
해당 내용은 Google Cloud AI 활동간 이우성 강사님의 강의를 토대로 작성하였습니다.
BigQuery
AI 모델을 만들 때 보통적으로 데이터가 필요하다
데이터를 스토리지에 저장해서 사용하는 방법하는 방법도 있지만
BigQuery를 통해서도 분석이 가능하다오늘은 완전 관리형 서비스인 BigQuery을 알아보도록 하자
데이터 웨어 하우스 (Data WareHouse, DW)
일반적인 데이터베이스는 데이터 저장이 목적이지만
저장이외의 데이터 분석까지를 도와주는 것이 데이터 웨어 하우스이다
POS 트랙잭션: 매장에서 상품이나 서비스를 판매할 때 발생하는 모든 거래 기록을 의미 ex) 상품, 판매가격, 결제 방식, 거래시간등
마케팅 자동화 시스템: 다양한 마케팅 작업과 캠페인을 자동화
고객 관리 시스템: 고객 데이터를 체계적으로 관리
여러 소스에서 가져온 구조화된 데이터와 반구조화된 데이터를 분석하고 보고한다
비정형데이터는 데이터베이스에 저장할 수 없다
그래서 비정형 데이터를 클라우드 스토리지에 저장하고 그 위치를 데이터베이스에서 저장해놓을 수 있다
- 임시 분석과 커스텀 보고서에 적합
- 과거 데이터와 현재 데이터를 이용하여 데이터를 분석할 수 있게 도와준다
ex) X-ray 파일들을 과거에는 사람들이 판단했지만 최근에는 이를 AI가 해준다
클라우드 데이터 웨어 하우스는 내부 및 외부 데이터 소스에서 데이터를 수집, 통합, 저장
데이터는 일반적으로 데이터 파이프라인을 사용하여 소스 시스템에서 전송한다
데이터 파이프라인: 데이터를 수집하고, 데이터를 변환하고, 데이터를 적재하는 프로세스
ETL (추출,변환,로드) 과정: 데이터가 소스 시스템에서 추출되어 변환된 후 데이터 웨어하우스에 로드되도록 한다
파이프라인을 활용하면 AI 모델을 생성하는데 큰 도움이 된다
대규모 환경에서는 데이터 파이프라인이 매우 유용하다
클라우드 데이터 웨어하우스는 실시간 또는 거의 실시간으로 데이터에서 활성화하기 위한 스트리밍 사용사례를 지원한다
트랜잭션 데이터를 수집하고 추출하는 플랫폼을 데이터 웨어 하우스라고 한다
BigQuery
BigQuery는 GCP에서 데이터 웨어 하우스 서비스의 이름이다
BigQuery는 데이터 보관이 목적이 아니라 데이터 분석이 목표이다
머신러닝, 지리정보 분석, 비즈니스 인텔리전스와 같은 기본 제공 기능으로 데이터를 관리하고 분석할 수 있게 해주는 완전 관리형 엔터프라이즈 데이터 웨어 하우스이다
VM 생성, 설치, 환경구성 등등을 GCP가 대신 해주고 우리는 서비스 부분에만 집중하면 된다
이러한 방식으로 환경구축을 해주는 서비스를 완전 관리형 서비스라고 한다
BigQuery : 서버리스 (완전 관리형) 아키텍처에서는 SQL 쿼리를 사용하여 제로 인프라 관리에 관한 조직의 가장 큰 질문을 해결할 수 있다
서버리스: 서버가 없다 (서버생성을 우리가 하지 않는다, GCP가 대신 생성해준다)
데이터 수집, 분석, AI모델 생성까지 전부 BigQuery에서 가능하다
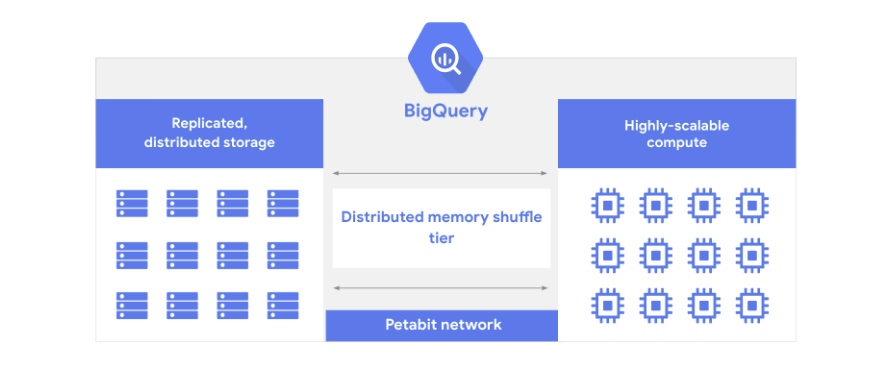
BigQuery 아키텍처는 데이터를 수집, 저장, 최적화하는 스토리지 레이어와
분석 기능을 제공하는 제공하는 컴퓨팅 레이저로 구성Big Query는 스토리지 레이어에 대량의 데이터를 가져오고
데이터 분석은 컴퓨팅 레이저에서 작업을 진행한다BigQuery에서 작업시 사용되는 Compute 리소스는 Slot이라는 단위로 할당되어 사용되며,
Slot은 정기적으로 예약 혹은 실시간 할당 하여 사용할 수 있다BigQuery에서는 컴퓨팅 레이어와 스토리지 레이어를 분리하여 각 레이어가
다른 레이어의 성능 또는 가용성에 영향을 미치지 않고 리소스를 동적으로 할당할 수 있다
기존의 데이터베이스 단점
기존의 데이터베이스는 일반적으로 읽기/쓰기 작업 및 분석 작업을 위한 리소스 공유하는데
이는 리소스 충돌을 야귀할 수도 있고, 또한 스토리지에서 데이터를 읽거나 쓰는 동안
쿼리 속도가 느려질 수 있다공유 리소스 풀은 권한 할당 또는 취소와 같은 데이터베이스 관리 태스크에
리소스가 필요할 때 부담이 증가한다
BigQuery 장점
분리 원칙을 통해 다운타임이나 시스템 성능에 미치는 부정적인 영향없이
스토리 및 컴퓨팅 개선사항을 독립적으로 배포가능
BigQuery 인터페이스
Big Query를 사용하면 이렇게 데이터를 쉽게 분석할 수 있다
Big Query는SELECT만 가능하다
데이터 분석이 목적이지, 데이터 관리가 목적이 아니다
그래서 다른 SQL문은 쓰지 않는다
그래서SELECT을 주로 쓴다 (그것만 알면 된다)
Big Query는 데이터 분석 플랫폼으로 사용해야지 관리목적으로 사용하면 비효율적이다
BigQuery 메뉴 -> BigQuery studio 선택 -> Dataset set 생성 -> Table 생성
- 분석을 수행할 대상 Table에 대해 console상 메뉴를 통하여 확인
- SQL을 통한 분석
SQL
SELECT: 출력하고 싶은 거 적어
FROM: 어디서 가져와?
WHERE: 조건 지정 + AND, OR
ORDER BY: 순서를 지정할 때 사용한다 + DESC
그런데 Big Query에서는 INSERT나 UPDATE를 사용할 수가 없다
그렇기에 NULL 값이 있어도 없애거나 대체할 수가 없다
그래서 Big Query에 넣기전에 전처리를 해주거나 아니면 NULL 값을 제외하는 조건을 걸어줘야 한다
집계함수
COUNT: 개수를 세기,AVG: 평균,MAX: 최대값,MIN: 최소값,CORR: 상관계수
데이터 캔버스
데이터 캔버스에서 여러 데이터를 확인 해볼 수 있고,
데이터 분석을 시각화 할 수 있다
BigQuery 구성요소
BigQuery는 서버리스 인프라를 통해 리소스 관리 대신 데이터 자체에 집중할 수 있다
Big Query Storage
BigQuery는 테이블, 행, 열 데이터를 표현하고 데이터 트랜잭션 시맨틱스 완전 지원 (ACID)
트랜잭션: 한 단위의 작업으로 취급되어 모든 작업을 말한다트랜잭션은 완전히 완료되도 하고 전혀 완료되지 않을 수도 있으며,
스토리지 시스템을 한결같은 상태로 둔다
ex) 은행계좌에서 현금을 인출하거나 인출되지 않거나 둘 중의 하나일뿐BigQuery 분석
기술적 및 예측적 분석 사용에는 비즈니스 인텔리전스(BI), 임시 분석, 지리정보 분석, 머신러닝이 포함된다BigQuery 관리
BigQuery는 데이터 및 컴퓨팅 리소스를 중앙에서 관리하고, identity and Access Management(IAM)는 Google Cloud에서 사용되는 엑세스 모델로 이러한 리소스를 보호하도록 도와준다
BigQuery 작동 방식 및 사용
BigQuery 스토리지는 대규모 데이터 세트에 대한 분석 쿼리를 실행하는데 최적화되어 있다
BigQuery 아키텍처 주요 특징 중 하나는 스토리지와 컴퓨팅 분리이다
따라서 BigQuery는 필요에 따라 스토리지와 컴퓨팅을 모두 독립적으로 확장할 수 있다스토리지와 VM이 분리되어 있고, 쿼리가 순차적으로 진행되는 것이 아니라 동시에 한 번에 쿼리를 해주기에 그만큼 처리속도가 빠를수밖에 없다
쿼리를 실행하면 쿼리 엔진이 여러 작업자에 작업을 동시에 분산하여 스토리지의 관련 테이블을 스캔하고 쿼리를 처리한 후 결과 수집BigQuery의 테이블 데이터
BigQuery에서는 테이블 수정이 어렵다 하지만 수정을 하고 싶다면 테이블 클론을 통해 쓰기가 가능한다메타데이터
BigQuery 스토리지에서는 BigQuery 리소스에 대한 메타데이터 저장스토리지 최적화
BigQuery 스토리지를 최적화하면 쿼리 성능을 높이고 비용을 관리할 수 있다.
BigQuery ML (BQML)
BQML을 사용하면 GoogleSQL 쿼리를 사용하여 머신러닝(ML) 모델을 만들고 실행할 수 있다
BigQuery의 SQL 소개
SQL
bq 명령줄 도구 살펴보기
bq 도구로 데이터 로드 및 쿼리
Vertex AI
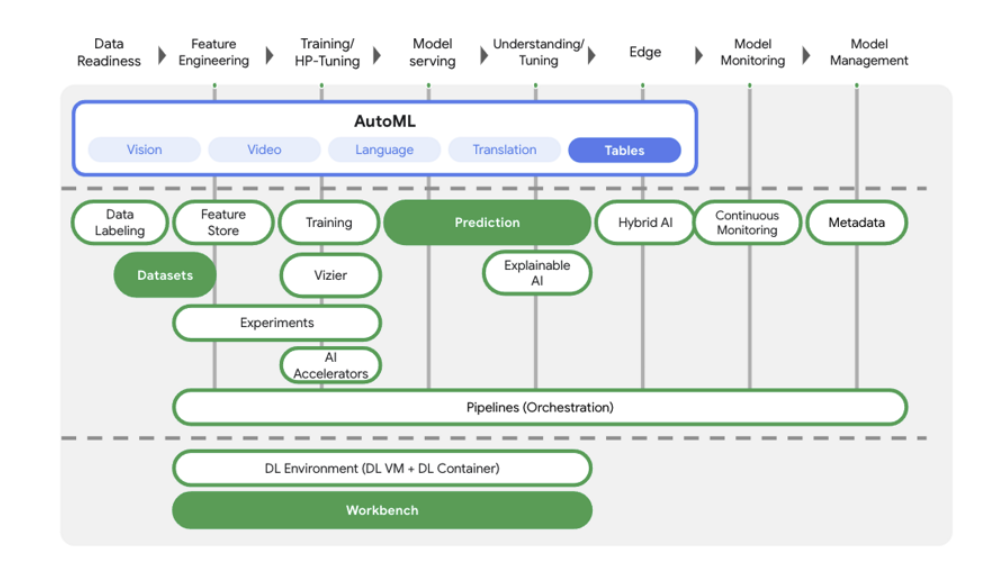
Vertex AI = 머신러닝 플랫폼
모델 학습 및 배포를 위한 여러 옵션을 제공하고 있음
AutoML: 직접 모델 구현을 하지 않아도 자동으로 모델 구현을 해주는 옵션
Model Garden: Vertex AI를 검색, 테스트, 맞춤설정 및 배포하고 오픈소스(OSS)
모델 및 에섯을 선택할 수 있다
Vertex AI 머신러닝(ML) 워크플로
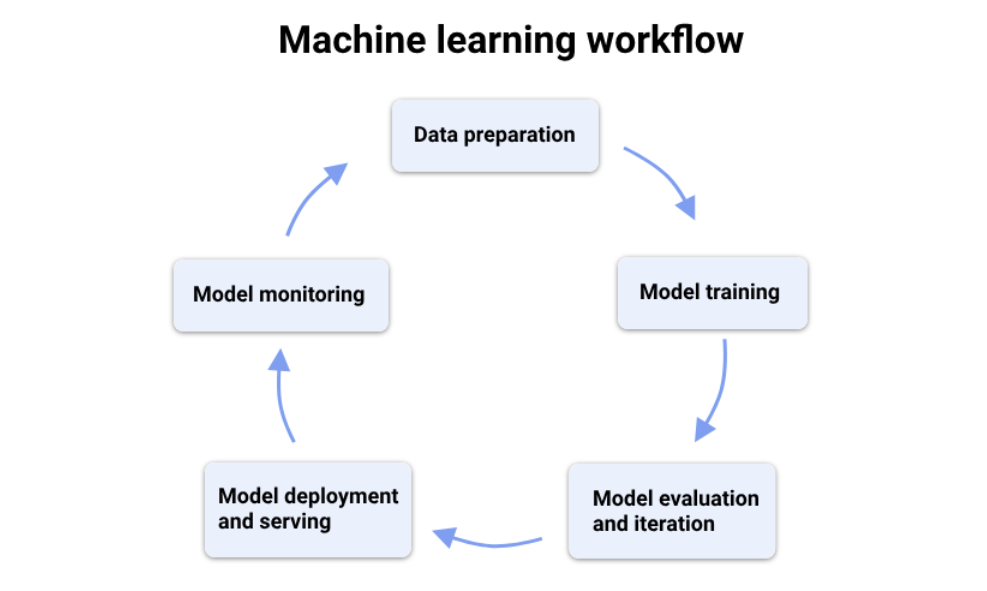
1. 데이터 준비
데이터를 수집하고 데이터를 분석하는 과정이 매우 중요하다
⇒ 데이터 전처리, 데이터 EDA
(주로 Vertex AI Workbench 노트북을 사용하여 데이터를 탐색하고 시각화)
보통은 Cloud Storage와 BigQuery와 통합되어서 더욱 빠른 데이터 엑세스 및 처리
2. 모델 학습
AutoML 사용하거나 직접 커스텀해서 커스텀 모델을 사용할 수도 있다
3. 모델 평가 및 반복
Pipeline으로 과정을 자동화시킬 수 있다
4. 모델 서빙
모델을 배포한다 = 실제 사용자가 모델을 활용할 수 있는 환경을 제공
5. 모델 모니터링
배포된 모델의 성능을 모니터링 한다
Vertex MLOps
- 기계 학습 (ML) 워크플로 및 배포를 자동화하고 단순화하는 일련의 관행
- MLOps는 ML 애플리케이션 개발(Dev)을 ML 시스템 배포 및 운영 (Ops)과 통합하는 ML 문화 및 관행
사실상 DevOps 와 MLOps는 개념은 거의 같지만 DevOps는 좀 더 포괄적인 어플리케이션 개발에서의 개념이고, MLOps는 머신러닝 쪽에 치중되어 있는 느낌이다
MLOps는 ML 수명 주기 자동화에 중점을 둔다
Vertex Interface
vertex AI와 상호작용하는 데 사용할 수 있는 인터페이스
Google Cloud Console,gcloud
Vertex AI SDK를 사용하여 Vertex AI 워크플로를 프로그래밍 방식으로 자동화
클라이언트 라이브러리도 같이 설치되게 됨
개발 환경 및 도구
- AutoML
최소한의 기술적 노력으로 모델을 만들고 학습시킬 수 있다
상대적으로 시간이 적게 걸린다
Hyperparameter를 직접 수정할 수 없다
- 커스텀 학습
목표한 결과에 최적화된 학습 애플리케이션을 만들 수 있다
상대적으로 시간이 많이 걸린다
Hyperparameter를 직접 수정할 수 있다
- BigQuery ML
직접 데이터를 사용하여 모델을 학습시킬 수 있다
Hyperparameter를 직접 수정할 수 있다
Colab Enterprise
기존의 코랩 환경에는 많은 제한이 있었다 (GPU 사용, 사용할 수 있는 노트북 개수등)
또한 코랩은 주어진 환경에서만 작업을 할 수 있었지만 반면
Colab Enterprise는 직접 환경을 설정할 수도 있고, 노트북을 공유하는데도 장점이 있다하지만 Colab Enterprise는 GCP 서비스와 연동하는데 한계가 있다
(물론 GCP SDK를 이용할 수는 있지만 이용하면 아예 다른 서비스를 연동하는 것과 큰 차이점이 없다)
Vertex AI Workbench
Vertex AI Workbench는 워크플로에 사용되는 Jupyter 노트북 기반 개발 환경
Workbench는 BigQuery 및 Cloud Storage 통합을 사용하여 Jupyter 노트북에서 데이터에 엑세스하고 탐색한다
모든 인스턴스 유형에는 JupyterLab이 사전 패키징되며 TensorFlow 및 PyTorch 프레임워크 지원을 포함하는 딥러닝 패키지 제품군이 사전 설치되어 있다
내부적으로 VM을 생성하기 때문에 시간이 약간 걸린다
코랩 엔터프라이즈가 내가 원하는 코랩을 환경하고 작업할 수 있음에 장점은 있지만
스토리지와 BigQuery가 직접으로 연결되어 있지 않다 일종의 작업이 필요하다Workbench의 JupyterLab는 스토리지와 BigQuery와 연결되어 있다
간편하게 만들고 싶다면 위의 사진과 같이 그냥 만들면 된다
하지만 조금 더 구체적 설정하고 싶다면
고급옵션 창으로 들어가서 작업을 하면된다Workbench를 사용하면 BigQuery와 Storage와의 연계가 편하다
만든 것을 cloud storage에 저장할 수 있고, 이를 배포할 수 있다
AutoML
- 최소한의 기술지식과 노력으로 모델을 만들고 학습시킨다
- Vertex AI에서 AutoML을 사용하면 제공한 학습 데이터를 기반으로 코드가 없는 모델을 빌드할 수 있다
- AutoML을 사용하여 빌드할 수 있는 모델 유형은 보유한 데이터 유형에 따라 달라진다
- 학습 데이터를 준비한다
- 데이터 세트를 만든다 - Vertex AI
- 모델 학습 - Vertex AI
- 모델을 평가하고 반복한다 - Vertex AI
- 모델에서 예측을 수행한다 - Vertex AI
- 예측 결과를 해석한다 - Vertex AI
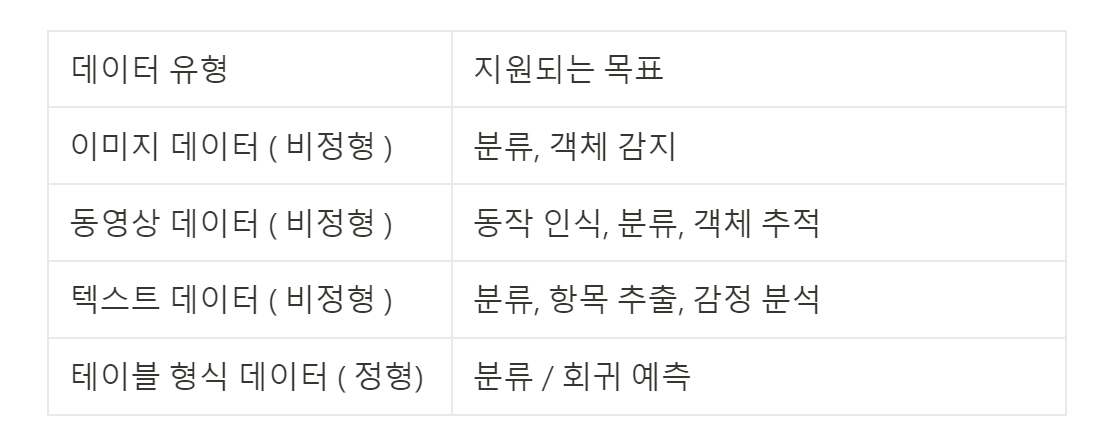
이미지 데이터
- AutoML은 머신러닝을 사용하여 이미지 데이터의 콘텐츠를 분석한다
- AutoML을 사용하여 ML 모델을 학습시켜 이미지 데이터를 분류하거나 이미지 데이터를 분류하거나 이미지 데이터에서 객체탐지
- Vertex AI를 사용하면 이미지 기반 모델에서 온라인 예측 및 일괄 예측을 수행할 수 있다
- 온라인 예측은 모델 엔드포인트에서 수행되는 동기식 요청이다
- 일괄 예측은 비동기식 요청
실습
-
학습 데이터를 준비한다
Google Cloud Storage에 csv 파일을 저장한다
-
데이터 세트를 만든다 - Vertex AI
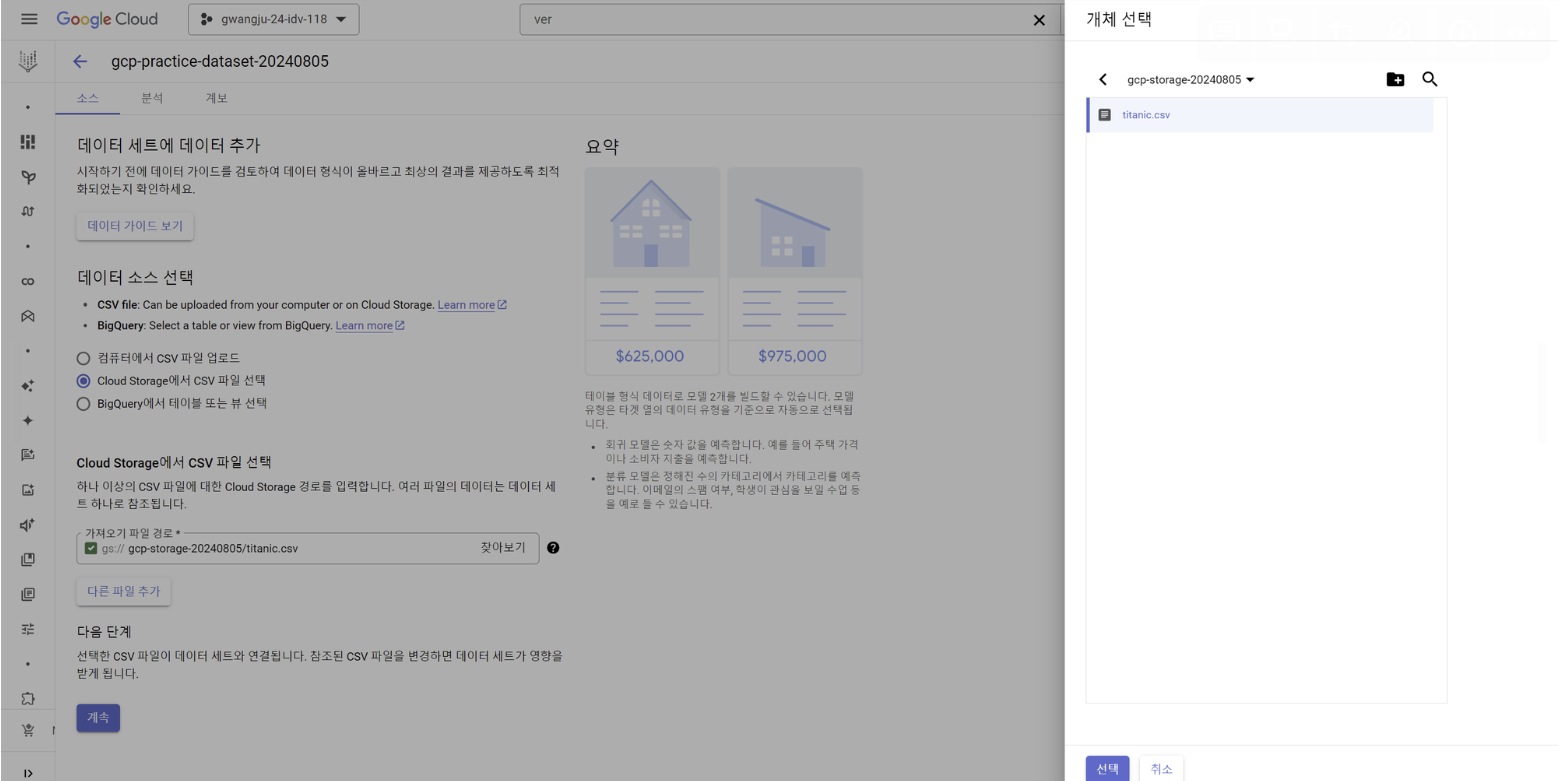
Google Cloud Storage에 저장된 데이터를 바탕으로 데이터 세트를 만든다
- 모델 학습 및 평가 - Vertex AI
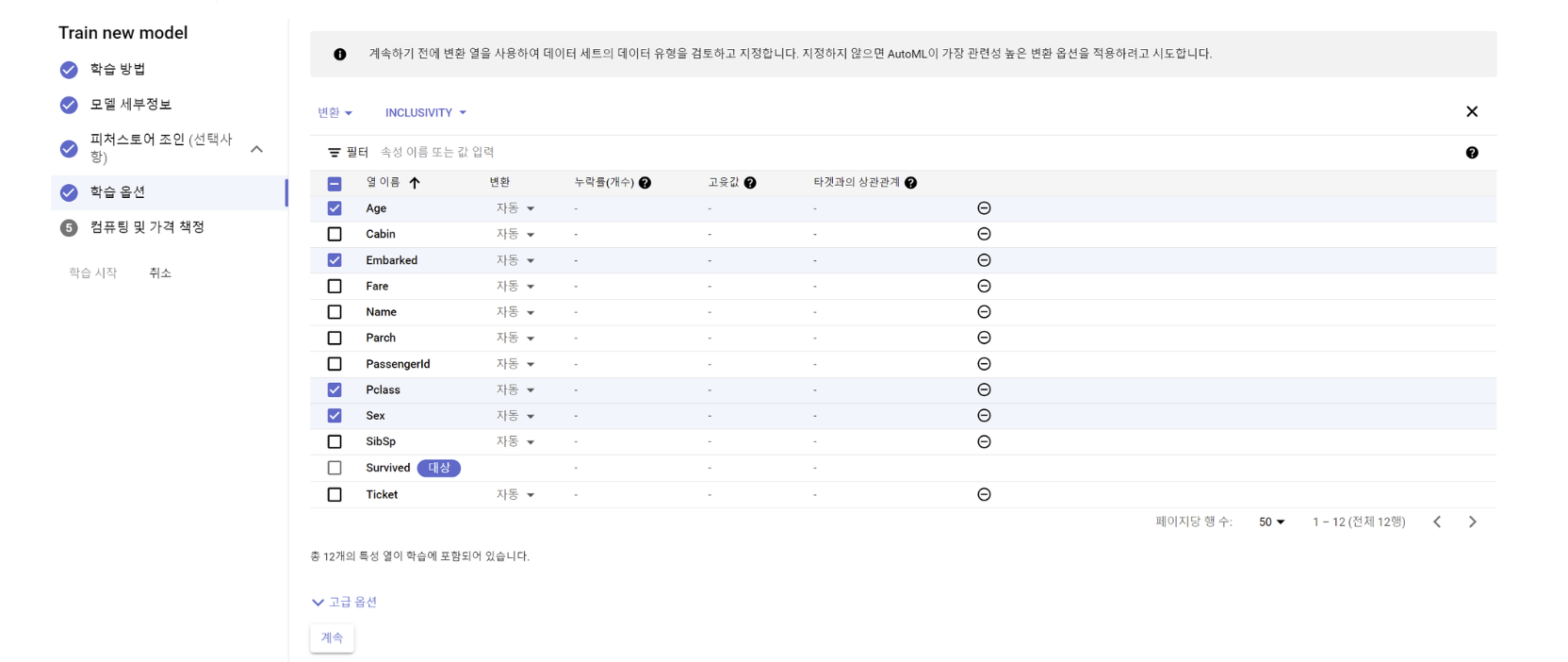
Custom 학습
Vertex AI가 제공하는 AI를 만드는 방법 중에 하나로 자동으로 AI를 생성해주는 Auto ML과 달리
AI를 만드는 작업을 스스로 개입해서 작업을 한다
직접 코드를 입력함으로써 AI 모델을 만든다 (사용자가 원하는 환경에서 AI 모델을 만들 수 있다)
이전의 코랩과 다른점은 환경이 클라우드이라는 것이다
이러한 이유로 발생하는 차이점은 데이터를 클라우드 스토리지에 저장한다는 것이다
클라우드 스토리지에 데이터를 꺼내오고 저장한다는 한다
Vertex AI에서는 AI에 해당하는 코드만 작성한다고 끝나지 않는다
VM는 하드웨어를 가상화하고, Container는 OS를 가상화해준다
실행하는 환경을 제공을 해줘야 한다 → 컨테이너를 만들어줘야 한다
학습하는 코드를 컨테이너 이미지로 바꿔줘야 한다
컨테이너 이미지는 GCP가 제공해주는 서비스 중에 Artifact Registry에 저장한다
기본적으로 컨테이너 이미지는 이렇게 Registry에 저장하고 사용하는 것이 일반적이다
누구나 Registry에 접속만 할 수 있다면 Registry에 있는 어디서나 다운로드 받을 수 있다
AutoML과 다르게 Custom 학습은 컨테이너 생성이 선행되어야 한다
또한 AutoML과 달리 Custom 학습은 자동으로 평가되지 않는다 우리가 직접 평가해야한다
그 뒤에 온라인 예측 방식과 일괄 예측 방식 중에 고민하여 배포하면 된다
Vertex AI Model Registry
AI 모델의 저장소 느낌
이렇게 저장되어 있는 모델을 가져와서 엔드포인트에 할당하여 배포할 수도 있다
- 모델 관리
- 모델의 버전을 추적하고, 효율적으로 구성 및 학습 가능
- 다양한 모델 지원
- 커스텀 모델 및 모든 AutoML 데이터 유형 지원
- BigQuery ML 모델도 지원
- 모델 세부정보 페이지
- 모델을 평가하고 엔드포인트에 배포하며 일괄 예측
- 모델 성능 측정항목을 쉽게 확인
- 워크플로 관리
- 모델을 ModelRegistry로 가져오고, 새 모델 버전을 생성하여 별칭 할당
- 엔드포인트에 모델 배포 및 일괄 예측 실행
- 모델 성능을 주기적으로 평가하여 필요 시 다시 학습
Vertex AI 모델 평가
Vertex AI는 예측 AI 및 생성형 AI 모델 모두에 대한 모델 평가 측정항목 제공한다
모델을 프로덕션에 배포한 후에는 새로운 수신 데이터로 모델을 주기적으로 평가
예측 AI 모델 평가 서비스에서 제공하는 주요 측정항목
정밀도 : 모델이 양성으로 예측한 데이터 중 실제 양성인 데이터의 비율
“높은 정밀도는 모델이 양성으로 예측한 경우 대부분이 실제로 양성임을 의미”재현율 : 재현율은 실제 양성 데이터 중 모델이 올바르게 예측한 비율
“모델이 실제 양성을 얼마나 잘 찾아내는지를 평가”
정밀도↔재현율서로 tradeoff 관계이기에 균형을 맞출 수 있도록 해야한다AuPRC : AuPRC는 정밀도, 재현율 곡선 아래의 면적을 나타내며, 모델의 성능을 평가하는데 사용
높은 AuPRC 값은 모델이 전반적으로 높은 정밀도와 재현율을 유지함을 의미
혼동행렬 : 모델의 예측 결과를 요약하여 보여주는 표로, 실제 값과 예측 값의 교차표를 형성한다
모델 평가 워크플로
Vertex AI에서는 모델 평가를 다양한 방식으로 수행할 수 있다
그래도 일반적인 워크플로가 있는데 다음과 같다
- 모델 학습
AutoML 또는 커스텀 학습을 사용하여 모델을 학습시킨다
- 일괄 예측 작업
모델에서 예측 결과를 생성합니다
- 정답 데이터 준비
실제로 “정확하게 분류된” 데이터, 즉 모델 학습 과정 중 사용된 테스트 데이터 세트를 준비합니다
- 모델 평가 실행
정답 데이터와 예측 결과를 비교하여 정확도를 계산합니다
- 측정항목 분석
평가 작업으로부터 발생하는 측정항목을 분석하여 모델 성능을 개선한다
모델을 평가하려면 학습된 모델, 일괄 예측 출력, 정답 데이터 세트가 있어야 한다
vertex AI에서 모델 평가를 여러 방식으로 실행한다
1) Vertex AI Model Registry를 통해 평가 생성
2) Vertex AI Pipelines에서 파이프라인 구성요소로 사용
Vertex ML 메타데이터
메타데이터는 주로 설명을 위한 데이터로 주로 Key, Value 로 구성한다
머신러닝 실험에서 사용된 매개변수, 아티팩트, 측정항목 등을 추적하여
모델 성능을 분석하고, 디버깅하고, 감시할 수 있는 도구이다
메타데이터 그래프: 아티팩트와 실행을 그래프로 설명하여, 각 요소 간의 관계를 이해할 수 있다
계보 추적: 특정 모델의 학습에 사용된 데이터 세트, 초매개변수, 코드 등을 추적
분석 및 디버깅: 모델 성능 변화를 분석하고, 문제 발생 시 이를 디버깅 할 수 있다메타데이터는 자동으로 생성이 된다, 우리가 일부로 생성하는 것이 아니다
Vertex AI Model Monitoring
모니터링
필요에 따라 또는 정기적으로 모니터링 작업을 실행하여
테이블 형식 모델 품질을 추적할 수 있다
(또한 알림을 설정한 경우 측정항목이 지정된 임곗값을 초과하면 이를 알려준다)
Colab Enterprise : 환경설정없이 AI 모델을 생성할 수 있는 환경 제공
Model Garden : Market Place (사전훈련된 모델을 가져다 쓰는 것)
Vertex AI Studio : 생성형 AI 관련해서 사용할 수 있는 환경
파이프라인 (PipeLines)
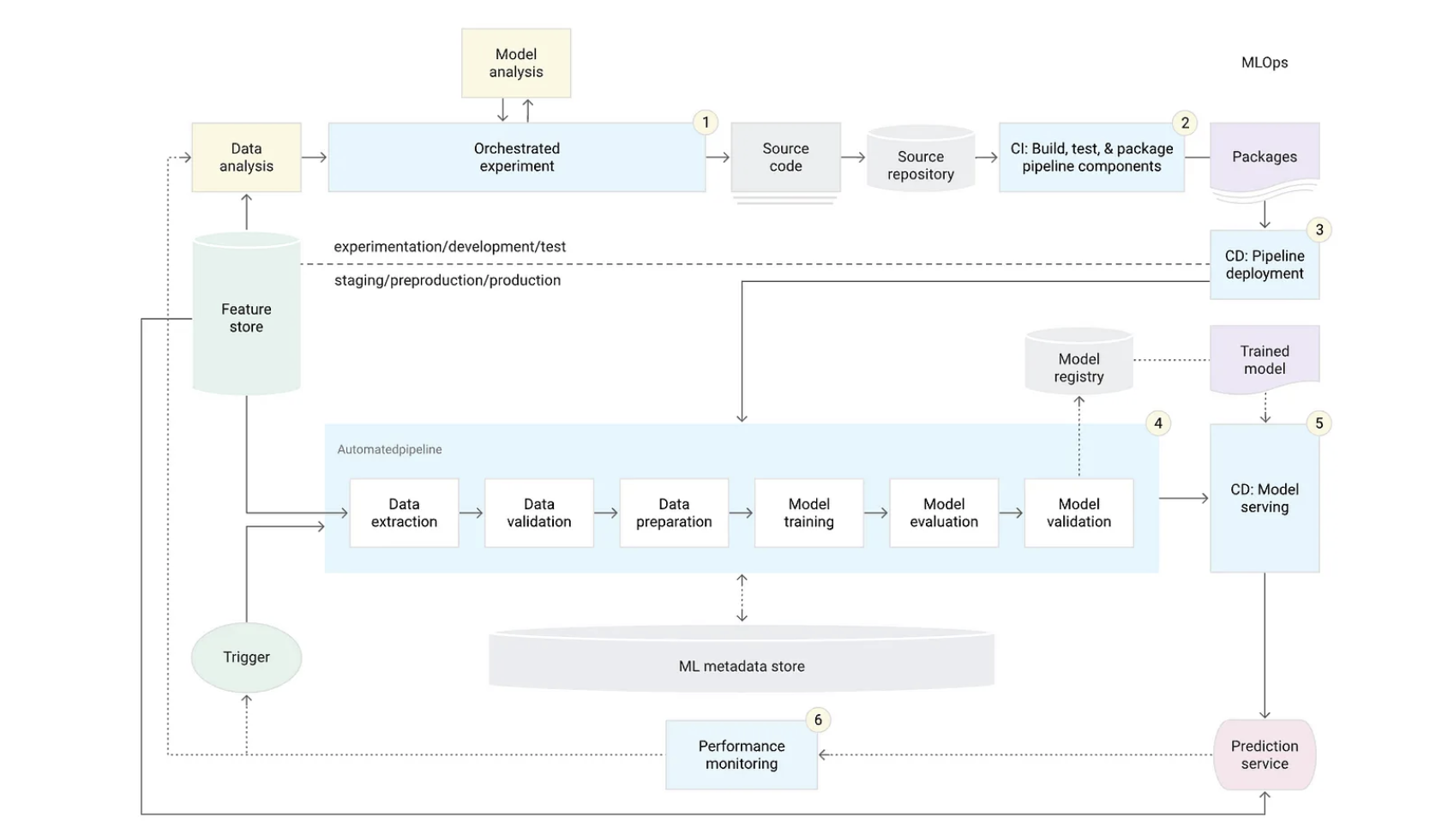
보통 우리는 데이터셋을 준비하고 모델을 설계하고 모델을 훈련시키고 평가하고 배포하는 과정을 거치는데 이러한 일련의 과정을 자동으로 수행하도록 구성하고 싶을 때 사용하는 것이 파이프라인이다
이러한 파이프라인을 구축하는 것이 MLOps의 개념이 들어간다따로 따로 진행하는 것을 하나의 묶어 일괄적으로 진행하도록 만드는 것이 PipeLine이다
서버리스 방식 (완전관리형과 유사, 우리가 별도적인 서버 구성없이 진행할 수 있도록)
파이썬 코드를 통해서 파이프라인을 구성한다
파이프라인을 사용하는 이유는 워크플로를 조정해 서버리스 방식으로 시스템을
자동화, 모니터링, 제어를 할 수 있도록 만드는 것이다반복적인 행동을 최소화하는 것이 파이프라인의 목적이기도 하다
ML 파이프라인
ML 파이프라인 구조는 입력-출력-종속 항목을 사용하여 상호 연결된 컨테이너화된
파이프라인 태스크의 방향성 비순환 그래프(DAG, directed acyclic graph)이다이 그래프는 여러 단계가 서로 연결되어 있는 형태로 각 단계는 다른 단계의 출력 데이터를 입력데이터로 사용한다
Kuboflow Pipelines SDK 또는 TFX SDK를 사용하여 파이프라인을 DAG로 정의하고
중간 표현을 위해 YAML로 컴파일한 후 파이프라인을 실행할 수 있다Kuboflow Pipelines SDK을 사람들이 더 많이 선택한다
파이프라인 태스크
파이프라인 태스크는 파이프라인 구성요소를 인스턴스화 한것이며
ML 워크플로의 각 단계 수행합니다
각 태스크는 특정 입력을 받아서 작업을 수행하고, 그 결과를 출력합니다
