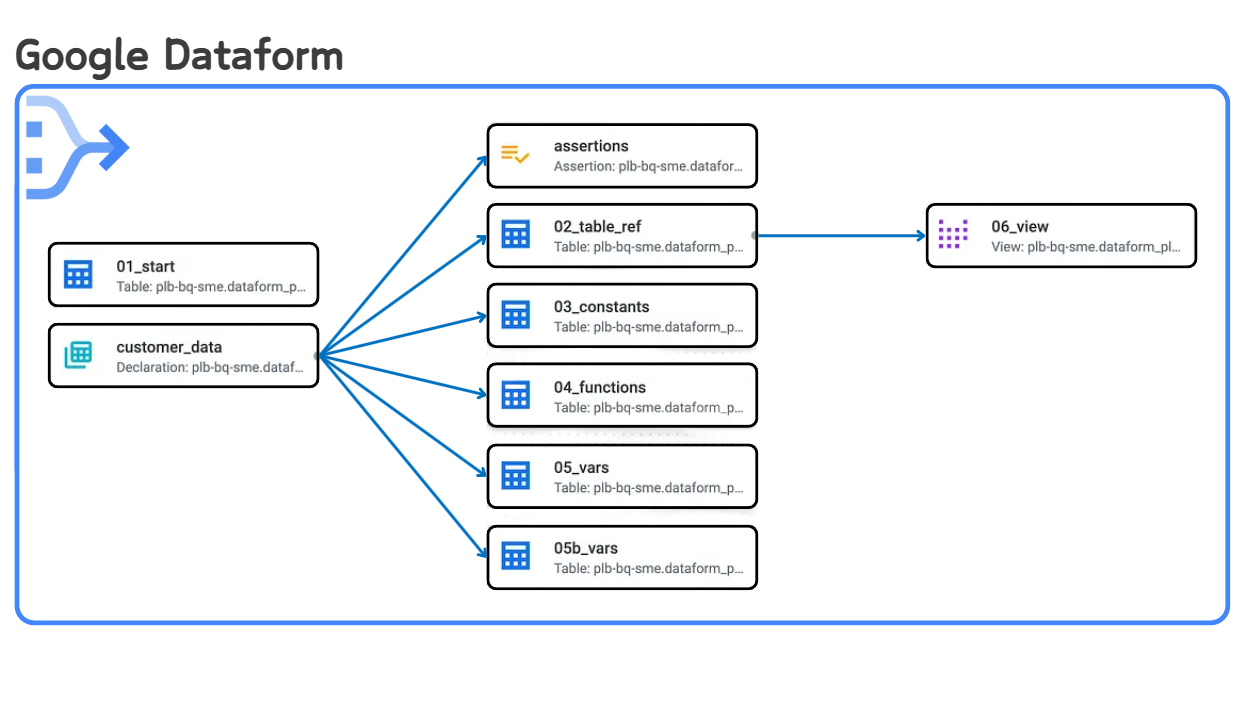
🔹 0. INTRO
- Apache Airflow, dbt, Step Functions, Databricks Workflow 등 데이터 관련 여러 작업들을 자동화하고 관리해주는 다양한 오케스트레이션 도구들이 있습니다. 그 중 dbt와 유사한 방식으로 BigQuery 환경에서 활용할 수 있는 도구가 있습니다. 바로 Dataform입니다.
- Dataform은 Google BigQuery에 저장된 데이터를 변환하고 워크플로우를 관리할 수 있도록 도와주는 도구입니다. BigQuery에 저장된 테이블들을 대상으로 자동화된 데이터 파이프라인 구축이 가능하죠.
- SQL 쿼리문에 config가 더해진 SQLX라는 확장된 SQL 문법과 JavaScript를 활용해 데이터 변환 로직을 정의할 수 있으며, 개발 작업공간을 통해 팀원들이 독립적으로 작업하고 변경 사항을 버전 관리(Git)로 관리할 수 있도록 지원합니다.
- 이번 글에서는 BigQuery 기반의 Dataform을 처음 사용하는 분들을 위해, 기본적인 사용법을 차근차근 소개해보려고 합니다.
🔹 1. 기본 세팅
▪ 1) 저장소 만들기
- Dataform에서 저장소(Repository)는 가장 상위 계층에 위치하며 파이프라인 작업들을 논리적으로 구분하는 단위입니다.
- 작업 공간(Workspace)은 저장소 내에 위치하며 저장소의 작업에 대해 버전 관리나 분기가 필요할 때 이를 구분하는 데 사용됩니다.
- BigQuery Dataform UI에서
+저장소 만들기버튼을 누르고 저장소 이름과 리전(Region)을 선택하면 생성이 가능합니다. quickstart-repository라는 이름으로 저장소를 생성하였습니다.

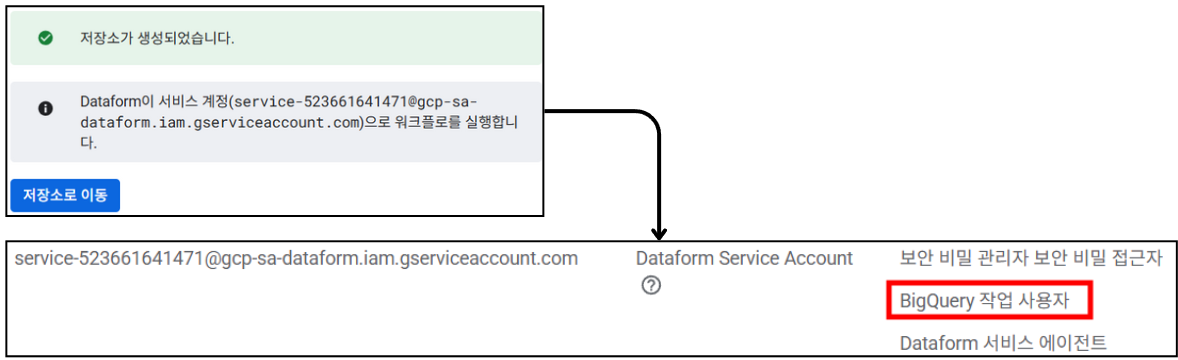
▪ 2) 서비스 계정 권한 부여
- 저장소 생성이 되면 이어서 Dataform 서비스가 사용할 서비스 계정에 대한 권한 확인 작업이 진행됩니다. 만약 Dataform을 최초로 이용하는 것이라면 생성된 서비스 계정에 대해 최소한
roles/bigquery.user역할 추가가 필요합니다.
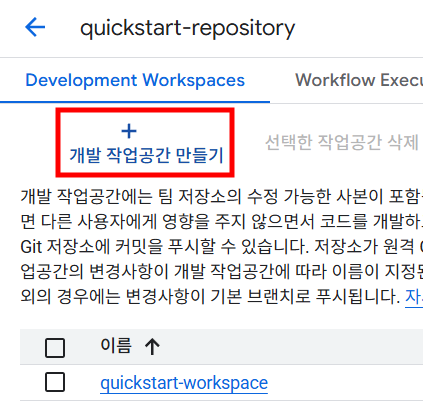
▪ 3) 작업 공간 만들기
- 작업 공간 역시 위에서 만든 저장소에 들어가
+개발 작업공간 만들기버튼을 눌러 생성이 가능합니다. quickstart-workspace라는 이름으로 작업 공간을 생성하였습니다.
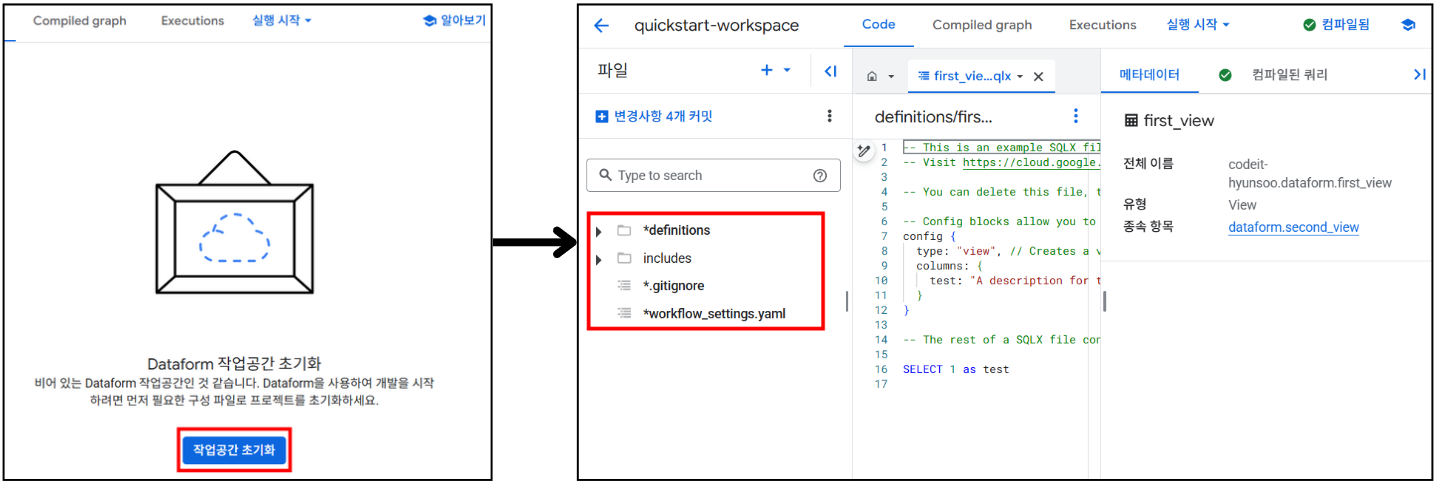
4) 작업 공간 초기화
- 위에서 생성한
quickstart-workspace에 들어가작업공간 초기화버튼을 누르게 되면 Dataform 작업에 필요한 초기 파일들이 생성되게 됩니다. - 초기 세팅 파일/디렉토리 설명
definitions/: Dataform 프로젝트의 SQLX 파일과 JavaScript 파일을 저장하는 디렉토리로, 본격적인 데이터 ETL 파이프라인 코드가 작성되는 디렉토리입니다.includes/: 재사용 가능한 JavaScript 함수나 공통 SQL 로직을 저장하는 디렉토리로, 프로젝트 전반에서 참조되는 파일들이 위치하는 디렉토리입니다.
workflow_settings.yaml: Dataform 워크플로의 실행 설정(예: 스케줄, BigQuery 위치, 기본 스키마 등)을 정의하는 구성 파일입니다.
🔹 2. 단일 테이블 작업 진행
▪ 1) workflow_settings.yaml
- 기본적으로 아래와 같이 5개의 키들이 세팅되어 있고 그 중 중요한 키는 3번째
defaultDataset으로, Dataform에서 작성한.sqlx파일내의 쿼리의 결과물이 빅쿼리의 어떤 Dataset에 저장될지를 명시하는 키입니다.defaultProject: codeit-hyunsoo defaultLocation: asia-northeast3 defaultDataset: dataform defaultAssertionDataset: dataform_assertions dataformCoreVersion: 3.0.0 - workflow_settings.yaml 관련 더 추가적인 내용은 공식 문서에서 확인할 수 있습니다.
▪ 2) .sqlx 파일 구성
.sqlx파일은 상단의config설정 부분과 하단의SQL 쿼리작성 부분으로 나뉩니다.- 🛠 config 설정부
.sqlx파일의 최상단에 위치하며, 중괄호 {} 안에 작성됩니다.- 이 부분은 해당 파일에서 생성하는 테이블, 뷰, 혹은 선언 등에 대한 메타데이터 및 실행 설정을 정의합니다.
- 주요 설정 내용
- 테이블 이름, 타입(view/table/assertion 등) 지정
- 파티션/클러스터링 설정
- 태그, 설명, 라벨 추가
- 의존성 설정(dependencies)
- 외부 쿼리 옵션 지정
workflow_settings.yaml내용 오버라이딩
- 📄 SQL 쿼리 작성부
- config에 정의한 설정을 기반으로 실제로 실행될 SQL 쿼리문을 작성합니다.
▪ 3) source.sqlx 파일 작성
-
컬럼이 2개(
fruit,count)있는 샘플 테이블을 생성하는 쿼리를 작성합니다. -
definitions/디렉토리 아래에source.sqlx파일 생성 후 아래 내용을 작성하면 됩니다. -
아래 파일은 빅쿼리의
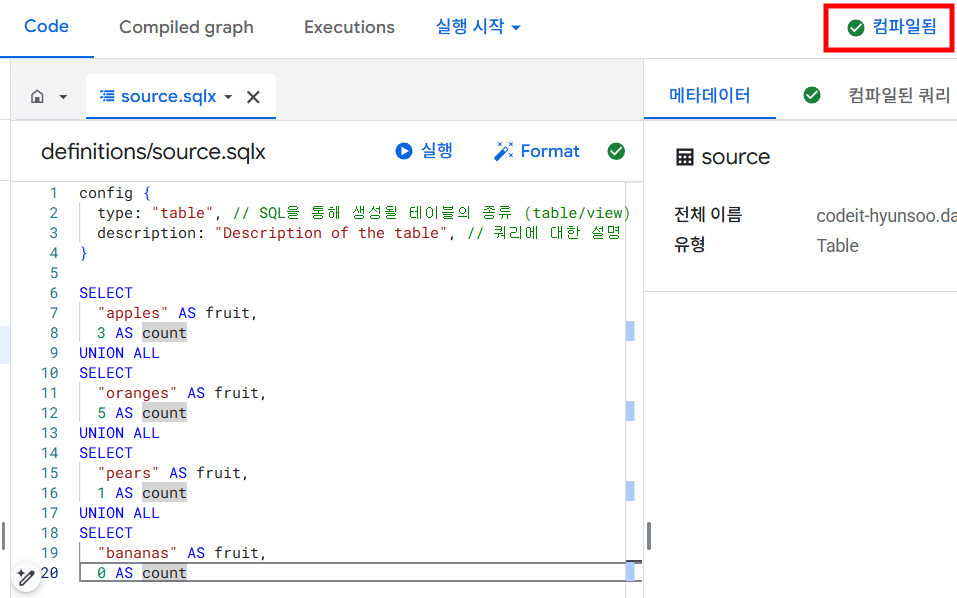
dataform데이터셋에source라는 테이블로 쿼리의 내용을 저장합니다.config상에 별도로 명시가 되어있지 않다면,.sqlx파일의 이름과 동일하게 테이블의 이름이 정해집니다.config { type: "table", // SQL을 통해 생성될 테이블의 종류 (table/view) description: "Description of the table", // 쿼리에 대한 설명 } SELECT "apples" AS fruit, 3 AS count UNION ALL SELECT "oranges" AS fruit, 5 AS count UNION ALL SELECT "pears" AS fruit, 1 AS count UNION ALL SELECT "bananas" AS fruit, 0 AS count
▪ 4) 작업 실행 및 확인
-
쿼리 작성이 완료되면 자동으로 해당
.sqlx파일의 문법을 체크하여 틀린 부분이 없는지 보여줍니다. config나 SQL 문법상 오류가 없다면 아래 사진과 같이 초록색 체크 표시가 나옵니다.
-
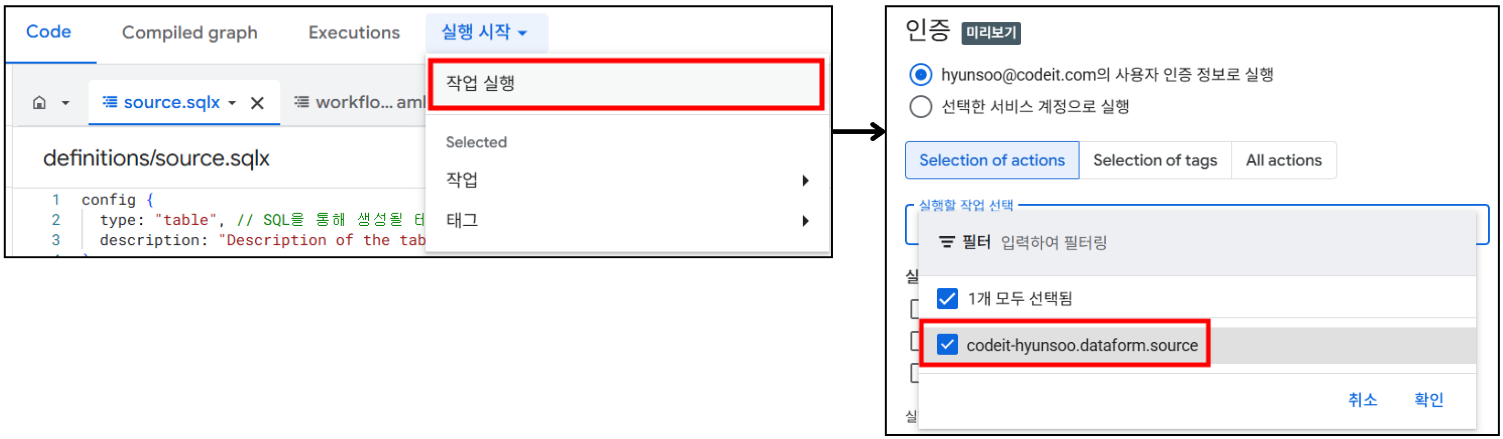
해당 쿼리를 실행하려면
실행 시작 > 작업 실행버튼을 누른 후 실행할 작업을 선택하여 시작할 수 있습니다.
-
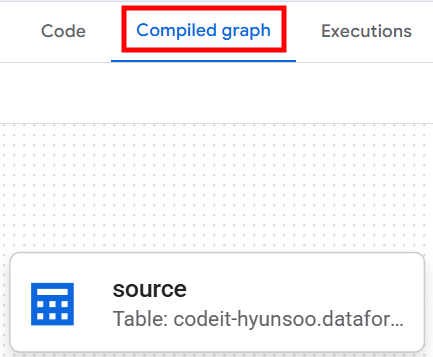
Compiled graph탭으로 가면 작성한.sqlx파일의 워크플로우를 시각적으로 확인할 수 있습니다.
-
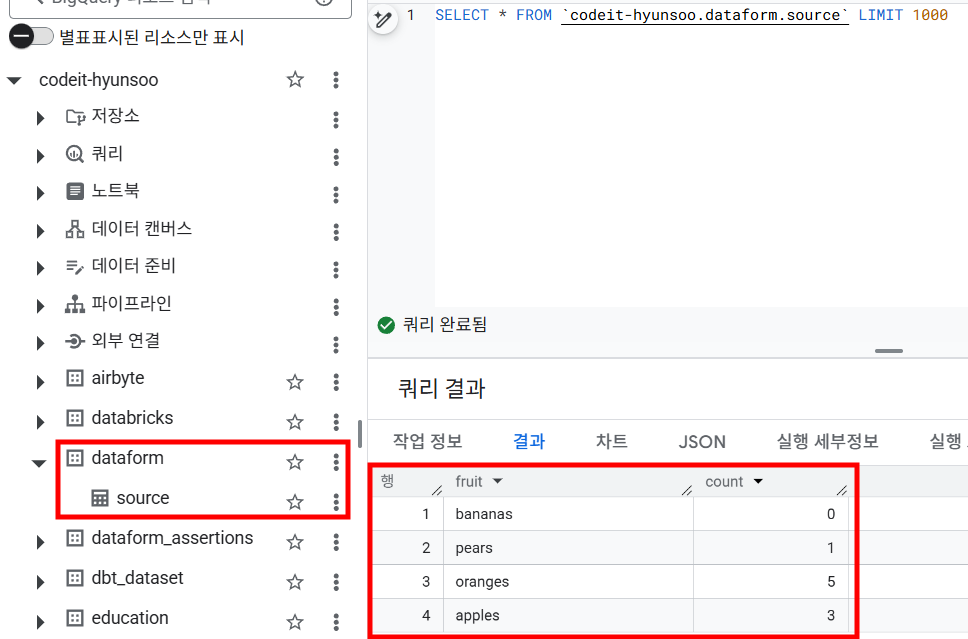
실행이 정상적으로 완료되면 기본 설정과 같이
dataform.source테이블이 생성되어 빅쿼리에서 확인할 수 있습니다.
🔹 3. 여러 테이블 작업 진행
- 이번에는 위에 작성한
source.sqlx파일로 생성된 테이블을 대상으로 집계를 하는aggregation.sqlx파일을 추가로 생성하여 2개의.sqlx파일이 연동되어 작업되는 파이프라인을 구성해볼 것입니다.
▪ 1) aggregation.sqlx 파일 작성
-
source테이블의count컬럼 값을 SUM 하는 쿼리입니다. -
dataform데이터셋에 파일명과 동일한aggregation이라는 이름의 VIEW로 저장되도록 config를 구성하였습니다. -
${ref("source")}코드를 통해 같은 디렉토리 내에서 생성되는 테이블을 참조할 수 있습니다. 참조 정의가 되면 파일의 실행 순서가 자연스럽게 정해집니다.config { type: "view", // SQL을 통해 생성될 테이블의 종류 (table/view) description: "Aggregation of source table", // 쿼리에 대한 설명 } SELECT SUM(count) AS fruit_cnt FROM ${ref("source")} -
Compiled graph탭을 확인하면 작업 순서에 맞게 UI로 표시가 되는 것을 확인할 수 있습니다.
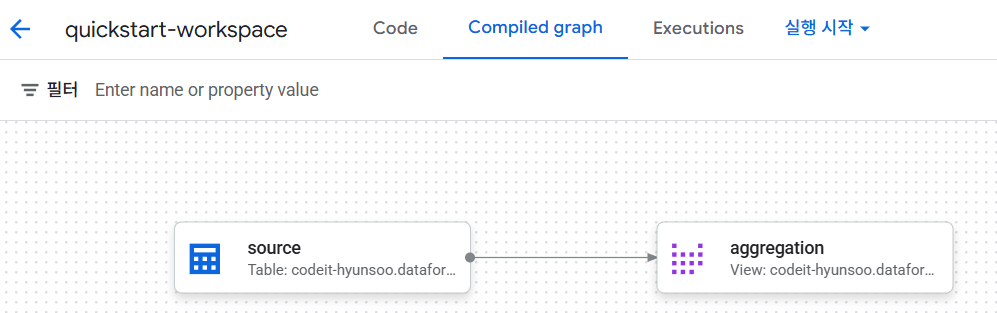
▪ 2) 작업 실행 및 확인
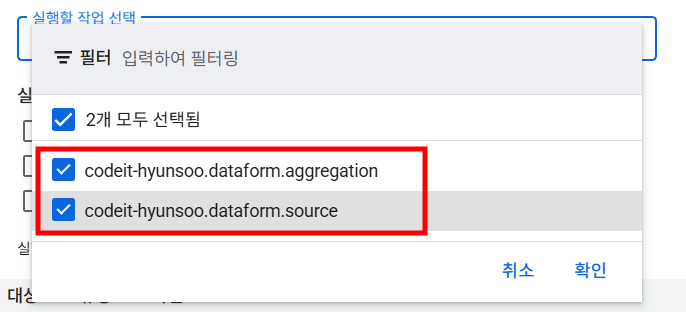
실행 시작 > 작업 실행버튼을 누른 후 실행할 작업(2개)을 선택하여 작업을 실행합니다.
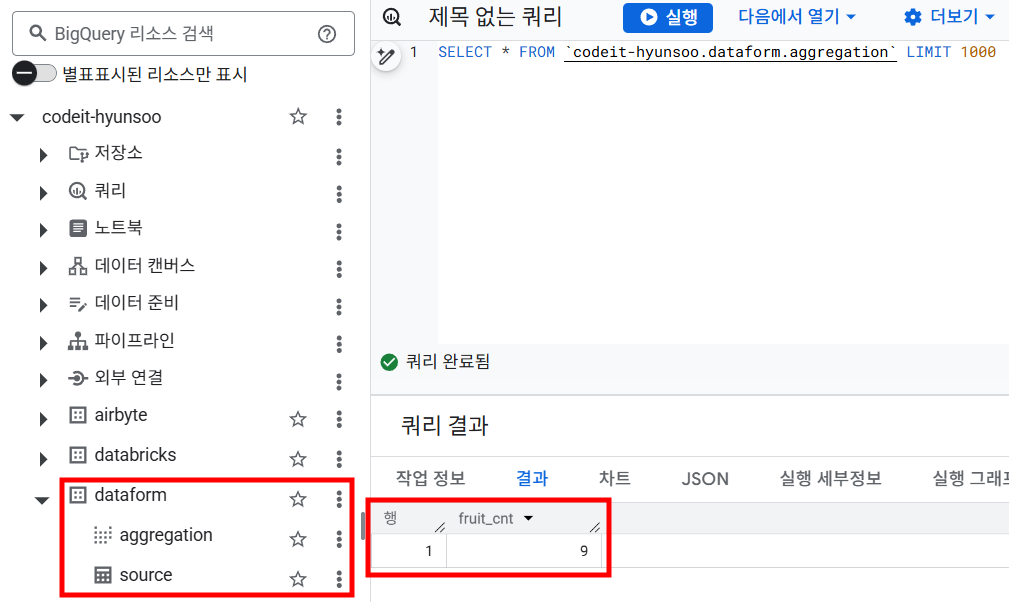
- 실행이 완료되면 BigQuery 스튜디오에서 생성된 테이블을 확인할 수 있습니다.
🔹 4. OUTRO
- 지금까지 Dataform의 기본 개념부터 실제 사용법까지, 간단한 실습을 통해 함께 살펴보았습니다. 처음에는 다소 생소하게 느껴질 수 있지만, 익숙해지면 SQL 기반으로 깔끔하고 체계적인 데이터 파이프라인을 구축할 수 있다는 점에서 매우 매력적인 도구입니다. 특히 dbt를 사용해본 경험이 있다면, Dataform의 구조와 사용 방식에 훨씬 빠르게 익숙해질 수 있을 것입니다.
- Dataform 서비스 자체는 무료이며
.sqlx파일을 통한 빅쿼리 엔진 사용에 대한 비용만 발생합니다. Github와의 호환성, 시각적인 워크플로우 관리 기능 등도 지원되어, BigQuery를 데이터 웨어하우스로 사용 중이라면 충분히 활용해볼 만한 자동화 도구라고 생각됩니다.
