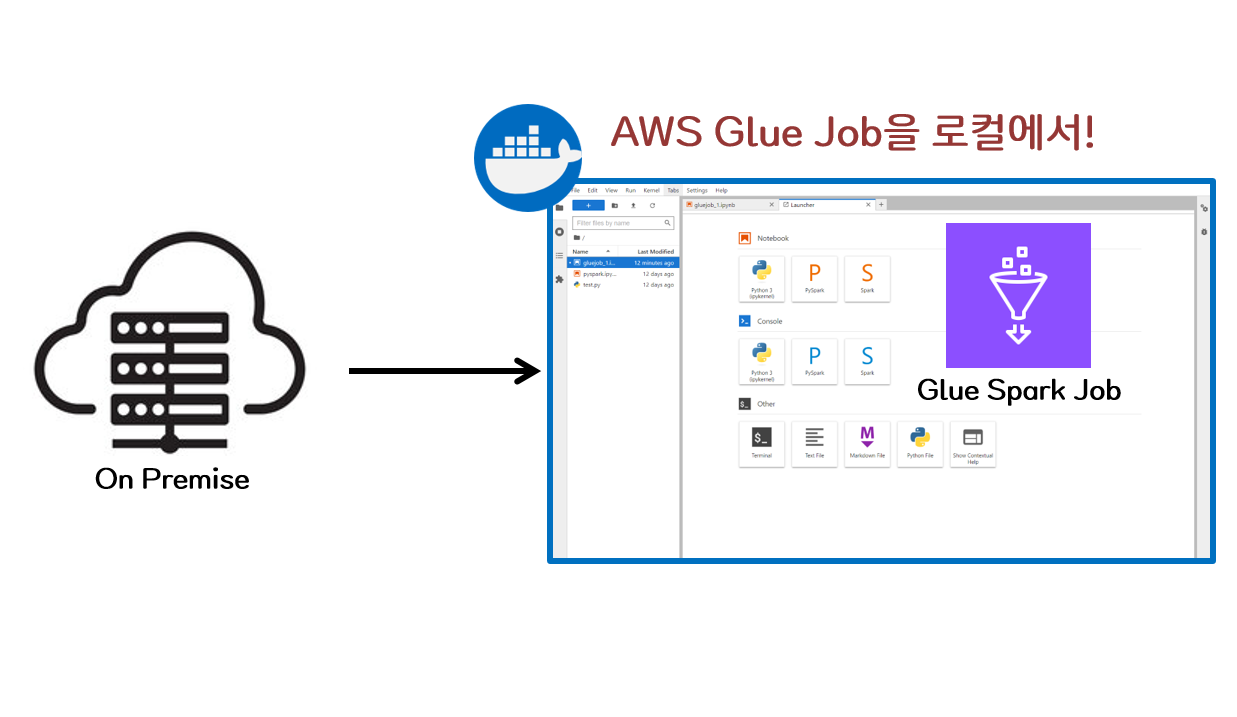
0. INTRO
-
Glue Job으로 Spark 스크립트를 작성하게되면 Glue Job 관련된 다른 import들을 함께 해주어야 한다. 예를 들자면 아래와 같은 것들이다.
from awsglue.transforms import * from awsglue.utils import getResolvedOptions from awsglue.context import GlueContext from awsglue.dynamicframe import DynamicFrame from awsglue.job import Job -
이러한 import들 때문에 Glue Job에 사용할 Script를 개발할 때 AWS 콘솔에서 작업하게되는 경우가 많다. 물론 콘솔에서 작업하게되면 Glue Studio라는 아주 편리한 툴을 사용할 수 있다는 장점이 있지만 코드만을 딱 개발하기 위해서는 기존에 로컬에서 사용하던 IDE의 환경이 더 편리할 수 있다.
-
Glue Job에 대해 이러한 개발의 연속성을 가져가기 위해 Glue Job Docker Image를 사용하여 컨테이너 환경을 구성하게 되면 로컬(On-Premise) 환경에서도 무리 없이 Glue Job 개발이 가능하고 Glue Table에 저장된 데이터들에도 접근이 가능하다.
1. 환경 구성
- Glue에 대한 Docker 컨테이너를 생성하는 과정은 아래 Docs에 상세히 나와있다.
(로컬로 AWS Glue 작업 스크립트 개발 및 테스트) - 아래의 Docker Run 명령어를 통해 Glue 컨테이너를 실행한다.
docker run -d -it \
-v ~/.aws:/home/glue_user/.aws \ > AWS credential 관련 볼륨 매핑
-v $PWD:/home/glue_user/workspace/jupyter_workspace/ \ > 작업 디렉토리 볼륨 매핑
-e AWS_PROFILE=default \ > 사용할 AWS PROFILE 이름
-e DISABLE_SSL=true \ > ssl 연결 비활성화
-p 4040:4040 \ >
-p 18080:18080 \ > spark history server
-p 8998:8998 \ > Apache Livy server
-p 8888:8888 \ > Jupyter Lab
--name glue_jupyter_lab \ > Docker Container 이름
amazon/aws-glue-libs:glue_libs_4.0.0_image_01 \ > Docker Image
/home/glue_user/jupyter/jupyter_start.sh > 작업 환경 시작 관련 shell script- AWS 계정 정보 및 볼륨 등이 제대로 매핑이 되었다면 아래와 같이 컨테이너가 잘 생성된 것을 확인할 수 있다.
> docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
eebef1dda59f amazon/aws-glue-libs:glue_libs_4.0.0_image_01 "bash -l /home/glue_…" 4 minutes ago Up 4 minutes 0.0.0.0:4040->4040/tcp, 0.0.0.0:8998->8998/tcp, 0.0.0.0:18080->18080/tcp, 0.0.0.0:8888->8888/tcp glue_jupyter_lab 2. Glue Job 개발
-
localhost:8888경로로 들어가게되면 Glue Job 개발할 수 있는 Jupyter Lab 환경으로 접속된다.
-
간단히 기존에 저장되어 있는 Glue Table을 불러와서 Spark로 데이터 정제하는 예제를 실행해보았다.
import sys
from pyspark.sql import functions as F
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
dyf = glueContext.create_dynamic_frame.from_catalog(database='default', table_name='fake_dataframe')
df = dyf.toDF()
df.groupby("city").count().orderBy('count', ascending=False).show()
+--------------+-----+
| city|count|
+--------------+-----+
| 서울특별시| 167|
| 울산광역시| 148|
| 대전광역시| 148|
|세종특별자치시| 148|
| 대구광역시| 144|
| 전라북도| 143|
| 광주광역시| 137|
| 강원도| 136|
| 충청남도| 135|
| 전라남도| 134|
| 부산광역시| 133|
| 경기도| 126|
| 충청북도| 125|
|제주특별자치도| 120|
| 경상북도| 119|
| 경상남도| 119|
| 인천광역시| 116|
| null| 1|
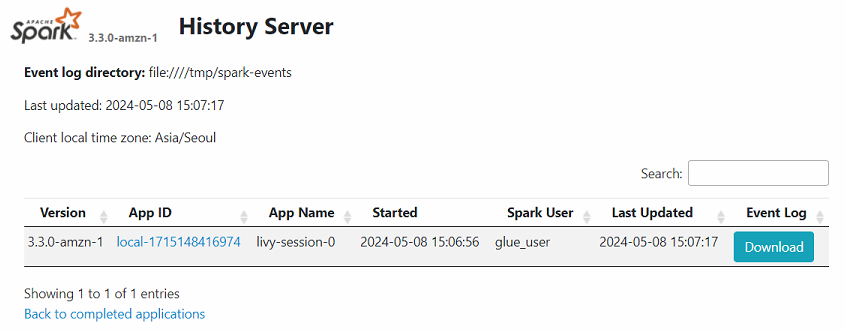
+--------------+-----+- Spark Session이 생성된 후 spark history server인
localhost:18080에 접속해보면 해당 session에 대한 정보가 기록된 것을 확인할 수 있다.
3. OUTRO
- Glue Job에 대한 Docker Container를 올려 Glue Spark Job을 로컬에서 간단히 개발할 수 있는 환경을 구축해보았다.
- 해당 Jupyter Lab 환경에서 Pyspark를 사용할 수 있으니 꼭 Glue Job 목적이 아니어도 유용하게 활용이 가능할 것이라 생각된다.
- 무엇보다 aws credential에 대한 인증이 되어 있기 때문에 Glue Table이나 S3에 저장된 데이터도 바로 읽어올 수 있다. 따라서 규모가 큰 작업이 아니라면 EMR Notebook에서 하는 역할을 많이 대체할 수 있어 금액적으로나 리소스적으로도 효율적인 개발이 가능할 것이라 생각한다.

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD