0. INTRO
- GCS, S3와 같은 클라우드 객체 스토리지를 Data Lake로 활용하는 경우, 지속적으로 유입되는 데이터를 디렉토리 단위로 파티셔닝하여 저장하는 방식이 일반적입니다.
예를 들어, 일 단위로 적재되는 데이터는yyyy=/mm=/dd=형식으로, 시간 단위 배치 데이터는yyyy=/mm=/dd=/hh=와 같은 구조로 저장할 수 있습니다. 이러한 디렉토리 구조는 데이터의 배치 주기와 일치하도록 설계되어 효율적인 관리와 조회를 가능하게 합니다. - 이처럼 주기적으로 누적되는 데이터를 분석용 테이블로 적재할 때는, 증가된 데이터만 APPEND 방식으로 적재하는 방법이 리소스와 처리 시간 면에서 훨씬 효율적입니다. 단, 이 방식은 원천 데이터에 삭제나 수정 없이 오직 데이터가 추가만 되는 경우에 안정적으로 작동할 수 있으며, 로그나 이벤트 기록처럼 이력성 데이터를 처리할 때 특히 유용한 전략입니다.
- 이번 글에서는 GCS(Google Cloud Storage)에 일 단위로 적재되는 데이터를 중분(Incremental) 방식으로 테이블에 적재하는 방법에 대해 다뤄보도록 하겠습니다.
1. GCS 적재 데이터 구조
-
GCS에 적재되는 데이터의 형상은 아래와 같습니다.
-
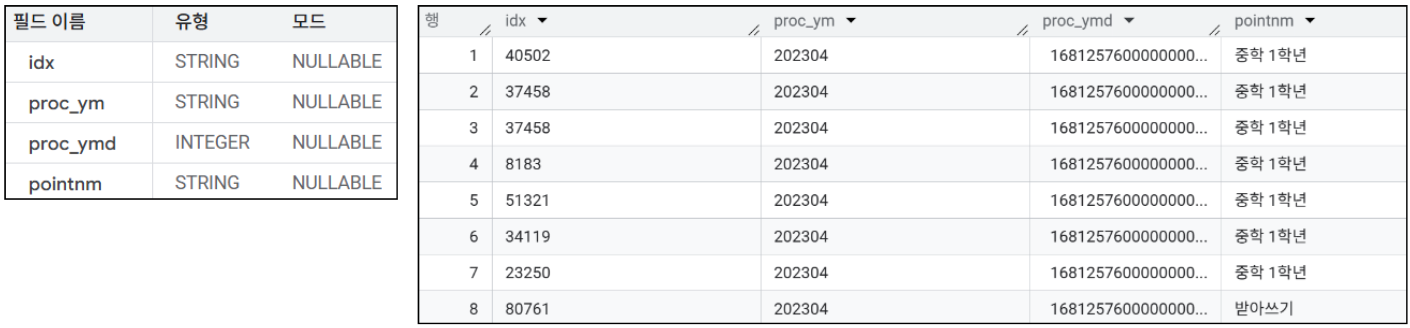
컬럼 4개로 이루어진 테이블이며, 그 중
proc_ymd컬럼이 적재된 날짜(년월일)를 알려줍니다. -
적재 기간은 2023-04-01 ~ 2023-04-30 입니다.
-
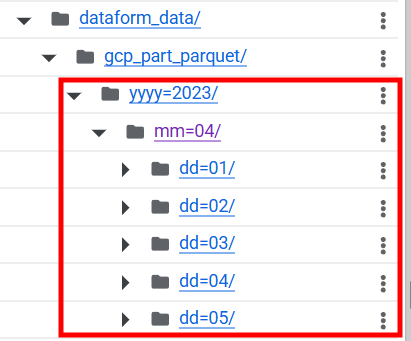
GCS에는
yyyy=2023/mm=04/dd=01/data.parquet이런 형식으로 일단위로 디렉토리가 나뉘어 적재됩니다.
2. EXTERNAL TABLE 활용하기
1) External Table이란?
- External Table은 BigQuery에서 외부 저장소(GCS, Google Drive 등)에 있는 데이터를 직접 참조하여 쿼리할 수 있는 가상 테이블입니다. 즉, 데이터를 BigQuery 테이블로 만들어 저장해놓지 않고도, 마치 BigQuery 내부 테이블처럼 SQL을 사용하여 조회할 수 있도록 해주는 기능입니다.
- 따라서 GCS에 parquet 파일 형식(CSV, JSON 등 다양한 형식 지원)으로 데이터가 적재되는 경우, 해당 디렉토리를 BigQuery External Table로 등록해놓으면 새롭게 유입된 데이터를 바로 조회해볼 수 있습니다.
- 하지만 BigQuery 내부 테이블에 비해서는 조회 속도가 느리며, 파티셔닝/클러스터링 기능 활용이 불가능하여 성능 최적화에 한계가 있습니다.
2) 사용 방법
- GCS에 적재되어 있는 데이터를 External Table로 등록하려면 아래와 같은 형식으로 SQL 쿼리를 실행하면 됩니다.
CREATE OR REPLACE EXTERNAL TABLE `프로젝트ID.데이터셋.테이블명` OPTIONS ( format = 'PARQUET', -- CSV, JSON 등 uris = [데이터에 대한 gsutil 주소] ); - 아래 코드는 GCS의
gs://hyunsoo_sprint_bucket/dataform_data/gcp_part_parquet/경로 이하에yyyy=/mm=/dd=형식으로 일 단위 적재되는 데이터들을dataform데이터셋에demo_source라는 이름의 테이블로 등록하는 쿼리입니다.CREATE OR REPLACE EXTERNAL TABLE `codeit-hyunsoo.dataform.demo_source` OPTIONS ( format = 'PARQUET', uris = ['gs://hyunsoo_sprint_bucket/dataform_data/gcp_part_parquet/yyyy=2023/mm=04/*'] );
3) 등록 확인
- 위의 SQL 쿼리문을 통해 External Table 등록이 완료되면 BigQuery 콘솔 화면에서 확인이 가능합니다.

- 이렇게 등록된 External Table의 경우 연결된 GCS 경로에 특정 날짜의 추가 데이터가 적재되면, 해당 적재분에 대한 조회가 바로 가능합니다.
3. DataForm으로 증분 데이터 처리하기
- 위와 같이 External Table을 생성하면, BigQuery는 GCS에 저장된 데이터를 직접 참조하기 때문에 별도의 증분 처리 없이도 최신 데이터를 즉시 조회할 수 있습니다. 그러나 이 데이터를 기반으로 다른 테이블을 생성하거나 가공된 결과를 저장해야 하는 경우, 해당 결과 테이블은 증분 처리가 필요합니다.
- 적재되는 데이터의 양이 많지 않다면 매번 전체 데이터를 다시 적재하는 full-refresh 방식도 고려할 수 있습니다. 하지만, 불필요한 계산과 비용을 줄이고 쿼리 성능을 최적화하려면 신규 데이터만 처리하는 증분 방식을 선택하는 것이 훨씬 효율적입니다.
- 이러한 증분 처리를 SQL 기반의 선언형 방식으로 손쉽게 구현할 수 있도록 도와주는 도구가 바로 Dataform입니다. Dataform을 활용하면 BigQuery 위에서 안정적이고 확장성 있는 증분 데이터 파이프라인을 간편하게 구성할 수 있습니다.
1) 증분 데이터 처리 코드 작성
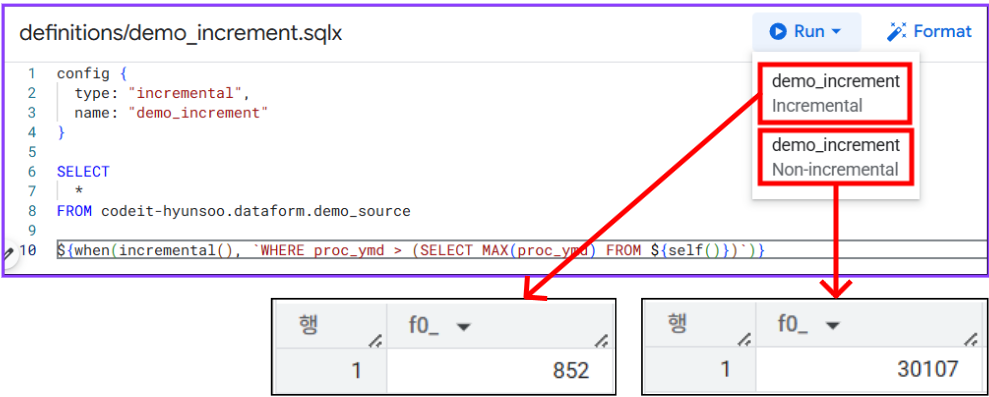
definition/demo_increment.sqlx
config {
type: "incremental",
name: "demo_increment"
}
SELECT
*
FROM codeit-hyunsoo.dataform.demo_source
${when(incremental(), `WHERE proc_ymd > (SELECT MAX(proc_ymd) FROM ${self()})`)}-
type: "incremental"
→ 이 모델은 증분 처리 대상 테이블임을 선언합니다. -
name: "demo_increment"
→ 생성될 테이블의 이름은 demo_increment 입니다. -
SELECT 쿼리문
→demo_source테이블의 전체 컬럼을 조회합니다. -
when(incremental() 쿼리문
→ 증분 실행 조건으로,demo_source테이블의proc_ymd컬럼에 새로운 날짜 데이터가 들어오면 해당 데이터를demo_increment로 삽입합니다.
즉, 위의 스크립트는
demo_source테이블에 새로운 데이터가 들어오면 추가된 데이터만demo_increment테이블에 적재합니다.
2) 실행 확인 확인
type: "incremental" 조건의 증분 처리 스크립트의 경우Run` 버튼을 누르면 아래와 같이 증분 조건일 경우와 아닐 경우, 두 가지 경우에 대해 실행 테스트를 진행해볼 수 있습니다.
4. OUTRO
- 이번 글에서는 GCS에 일 단위로 데이터가 파일 형식으로 적재되는 경우, BigQuery에서 이를 효율적으로 분석하기 위한 두 가지 증분 처리 방식에 대해 살펴보았습니다.
- External Table : 데이터를 BigQuery로 로드하지 않고도 GCS의 최신 데이터를 직접 조회할 수 있는 방식으로, 별도의 적재 작업 없이 빠르게 분석을 시작할 수 있다는 장점이 있습니다. 단, 대용량 데이터나 정교한 가공이 필요한 경우에는 성능이나 비용 측면에서 주의가 필요합니다.
- Dataform incremental 모델 : 데이터가 쌓이는 구조를 반영하여, 새로운 데이터만을 선택적으로 BigQuery 테이블에 추가하는 방식입니다. 스케줄링과 병합 조건을 선언형으로 관리할 수 있어, 지속적인 데이터 파이프라인 운영에 적합합니다.
- 데이터 엔지니어링에서 증분 처리는 비용 효율성과 쿼리 성능을 동시에 잡기 위한 핵심 전략입니다. 데이터의 속성, 쿼리 목적, 사용 빈도 등을 고려하여 상황에 맞는 방식을 선택하는 것이 중요합니다.

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD