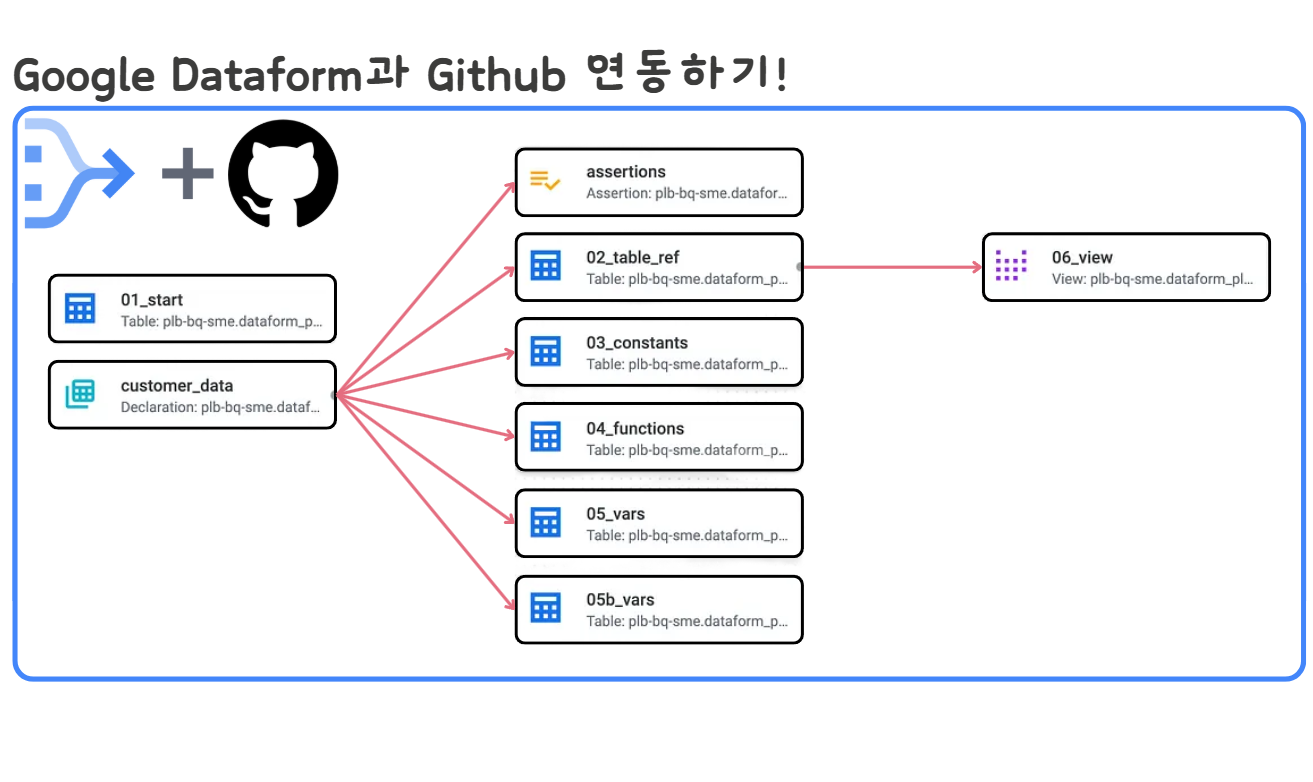
🔹 0. INTRO
- 앞선 글(BigQuery Dataform으로 빅쿼리 데이터 플로우 자동화하기!)에서는 BigQuery에서 제공해주는 Dataform 이라는 서비스에 대해 알아보고 간단한 실습까지 진행해 보았습니다.
빅쿼리 데이터를 기반으로 자동화된 파이프라인을 만들어준다는 것 외에도 Dataform에는 매력적인 기능들이 많이 있는데요, 대표적인 것이 Github Repo와의 연동입니다. - Dataform에 작성한 코드를 Github Repo와 연결하여 UI에서 바로 commit이나 push 작업이 가능하며, 특정 브랜치에 push하는 것도 가능합니다.
- 이번 글에서는 Github Repo와 연동하는 방법에 대해 알아보고,
.sqlx의 문법에 대해 추가적으로 다뤄보도록 하겠습니다.
🔹 1. Github와 연동
🔸 1) Github Repo 생성 및 토큰 발행
-
dataform-practice라는 이름의 깃허브 Repo를 생성합니다.
-
Settings > Developer settings > Personal access tokens > Fine-grained tokens메뉴로 가서 토큰을 발행합니다.

-
토큰 발행시 아래와 같이 설정하고 발행합니다.
-
토큰 이름 : dataform-prac-token
-
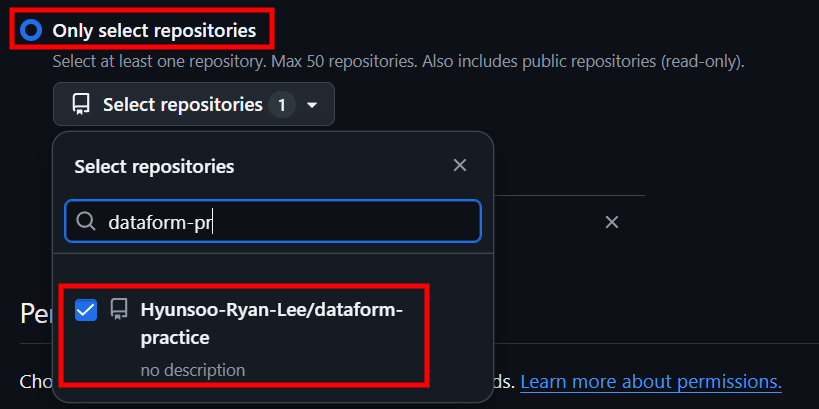
Repository access :
Only select repositories선택 후 위에서 생성한 Repo를 선택합니다.
-
Repository permissions :
Contents선택 후Read and write로 변경

-
-
발행이 완료되면
github_pat_xxxxx와 같은 토큰값을 얻을 수 있습니다.
🔸 2) Secret Manager에 토큰 등록
-
위에서 발행한 토큰을 비밀이나 민감정보를 관리해주는 GCP 서비스인 Secret Manager에 등록해줘야 Dataform에서 github와 연동시 사용이 가능합니다.
-
Secret Manager > +보안 비밀 만들기를 선택합니다.
-
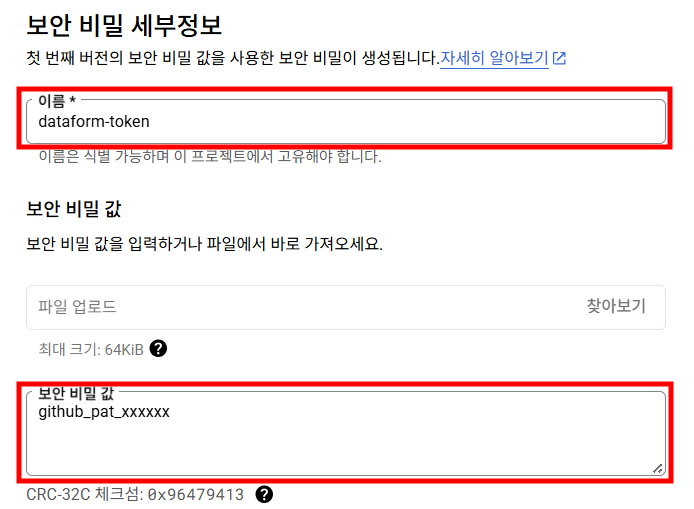
이름을 정한 후
보안 비밀 값항목에 위에서 발급받은 토큰값을 붙여넣고 보안 비밀을 생성합니다.

🔸 3) Dataform 저장소 생성 및 연동
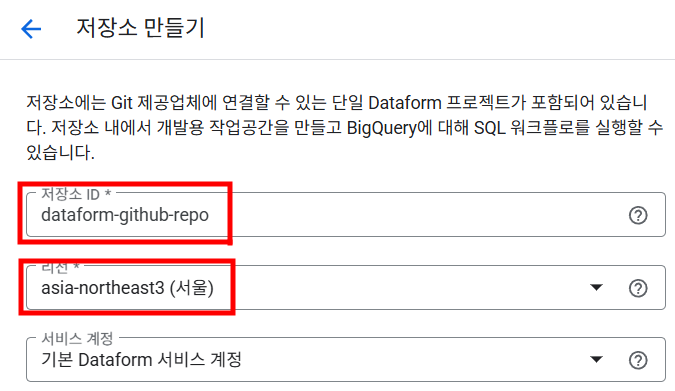
- 위에서 생성한 github Repo와 연동될 Dataform 저장소를 생성합니다.
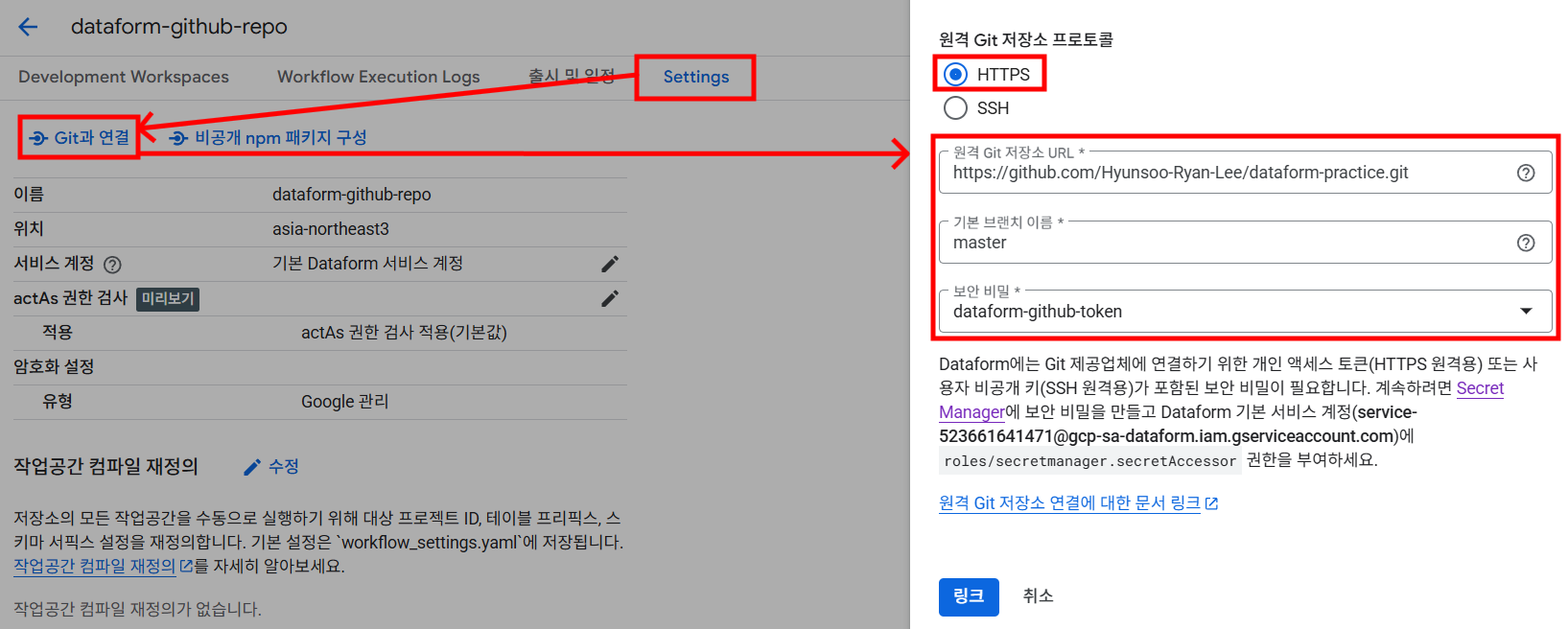
- 생성한 저장소로 들어가
Settings > Git과 연결을 누르면 github Repo와 연동할 수 있는 설정창이 나옵니다.
아래 사진과 같이 github Repo 저장소 URL, 기본 브랜치 이름, 그리고 위에서 등록한 secret manager 키를 선택해주고링크를 누르면 연동이 완료됩니다.
🔸 4) 작업 공간(workspace) 생성 후 초기화
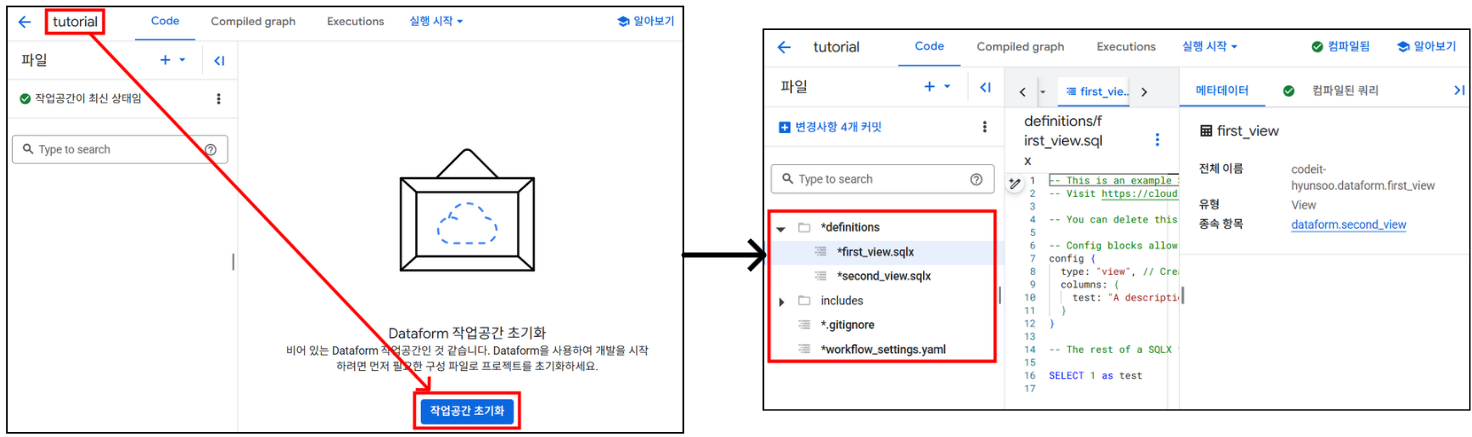
- 연동된 Dataform 저장소에 작업 공간을 생성합니다. 이 작업 공간은 이후 Github Repo와 연동될 때 브랜치명으로 사용됩니다. 즉,
dataform-github-repo라는 저장소 내에 작업 공간을 A, B, C 이렇게 3개를 만들었다면, 이들 각각이 연동된 github Repo의 브랜치가 되는 것입니다. tutorial이라는 작업 공간을 생성하고작업공간 초기화버튼을 클릭하면 초기 세팅 파일들이 생성됩니다.
🔸 5) Github Repo로 push
tutorial작업 공간에 생성된 초기 파일들을 연동된 Github Repo로 push 할 수 있습니다. UI에서 버튼 몇 번만 클릭하면 간단하고 직관적으로 commit 후 push가 완료됩니다.tutorial브랜치로 push하는 것이 디폴트지만 설정을 통해master(혹은 main)브랜치로 바로 push하는 것도 가능합니다.
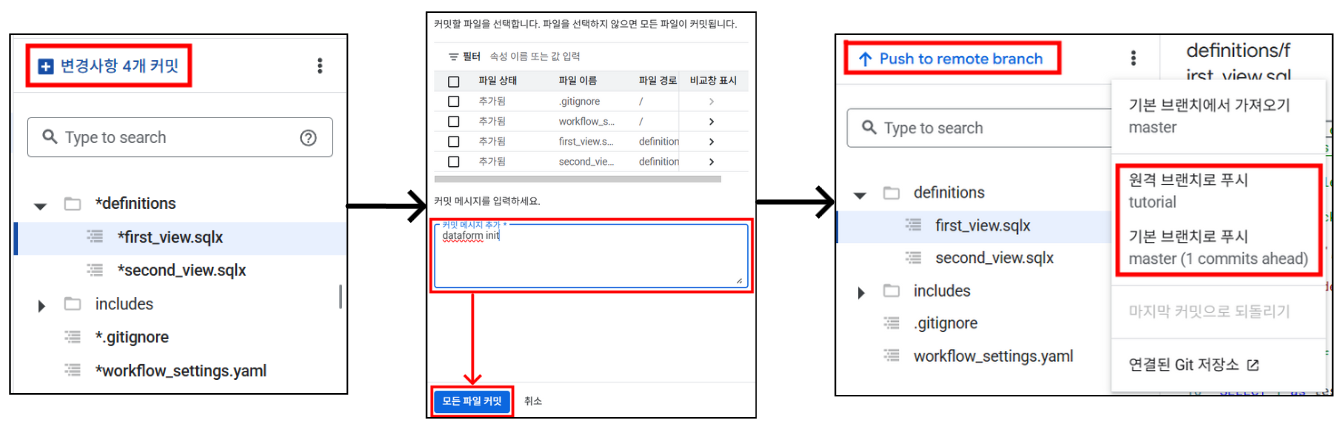
- Github에서 확인해보면 앞에서 생성한
dataform-practiceRepo의tutorial브랜치에 해당 파일들이 잘 올라가있는 것을 확인할 수 있습니다.
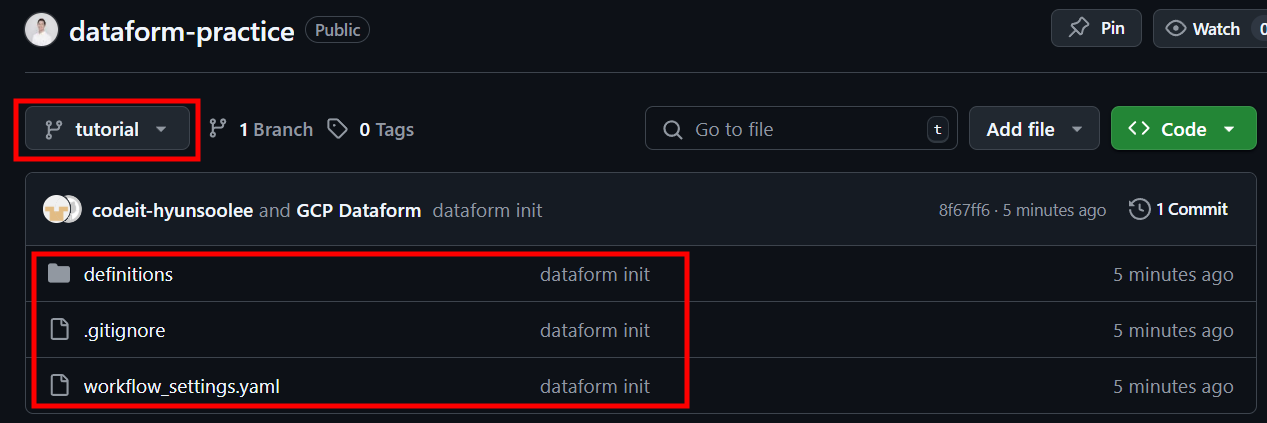
- 이후 Dataform 작업시 파일이나 디렉토리에 변경이 일어나는 경우, 위와 같이 UI를 통해 github 저장소로 바로 push를 할 수 있어 코드 형상관리가 아주 편리해진다는 장점이 있습니다.
🔹 2. config 설정
.sqlx파일의 문법이 일반 SQL과 다른점은 상단에 정의되는 config 때문입니다. 이 설정을 통해 쿼리의 의존성, 실행 순서, 파티셔닝, 태그 지정, 품질 검사 등 파이프라인 작업에 필요한 다양한 세부 사항들을 정의할 수 있어, 단순한 SQL 쿼리를 넘어 복잡한 데이터 워크플로우를 구성이 가능하게 해줍니다.
🔸 1) 기본 설정 오버라이딩
workflow_settings.yaml파일에 작성했던 기본 설정값들을 파일 내에서 재정의 할 수 있습니다. 설정을 따로 하지 않으면, 기본 설정값에 명시된 사항에 따라 테이블이 생성됩니다.
config {
type: "table",
description : "This is Sample Table"
database: "my-gcp-project-id",
schema: "education",
name: "sample_tbl",
columns: {
user_id: {
description: "Unique identifier for the user"
event_timestamp: {
description: "Timestamp of the battle event"
}
}type: 파일이 어떤 방식으로 실행되고 결과를 생성할지 유형을 정의table: 물리적 테이블 생성incremental: 테이블에 증분 방식으로 데이터를 추가하거나 업데이트view: 논리적 뷰 생성operations: 테이블이나 뷰를 생성하지 않고, 정의된 SQL 작업을 실행assertion: 데이터 품질 검사를 정의(조건 불충족시 작업 실패)
description: 생성될 테이블에 대한 설명 추가database: 작업이 저장될 project ID 설정schema: 저장될 빅쿼리 dataset 이름 설정name: 저장될 테이블 이름 설정(없다면sqlx파일명으로 저장)columns: 테이블의 컬럼에 대한 메타데이터(설명, 태그 등)를 정의
🔸 2) 추가 설정
config {
type: "table",
database: "my-gcp-project-id",
schema: "education",
name: "sample_tbl",
columns: {
user_id: {
description: "Unique identifier for the user"
},
event_timestamp: {
description: "Timestamp of the battle event"
}
},
disabled: true,
hasOutput: true,
dependencies: ["raw_battle_data", "user_profile"]
tags : ['dev']
}disabled: 해당 파일에서의 테이블 생성 비활성화 여부hasOutput:type: "operations"인 SQLX 파일에서 출력 테이블을 생성하도록 지정dependencies: SQLX 파일 간의 명시적 의존성을 정의tags: 특정 작업을 선택적으로 실행하거나 그룹화할 때 사용되는 태그를 설정
🔹 3. 작업 전후 쿼리 설정
pre_operations,post_operations설정을 통해 파일 본문의 SQL 쿼리 작업이 실행되기 전과 후에 실행할 SQL 문을 정의할 수 있습니다.pre_operations: 테이블 생성 전에 실행할 SQL 문을 정의post_operations: 테이블 생성 후에 실행할 SQL 문을 정의
config {
type: "table",
description : "This is Sample Table"
database: "my-gcp-project-id",
schema: "education",
name: "sample_tbl",
columns: {
user_id: {
description: "Unique identifier for the user"
event_timestamp: {
description: "Timestamp of the battle event"
}
}
-- 본문의 SQL 쿼리 실행 전 작업 정의
pre_operations {
CREATE OR REPLACE TABLE sprintda05-hyunsoo.dataform.pre AS SELECT * FROM codeit-hyunsoo.dataform.source
}
-- 본문의 SQL 쿼리 실행 이후 작업 정의
post_operations {
CREATE OR REPLACE TABLE sprintda05-hyunsoo.dataform.post AS SELECT * FROM codeit-hyunsoo.dataform.source
}
-- SQL 쿼리
SELECT 1 AS number;🔹 4. Assertions 설정
- Assertions 공식 문서
- 작업시 생성되는 테이블의 품질 검사를 정의하는 항목으로, 지정된 조건이 충족되지 않으면 워크플로우 실행이 실패하게 됩니다.
- 정의에 따른 쿼리의 결과값이 0이면 통과, 한 행 이상을 반환하게되면 실패로 간주됩니다.
- 일반적으로 아래와 같은 내용들을 체크할 때 많이 활용됩니다.
데이터 무결성: 필수 필드에 null 값이 없는지 확인.중복 데이터: 고유 키(unique key)에 중복이 없는지 확인.데이터 범위 검증: 값이 예상 범위 내에 있는지 확인.데이터 최신성 확인: 데이터가 특정 시간 내에 적재되었는지 확인.
- Assertions 작업이 실패하게 되면 빅쿼리에
dataform_assertions이라는 dataset이 만들어지고 작업 파일명과 동일한 이름의 VIEW가 생성되어 실패한 행 확인이 가능합니다.

🔸 1) 수동 Assertions 정의
-
수동 Assertions는 독립적인 SQLX 파일에 정의되며, 특정 테이블의 품질을 테스트하는 데 사용됩니다.
-
예를 들어
demo_table이라는 테이블의status행에 null값이 있는지 확인하는 Assertions를 작성할 수 있습니다. -
definitions/single_assert.sqlxconfig { type: "assertion" } SELECT status FROM dataform.demo_table WHERE status IS NULLconfig { type: "assertion" }: 이 파일이 Assertion임을 지정.- 쿼리는 status 컬럼에서 null인 행을 찾음.
- 쿼리가 0행을 반환하면 Assertion 성공, 1행 이상 반환하면 실패.
- 실패 시
dataform_assertions.single_assert뷰를 BigQuery에 생성하여 실패한 행을 확인할 수 있도록 함.
-
수동으로 Assertions를 정의하는 경우, 워크플로우 그래프를 보게되면 아래와 같이 하나의 작업만 보이는 것을 확인할 수 있습니다.
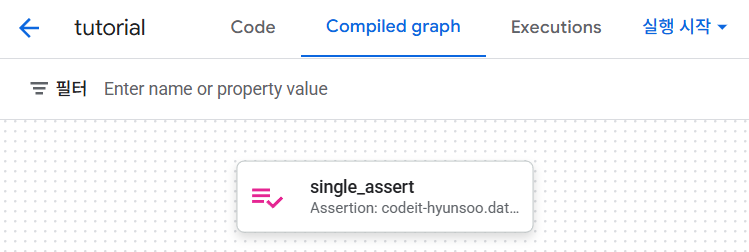
🔸 2) 테이블 내 Assertions 정의
-
테이블 정의 내에서 Assertions를 설정하면, 해당 테이블 생성 후 자동으로 데이터 품질 테스트를 수행합니다. config 블록에 assertions 속성을 추가하여 정의합니다.
-
definitions/multi_assert.sqlxconfig { type: "table", assertions: { uniqueKey: ["user_id"], // user_id가 고유해야 함 nonNull: ["user_id", "customer_id"], // user_id, customer_id가 null이 아니어야 함 rowConditions: [ "create_date > '2019-01-01'", // create_date 조건 "email LIKE '%@%.%'" // 이메일 형식 검증 ] } } SELECT user_id, customer_id, create_date, email FROM dataform.assertion_tableuniqueKey: user_id 열에 중복 값이 없어야 함.nonNull: user_id와 customer_id가 null이 아니어야 함.rowConditions: 컬럼의 값들이 지정된 SQL 조건을 만족해야 함
-
아래 정의된 SQL 문을 바탕으로 파일명과 동일한
multi_assert테이블 생성 후assertions항목에 정의된 검증을 실행합니다. -
assertions항목에 정의된 내용의 통과 유무는 이후 연결된 작업에 영향을 미치기 때문에 해당 파일 하나로는 품질 검증에 의미가 크게 없고, 각 검증 절차 이후 연결되는 또 다른 작업 파일이 있을 때 활용성이 높아집니다. -
워크플로우 그래프를 확인해보면, 아래와 같이
multi_assert작업 이후assertions검증 항목이 연결되어 보이는 것을 확인할 수 있습니다.
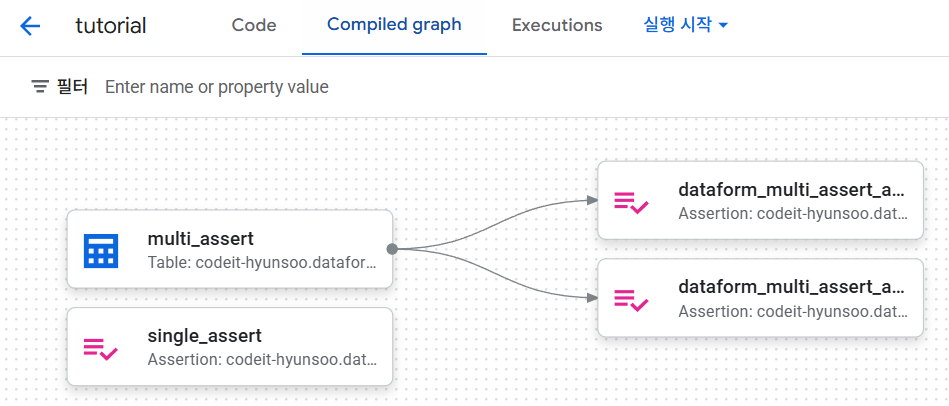
🔹 5. OUTRO
- 이번 글에서는 Dataform의 저장소를 Github와 연동하고,
.sqlx파일에 정의할 수 있는 config 요소들에 대해 상세히 알아보았습니다. 위의 기능들만 잘 활용해도 BigQuery 테이블을 바탕으로 효율적인 ETL 파이프라인을 구성할 수 있지 않을까 싶습니다.
