Title : Denoising Diffusion Probabilistic Models
Year : 2020
Journal : Conference on Neural Information Processing Systems (NeurIPS 2020)
1. Introduction
2. Background
⭐ 본 논문에서는 비슷하게 보이는 수식이 정말 많이 나온다. 따라서, 각 미지수가 어떤 것을 의미하는지, 수식이 어떤 것을 말하고 있는지를 정확하게 짚고 넘어갈 필요가 있다. ⭐
핵심 Keyword
1. Reverse Process ()
-
가우시안 노이즈에서 노이즈를 걷어내어 원본이미지로 복원하는 과정.
-
Diffusion 모델은 Reverse Process를 학습하여 이미지 생성방법을 배운다.
-
마코프 체인 이용. -
t-1에서 t로 변하는 과정은 위와 같이 표현할 수 있음.
는 t단계에서의 이미지, 는
2. Forward Process
-
원본 이미지에 노이즈를 주입하는 과정
-
노이즈 주입은 로 이루어진다.
3. Negative Log Likelihood
- 학습 과정에서 최적화시키려고 하는 함수.

-
Iterative Markov chain 사용하며, 생성에 활용되는 조건부 확률분포 를 학습시키기 위해 Diffusion Process 를 활용
-
타 모델과의 두 가지의 차이점이 존재
(1) Gaussian Noise를 주입하는 forward과정을 학습 대상으로 생각하지 않음.
(2) 조건부 확률분포의 체인(Markov chain)으로 이루어짐
3. Diffusion model
-
패턴 생성과정을 학습하기 위해 고의적으로 패턴을 무너트리고(Diffusion process), 이를 다시 복원(Reverse process, Denoising process)하는 조건부 PDF를 학습
-
을 안다고 해도 을 바로 알 수는 없음. 따라서 학습을 해야함. 다만 가 Gaussian 분포를 따르면 그 역도 Gaussian 분포를 따른다.
-
를 학습해서 이 값이 에 근접할 수 있도록 학습한다.
-
large number of small perturbation. 큰 변화를 매우 작은 양으로 만듦. 1000번의 step으로 잘개 쪼갬.
3.1 Forward process
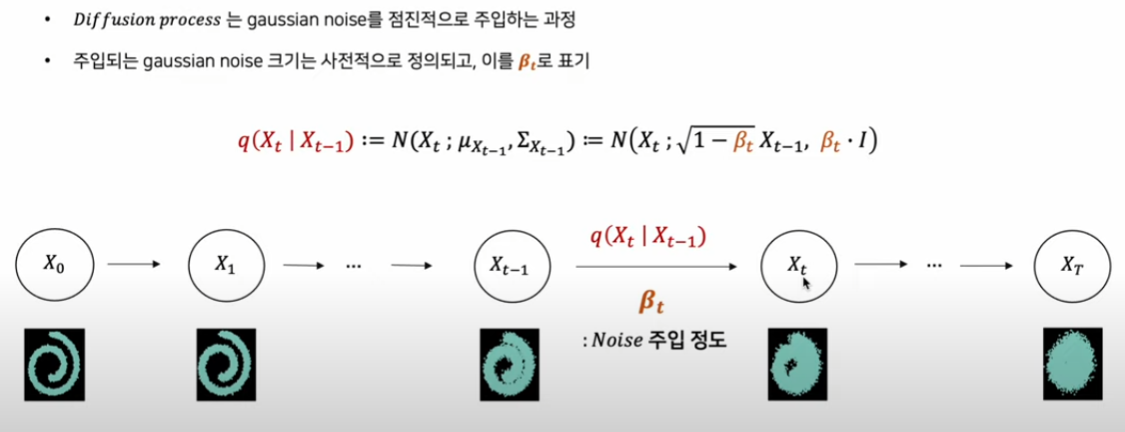
-
노이즈가 주입되는 양을 로 표현한다.
-
는 점진적으로 커짐.
n_times = 1000, beta_minmax=[1e-4, 2e-2]
beta_1, beta_2 = beta_minmax
betas = torch.linspace(start = beta_1, end = beta_2, steps = n_times).to(device) # follows DDPM paper
self.sqrt_betas = torch.sqrt(betas)- diffusion noising 과정이 1000번으로 나뉘어서 주입됨.
def make_noisy(self, x_zeros, t):
epsilon = torch.randn_like(x_zeros).to(self.device)
sqrt_alpha_bar = self.extract(self.sqrt_alpha_bars, t, x_zeros.shape)
sqrt_one_minus_alpha_bar = self.extract(self.sqrt_one_minus_alpha_bars, t, x_zeros.shape)
# make noisy sample. forward process with fixed variance schedule
noisy_sample = x_zeros * sqrt_alpha_bar + epsilon*sqrt_one_minus_alpha_bar
return noisy_sample.detach(), epsilon # noise detach는 텐서를 복사하는 방법.사실상, Foward과정은 단순히 노이즈를 주입하는 과정이므로, 학습한다고 말할 수 없다. Forward Process는 constant하고, 무시가 가능하다.
3.2 Reverse Process
Reference
