0. INTRO
- 이번 글에서 다룰 내용
- EMR Virtual Cluster 생성
- EKS Node Group 추가 (On Demand / Spot)
- 위의 과정들을 모두 마치고 나면 EMR 가상 클러스터를 생성하고 해당 클러스터에서 Spark Job 실행을 위한 EKS Node Group 추가까지 완료되어 EMR on EKS 환경에서 작업을 실행할 수 있는 환경 구성이 끝나게 된다.
1. EMR Virtual Cluster 생성
-
EMR의 가상 클러스터는 Amazon EMR이 등록된 쿠버네티스 네임스페이스로 EMR 클러스터의 개념적인 단위이다. 따라서 목적에 따라 분리하여 Job을 실행하기 용이하여 관리가 편해지는 장점이 있다.
aws emr-containers create-virtual-cluster \ --name emr-cluster \ --container-provider '{ "id": "[EKS Cluster 이름]", "type": "EKS", "info": { "eksInfo": { "namespace": "[namespace 이름]" } } }' -
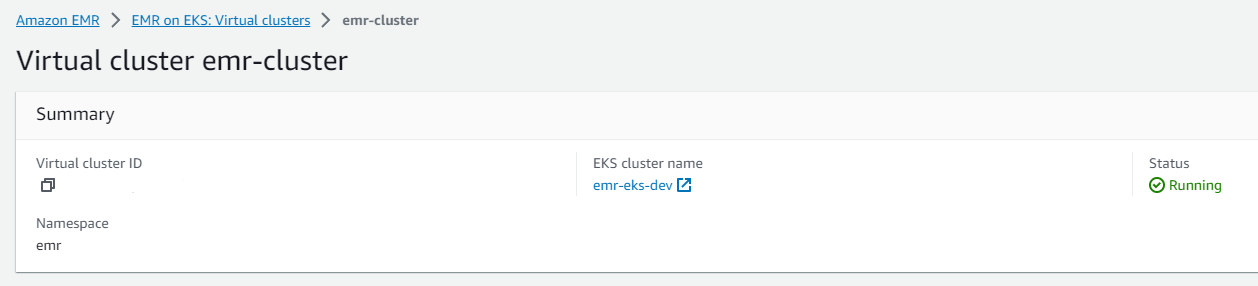
위 명령을 치면 아래와 같이 EMR Virtual Cluster가 생성된다.
2. EKS Node Group 추가
-
EKS가 만들어질 때 기본적으로 Node Group 하나가 생성되지만 해당 Node에는 Kubernetes Cluster를 구성하기 위한 기본적인 pod들이 떠있기 때문에 Virtual Cluster에서 실행되는 spark 작업을 수행하기에는 리소스가 부족할 수 있다. 따라서 추가적인 Node Group을 따로 생성하여 작업 처리를 원활히 할 수 있도록 한다.
-
기본적으로는 On-Demand 타입으로 생성이 되지만 간헐적인 작업이나 요금 절약을 위해서는 SPOT 타입의 인스턴스를 Node Group에 추가하는 것도 좋은 방법이다.
-
YAML 포맷을 만들어 Node Group을 추가해준다.
- On-Demand
-
addnodegroup.yaml
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: [EKS Cluster 이름] region: [Cluster Region] managedNodeGroups: - name: [Node Group 이름] labels: { key: value } minSize: 1 desiredCapacity: 2 maxSize: 3 privateNetworking: true instanceType: m5.large ssh: enableSsm: true availabilityZones: ["ap-northeast-2a", "ap-northeast-2b", "ap-northeast-2c"]
- SPOT
-
addnodegroup-spot.yaml
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: [EKS Cluster 이름] region: [Cluster Region] managedNodeGroups: - name: [Node Group 이름] labels: { key: value } minSize: 1 desiredCapacity: 2 maxSize: 3 privateNetworking: true instanceType: m5.large spot: true ssh: enableSsm: true availabilityZones: ["ap-northeast-2a", "ap-northeast-2b", "ap-northeast-2c"]eksctl create nodegroup --config-file=[addnodegroup.yaml 파일 경로]
-
위의 create nodegroup 명령을 치면 작성한 YAML 파일 내용에 맞는 Cloudformation Stack이 생성, 작동되어 약 2-3분 후에 새로운 Node Group이 만들어지게된다. 아래의 명령을 통해 확인해보면 현재 EKS 클러스터의 Node 총 개수와 각각의 타입까지 알 수 있다.
kubectl get nodes --label-columns=eks.amazonaws.com/capacityType

3. OUTRO
- Spark Job 실행의 바탕이 되는 EMR 가상 클러스터 생성과 Job이 실제로 실행될 Node Group 추가를 진행했다. 이젠 정말 해당 가상 클러스터에 작업을 던져 실행해보는 일만 남았다.
- 다음 글에서는 실행될 Job에 대한 Cloudwatch Logging 설정과 샘플 spark job 및 변수가 있는 job을 실행해보는 과정을 다뤄볼 것이다.
