0.INTRO
- 이번 글에서 다룰 내용
- Cloudwatch 및 S3에 Log가 남도록 Logging 설정
- 변수 없는 Spark Job 실행 후 Log 확인
- 변수 있는 Spark Job 실행 후 Log 확인
- 본격적으로 EMR on EKS 환경에서 Spark Job을 실행하고 해당 작업의 로그까지 확인해보는 과정을 실습해본다.
1. Logging 설정
- 공식 Docs에 따르면 Spark Job에 대한 로깅은 Cloudwatch+S3, Grafana+Prometheus 이렇게 두 가지 조합으로 소개를 하고 있다. 이 중 더 쉽고 기본이 되는 Cloudwatch와 S3 로깅 설정하는 방법을 보도록 하자.(사실 굉장히 간단하다)
-
Cloudwatch
-
aws cli를 통해 설정해준다.
aws logs create-log-group --log-group-name=[로그 그룹 경로] 예시 > aws logs create-log-group --log-group-name=/emr-on-eks/emr-eks-dev-logs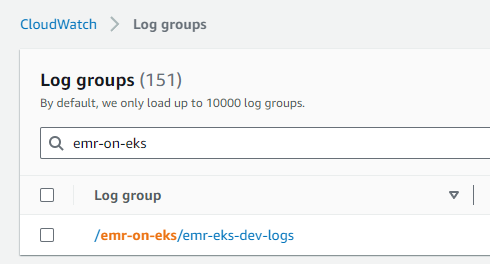
-
-
S3
- 따로 특별히 명령을 통해 설정해주진 않고 아래와 같이 Spark Job이 실행될 json 파일 내에 로그가 저장될 S3 경로를 명시해주기만 하면 된다. Spark Job 실행 섹션에서 더 자세히 알아보자.

- 따로 특별히 명령을 통해 설정해주진 않고 아래와 같이 Spark Job이 실행될 json 파일 내에 로그가 저장될 S3 경로를 명시해주기만 하면 된다. Spark Job 실행 섹션에서 더 자세히 알아보자.
2. Spark Job 실행
- EMR on EKS 환경에서 Spark Job은 'aws emr-containers' CLI 명령을 통해 수행되게 된다.(Docs 설명)
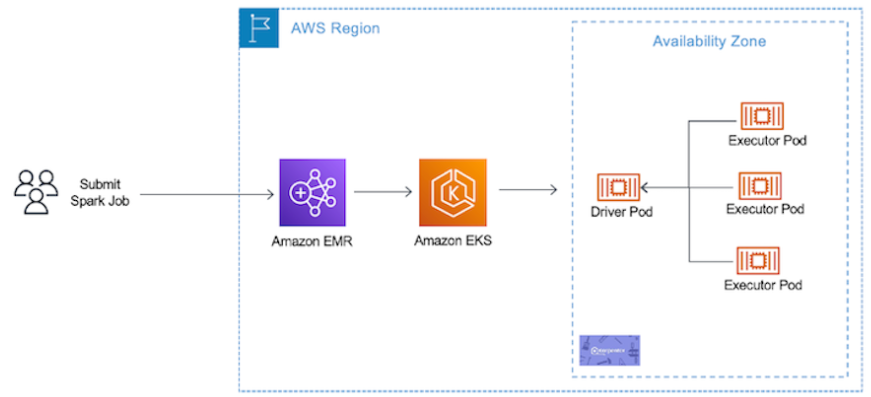
- start-job-run 명령을 Job에 대한 json 파일과 함께 실행하게 되면 아래 아키텍처와 같이 EKS 클러스터에서 Driver와 Executor Pod들이 뜨면서 Spark Job을 수행하며, 작업이 끝나면 pod들은 모두 없어진다.
- 이를 위해서는 기본적으로 spark script와 해당 스크립트가 저장된 S3 경로, Job에 대한 설정 구성을 담은 Json 파일이 필요하다. 하나씩 알아보자.
-
넘겨주는 변수가 없는 Spark Job
-
Spark script (경로 : s3://emr-on-eks-examples/spark-script/job-without-var.py)
- 임의의 spark dataframe을 만들어 'S3://emr-on-eks-examples/result/job-without-var/' 경로에 저장하는 스크립트이다.from pyspark.sql import SparkSession from pyspark import SparkContext from pyspark.sql import functions as F from pyspark.sql import types as T import argparse spark = SparkSession.builder.appName("sample_script").getOrCreate() def main(): df_spark = spark.createDataFrame([ Row(a=1, b=11.2, c='apple'), Row(a=2, b=3.5, c='banana'), Row(a=3, b=7.3, c='tomato'), ]) df_spark.write.mode('overwrite').parquet('s3://emr-on-eks-examples/result/job-without-var/') if __name__ == "__main__": main() -
실행할 Json 파일 (sparkjob-without-var.json)
{ "name": "[Spark Job 이름]", "virtualClusterId": "[VIRTUAL CLUSTER ID]", "executionRoleArn": "[EMR ROLE ARN]", "releaseLabel": "emr-6.2.0-latest", "jobDriver": { "sparkSubmitJobDriver": { "entryPoint": "s3://emr-on-eks-examples/spark-script/job-without-var.py", "sparkSubmitParameters": "--conf spark.executor.instances=1 --conf spark.executor.memory=2G --conf spark.executor.cores=1 --conf spark.driver.cores=1" } }, "configurationOverrides": { "applicationConfiguration": [ { "classification": "spark-defaults", "properties": { "spark.dynamicAllocation.enabled": "false", "spark.kubernetes.executor.deleteOnTermination": "true" } } ], "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "[로그 그룹 경로]", "logStreamNamePrefix": "sample" }, "s3MonitoringConfiguration": { "logUri": "[로그 저장될 S3 버킷 경로]" } } } }
- JSON 파일의 인자들 중 'VIRTUAL CLUSTER ID'와 'EMR ROLE ARN'은 아래 명령으로 알 수 있다.
VIRTUAL CLUSTER ID -> $(aws emr-containers list-virtual-clusters --query "virtualClusters[?state=='RUNNING'].id" --output text) EMR ROLE ARN -> $(aws iam get-role --role-name EMRContainers-JobExecutionRole --query Role.Arn --output text) - 수정 필요한 인자들 설명
- entryPoint : spark script가 있는 S3 경로
- sparkSubmitParameters : Spark Job 실행시 worker 관련 설정
- logGroupName : Cloudwatch 로그 그룹 경로
- logUri : 작업 로그 저장될 S3 경로
- 실행 명령
aws emr-containers start-job-run --cli-input-json file://[sparkjob-without-var.json 파일 경로]
-
-
넘겨주는 변수가 있는 Spark Job
-
Spark script (경로 : s3://emr-on-eks-examples/spark-script/job-with-var.py)
- var1, var2, var3 변수 세 개를 받아 spark dataframe의 'c' 컬럼에 넣어 'S3://emr-on-eks-examples/result/job-with-var/' 경로에 저장하는 스크립트이다.
- sys 라이브러리의 sys.argv 메소드를 이용하여 json 파일로부터 넘어온 변수들을 파싱해와서 main 함수의 알맞은 자리에 넣어준다.
- argparse 라이브러리를 사용하여 넘겨줄 수도 있는데 sys를 쓰는게 약간 더 간단하기 때문에 우선은 sys 라이브러리만 다뤄본다.
from pyspark.sql import SparkSession from pyspark import SparkContext from pyspark.sql import functions as F from pyspark.sql import types as T import sys spark = SparkSession.builder.appName("sample_script").getOrCreate() def main(var1, var2, var3): df_spark = spark.createDataFrame([ Row(a=1, b=11.2, c=var1), Row(a=2, b=3.5, c=var2), Row(a=3, b=7.3, c=var3), ]) df_spark.write.mode('overwrite').parquet('s3://emr-on-eks-examples/result/job-with-var/') if __name__ == "__main__": main(sys.argv[1], sys.argv[2], sys.argv[3]) -
실행할 Json 파일 (sparkjob-with-var.json)
{ "name": "[Spark Job 이름]", "virtualClusterId": "[VIRTUAL CLUSTER ID]", "executionRoleArn": "[EMR ROLE ARN]", "releaseLabel": "emr-6.2.0-latest", "jobDriver": { "sparkSubmitJobDriver": { "entryPoint": "s3://developer-personal-storage/hyunsoo/emr_on_eks/sample-4.py", "entryPointArguments": ["apple", "banana", "tomato"], "sparkSubmitParameters": "--conf spark.executor.instances=1 --conf spark.executor.memory=2G --conf spark.executor.cores=1 --conf spark.driver.cores=1" } }, "configurationOverrides": { "applicationConfiguration": [ { "classification": "spark-defaults", "properties": { "spark.dynamicAllocation.enabled": "false", "spark.kubernetes.executor.deleteOnTermination": "true" } } ], "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "[로그 그룹 경로]", "logStreamNamePrefix": "sample" }, "s3MonitoringConfiguration": { "logUri": "[로그 저장될 S3 버킷 경로]" } } } }
-
수정 필요한 인자들 추가 설명
- entryPointArguments : spark script에 들어갈 변수들을 순서대로 list 형태로 써준다.
(위에 list 기준으로 sys.argv[1] = "apple", sys.argv[2] = "banana", sys.argv[3] = "toamto"'
sys.argv[0]은 스크립트의 temp 경로이므로 변수들은 1번 인덱스부터 매핑된다.)
- entryPointArguments : spark script에 들어갈 변수들을 순서대로 list 형태로 써준다.
-
실행 명령
aws emr-containers start-job-run --cli-input-json file://[sparkjob-with-var.json 파일 경로]
-
3. Job 실행 후 확인
-
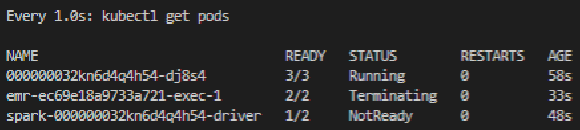
명령을 통해 작업을 실행하게 되면 아래와 같이 EKS 클러스터에 Pod들이 차례대로 떴다가 종료되었다 하면서 작업이 수행되며 Virtual Cluster에서 작업 완료 여부 확인이 가능하다.
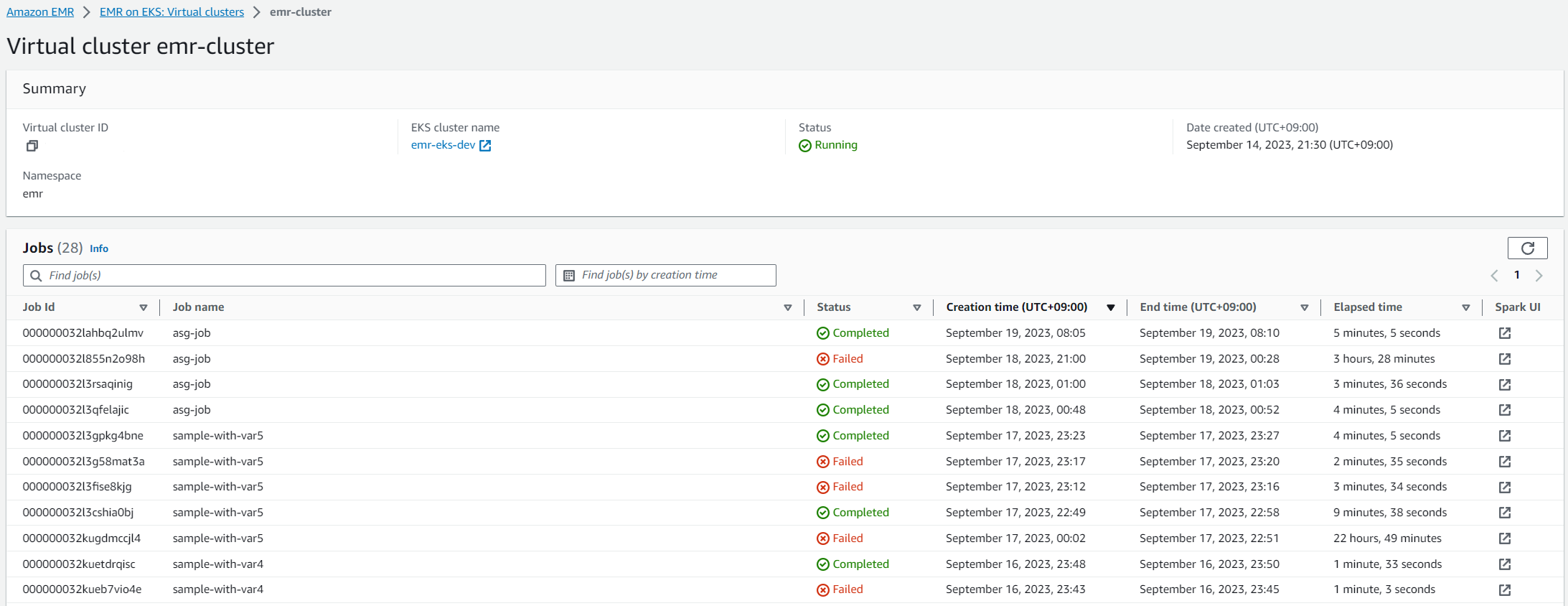
-
작업이 성공적으로 Completed 되었다면 스크립트에서 지정한 저장 경로에 dataframe이 저장되어 있는 것을 확인 할 수 있다.
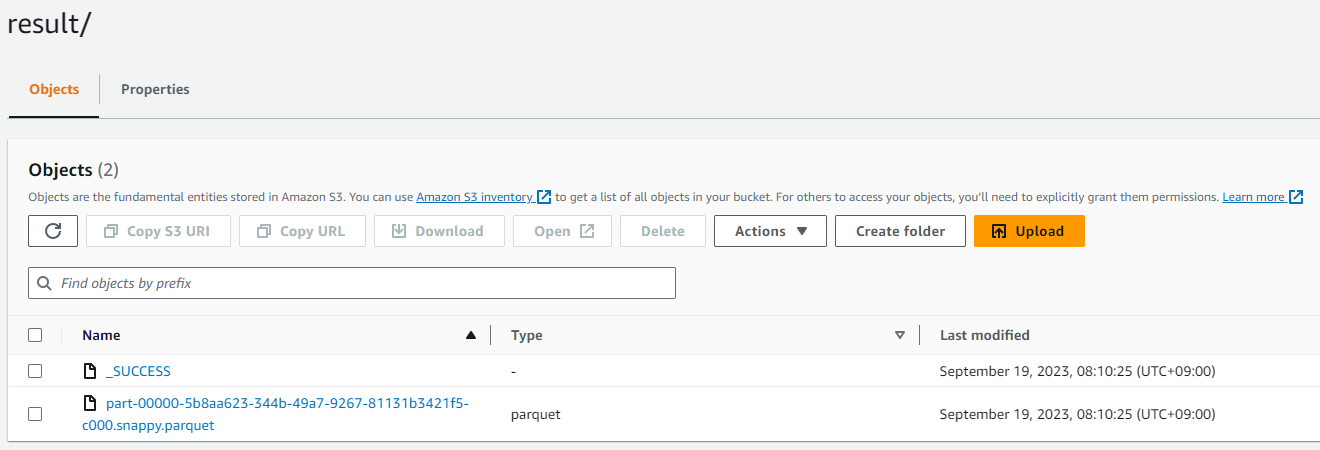
-
Cloudwatch의 Log Group 및 S3 경로에도 해당 작업에 대한 로그가 잘 적재된 것을 확인할 수 있다.
- Cloudwatch
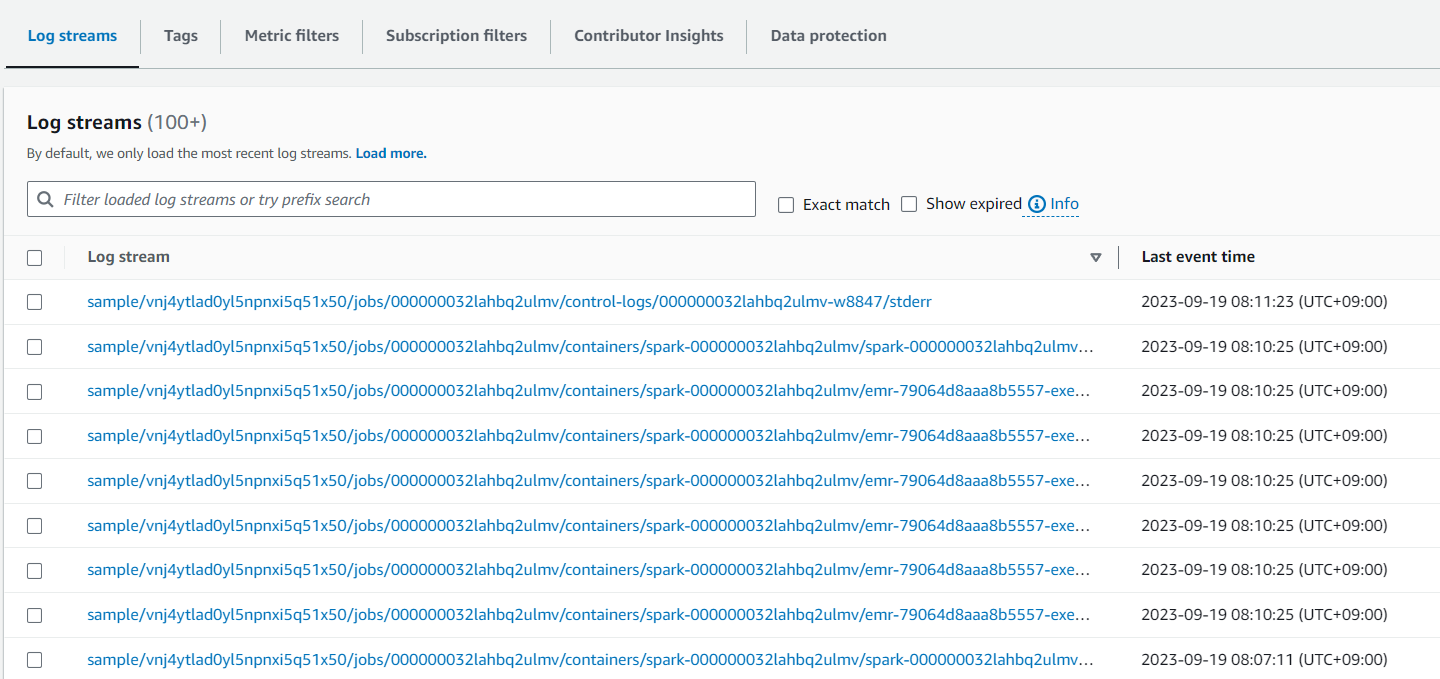
- S3
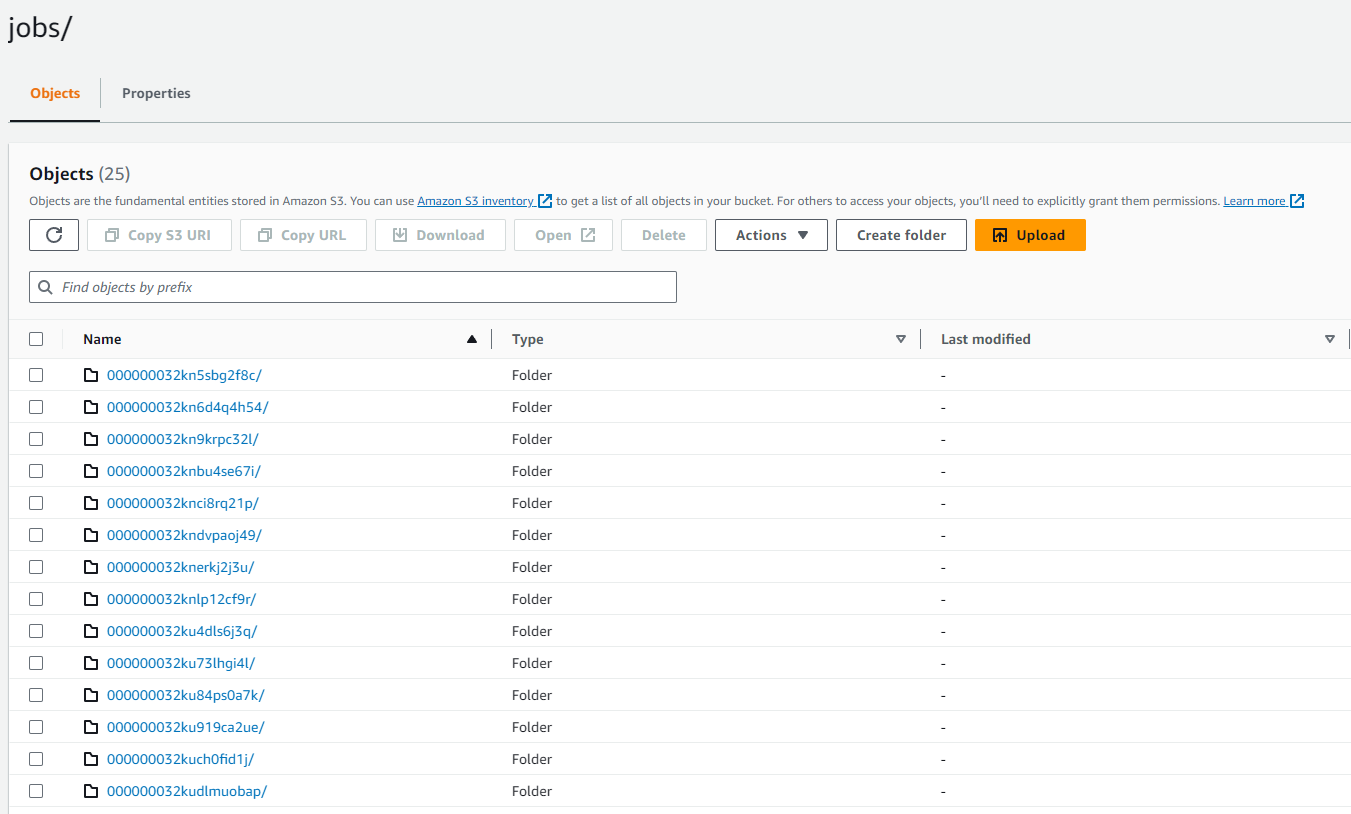
- Cloudwatch
3. OUTRO
- Spark Job에 대한 Cloudwatch 로그 설정과 EKS 클러스터에 spark job을 던져 수행하는 과정까지 다뤄보았다.
- 로깅의 경우 작업이 명시된 JSON 파일내에 로깅 경로만 추가해주면 손쉽게 해당 작업에 대한 로그를 저장할 수 있기 때문에 독립적인 EMR 클러스터 상에서 수행되는 Job에 대한 로깅 설정에 비해 훨씬 쉽고 간단하다.
- 다음 글에서는 실행될 Job에 대해 Dynamic하게 자원 할당이 가능하도록 Cluster Auto Scaler 설정 및 Job 수행시 추가해줘야 할 인자들에 대해서 다뤄볼 것이다.
