데이터베이스 분할에 대한 고민
전체 데이터베이스에 모든 데이터를 한 테이블 혹은 데이터베이스에서 관리하기가 어려워진다. 데이터베이스 볼륨이 커지면 커질수록 데이터베이스 읽기/쓰기 성능은 감소할 것이고, 데이터베이스가 병목 지점이 될 것이다. 따라서 이를 적절히 분할할 필요가 있다. 데이터베이스를 분할하는 방법은 크게 샤딩(sharding)과 파티셔닝(partitioning)이 있다. 이 두 가지 기술은 모두 거대한 데이터셋을 서브셋으로 분리하여 관리하는 방법이다. 이번 포스팅에서는 이 둘의 개념과 차이점에 대해 알아본다.
파티셔닝
파티셔닝은 매우 큰 테이블을 여러개의 테이블로 분할하는 작업이다. 하나의 데이터베이스 서버 내에서 이루어진다. 큰 데이터를 여러 테이블로 나눠 저장하기 때문에 쿼리 성능이 개선될 수 있다. 이때, 데이터는 물리적으로 여러 테이블로 분산하여 저장되지만, 사용자는 마치 하나의 테이블에 접근하는 것과 같이 사용할 수 있다는 점이 특징이다. 수직 파티셔닝과 수평 파티셔닝 방법이 있다.
수직 파티셔닝
수직 파티셔닝은 테이블의 Column을 분할하여 여러 개의 서로 다른 테이블로 나누는 방법이다.
성능 개선 이외에도 이미 정규화가 되어있는 테이블을 퍼포먼스를 위해서, 또는 민감한 정보에 제한을 걸어서 접근을 방지하기 위해서, 자주 사용되지 않는 Column을 모으기 위해서 수직 파티셔닝을 수행할 수 있다.
수평 파티셔닝
데이터베이스에서 테이블의 Row를 분할하여 여러 개의 서로 다른 테이블로 나누는 방법이다. 주로 데이터베이스의 용량이 커지면서 성능 저하를 막기 위해 사용된다.
파티셔닝은 DML( 데이터 조작어, SELECT, INSERT, UPDATE, DELETE )의 성능이 개선되고 유지보수성, 가용성이 향상된다는 장점이 있지만 join 복잡도가 증가하는 것과 분산으로 관리와 무결성 유지가 어려워지는 단점이 있다.
파티셔닝 방법
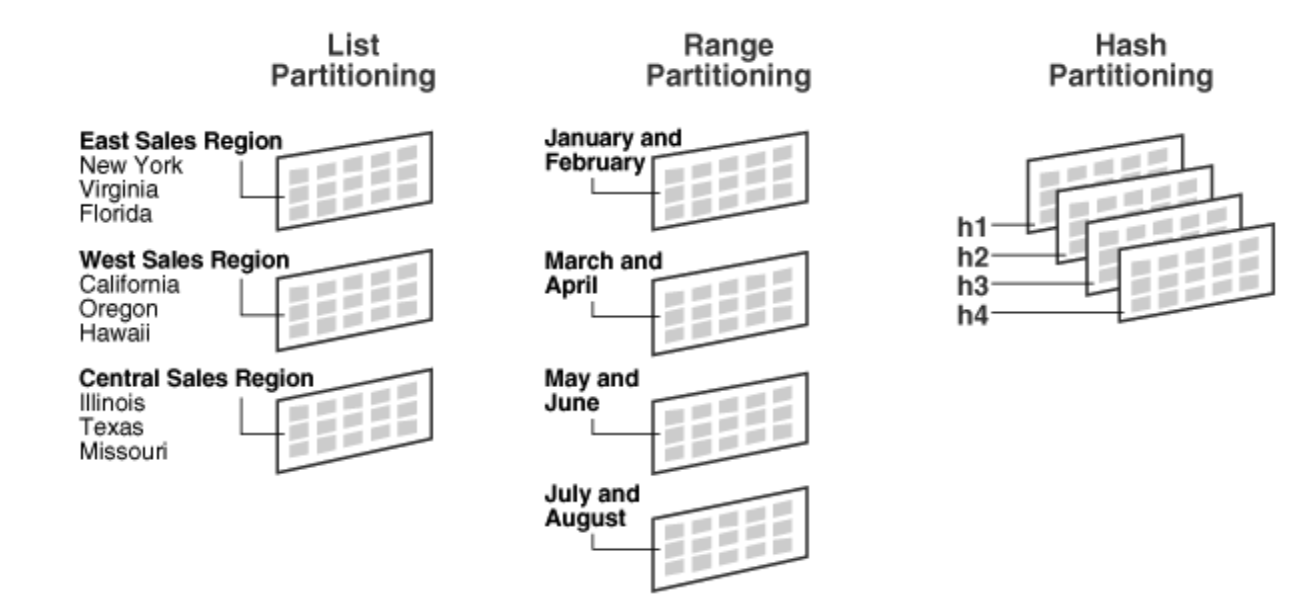
범위 파티셔닝 (Range Partitioning)
- 연속적인 값을 범위를 기준으로 하여 분할
- 우편 번호, 날짜, 분기 등의 데이터에 적합
리스트 파티셔닝 (List Partitioning)
- 데이터 값이 특정 목록에 포함된 경우 데이터를 분리
- 나라, 지역 등의 데이터에 적합
해시 파티셔닝 (Hash Partitioning)
- Key값 등 특정 Column의 값을 Hashing 하여 분할
- 균등한 데이터 분할이 가능
- 범위가 없는 데이터에 적합
합성 파티셔닝 (Composite Partitioning)
- 위 종류 중 2개 이상을 사용하여 분할
샤딩
샤딩은 동일한 스키마를 가지고 있는 데이터를 다수의 데이터베이스에 분산하여 저장하는 기법이다.
어떻게 보면 샤딩은 수평 파티셔닝과 비슷하지만 차이점은 수평 파티셔닝의 경우 동일한 서버에 저장되어 있지만 샤딩은 서로 다른 서버에 분산하여 저장한다는 점입니다. 따라서 쿼리 성능 향상뿐만 아니라 부하가 분산되는 효과까지 얻을 수 있다. 즉, 샤딩은 데이터베이스 차원의 수평 확장( scale-out )이다.
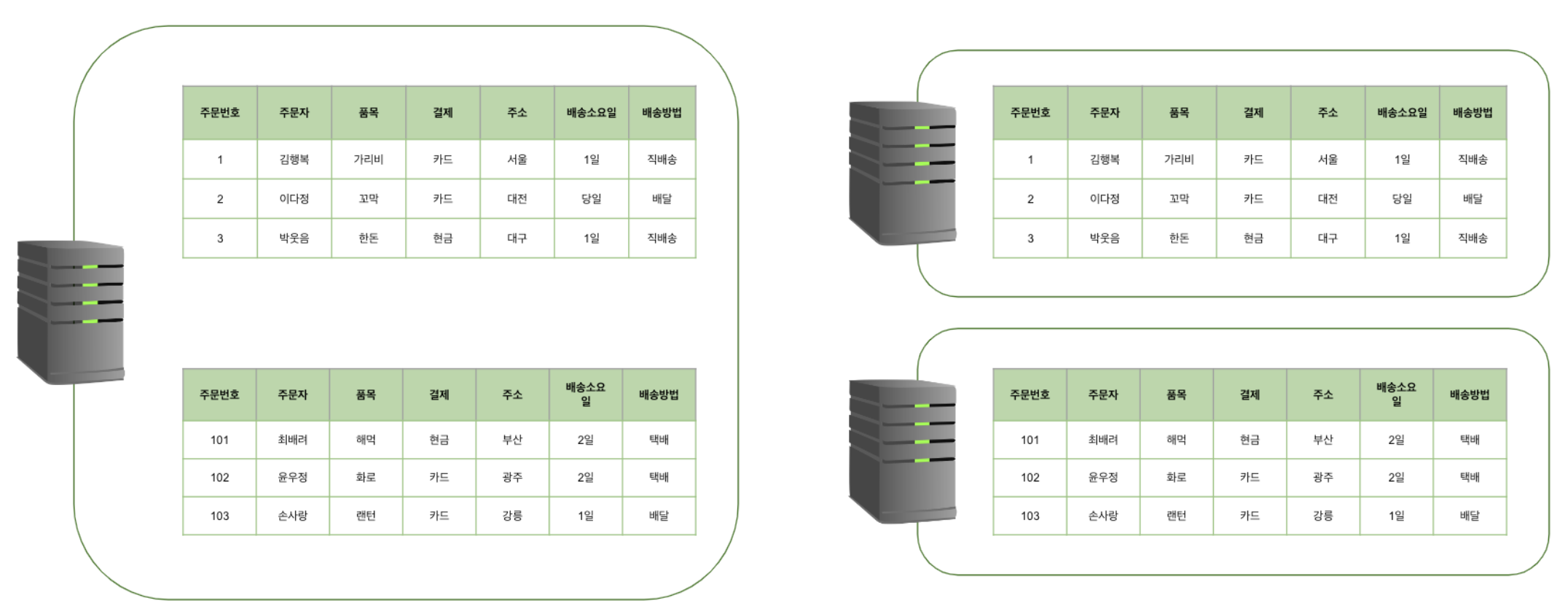
위처럼 모든 파티션을 같은 DB 서버에 저장하는 수평 파티셔닝과 다르게 샤딩은 각 파티션들을 서로 다른 DB 서버에 저장함으로서 DB서버의 부하( Load )를 분산시키는 목적이 있다. 이때 파티션 키( Partition Key )를 샤드 키( Shard Key )라고 부르고 각 파티션을 샤드( Shard )라고 부른다. 규모가 큰 서비스, 데이터가 많이 쌓이는 테이블, 트래픽이 많이 몰리는 경우에 사용한다.
샤딩은 데이터를 물리적으로 독립된 데이터베이스에 각각 분할하여 저장하므로, 여러 샤드에 걸친 데이터를 조인하는 것이 어렵다. 또한, 한 데이터베이스에 집중적으로 데이터가 몰리면 Hotspot이 되어 성능이 느려진다. 따라서 데이터를 여러 샤드로 고르게 분배하는 것이 중요하다.
샤딩 종류는 다양하지만 Range sharding과 Hash Sharding에 대해 알아보도록 하자.
Hash Sharding
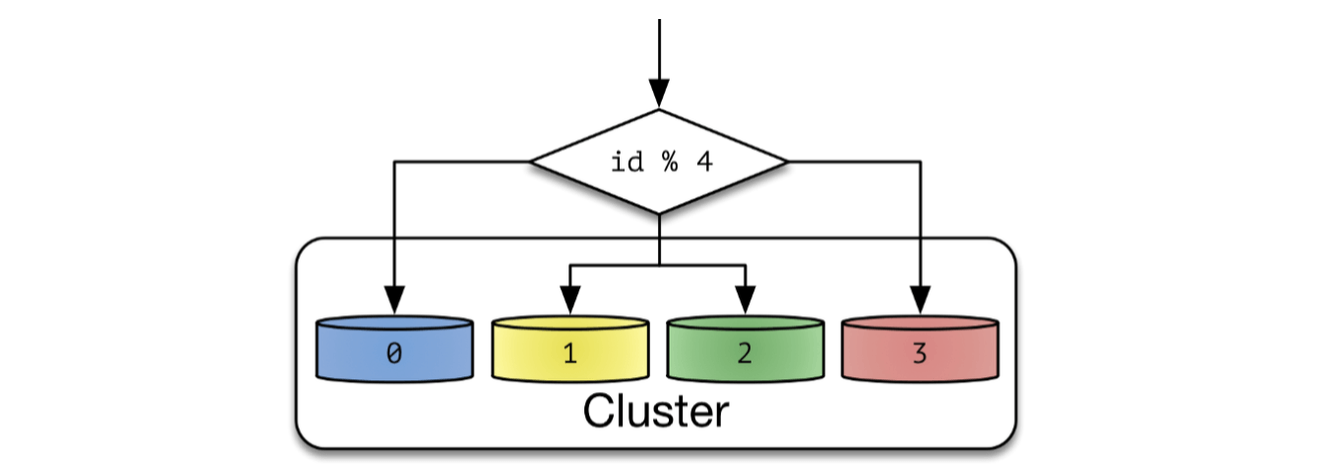
Hash Sharding 중 나머지 연산을 사용한 Modular Sharding 을 알아본다. Modular Sharding은 PK값의 모듈러 연산 결과를 통해 샤드를 결정하는 방식이다. 총 데이터베이스 수가 정해져있을 때 유용하다. 데이터베이스 개수가 줄어들거나 늘어나면 해시 함수도 변경해야하고, 따라서 데이터의 재 정렬이 필요하다.
Range Sharding
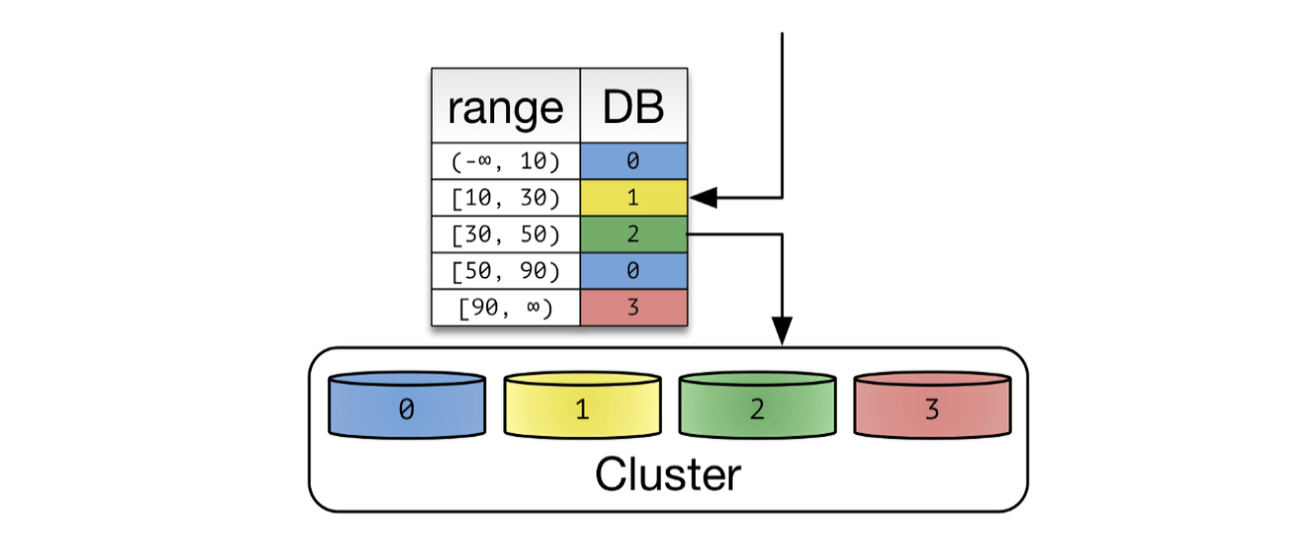
PK 값을 범위로 지정하여 샤드를 지정하는 방식이다. 예를 들어 PK가 1~1,000 까지는 1번 샤드에, 1,001~2,000 까지는 2번 샤드에, 2,001~ 부터는 3번 샤드에 저장할 수 있다. Hash Sharding 대비 데이터베이스 증설 작업에 큰 리소스가 소요되지 않는다. 따라서 급격히 증가할 수 있는 성격의 데이터는 Range Sharding 을 사용함이 좋아보인다. 이런 특징으로 Range Sharding은 Dynamic Sharding 으로도 불린다.
다만, 이렇게 기껏 분산을 시켜놨는데 특정한 데이터베이스에만 부하가 몰릴 수 있다. 예를 들어 페이스북 게시물을 Range Sharding 했다고 가정해보자. 대부분의 트래픽은 최근에 작성한 게시물에서 발생할 것이다. 위 그림에서는 2, 3번 샤드에만 부하가 몰리는 것이다. 부하 분산을 위해 데이터가 몰리는 DB는 다시 재 샤딩(re-sharding)하고, 트래픽이 저조한 데이터베이스는 다시 통합하는 작업이 필요할 것이다.
레플리케이션 (Replication)
레플리케이션은 데이터베이스 시스템에서 데이터의 복제를 통해 데이터베이스의 가용성과 안정성을 높이는 기술이다. 레플리케이션을 사용하면 데이터베이스 시스템에서 발생한 데이터의 변경 사항을 여러 대의 서버에 동일하게 복제하여 데이터 손실을 방지하고, 읽기 작업의 성능을 높일 수 있다.
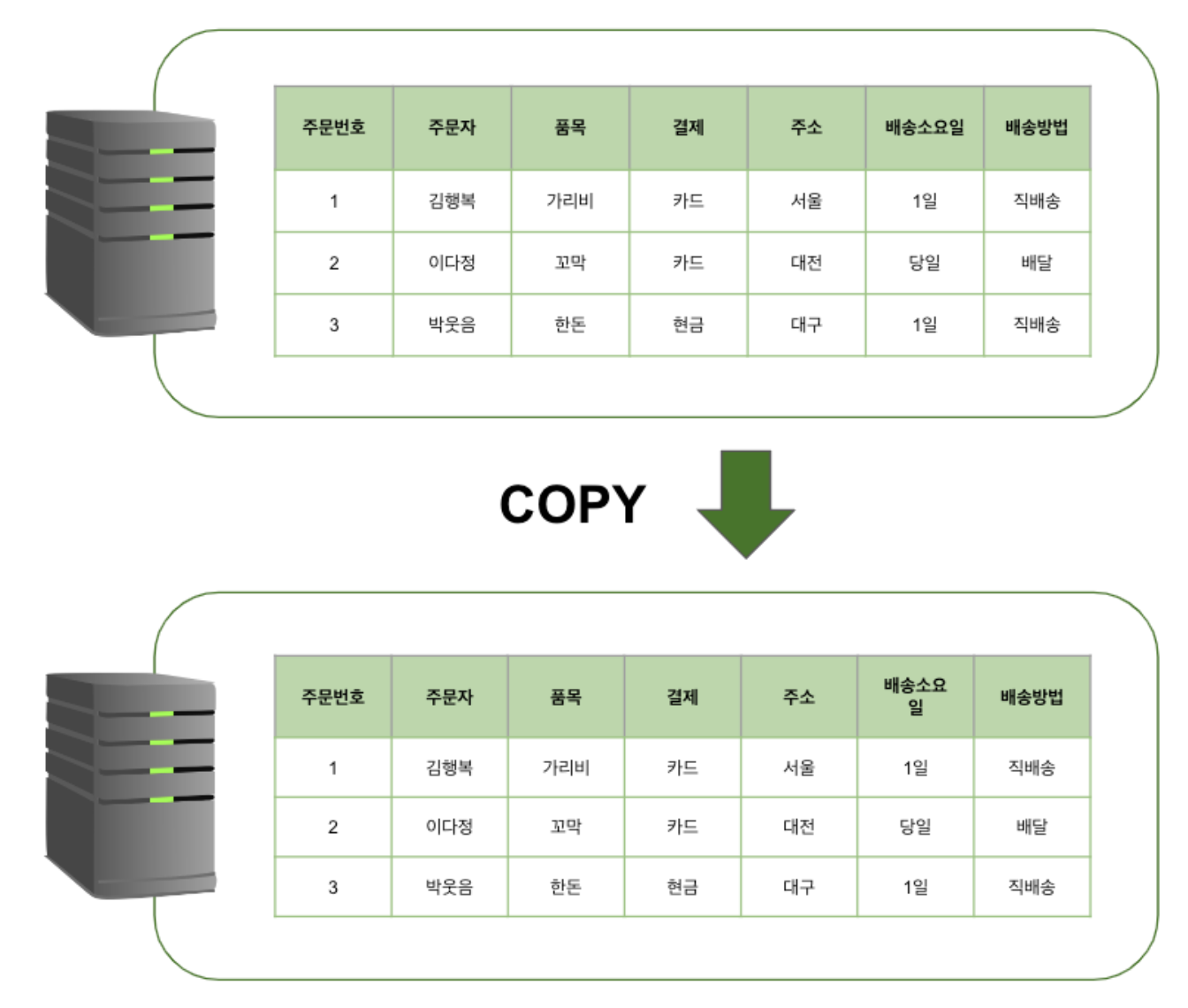
원본의 서버는 Master / Primary / Leader 등으로 불리며 복제된 서버는 Slave / Secondary / Replica 등으로 불린다. 복제된 서버는 한대 이상의 서버가 있을 수 있다.
Leader 데이터베이스에 장애가 발생할 경우 Replica를 Leader로 승격시켜 빠른 서비스 복구가 가능하다는 장점이 있지만 서버가 다르기 때문에 동기화에 대한 어려움이 있다.
파티셔닝과 샤딩은 데이터베이스의 볼륨이 커졌을 때 적절히 분할하여서 성능 최적화를 하기 위한 방법이다. 파티셔닝은 한 데이터베이스 서버에서 큰 테이블을 여러개의 테이블로 분할하는 방법이다. 물리적으로 분할이 되었지만 논리적으로는 하나의 테이블을 사용하는 것처럼 사용할 수 있다. 파티셔닝은 컬럼을 기준으로 분할을 하는 수직 파티셔닝과 행을 기준으로 분할하는 수평 파티셔닝이 있다. 둘다 성능 개선을 할 수 있지만 그 중 수직 파티셔닝은 민감한 정보를 분리하거나 사용하지 않는 컬럼을 모으기 위해서 사용되기도 한다. 파티셔닝은 DML의 성능이 개선되고 유지보수성, 가용성이 향상된다는 장점이 있지만 join 복잡도가 증가하는 것과 분산으로 관리와 무결성 유지가 어려워지는 단점이 있다. 샤딩은 동일한 스키마를 가지고 있는 데이터를 다수의 데이터베이스에 분산하여 저장한다. 샤딩은 수평 파티셔닝과 비슷하지만 차이점은 수평 파티셔닝의 경우 동일한 서버에 저장되어 있지만 샤딩은 서로 다른 서버에 분산하여 저장한다는 점에서 차이가 있다. 쿼리 성능 향상뿐만 아니라 부하가 분산되는 효과까지 얻을 수 있다.
샤딩은 데이터를 물리적으로 독립된 데이터베이스에 각각 분할하여 저장하므로, 여러 샤드에 걸친 데이터를 조인하는 것이 어렵다. 또한, 한 데이터베이스에 집중적으로 데이터가 몰리면 Hotspot이 되어 성능이 느려진다. 따라서 데이터를 여러 샤드로 고르게 분배하는 것이 중요하다.
(1) 어떤 경우에 파티셔닝을, 어떨때 샤딩을 선택할까?
- 파티셔닝
-데이터 규모가 크지만 단일 서버로 처리 가능할 때
-쿼리 패턴이 명확하고 시간/범주 기반일 때
-JOIN과 트랜잭션이 많을 때
-데이터 생명주기 관리가 중요할 때# 오래된 데이터 삭제 DROP PARTITION p_2022; # 2022년 데이터 일괄 삭제 (1초) # vs 파티셔닝 없을 때 DELETE FROM orders WHERE order_date < '2023-01-01'; # 수 시간 소요
- 샤딩
-데이터가 단일 서버 용량을 초과할 때
-수평 확장이 필수적일 때
