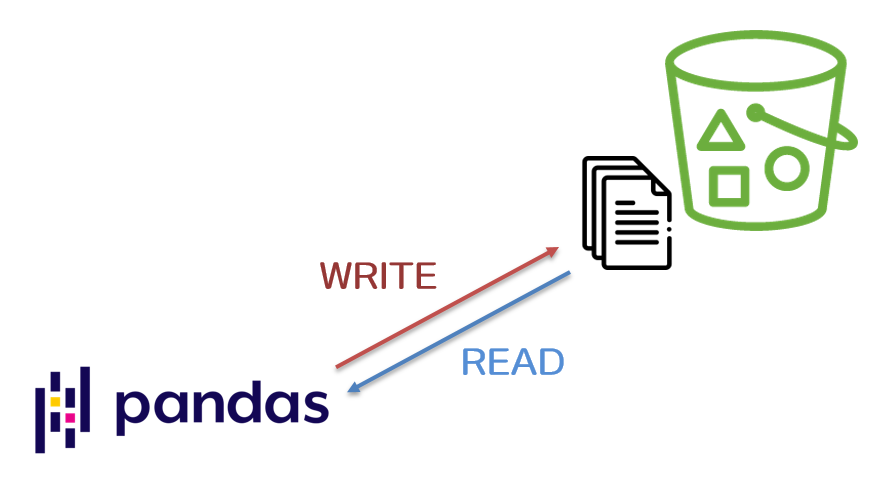
0. INTRO
- pandas에는 DataFrame을 각종 형태로 저장할 수 있는 다양한 메소드들을 지원한다. to_csv(), to_json(), to_parquet() 등의 메소드를 사용하면 메모리에 저장된 Pandas DataFrame을 실제 파일로 저장할 수가 있는 것이다.
- 기존에는 로컬에 저장하는 용도로만 위의 메소드들을 사용하였지만 이번에 data pipeline을 구성하면서 특정 Cloud의 Object Storage에 바로 저장이 가능하다는 것을 알게 되었다. 생각보다 간단하지만 알고나면 아주 파워풀한 기능이 될 것이라 생각하며 해당 기능들에 대한 쓰임을 정리한다.
- Naver Cloud의 공공존에 있는 인프라로 테스트를 진행했다.
1. read_parquet()을 통한 데이터 읽기(read)
-
s3fs라이브러리 설치 후 기능 사용이 가능하므로 먼저 설치를 해준다.pip install s3fs
-
Object Storage에 있는 parquet 파일 읽기
import pandas as pd
aws_storage_options = {
"key" : "",
"secret" : ""
}
ncp_storage_options = {
"endpoint_url" : "http://kr.object.gov-ncloudstorage.com",
"key" : "",
"secret" : ""
}
df = pd.read_parquet(
"s3a://[Object Storage 내부 경로]",
storage_options = ncp_storage_options
)
df.head()2. to_parquet()을 통한 데이터 쓰기(write)
- Object Storage로 parquet 파일 쓰기
import pandas as pd
aws_storage_options = {
"key" : "",
"secret" : ""
}
ncp_storage_options = {
"endpoint_url" : "http://kr.object.gov-ncloudstorage.com",
"key" : "",
"secret" : ""
}
pdf.to_parquet(
"s3a://[Object Storage 내부 경로]",
compression='snappy',
engine = 'pyarrow',
storage_options = ncp_storage_options
)
데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD