까지 하면 제목에 해당 키워드가 있는 글만 너무 우선시 될 수 있는 문제가 있다.
그래서 "" 검색을 따로 분리하는 게 더 낫다고 판단했다.
9. 벡터 검색 속도 최적화
왜 이리 느려!
'카프카' 검색하는 데에만 무려 6초가 걸렸다.

대부분의 검색에서 대략 6~8초가 걸리는 모습을 보였다.
벡터 검색 실행계획을 보면 6초가 걸렸다.
당연히 이는 최적화를 해야 할 부분이었다.
이 당시 embedding한 chunk 개수는 약 8만 개였다. 사용자의 검색어를 임베딩한 vector로 8만 개를 비교해야 하니 오래 걸릴 수밖에 없었다. (글을 쓰는 지금 기준으로는 12만 개로 늘어났다.)
최적화 방안 검토
벡터 검색 속도를 높이기 위해서는 크게 두 가지 방법이 있다.
첫 번째, 비교할 chunk 수를 줄이는 것이다.
지금은 한 글의 모든 chunk에 대해서 비교를 한다. 이게 아니라, 특정 chunk만 선별한 뒤 비교를 하게 하면 된다. 그러면 I/O 횟수를 훨씬 줄일 수 있다.
단점은 검색 품질이 낮아질 수 있다는 점이다. 하지만, 검색 품질을 희생하고 싶진 않다. 또 매일 새로운 글이 나오고 있는 상황에서 해당 방법은 근본적인 해결책이 아니었다.
두 번째, KNN 비교 방식에서 ANN으로 바꾸는 것이다.
- KNN(K-Nearest Neighbors): 모든 데이터를 비교해서 가장 정확한 K개 이웃 찾는 방법
- ANN(Approximate Nearest Neighbor): 구조화된 인덱스를 사용해 빠르게 비슷한 이웃을 찾는 방법
PostgreSQL pg_vector에서 지원하는 ANN에는 두 가지가 있다.
- HNSW(Hierarchical Navigable Small World)
- 벡터 검색에서 표준처럼 쓰이는 대표적인 알고리즘
- 그래프 기반이며 여러 계층으로 쌓여 있음
- 매 계층마다 찾고자 하는 벡터 쪽으로 greedy하게 탐색함
- recall이 높은 대신, 메모리를 많이 차지함
- 그래프 탐색 알고리즘이기에 랜덤 I/O가 많아 메모리에 올라와야 제 성능 발휘
- IVFFlat(Inverted File Index)
- 벡터를 여러 개의 클러스터로 미리 나누어두는 알고리즘
- recall이 HNSW보다 낮은 대신, 메모리를 덜 차지함
- HNSW보다 상대적으로 인덱스 빌드 시간이 짧음
HNSW가 빠르면서도 recall이 높기에 매우 매력적인 ANN이다. 다만 메모리를 많이 차지하는 게 단점이다.
NewCodes의 DB 서버는 1CPU, 1GB인 RAM 환경이다. 따라서, 메모리를 최대한 효율적으로 사용해야 하는 상황이다. 얼핏 보면 IVFFlat을 사용해야 하는 상황처럼 보인다.
하지만, HNSW를 선택했다. 장점이 뚜렷한 인덱스이기에 우선 도입해보고, 최대한 최적화를 한 다음 그래도 안 되면 차선책으로 IVFFlat을 선택하고자 했다.
2단계 검색 구조 설계
시행착오 끝에 나온 설계본은 아래와 같다.
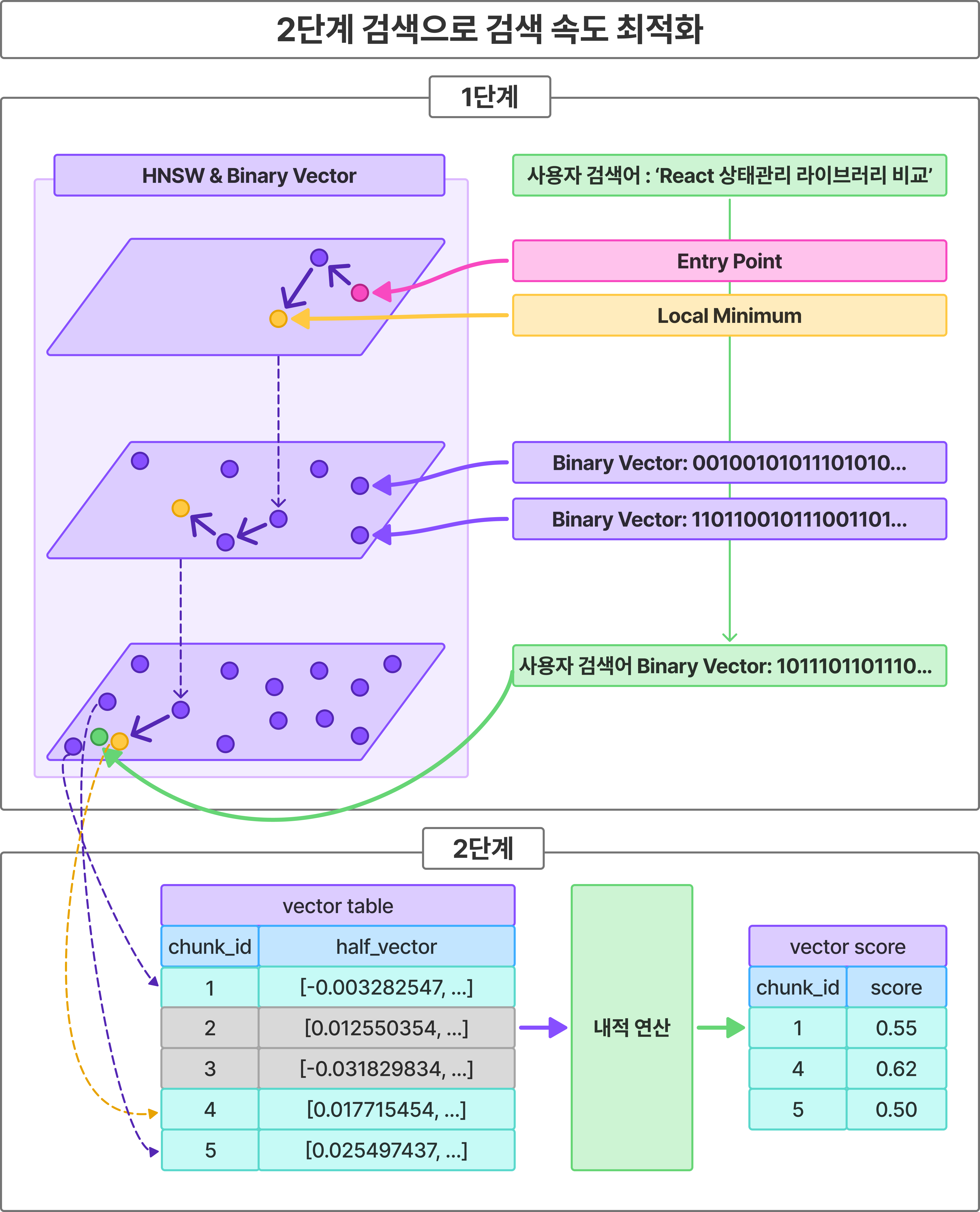
사용자가 검색 시 아래 2단계를 거쳐 검색 결과가 나오게 된다.
- 1단계: HNSW 인덱스를 통해 후보 글 추출 (ANN)
- 2단계: 후보 글에 대해 half_vector로 유사도 비교하여 검색 정확도 향상 (KNN)
위 설계 그림이 나오게 된 이유를 하나씩 살펴보자.
HNSW 인덱스 도입, 메모리 공간 확보
-- HNSW 인덱스 생성
CREATE INDEX idx_clova_chunk_embedding_binary_hnsw
ON public.clova_article_chunk
USING hnsw (embedding_binary bit_hamming_ops)
WITH (m='16', ef_construction='1000')위와 같이 HNSW 인덱스를 만들었다. 하지만, 문제가 생겼다. HNSW 인덱스가 메모리에 올라올 정도의 크기가 되지 않아 디스크 I/O가 되어 예상만큼 속도가 올라오지 않았다.
그래서 시도한 것들은 아래와 같다.
- Binary 양자화 적용
- 벡터 자체의 크기를 줄이기 위해 벡터를 Binary로 양자화하여 크기 최소화
- Binary 양자화는 0보다 크냐 작냐에 따라서 벡터 각각을 0과 1로 나타내는 방식
- 생각보다 단순한 방법이지만, 크기 절감 효과는 엄청남
- shared_buffers에 HNSW 올라갈 수 있게 지원
- HNSW 인덱스는 PostgreSQL 내 shared_buffers라는 메모리 위에 올라가게 됨
- shared_buffers의 크기를 128MB에서 256MB으로 늘히고, HNSW 인덱스를 prewarm하여 메모리 로드
- HNSW 인덱스가 걸어진 벡터 테이블에서 고용량 컬럼인 content, half_vector를 별도의 테이블로 분리하여 shared_buffers 공간 확보
- PostgreSQL은 페이지 블록 단위로 조회하기에 고용량 컬럼은 분리하는 게 shared_buffers 공간 확보에 유리 - 2단계에서 정밀 검색할 때 기존 FP32 벡터를 FP16으로 양자화하여 recall은 유지하면서도 shared_buffers 공간 확보
위 두 가지 과정은 쉽게 이해할 수 있게 매우 압축해서 적어두었다. 위 문단에 내 주말 하루가 녹아져있다 ㅎㅎ
추가 최적화
- Disk I/O 줄이도록 임베딩 쿼리 개선
- 애플리케이션 로직 단위에서 비효율 개선
- 기존에는 코사인 유사도로 비교하다가, 벡터 저장할 때 미리 L2 정규화하고 비교할 땐 내적하여 검색 시 연산 최소화
- 검색어 벡터 캐시하여 임베딩 API 호출 시간 절감. 검색어 캐시를 비동기적으로 저장해서 응답시간에는 영향 최소화
벡터 검색 쿼리
HNSW 인덱스를 탈 수 있게 쿼리를 작성해보자.
/**
* 2단계 통합 검색: Binary HNSW 후보 필터링 → halfvec Reranking
*
* CTE로 쿼리 벡터 정규화를 한 번만 수행하고,
* candidates CTE에서 embedding_normalized를 미리 읽어 PK 재조회를 방지합니다.
*
* @param queryEmbedding 검색 쿼리의 임베딩 벡터 (PostgreSQL 배열 포맷)
* @param queryBinary 검색 쿼리의 binary vector (bit string)
* @param candidateLimit Stage 1 후보 수 (예: 500)
* @param topK 평균 계산에 사용할 상위 청크 수
* @param threshold 최소 유사도 임계값
* @param limit 최종 결과 수
* @return Article ID와 평균 유사도
*/
@Query(value = """
WITH query_vec AS (
SELECT l2_normalize(CAST(:queryEmbedding AS halfvec)) AS vec
),
candidates AS (
SELECT
cac.article_id,
ccv.embedding_normalized
FROM clova_article_chunk cac
JOIN article a ON cac.article_id = a.id
JOIN clova_chunk_vectors ccv ON ccv.id = cac.id
WHERE a.deleted_at IS NULL
AND cac.embedding_binary IS NOT NULL
ORDER BY cac.embedding_binary <~> CAST(:queryBinary AS bit(1024))
LIMIT :candidateLimit
)
SELECT article_id, AVG(similarity) AS avg_similarity
FROM (
SELECT
c.article_id,
-(c.embedding_normalized <#> q.vec) AS similarity,
ROW_NUMBER() OVER (
PARTITION BY c.article_id
ORDER BY c.embedding_normalized <#> q.vec
) AS rn
FROM candidates c, query_vec q
) ranked
WHERE rn <= :topK
AND similarity >= :threshold
GROUP BY article_id
ORDER BY avg_similarity DESC
LIMIT :limit
""", nativeQuery = true)
List<Object[]> findArticlesByTwoStageSearch(
@Param("queryEmbedding") String queryEmbedding,
@Param("queryBinary") String queryBinary,
@Param("candidateLimit") int candidateLimit,
@Param("topK") int topK,
@Param("threshold") double threshold,
@Param("limit") int limit
);실행계획을 확인한 결과, 인덱스를 정상적으로 잘 활용한다.
위 쿼리에서 주요 포인트를 정리해보자.
- 계산 중복을 줄이기 위해 사용자 검색어 쿼리 l2 정규화 미리 해둠
- HNSW 인덱스를 통해 후보 글 담은 candidates CTE(Common Table Expression) 생성
<~>: 두 이진 벡터 사이의 거리를 측정 (XOR 연산)
- 후보 글에 대해 half_vector 비교하며 후보 글 중 점수 높은 순 선별
<#>: 내적. 벡터의 거리 계산
12만 벡터 기준 성능 결과
embedding한 chunk 벡터 개수가 12만 개 기준일 때 아래와 같이 성능이 개선됐다.
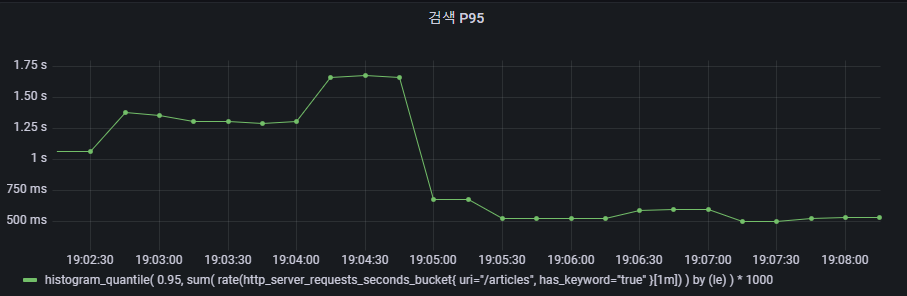
벡터가 8만 개에서 12만 개로 늘어났는데도 대부분의 응답시간이 1초 내외로 나온다.
성능 최적화는 성공적이었다. 1CPU, 1RAM DB 서버에서도 12만 개 벡터 검색이 원활하게 지원된다.
10. 검색을 기반으로 한 기능 도입
'관련 글 추천 기능' 도입
글을 클릭하면 그와 관련된 3개의 글을 추천해준다.
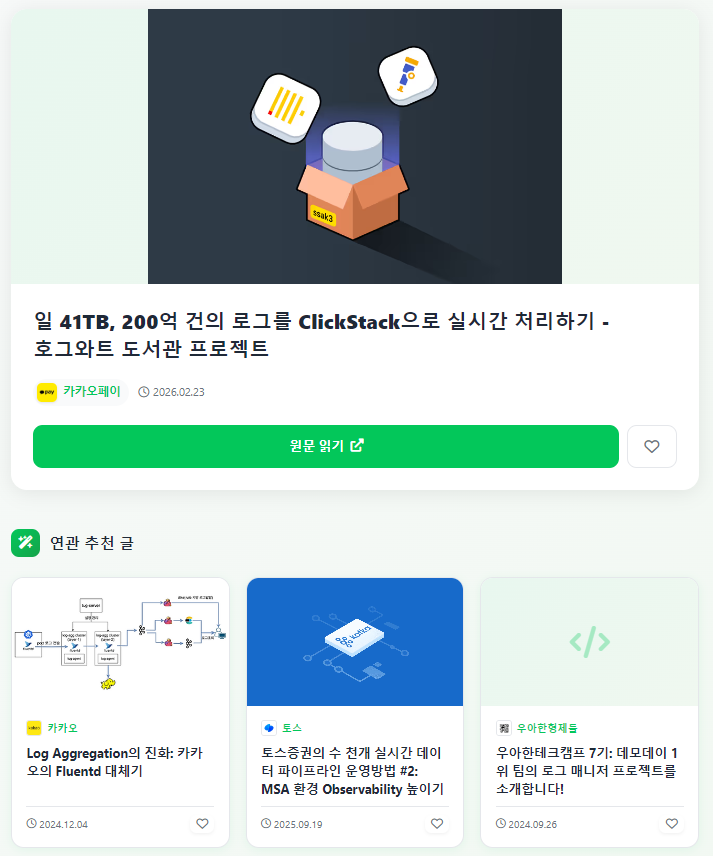
이를 통해 사용자에게는 원하는 글을 찾을 수 있게 도와주고, 체류 시간을 높임으로써 NewCodes 프로젝트 성장에 기여할 수 있다.
관련 글을 찾는 방식은 이러하다.
- (전처리) 글마다 BM25 점수가 높은 키워드들이 포함돼있는 chunk 1개를 선별한다.
- (사용자가 글을 클릭하면) 해당 글의 대표 chunk 벡터와 다른 모든 글의 대표 chunk 벡터와 유사도 비교하여 후보 글을 선정한다.
- 후보 글들에 대해서는 half_vector로 후보 글 전체 chunk 벡터를 비교한다.
- 해당 글의 제목을 analyzer로 분석하고 term으로 BM25 검색한다.
- 둘의 결과를 rerank해서 가장 상위 3개를 선정한다.
대표 chunk 1개를 정해서 후보 글을 먼저 추리는 이유는 속도 때문이다. 모든 글의 chunk끼리 비교를 하면 굉장히 오래 걸린다. 그래서 대표 chunk로 먼저 추리고 half_vector로 꼼꼼히 비교하는 방식을 채택했다.
'테마별 글 추천 기능' 도입
검색 기능과 관련 글 추천 기능을 바탕으로 테마별 추천 글 기능을 만들었다.
Featured Section(특정 목적을 가지고 선별된 글 모음)을 두어 유저의 콘텐츠 탐색 시간을 줄일 것. 지금처럼 그냥 뿌려두면 원래 해결하고자 했던 문제가 그대로 있음.
위 피드백을 바탕으로 구현한 기능이다. 해당 기능을 통해 예전에 발행되었던 좋은 글들을 다시 한 번 전달할 수 있는 효과가 있다. 또한, 사용자는 특정 섹션에 대한 지식을 더욱 깊고 넓게 알아갈 수 있다.
현재는 관리자가 직접 선별한 테마만 있지만, 향후에는 사용자가 선별한 테마도 직접 추가할 수 있게 개선할 예정이다.
정리
요약
- 사용자 피드백에서 출발하여 3달 동안 검색 기능 고도화에 투자
- 임베딩 벡터와 BM25를 통한 Semantic Search 구현
- 임베딩 벡터를 통해 사용자 쿼리와 유사한 맥락의 글 검색
- BM25를 통해 정확한 키워드 단위 검색
- 2단계 검색 구조를 통해 1CPU, 1GB RAM인 DB 서버에서도 12만 개 벡터 검색 지원
소감
-
검색은 잘 몰랐던 분야이기에 처음부터 완벽히 선형적으로 할 수는 없었다. 조금씩 시도해보고 과정을 되돌아보며 완성도를 높여갔다. 이 태도는 앞으로도 유지하자.
-
또한, 모르는 분야이기에 참고한 자료가 정말 많았다. 자료를 찾기 위해 NewCodes 검색을 쓰기도 했다. 이런 케이스에서 NewCodes가 더 쓰였으면 좋겠다.
-
IDE 안에 쏙 들어가서 코드를 짜는 즐거움은 AI 때문에 잃었지만, 기술의 내부 원리를 탐구하는 즐거움을 잃어버릴 수 없다. 블랙박스에서 점점 형체를 밝혀가는 재미가 있었다.
-
다음에는 검색 중 한 부분에 대해 더 집중해서 파보고 싶다. 이를테면, chunk를 몇으로 잘라야 recall이 가장 높을지 연구해보고 싶다.
-
글을 바탕으로 검색 기능의 완성도를 높여갔다. 내가 한 과정을 글로 정리하다보니 논리적으로 부실한 부분이나 아쉬웠던 부분들이 쉽게 보였다. 이를 바탕으로 점진적으로 개선해나갔다. 그러다보니 이 글 쓰면서 개선하는 데 한 달이 걸렸다. 이를 'BDI(Blog Driven Improvement)'라 부르고 싶다.
향후 개선할 점
- chunk 전략, embedding api 선정에 대해서는 NewCodes 데이터에 기반한 의사결정
- 사용자가 검색 후 무슨 아티클 방문하는지 등 로그 바탕으로 검색 품질 개선하기
- 현재 검색 속도 성능 지표는 '단일 요청'이기에 '부하 테스트'를 해서 정확히 지표를 측정해야 함
레퍼런스
- semantic search
- BM25
- ParadeDB
- FTS
- HNSW
- analyzer
- chunk
- https://learn.microsoft.com/en-us/azure/search/vector-search-how-to-chunk-documents
- https://developer.nvidia.com/blog/finding-the-best-chunking-strategy-for-accurate-ai-responses/
- https://elib.dlr.de/221921/1/COINS_CAMERA_READY_IEEE_APPROVED.pdf
- https://www.anthropic.com/news/contextual-retrieval
- https://m.blog.naver.com/n_cloudplatform/223974030008
- https://tech.hancom.com/improving-generative-search-accuracy-through-document-chunk-knowledge-generation/
- https://tech.ktcloud.com/entry/2025-11-ktcloud-rag-ai-%EC%B2%AD%ED%82%B9%EC%A0%84%EB%9E%B5-%EC%B5%9C%EC%A0%81%ED%99%94
- https://www.pinecone.io/learn/chunking-strategies/
- RSF
- 이미지 출처
- embedding: https://weaviate.io/blog/how-to-choose-an-embedding-model
- Nori analyzer: https://elsboo.tistory.com/44
여기까지 해서 NewCodes에서 검색 기능을 고도화한 경험을 정리해봤습니다.
기술 블로그 큐레이팅 서비스 NewCodes 많이 방문해주세요!!
북마크 하시고 시간 날 때 한 번씩 들어와서 글 읽어보시는 거 추천드려요 ㅎㅎ
읽어주셔서 감사합니다!



검색(추천)이라는게 어떤 과정이 숨어있는지 덕분에 엿보아갑니다~! 많은 고민 덕분에 적절한 글들이 찾아지는구나 싶어요!
블로그 글을 쓰면서 작업이 같이 쌓여간다는 것도 재미있는 발견이였습니다!