
1. 자료 구하기
자료 수집은 데이터 분석과정에서 처음 만나는 관문이다
이 때 어떤 자료를 어떻게 수집할지는 분석에 소요되는 시간과 비용,
그리고 결과물의 수준을 결정한다
단순히 인터넷에서 자료를 가져올 때는 복사와 붙여넣기를 반복하면 되지만,
많은 자료가 여기저기 있거나 정기적으로 업데이트 되는 경우에는
크롤러 같은 자동 수집 도구를 사용하면 편하다
크롤러 : 웹을 돌아다니며 유용한 정보를 찾아 수집하는 프로그램
하지만 크롤러를 직접 만드는 일은 까다롭지만
공공데이터 포털에서는다양한 데이터를 이용할 수 있도록 API를 제공한다
하지만 API를 이용하려면 인증키가 있어야 한다
인증키는 API를 이용할 수 있는 권한으로서 허용된 사용자에게만 데이터를 제공한다
2. API 인증키 얻기
공공 데이터 포털 : https://www.data.go.kr/
1) 공공 데이터 포털 회원가입
2) API 활용 신청하기
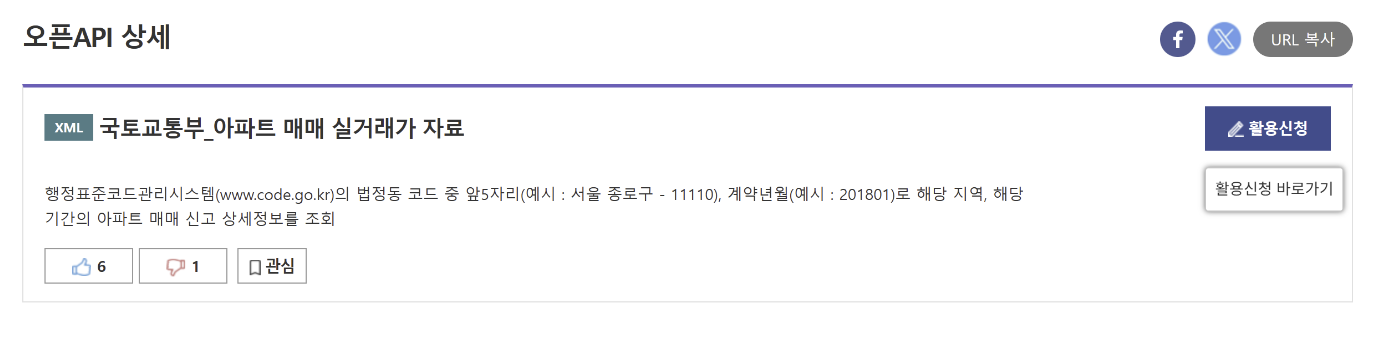
오픈 API 탭에서 '국토교통부_아파트 매매 실거래가 자료'를 찾아서 신청하였다
3) 승인 및 인증키 확인하기
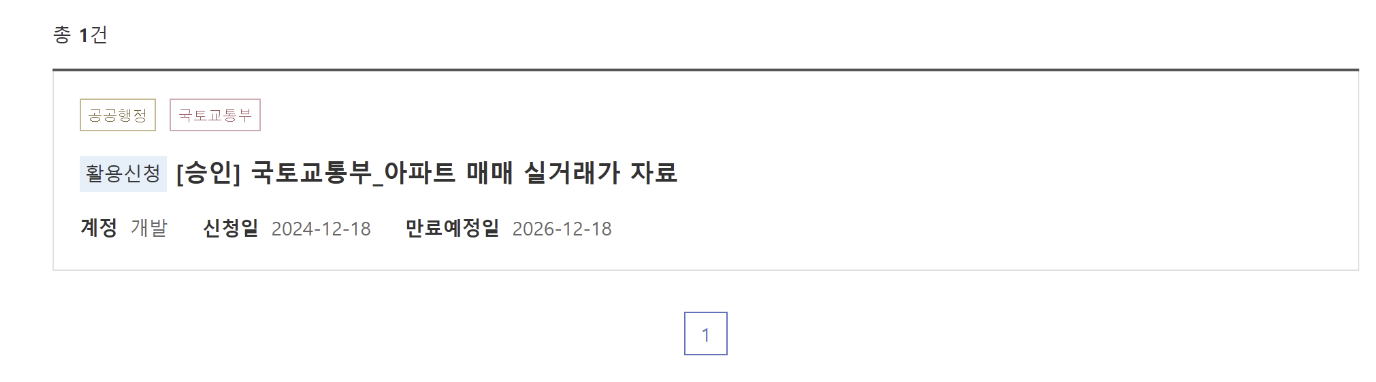
API 활용 신청을 맞치고 승인이 났는지 확인하려면 마이페이지를 확인하면 된다

또한 참고 문서 항목에 "기술문서" 가 있는데
API마다 이러한 기술 문서를 제공하기에 참조해서 사용하면 된다
3. API에 자료 요청하기
API에 자료를 요청하려면 규격에 맞게 특정한 정보를 전달해야 한다
그러면 이를 전달받은 API는 서버에서 알맞은 자료를 찾아서 응답해준다
1) 서비스 URL 확인하기
먼저 자료 요청을 어디에 해야 하는지를 알아야 한다
즉, 자료를 요청할 서버의 주소를 알아야 하는데 이를 '서비스 URL'이라고 한다
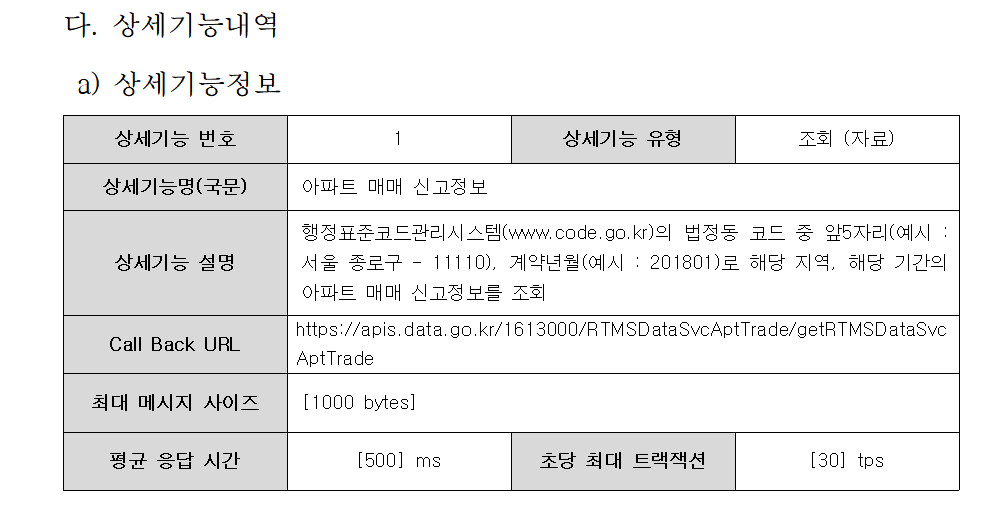
기술 명세서를 확인해보면 'call back URL' 항목의 주소가 바로 서비스 URL이다
https://apis.data.go.kr/1613000/RTMSDataSvcAptTrade/getRTMSDataSvcAptTrade
일단 기록해주자
2) 요청 변수 확인하기
자료를 어디에 요청해야 할지 알았다면 그 다음에는 어떻게 요청해야 할지도 알아야 한다
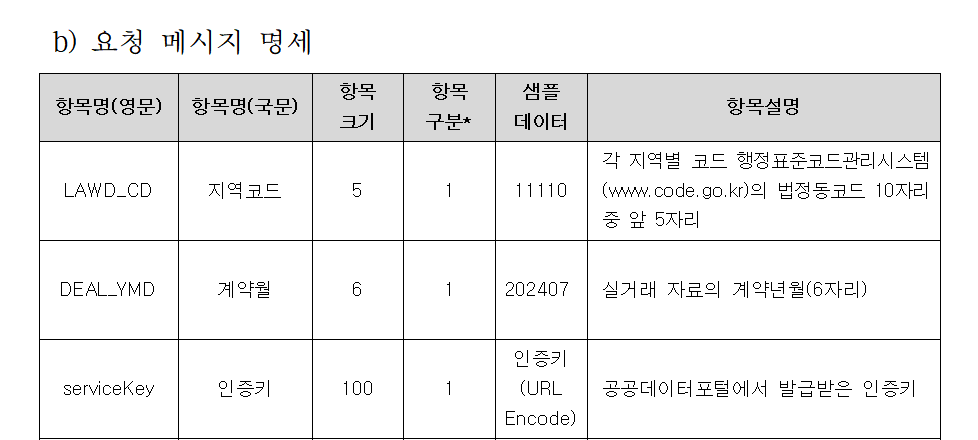
요청 메세지 명세를 보면 아파트 실거래 자료를 요청할 때
다음 3가지 정보가 필요하다고 한다
이 정보를 조합해 하나의 요청 URL로 만들어서 API에 요청하면
서버가 해당 자료를 찾아서 보내준다
3) 요청 URL 만들기
이제 API에 요청하는 URL을 만들어 보자
요청 URL은 '서비스 URL'과 '요청내역'으로 구성된다
서비스 URL은 앞에서 확인한 주소를 그대로 사용하면 되고
서비스 URL 다음에는 ? 연산자를 입력하고 이어서 요청 내역을 입력한다
요청내역은 앞에서 확인한 API가 요구하는 3가지 정보이다
서비스URL?LAWD_CD=지역코드&DEAL_YMD=거래연월&serviceKey=인증키

실제로 이렇게 입력하면
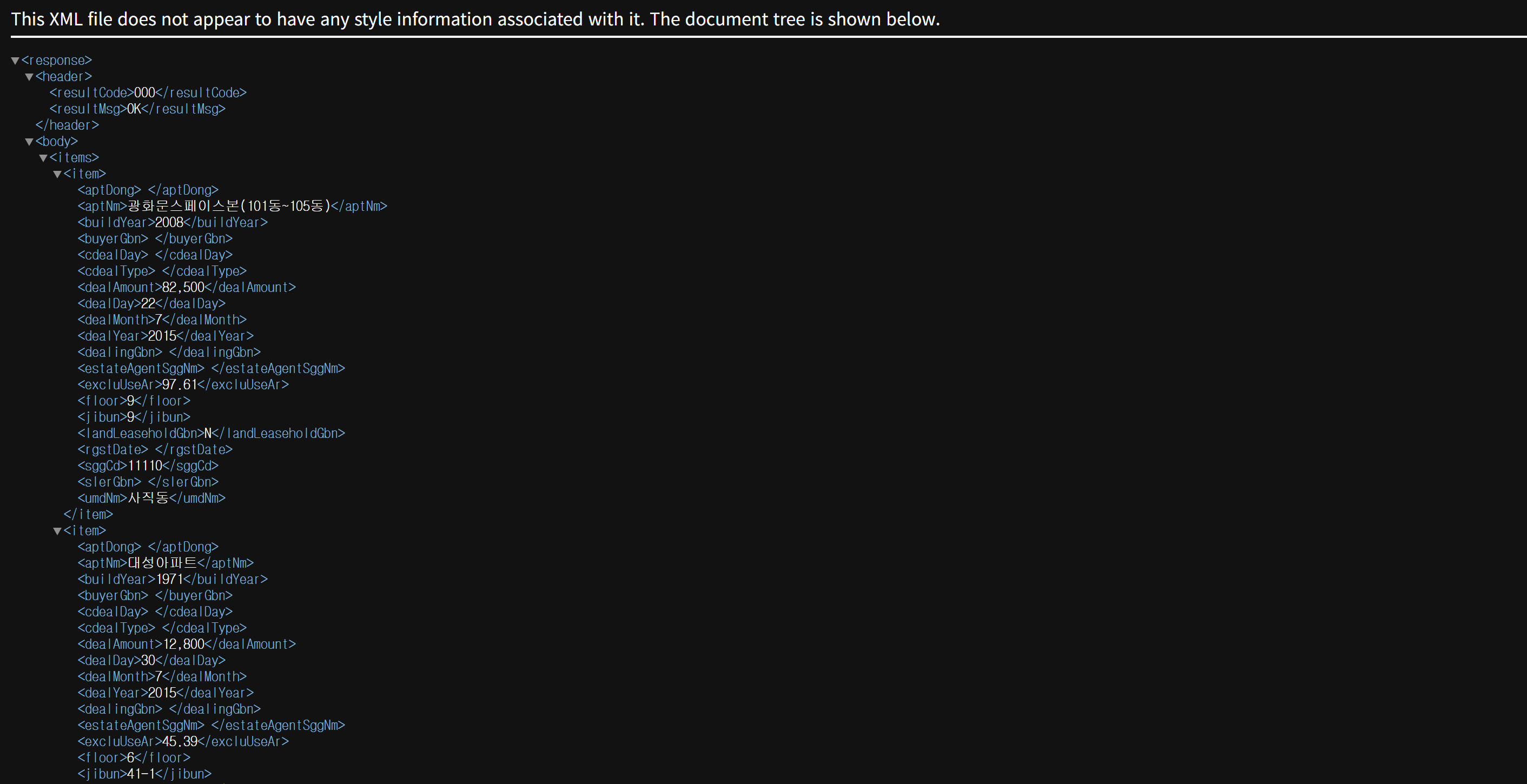
값을 주는 것을 확인할 수 있다
4. API응답 확인하기
요청 URL을 API에 보내면 서버는 이에 응답하여 결과를 제공한다
1) 응답 내역
응답내역은 크게 상태와 값 정보로 구분할 수 있다
상태 정보는 요청이 제대로 이루어졌는지 알려주는 확인 코드로서
결과 코드와 결과 메시지로 구성된다
요청이 제대로 이루어졌으면 각각 00와 NORMAL SERVICE라는 값을 받는다
API 마다 응답 데이터 형식은 다를 수 있다
대부분 XML 형식으로 반환하지만 JSON이나 CSV 형식으로 제공하는 API도 있다
여기서는 XML 형식으로 반환한다
2) XML 형태의 응답 내역
XML은 컴퓨터끼리 데이터를 원할하게 전달하는 것을 목적으로 만든 언어다
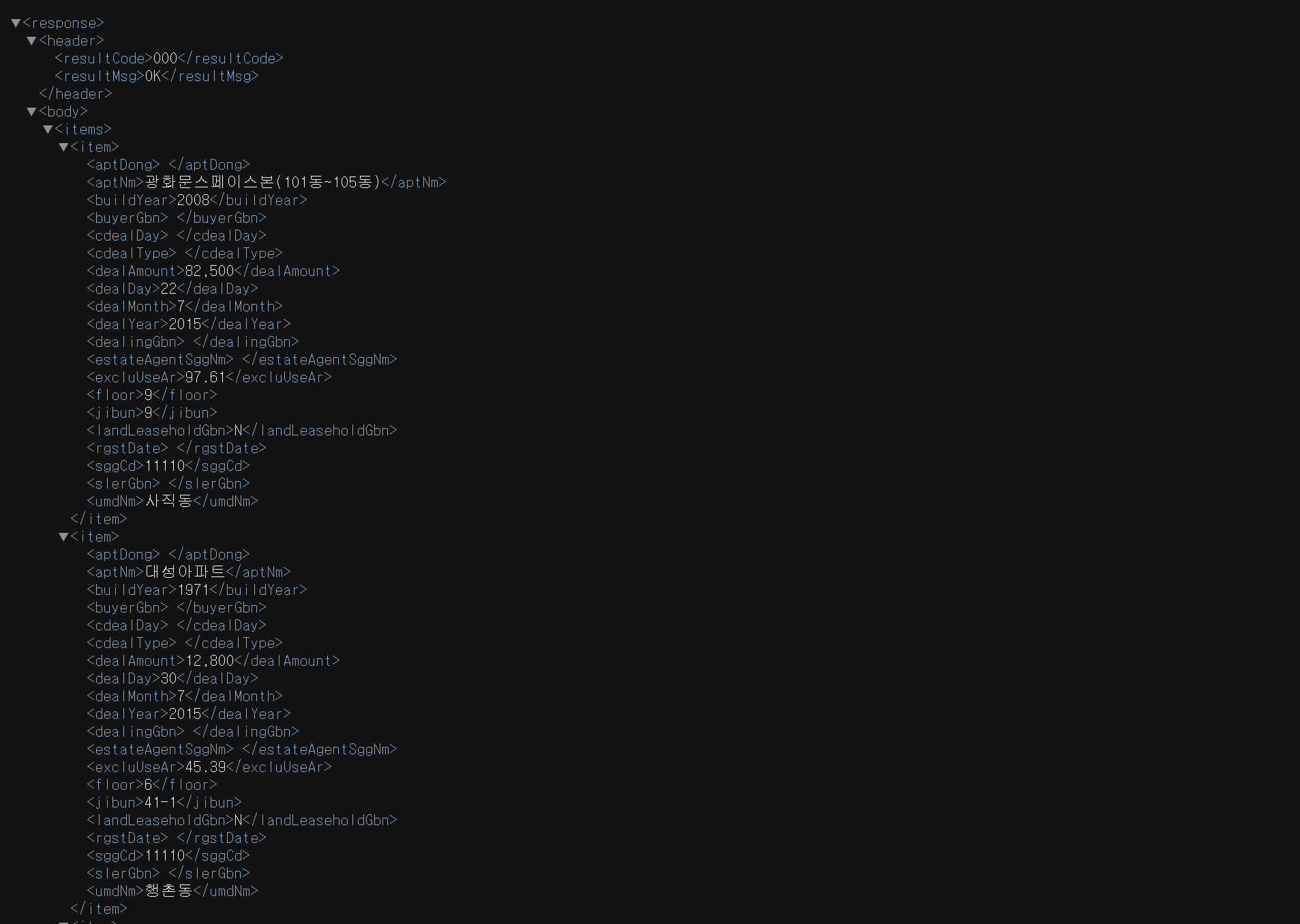
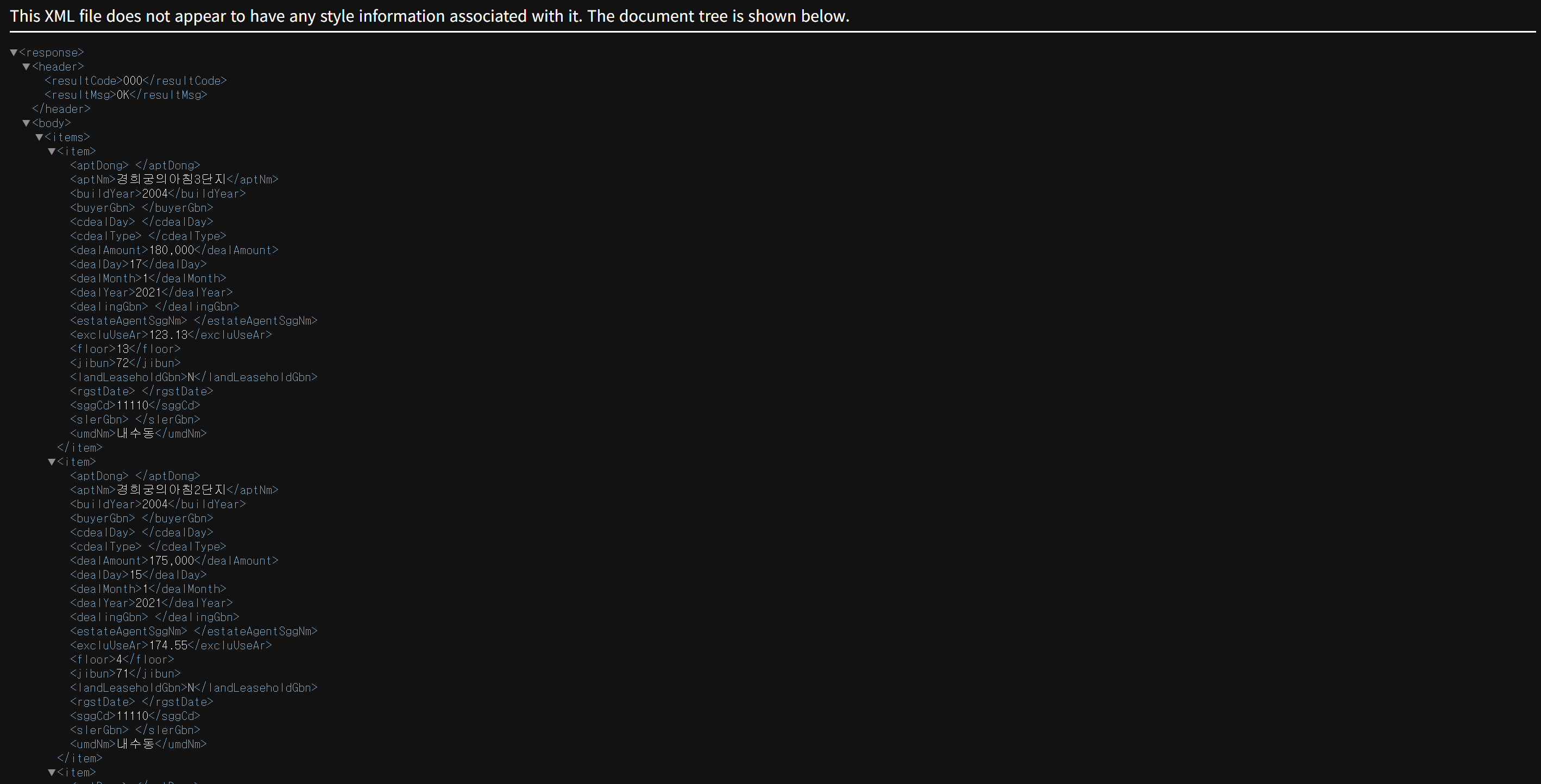
모든 XML 데이터는 루트 노드에서 출발하여 부모-자식 관계로 연결되어 있다
우리가 받고자 하는 실거래 자료는 응답 순번이 저장된 루트 노드인
<response>에서 출발한다 그리고 <header>와 <body>라는 노드를 포함한다
<header>는 상태정보를 알려주는 <resultCode>와
상태 메세지가 담긴 <resultMSg>로 구성되어 있다
<body>노드 아래에 있는<items>노드에는 세부 응답 내역이 있다
5. 크롤링 준비
1) 작업 폴더 설정
R 데이터 분석 작업을 시작할 떄 가장 먼저 해야할 일은 기본 작업 폴더를 생성하는 것이다
그리고 작업 폴더를 만들어주고 예제 파일을 그 안에 넣어준다
그러고 나서 새로운 R 스크립트 파일을 만들고 그 안에 코드를 작성한다
install.packages("rstudioapi") # rstudioapi 설치
setwd(dirname(rstudioapi::getSourceEditorContext()$path)) # 작업 폴더 설정
getwd() # 작업 폴더 확인
rstudioapi라는 라이브러리를 사용하면 스크립트가 저장된 위치를 작업 폴더로 쉽게 설정할 수 있다
그리고 setwd() 함수는 현재 위치를 작업 폴더로 설정하고,
getwd() 함수는 설정된 작업 폴더 위치를 출력한다
2) 수집 대상 지역 설정
앞서 API에 자료를 요청하는 방법으로 요청 URL을 살펴봤다
이 요청 URL을 만들려면 수집 대상 지역을 나타내는 지역 코드, 거래 연월,
그리고 인증키 정보가 필요하다
이 가운데에서 지역 코드는 예제로 미리 CSV 파일로 준비가 되어있다
한 번 지역 코드를 불러와보자
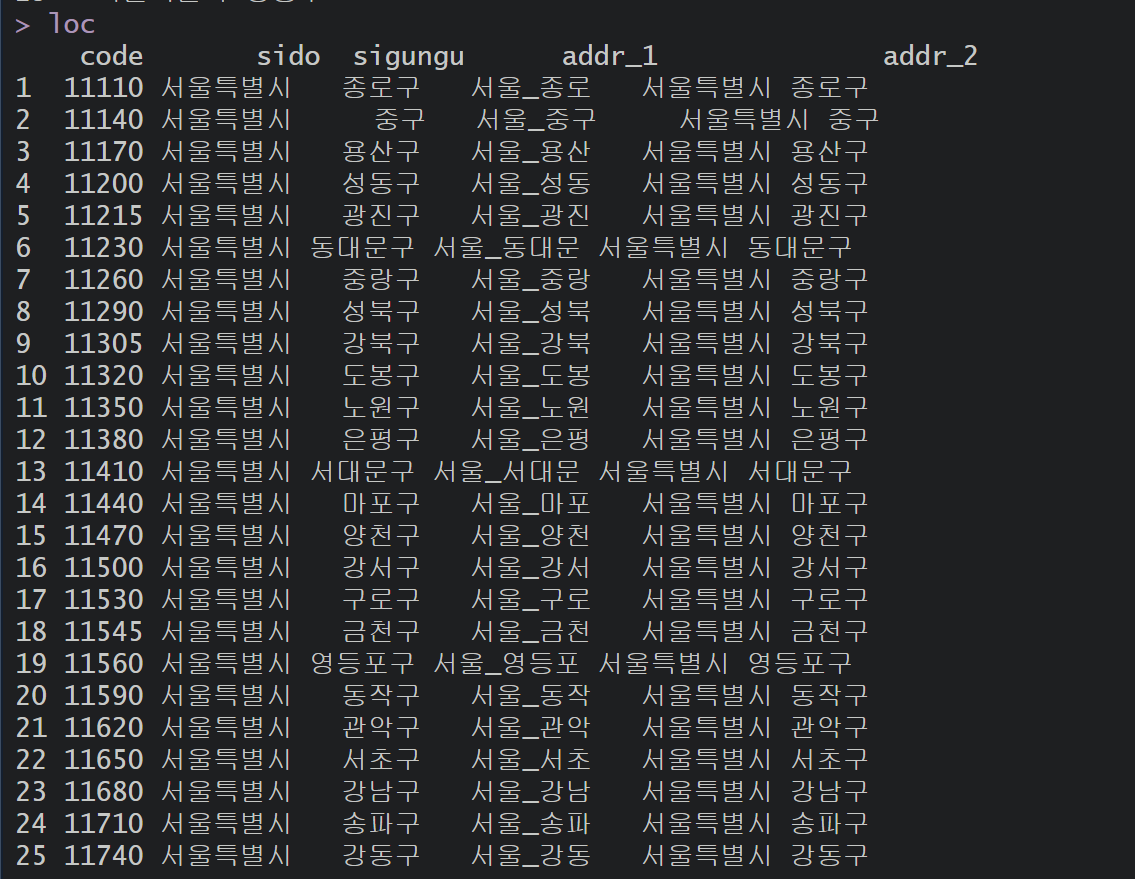
loc <- read.csv("./01_code/sigun_code/sigun_code.csv", fileEncoding="UTF-8") # 지역 코드
loc$code <- as.character(loc$code) # 행정구역명 문자 변환
head(loc, 2) # 확인
read.csv() 함수는 지역 코드를 불러오고, as.character() 함수로
행정구역 이름(loc$code)을 문자로 변환한다
그리고 head(loc,2) 코드는 추출 결과를 출력한다
3) 수집 기간 설정하기
두 번째로 필요한 정보는 언제부터 언제까지 데이터를 가져올 것인가를
나타내는 수집기간이다
분석에 필요한 자료는 2021년 1월부터 2021년 12월까지 12개월로 설정하고
기간설정은 YYYYMM(연도+월) 형식으로 한다
그래서 연도+월 목록 12개를 생성한다
datelist <- seq(from = as.Date('2021-01-01'), # 시작
to = as.Date('2021-12-31'), # 종료
by = '1 month') # 단위
datelist <- format(datelist, format = '%Y%m') # 형식 변환(YYYY-MM-DD => YYYYMM)
datelist[1:3] # 확인

seq(from=A, to=B, by=C)와 같은 형태로 연도+월 목록을 생성한다
해당 코드는 시작(A)에서 종료(B)까지 일정 간격(C)를 두고 연속된 자료를 생성하는 함수이다
YYYY-MM-DD 형식으로 날짜 데이터를 생성했지만 우리가 필요한 날짜형식은
YYYYMM이다 그래서 format(데이터,format='%Y%m') 코드로 YYYYMM 형식으로 변환한다
그리고 data[1:3]으로 처음부터 세 번째 자료까지 변환된 결과를 확인한다
4) 인증키 입력하기
공공 데이터 포털에서 발급받은 인증키를 입력한다
service_key <- "인증키" # 인증키 입력6. 요청 목록 생성
공공데이터포털에서 제공하는 아파트 실거래 API는 한 번에 행정구역 한 곳에서
1개월 이내에 이루어진 실거래 정보만 수집할 수 있다
따라서 대상 지역이나 기간을 늘리면 자료 요청 건수도 늘어난다
우리는 서울시에 속한 25개 자치구에서 1년 동안 실거래 자료를 수집하여 분석하려고 한다
그래서 25개 자치구별로 2021년 1월부터 12개월 동안 등록된 실거래 자료를 수집하려면
요청 URL을 모두 300건(25x12)을 만들어야 한다
1) 요청 목록 만들기
먼저 아무것도 들어 있지 않은 빈 목록을 만든다
list() 함수로 빈 요청 목록(url_list)을
url_list <- list() # 빈 리스트 만들기
cnt <- 0 # 반복문의 제어 변수 초깃값 설정2) 요청 목록 채우기
요청목록(url_list)은 '프로토콜 + 주소 + 포트번호 + 리소스 경로 + 요청 내역' 등
5가지 정보로 구성될 것이다
대부분 고정된 내용이지만 요청내역은 대상 지역과 기간이라는 2가지 조건에 따라 변한다
for ( i in 1:nrow(loc)) { # 외부 반복 : 25개 자치구
for ( j in 1:length(datelist)){ # 내부 반복 : 12개월
cnt <- cnt + 1 # 반복 누적 세기
#---# 요청 목록 채우기 (25x12=300)
url_list[cnt] <- paste0("https://apis.data.go.kr/1613000/RTMSDataSvcAptTrade/getRTMSDataSvcAptTrade?",
"LAWD_CD=",loc[i,1], # 지역 코드
"&DEAL_YMD=",datelist[j], # 수집 월
"&num0fRows=",100, # 한 번에 가져올 최대 자료 수
"&serviceKey=",service_key) # 인증 키
}
Sys.sleep(0.1) # 0.1초간 멈춤
msg <- paste0("[",i,"/",nrow(loc),"]",loc[i,3],"
의 크롤링 목록이 생성됨 => 총[",cnt,"]건") # 알림 메세지
cat(msg,"\n\n")
}
바깥쪽 반복문 for()은 서울시 25개 지역(자치구)을 순회하고, 안쪽 반복문 for()는 12개월을 순회한다 cnt는 반복횟수를 세는 변수이므로 현재 횟수에서 1만큼 더하도록 cnt + 1을 입력한다 그러면 반복문이 종료될 때마다 cnt가 1씩 증가하고 마지막에는 300까지 누적된다 따라서 중첩 반복문을 모두 마치면 url_list에 요청목록 300개가 저장된다
요청 구성 목록을 보면
"LAWD_CD="에는 지역코드
"&DEAL_YMD="에는 수집기간
"&num0fRows="에는 한 번에 가져올 최대 거래 건수로 100을 입력했다
"&serviceKey="는 앞에서 service_key에 설정한 인증키 정보를 입력합니다
Sys.sleep(0.1) 코드는 응답 결과를 보내는 서버의 부담을 줄이고자 반복문 속도를 0.1초씩 멈추는 코드이다 그리고 반복문이 한 번 완료될 떄마다 진행 상황을 알리고자 msg에 메시지를 생성하고 cat를 통해서 콘솔 창을 출력한다
3) 요청 목록 확인하기
length(url_list) # 요청 목록 개수 확인
browseURL(paste0(url_list[1])) # 정상 동작 확인(웹브라우저 실행)
length()는 전체 url_list가 몇 개인지 알려 줍니다
그리고 url_list[1]로 가져온 첫 번째 요청 URL을 browseURL()을 이용해
웹 브라우저로 열어서 제대로 동작하는지 확인할 수 있습니다
7. 크롤러 만들기
1) 임시 저장 리스트 만들기
library(xml2)
library(data.table)
# 임시 저장소 생성
raw_data <- list()
root_Node <- list()XML 데이터를 읽고 파싱하기 위해 xml2 라이브러리를 불러오고,
데이터를 구조화하고 효율적으로 다루기 위해서 data.table 라이브러리를 가져온다
그리고 각각의 임시 저장리스트를 만들었다
raw_data는 각 URL로부터 받은 원시 XML 데이터를 저장한다
root_Node는 각 URL의 응답에서 필요한 노드(전체거래내역)를 저장한다
2) 자료 요청하고 응답 받기
자료를 반복문으로 요청하고 응답결과를 저장을 해보자
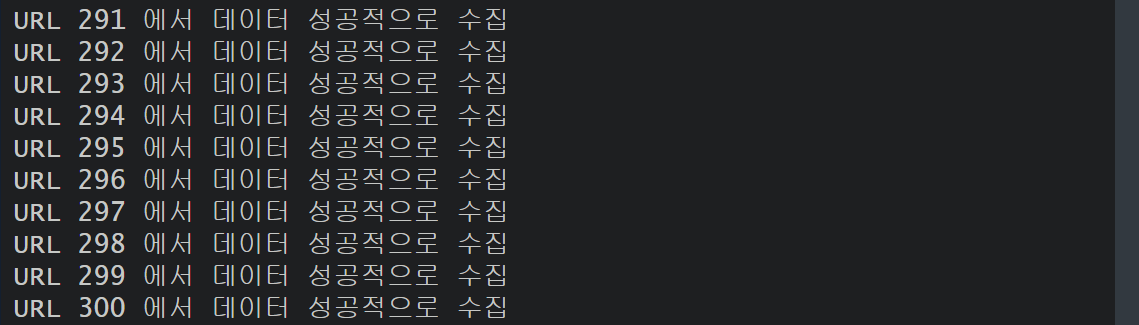
for (i in 1:length(url_list)) {
tryCatch({
# URL에서 XML 데이터를 읽어오기
raw_data[[i]] <- read_xml(url_list[[i]])
# 루트 노드 추출
root_Node[[i]] <- xml_find_all(raw_data[[i]], ".//body//items//item")
if (length(root_Node[[i]]) > 0) {
cat("URL", i, "에서 데이터 성공적으로 수집\n")
} else {
cat("URL", i, "에서 데이터 없음\n")
}
}, error = function(e) {
cat("URL", i, "에서 오류 발생:", conditionMessage(e), "\n")
})
}
read_xml(url_list[[i]])를 통해서 각 URL에서 XML 데이터를 읽어오고,
xml_find_all(raw_data[[i]], ".//body//items//item")
를 통해서 응답 XML에서 item 태그들을 찾습니다
이 때 XPath .//body//items//item는 body 태그 아래의 items 노드에서
모든 item을 선택하도록 한다
그리고 데이터 유무를 확인하기 위해서 length(root_Node[[i]])
응답 내에 item 태그가 있는지 확인하고 데이터가 없으면 "데이터 없음"을 출력한다
이때 tryCatch를 사용해 오류가 발생해도 코드 실행이 중단되지 않고
메시지를 출력하도록 했다
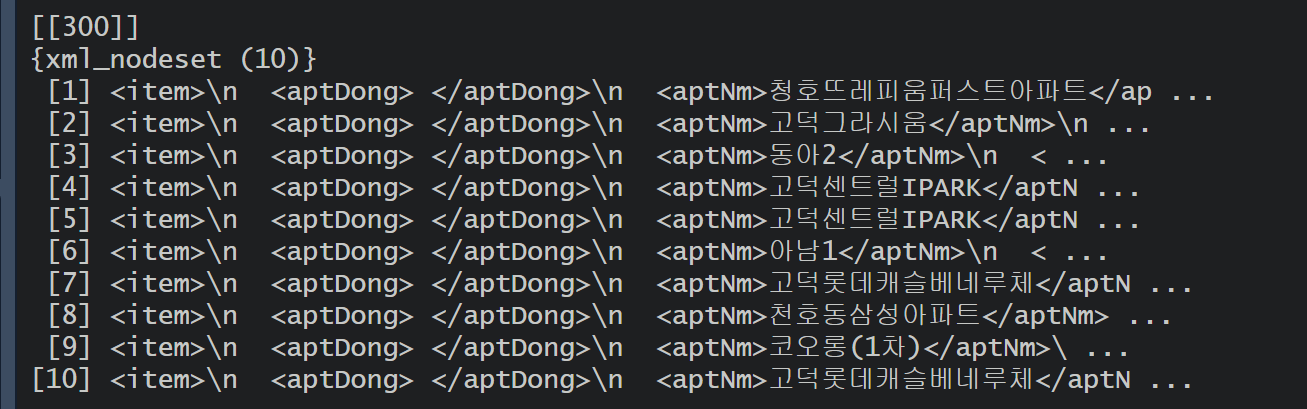
3) 개별 거래 내역 추출
output_dir <- "./02_raw_data"
if (!dir.exists(output_dir)) {
dir.create(output_dir)
}
for (i in 1:length(root_Node)) {
if (length(root_Node[[i]]) > 0) {
tryCatch({
item_list <- list()
for (m in 1:length(root_Node[[i]])) {
item_temp <- xml_children(root_Node[[i]][[m]]) %>% xml_text(trim = TRUE)
names(item_temp) <- xml_children(root_Node[[i]][[m]]) %>% xml_name()
item_dt <- data.table(
aptNm = item_temp["aptNm"],
buildYear = item_temp["buildYear"],
dealAmount = item_temp["dealAmount"],
dealDay = item_temp["dealDay"],
dealMonth = item_temp["dealMonth"],
dealYear = item_temp["dealYear"],
excluUseAr = item_temp["excluUseAr"],
floor = item_temp["floor"],
jibun = item_temp["jibun"],
umdNm = item_temp["umdNm"]
)
item_list[[m]] <- item_dt
}
apt_data <- rbindlist(item_list, fill = TRUE) # 데이터 병합
file_name <- paste0(output_dir, "/data_", i, ".csv") # 파일 이름 생성
write.csv(apt_data, file_name, row.names = FALSE, fileEncoding = "UTF-8") # CSV 저장
cat("파일 저장 완료:", file_name, "\n")
}, error = function(e) {
cat("데이터 처리 중 오류 발생 (URL", i, "):", conditionMessage(e), "\n")
})
}
}
먼저 출력물을 저장할 디렉토리를 만든다
output_dir 은 데이터 파일을 저장할 디렉토리 경로이다
그리고 데이터의 저장을 위해서 반복문을 돌린다
root_Node[[i]]는 현재 URL 요청에 대한 XML 데이터에서 각 item 노드를 추출
xml_children()은 XML 노드의 자식 노드를 가져옴
xml_text(trim=TRUE)는 자식 노드의 텍스트 값을 가져오고, 공백을 제거
xml_name()은 자식 노드의 이름을 가져와서 데이터의 열 이름으로 사용
item_temp는 각 거래 데이터를 저장한 리스트
그리고 각 거래 데이터를 열 이름과 매칭하여 data.table로 저장
그리고 각 item_dt를 item_list에 추가한다
그리고 rbindlist()를 통해서 item_list에
저장된 여러 개의 데이터 테이블을 하나로 병합한다
그리고 파일 이름을 생성해서 CSV 파일로 저장하도록 한다
4) 결과저장
최종 정리된 apt_bind 데이터를 csv 파일로 저장한다
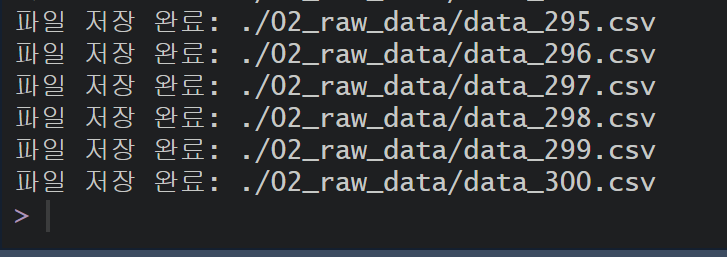
최종적으로 정리를 하면 공공데이터포털의 아파트 실거래 API를 이용하여
데이터를 요청하고, 수집한 데이터를 처리한 후 개별 CSV 파일로 저장하는 과정을 수행했다
해당 내용은 Do it 공공데이터로 배우는 R 데이터 분석을 참조하여 진행하였습니다
