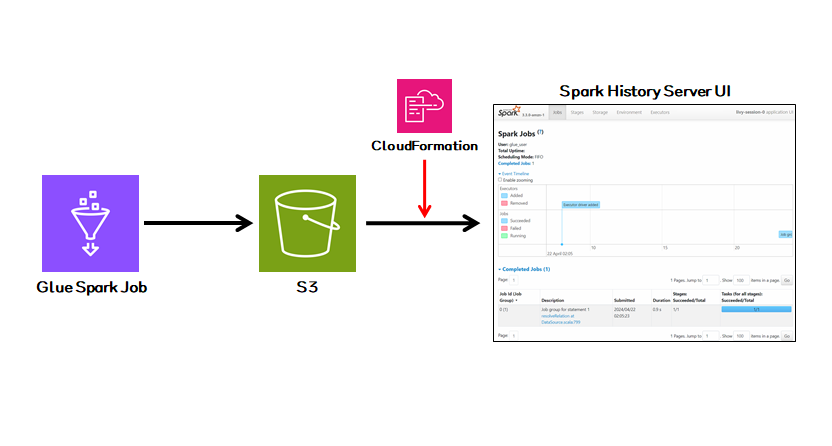
0. INTRO
- AWS Glue를 통해 Serverless하게 Spark Job을 실행할 수 있다.
- EMR 같이 Cluster 환경에서 Spark 작업을 하게되면 Spark History Server UI도 자체적으로 지원을 해주기 때문에 상시적으로 확인이 가능하지만 Glue의 경우에는 따로 Spark UI 관련 리소스를 생성해주어야 한다.
- 이번 글에서는 AWS에서 지원해주는 Spark History Server UI에 대한 CloudFormation을 사용하여 특정 Glue Job에 대한 Spark 로그 및 각종 기록들을 UI에서 확인해보는 내용을 다룰 것이다.
1. Glue Job 생성
- Glue > ETL jobs 탭에 접속하여 샘플 Glue Job을 생성한다.(Script editor Job 권장)

- Job Detail에서 몇 가지를 설정해주어야 한다.
- Name : 작업 이름
- IAM Role : Glue Job Execute하고 특정 S3 버킷에 접근하는 등 스크립트 내용에 따른 AWS 서비스 리소스들 접근 권한이 포함된 Role.(없다면 UI에서 바로 자동 생성이 가능하다.)
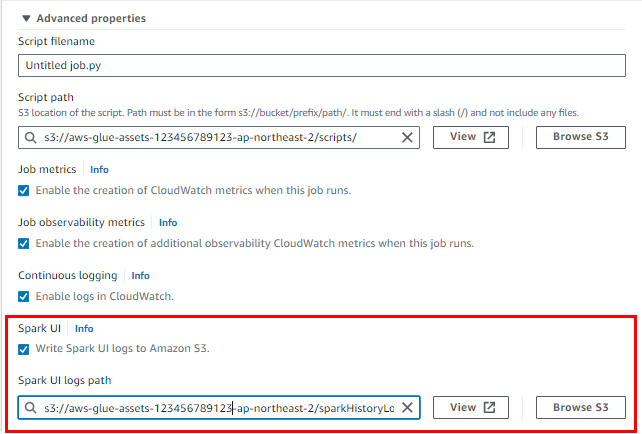
- Advanced properties 항목을 펼쳐준 후 아래와 같이
Spark UI항목 체크를 해주고 Glue Job에 대한 Spark Log가 저장될 경로도Spark UI logs path에 설정해준다. (Default로 두어도 상관없다.)
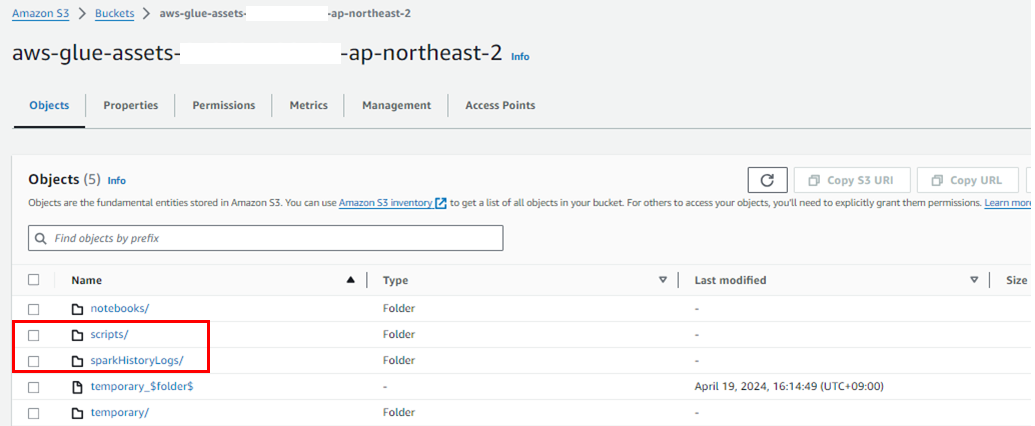
- Glue 작업 관련 설정이 완료되면 우측 상단의
Save를 누르고 최초로Run을 시켜주어 작업 설정에 명시한Spark UI logs path나Script Path가 만들어질 수 있도록 해준다.
2. Spark History Server UI 배포
- Launching the Spark history server 링크에 들어가면 각 리전별 Spark UI 배포 관련 CloudFormation 설정으로 접속할 수가 있다. 난 서울 리전에서 작업을 하기 때문에 해당 리전을 찾아
Launch Stack버튼을 눌러준다. - 그러면 아래와 같이
Create Stack화면이 나오게 된다.
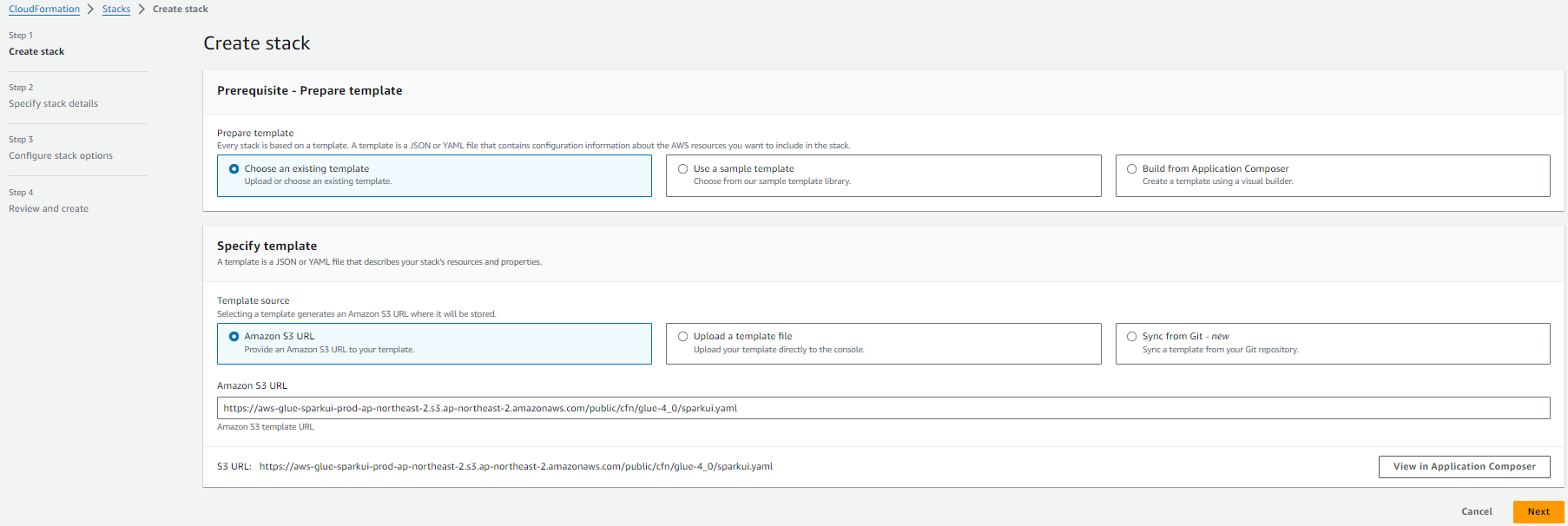
- CloudFormation 배포 관련 설정 중 아래에 나오는 항목들을 채워준 후 배포를 완료해주면 된다.
- (주의)EventLogDir : Glue Job에서 설정했던 Spark UI 경로를 써주면 되는데 반드시
s3a://포맷으로 s3a로 시작할 수 있게 작성해주어야 한다.
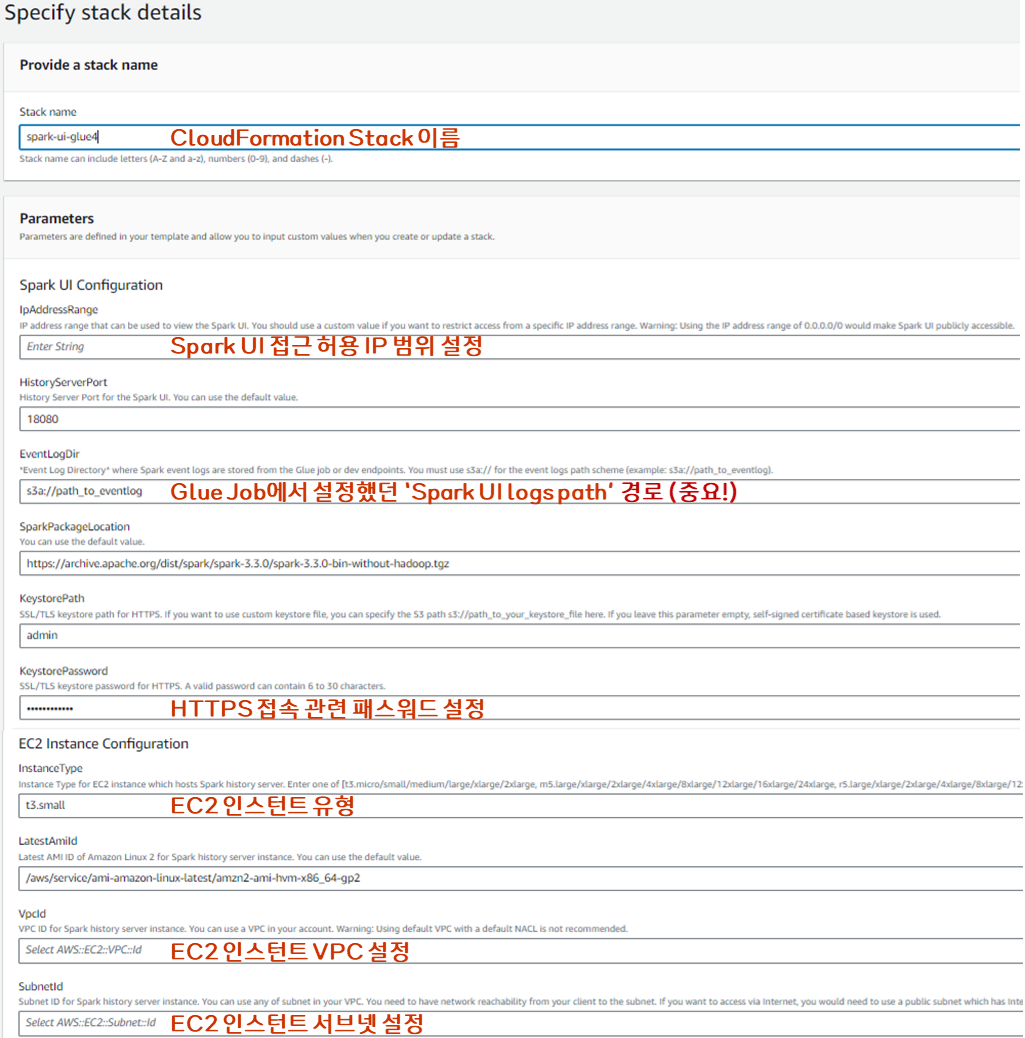
- (주의)EventLogDir : Glue Job에서 설정했던 Spark UI 경로를 써주면 되는데 반드시
3. Spark History Server UI 확인
- Glue Job에 대한 Spark UI는 CloudFormation을 통해 관련 리소스들이 설치된 EC2 인스턴트 한 대가 실행되고 Spark Job 이력이 쌓이는 S3 경로의 데이터를 참조하여 작업 실행 내용을 보여주는 구조로 작동이 된다.
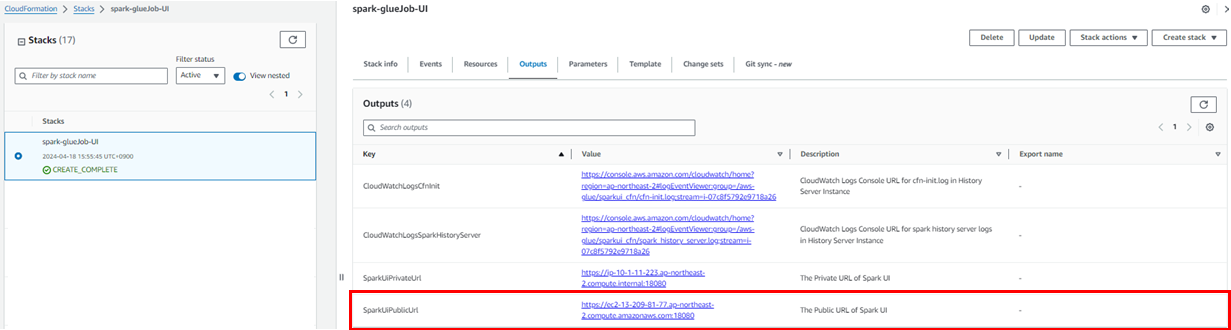
- CloudFormation 배포가 완료되면 해당 Stack의
Outputs탭의SparkUiPublicUrl주소를 통해 Spark UI에 접속이 가능하다.
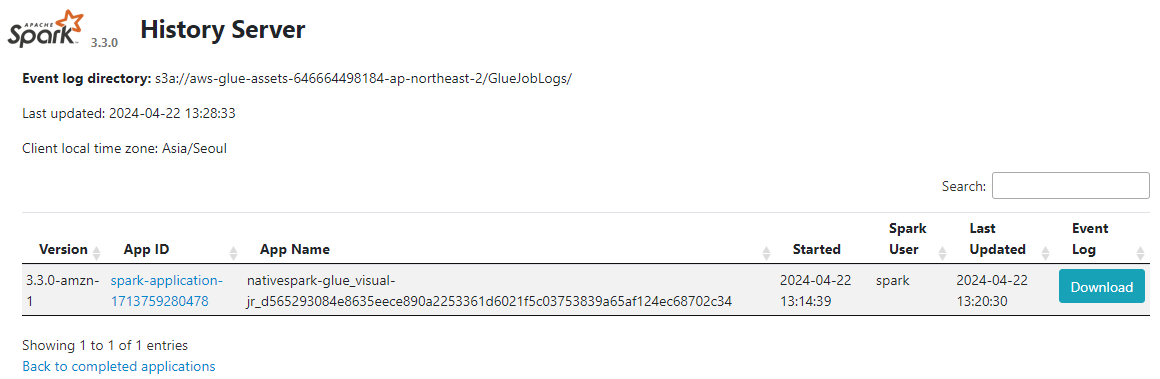
- Spark History Server UI에 접속하여 Glue Job 내역 확인
4. OUTRO
- Glue Job을 비롯하여
EventLogDir아래에 저장되는 Spark 작업에 대해서는 전용 EC2에서 작동되는 Spark UI로 작업 조회가 가능하니 상당히 편리했다. - CloudFormation으로 간단하게 Spark History UI를 띄울 수 있으니 향후 AWS 상에서 Spark 작업시 데이터 특성별 작업 디렉토리 관리를 통해 별도의 UI를 조회해볼 수 있을 것 같아 Spark 작업 조회에 대한 확장성이 늘어난 느낌이 들었다.
5. 참고 자료

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD