🔹 0. INTRO
- 지금까지 spark를 사용하면서 데이터의 원천은 거의 파일 데이터였다. 현재 다니는 회사의 Data Lake에 수집되는 데이터의 형식이 parquet 파일인 이유가 가장 컸고 그 외에 DB에 바로 붙어서 처리를 해야할 때는 python을 주로 사용했었다.
- 하지만 spark역시 다양한 형태의 Database에 대한 Connection을 지원한다. MYSQL, PostgreSQL 등의 RDB 및 MongoDB나 Elastic Search와 같은 NoSQL DB에 대한 연결 등 아주 광범위한 Connection range를 가지고 있다.
- 이번 글에서는 로컬에 설치된 MYSQL, PostgreSQL 두 RDBMS에 대하여 Spark로 Connection을 생성하고 특정 테이블 데이터를 읽고 쓰는 기본적인 내용을 다뤄볼 것이다.
🔹 1. PostgreSQL Connection
📍 1. jar 파일 다운로드
- Connection을 생성하기 위해서는 DB에 맞는 jar 파일을 다운로드 받아서 해당 경로를 config에 참조시켜주어야 한다.
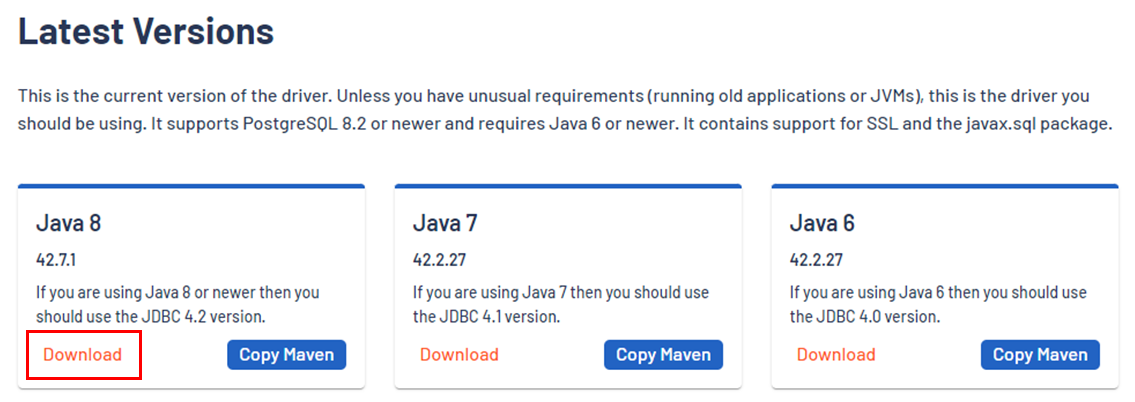
- postgresql jdbc 사이트에 들어가서
Java 8버전을 다운로드 해준다.
📍 2. SparkSession 생성
-
위에서 다운받은 jar 파일 경로를 참조하여 SparkSession을 만들어준다.
spark = SparkSession \ .builder \ .config("spark.driver.extraClassPath", "[postgresql jar 파일 경로]") \ .appName('pyspark-db-connect') \ .getOrCreate()
📍 3. DB Connection 생성 후 Read
- 3-0. 기본 정보들 명시
ip = "127.0.0.1"
port = "5432"
user = [User Name]
passwd = [User Password]
db = [DB Name]
table_name = [Table 이름]- 3-1. Table 이름으로 Read
df = spark.read.format("jdbc") \
.option("url", f"jdbc:postgresql://{ip}:{port}/{db}") \
.option("driver", "org.postgresql.Driver") \
.option("dbtable", table_name) \
.option("user", user) \
.option("password", passwd) \
.load()
df.show(5)
+--------------------+------+---------------------------------+---------------------------------+-----------+---+---------+
| uuid| name| job| residenct|blood_group|sex|birthdate|
+--------------------+------+---------------------------------+---------------------------------+-----------+---+---------+
|hiHBkVffEpBQYjnzH...|조시우| 웹 및 멀티미디어 디자이너| 인천광역시 서초구 영동대87로| AB-| F| 19190212|
|agpsZF4GY7BNvG93e...|이민준|기타 비금속제품관련 생산기 조작원| 대구광역시 용산구 역삼387길| AB+| F| 19811230|
|7ADnduVUeGHmsbPP2...|최영호| 식품공학 기술자 및 연구원| 울산광역시 금천구 삼성가| AB-| M| 20040127|
|E45xDDdVZejWnmUzS...|김상호| 화학제품 생산기 조작원|부산광역시 강북구 서초대가 (지...| AB-| M| 19420603|
|VfAHfJZGK4nkLFhfh...|서숙자| 기타 음식서비스 종사원| 전라북도 수원시 권선구 반포대길| O+| F| 19271101|
+--------------------+------+---------------------------------+---------------------------------+-----------+---+---------+- 3-2. SQL query로 Read
sql = "select * from temp"
df = spark.read.format("jdbc") \
.option("url", f"jdbc:postgresql://{ip}:{port}/{db}") \
.option("driver", "org.postgresql.Driver") \
.option("query", sql) \
.option("user", user) \
.option("password", passwd) \
.load()
df.show(5)
+--------------------+------+---------------------------------+---------------------------------+-----------+---+---------+
| uuid| name| job| residenct|blood_group|sex|birthdate|
+--------------------+------+---------------------------------+---------------------------------+-----------+---+---------+
|hiHBkVffEpBQYjnzH...|조시우| 웹 및 멀티미디어 디자이너| 인천광역시 서초구 영동대87로| AB-| F| 19190212|
|agpsZF4GY7BNvG93e...|이민준|기타 비금속제품관련 생산기 조작원| 대구광역시 용산구 역삼387길| AB+| F| 19811230|
|7ADnduVUeGHmsbPP2...|최영호| 식품공학 기술자 및 연구원| 울산광역시 금천구 삼성가| AB-| M| 20040127|
|E45xDDdVZejWnmUzS...|김상호| 화학제품 생산기 조작원|부산광역시 강북구 서초대가 (지...| AB-| M| 19420603|
|VfAHfJZGK4nkLFhfh...|서숙자| 기타 음식서비스 종사원| 전라북도 수원시 권선구 반포대길| O+| F| 19271101|
+--------------------+------+---------------------------------+---------------------------------+-----------+---+---------+📍 4. Table 가공 후 DB에 write
residenct컬럼의 앞단어만 추출해서 시별로 group by 된 테이블을 저장해보도록 할 것이다.
# residenct 컬럼의 앞 단어만 추출
df_ = df.withColumn('residenct', F.split(F.col('residenct'), " ").getItem(0))
# Group by count
df_group = df_.groupBy(F.col('residenct')).count().orderBy('count', ascending=False)
# Write to DB
df_group.write.format("jdbc") \
.option("url", f"jdbc:postgresql://{ip}:{port}/{db}")\
.option("driver", "org.postgresql.Driver") \
.option("dbtable", [저장할 Table 이름]) \
.option("user", user) \
.option("password", passwd) \
.save()- psql을 통해 테이블을 조회해보면 잘 저장된 것을 확인할 수 있다.
postgres=# SELECT * FROM group;
residenct | count
----------------+-------
울산광역시 | 12
충청남도 | 12
경기도 | 12
대전광역시 | 17
대구광역시 | 13
부산광역시 | 8
세종특별자치시 | 8
광주광역시 | 14
인천광역시 | 14
강원도 | 14
충청북도 | 14
전라북도 | 10
제주특별자치도 | 10
경상남도 | 11
경상북도 | 11
전라남도 | 9
서울특별시 | 6
(17개 행)🔹 2. MYSQL Connection
📍 1. jar 파일 다운로드
- 전체적으로는 위의 postgresql 연결하는 방식과 동일한 흐름으로 진행된다.
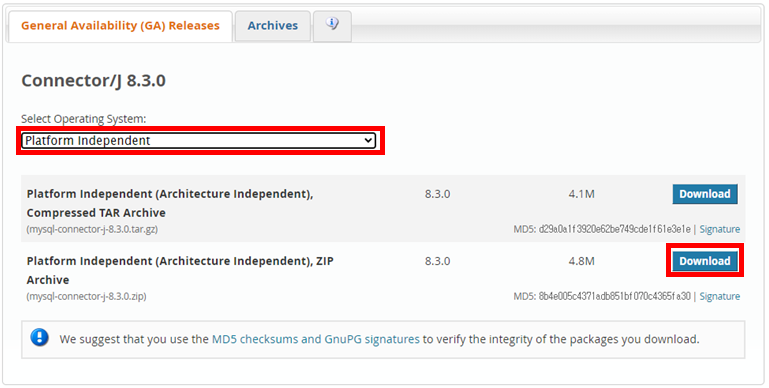
- mysql jdbc 사이트에 들어가서 jar 파일을 다운로드 받아준다.
- 다운로드시
Platform Independent유형을 선택하여 압축파일을 다운받아준다.
- 압축을 풀고 폴더 안으로 들어가면
mysql-connector-j-8.3.0.jar파일을 찾을 수 있다.
📍 2. SparkSession 생성
-
위에서 다운받은 jar 파일 경로를 참조하여 SparkSession을 만들어준다.
spark = SparkSession \ .builder \ .config("spark.driver.extraClassPath", "[mysql jar 파일 경로]") \ .appName('pyspark-db-connect') \ .getOrCreate()
📍 3. DB Connection 생성 후 Read
- 3-0. 기본 정보들 명시
ip = "127.0.0.1"
port = "3306"
user = [User Name]
passwd = [User Password]
db = [DB Name]
table_name = [Table 이름]- 3-1. Table 이름으로 Read 1
url = f"jdbc:mysql://{ip}:{port}/{db}"
properties = {
"user": user,
"password": passwd,
"driver": "com.mysql.jdbc.Driver"
}
table_name = table_name
df = spark.read.jdbc(url, table_name, properties=properties)- 3-2. Table 이름으로 Read 2
df = spark.read.format("jdbc") \
.option("url", f"jdbc:mysql://{ip}:{port}/{db}") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.option("dbtable", table_name) \
.option("user", user) \
.option("password", passwd) \
.load()- 3-3. SQL query로 Read
sql = "select * from dept"
df = spark.read.format("jdbc") \
.option("url", f"jdbc:mysql://{ip}:{port}/{db}") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.option("query", sql) \
.option("user", user) \
.option("password", passwd) \
.load()📍 4. Table 가공 후 DB에 write
deptno컬럼이 20보다 큰 row만 filter하여 저장한다.
sdf = df.filter(F.col('deptno') > 20)
sdf.write \
.format("jdbc") \
.option("driver","com.mysql.cj.jdbc.Driver") \
.option("url", f"jdbc:mysql://{ip}:{port}/{db}") \
.option("dbtable", [저장할 Table 이름]) \
.option("user", user) \
.option("password", passwd) \
.save()🔹 3. 참고 자료

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD