쿼리 플랜 (실행계획)
DBMS는 SQL을 수행할 최적의 처리 경로를 생성해 주는 핵심 엔진인 옵티마이저(Optimizer)를 가지고 있다. 이 옵티마이저는 우리가 SQL을 작성하고 실행하면 이 쿼리를 어떤 순서로 실행하겠다고 실행계획을 세우게 된다. 이 실행계획이 어떤 순서로 짜여져 있냐에 따라 성능의 차이가 크기 때문에 plan을 보는 방법을 알아두면 쿼리 성능 개선에 큰 도움이 된다.
쿼리 플랜 보는 법
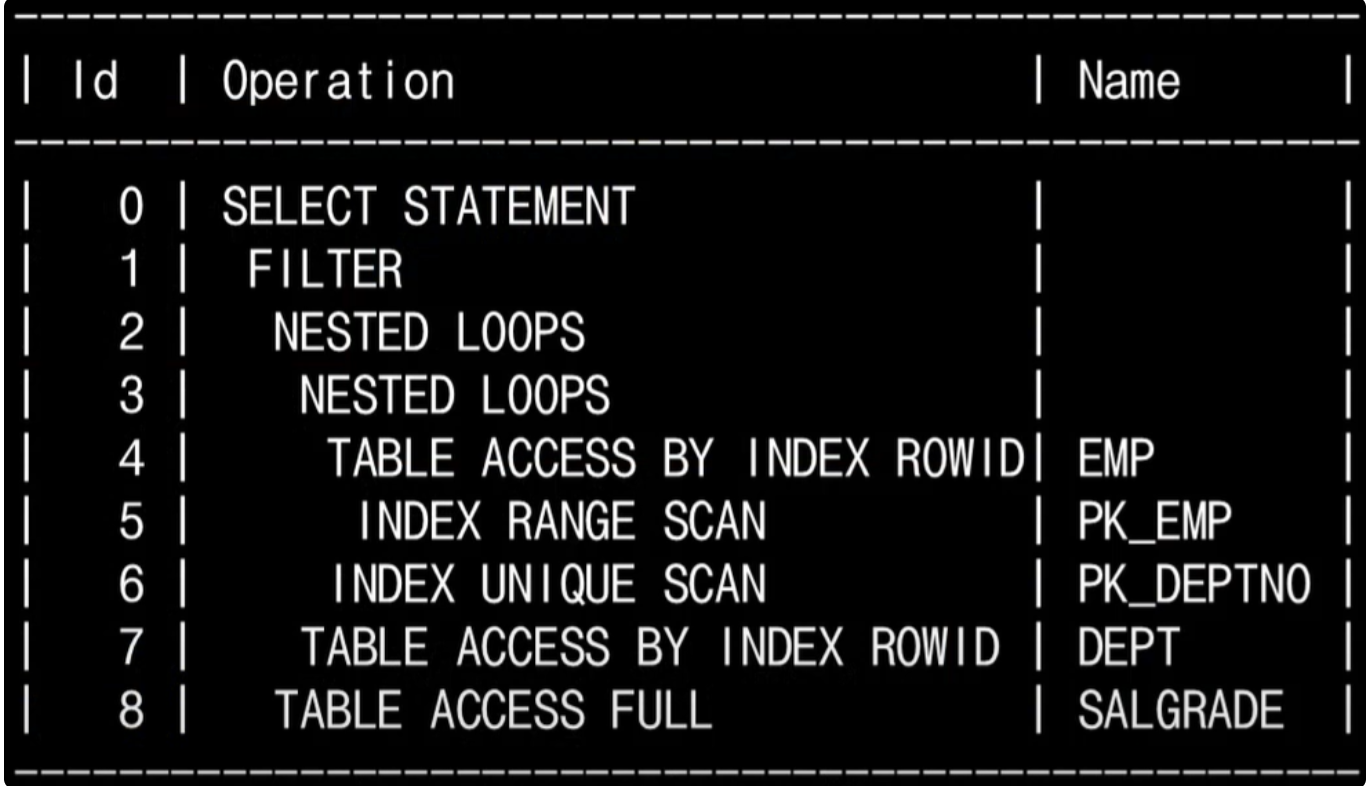
툴을 확인하거나 "Explain plan for"를 쿼리 앞단에 붙여서 실행계획을 떠보면 위와 비슷한 형식으로 나온다. (툴별로 조금씩 다를 수 있음)
우리는 보통 plan을 읽을 때 Operation 부분을 기준으로 순서를 보게 된다. 순서는 다음과 같이 읽는다.
- 레벨이 다른 경우에는 안쪽 레벨부터 해석한다.
- 레벨이 같은 경우에는 위에서 아래로 해석한다.
간단하게 말하면
- 부모와 자식중에서는 자식이 먼저
- 형제중에서는 형이 먼저
라는 말이다.
그래서 위의 예시는 순서대로 읽어보면 5 -> 4 -> 6 -> 3 -> 7 -> 2 -> 8 -> 1 -> 0 이다.
해당 순서로 위의 예시를 해석하면 다음과 같다.
5: PK_EMP 인덱스로 INDEX RANGE SCAN을 해서 조건을 만족하는 인덱스 블록과 키값을 검색한 결과를 반환
4: 5에서 읽은 ROWID를 기반으로 EMP 테이블에서 조건에 부합하는 결과 반환
6: PK_DEPTNO 인덱스에서 INDEX UNIQUE SCAN 방식으로 검색한 결과의 ROWID 반환
3: 4, 6번에서 반환된 데이터 기준으로 NESTED LOOP JOIN 방식으로 4번에서 반환된 데이터의 숫자만큼 반복해서 조인한 결과 반환
7: 4번과 동일하게 DEPT 테이블에서 조건에 부합하는 결과 반환
2: NESTED LOOP JOIN 방식으로 JOIN의 결과 반환
8: SALGRADE 서브쿼리 실행
1: 서브쿼리를 통해 해당 조건을 만족하는 데이터를 필터링해서 반환
PLAN으로 성능 개선하기
Plan을 뜨면 우리는 다음과 같은 요소들을 확인할 수 있다. (Oracle, Dbeaver 기준)

그 중 주목해야하는 값은 Cost, Cardinality, Bytes이다.
Cost
- 옵티마이저가 측정한 오퍼레이션 수행에 필요한 예측 비용.
- 플랜 읽는 순서에 따라 누적된 값. 대체로 작을 수록 효율적인 쿼리.
- Full Scan을 해야하는 쿼리는 의미가 없을 수 있음.
- cost 수치가 더 높은데 빠른 경우도 있음.
Cardinality
- 행 집합에서 행의 수를 표시 (분포도)
- 행 집합은 기본 테이블, 뷰, 조인이나, GROUP BY의 결과
- 작을 수록 SQL이 빠를 수 있음 (작을수록 행이 적음)
Bytes
- 각 실행계획 단계마다 Access된 byte 수를 의미 (I/O)
즉 위 이미지의 플랜을 종합하면, 해당 쿼리는 최종적으로 1개의 데이터를 읽어오며, 77,522Byte의 I/O를 유발하고 1,385만큼의 비용을 발생시킨다.
다른 예시를 살펴보자.

이 플랜에서는 고객 테이블을 FULL SCAN을한 뒤에 SORT를 하는데, 차례대로 633K -> 6M 만큼의 비용을 발생시킨다. 우리는 여기서 조건절의 인덱스 유무도 중요하지만 소팅도 튜닝에서 중요한 요소임을 알 수 있다.
또 다른 예시를 보자.
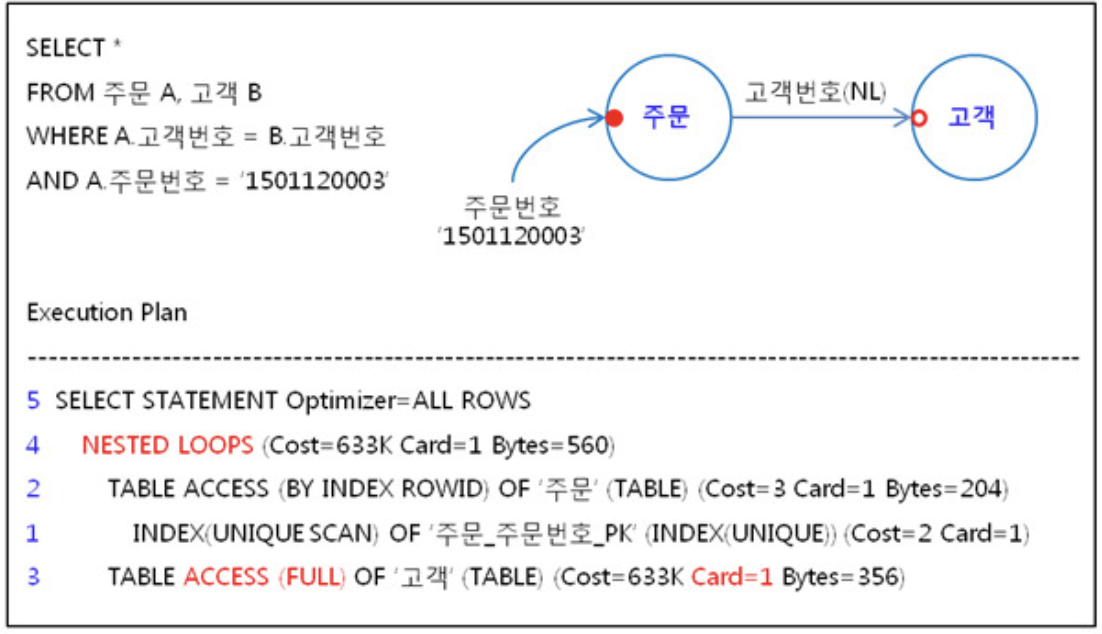
주문 테이블의 주문번호는 인덱스가 걸려있어 INDEX(UNIQUE SCAN)을 하고 있지만 고객 테이블에서는 고객 번호에 인덱스가 없어 TABLE ACCESS (FULL) 로 풀스캔을 하고 있음을 알 수 있다. 그런데 여기서 Card=1이라는 값으로 고객번호가 UNIQUE 함을 알 수 있고, 고객번호 컬럼을 인덱스로 생성해야 함을 알 수 있다.
인덱스를 생성한 결과는 다음과 같다.
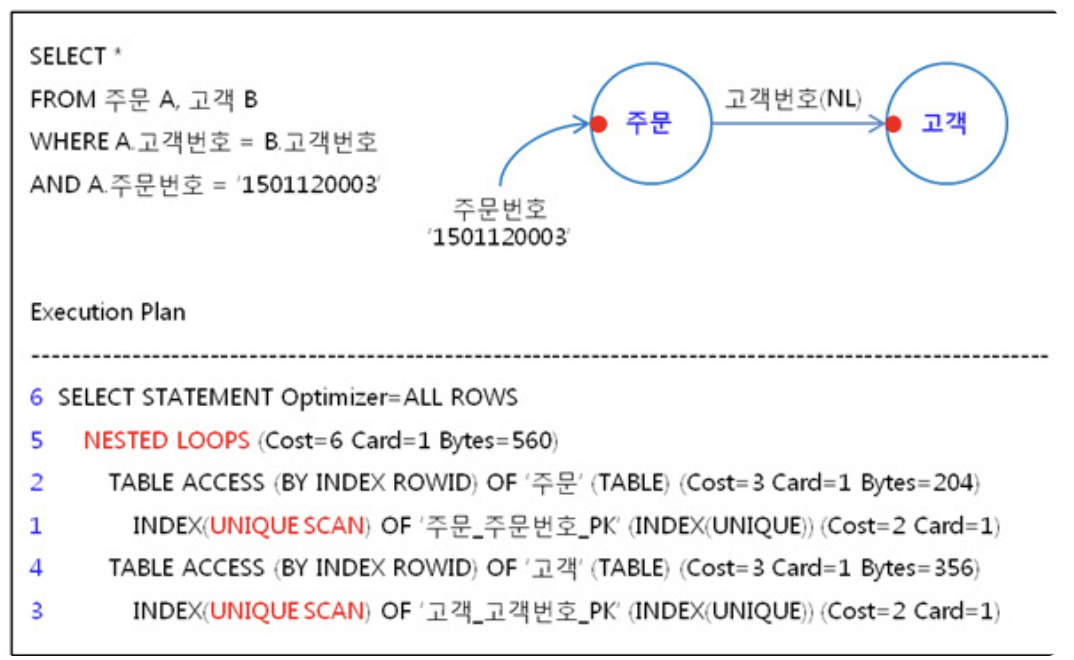
고객 테이블에서도 주문테이블과 동일하게 INDEX SCAN을 하고 있다. 이처럼 테이블 FULL SCAN을 하는 경우에 우리는 3가지를 생각해 볼 수 있다.
- 해당 쿼리에 대한 적절한 인덱스가 존재하지 않는 경우로, 필요한 인덱스를 생성해 해결 가능하다.
- 인덱스는 존재하나 인덱스를 타지 않는 경우로, 힌트절을 사용해서 해결 가능하다.
- 테이블을 FULL SCAN 하는 것이 인덱스를 통한 랜던 엑세스보다 유리한 경우로, 데이터 조회 범위가 커서 인덱스를 사용하는 것이 별 효용성이 없을 때다.
MySQL 쿼리플랜
- ID: 실행계획의 순서. 이 순서대로 select 문이 실행
- select_type:
-SIMPLE : 단순 select문
-PRIMARY : 첫번째 쿼리
-DERIVED : select문으로 추출된 테이블 ( from 절에서의 서브쿼리 또는 inline view)
-SUBQUERY : sub query 중 첫번째 select문
-UNION : UNION쿼리에서 PRIMARY를 제외한 나머지 select문
-DEPENDENT SUBQUERY
-DEPENDENT UNION - table: 대상이 되는 테이블 or alias명
- partitions: 파티션 사용 시, 대상이 되는 파티션
- type
-data access 타입(우수한 순서대로 적어 둠)
-system : 0개 또는 하나의 row를 가진 테이블. const 타입의 특별한 케이스. (MyISAM, Memory 테이블)
-const : primary key나 unique Key의 모든 컬럼에 대해 equal 조건으로 검색 반드시 1건의 레코드만 반환
-eq_ref : 조인에서 첫 번째 읽은 테이블의 컬럼값을 이용해 두 번째 테이블을 primary key나 unique Key로 equal 조건 검색으로 두번째 테이블은 반드시 1건의 레코드만 반환 (1:1 관계)
-ref : 조인의 순서와 인덱스의 종류와 관계없이 equal 조건으로 검색 (1:n 관계)
-unique_subquery : IN(sub-query) 형태의 조건에서 반환 값에 중복 없음
-index_subquery : unique_subquery와 비슷하지만 반환 값에 중복 있음
-range : 인덱스를 하나의 값이 아니라 범위로 검색. 가장 많이 사용
-Index : 인덱스를 처음부터 끝까지 읽는 인덱스 풀 스캔
-All : 풀스캔. 성능 가장 안 좋음 - possible_keys: 해당 테이블에서 데이터를 찾기위해 선택한 인덱스 목록
- key: 실제로 쿼리 실행에 사용한 인덱스
- key_len: 쿼리를 처리하기 위해 단일, 다중 컬럼으로 구성된 인덱스의 각 레코드에서 몇 바이트까지 사용했는지
- ref: 행을 추출하는데 키와 함께 사용된 컬럼이나 상수 값
- rows:
-쿼리 수행에서 예상하는 검색해야 할 행수. 조인문이나 서브쿼리 최적화에 있어서 중요한 항목.
-조회 결과 수와 rows가 차이가 크다면 성능 개선 필요 - extra: 쿼리에 관한 추가적인 정보
-distinct : 이미 처리한 값과 동일한 값을 가진 Row는 처리하지 않음.
-not exist : left join을 수행함에 매치되는 한 행을 찾으면 더 이상 매치되는 행을 검색하지 않음.
-Range checked for each record :사용할 좋은 인덱스가 없음.
-using filesort : 정렬을 위해 추가적인 과정을 필요로 함(물리적인 정렬작업 수행)
-using index : 실제 데이터 Block을 읽지 않고 인덱스 Block 만으로 결과를 생성할 수 있는 경우
-using temporary : 임시 테이블을 사용. order by 나 group by 절이 각기 다른 컬럼을 사용할 때 발생
-using where : where절이 다음 조인에 사용될 행이나 클라이언트에게 돌려질 행을 제한하는 경우
-using index for group-by
쿼리를 가능한 한 빠르게 하려면, Extra 값의 Using filesort나 Using temporary에 주의해야 함
EXPLAIN의 출력 내용 중 rows 컬럼값들을 곱해봄으로써 얼마나 효과적인 join을 실행하고 있는지 알 수 있음
참고문서: 쿼리플랜으로 성능최적화하기 (추천)
참고문서
