1. Cloudtrail Log 데이터 활용
-
AWS Cloudtrail 서비스는 AWS 계정을 통해 접속한 User들의 활동 기록들을 남겨주는 서비스이다. AWS 공식 문서에는 아래와 같이 나온다.
AWS CloudTrail은 AWS 계정의 운영 및 위험 감사, 거버넌스 및 규정 준수를 활성화하는 데 도움이 되는 AWS 서비스입니다. 사용자, 역할 또는 AWS 서비스가 수행하는 작업들은 CloudTrail에 이벤트로 기록됩니다. 이벤트에는 AWS Management Console, AWS Command Line Interface 및 AWS SDK, API에서 수행되는 작업들이 포함됩니다.
-
단지 이용자들이 수행한 활동만이 아닌, AWS 서비스들끼리 통신하는 기록, API나 SDK를 통한 기록들까지 모두 저장이 되고 Log를 탐색해보면 알 수 있겠지만 정말 세세한 부분 하나하나까지 다 기록으로 저장이 된다. 이를 통해 AWS 리소스 이용에 대한 세세한 로그 기록들을 통하여 특정 서비스별 사용 인원, 리소스 사용 비율, 시간대별 사용량 등 다양한 방향으로 분석을 진행할 수 있으며 이를 통해 AWS 클라우드 관리나 이용, 보안 등에 관한 유의미한 데이터들을 추출해낼 수 있다. 아래는 Cloudtrail Data Usage에 대한 공식 문서의 설명 중 일부이다.
AWS 계정 활동에 대한 가시성은 보안 및 운영 모범 사례에서 중요한 측면입니다. CloudTrail을 사용하여 AWS 인프라 전반에서 계정 활동을 확인, 응답할 수 있습니다. 누가 또는 무엇이 어떤 작업을 수행했는지, 어떤 리소스에 대해 조치가 취해졌는지, 언제 이벤트가 발생했는지, AWS 계정에서 활동 분석 및 응답에 도움이 되는 기타 세부 정보를 식별할 수 있습니다.
-
현재 회사에서는 AWS Cloud 서비스들을 활용하여 데이터 분석을 진행하고 있으며 하나의 계정 아래 여러명의 IAM User가 Group별로 나뉘어 등록되어 있는 구조이다. 일과중에는 약 15명 남짓의 직원이 동시에 접속하여 사용하고 있으며 타 그룹 유저들까지 포함한다면 20명 이상으로 올라갈 것이다. 이러한 AWS 계정에 대한 Cloudtrail Log 분석을 진행하며 느꼈던 점들과 분석에 대한 포인트들을 공유해보고자 한다.
2. Cloudtrail Log 데이터의 저장
- 각 User들의 활동 로그는 Cloudtrail 서비스에 저장되지만 최대 90일까지만 저장이된다. 따라서 특별한 설정을 하지 않는다면 90일 이후의 로그기록들은 자동으로 삭제가 되어버리는 것이다.
- 로그 기록들의 지속적인 저장을 위해 로그 기록이 저장되는 곳을 S3 버킷으로 지정하도록 설정이 가능하다. (Cloudtrail > Trails > Create trail) 이러한 설정을 해놓으면 삭제에 대한 우려 없이 지속적으로 S3에 로그 저장을 할 수 있게 된다.
3. Cloudtrail Log 데이터 분석의 어려움
- 데이터 저장 format
- 일반적으로 우리가 다루기 편한 데이터의 포맷은 csv, json 혹은 xlsx 등일 것이다. Spark를 다룰 줄 알거나 더 높은 효율성을 원한다면 parquet 까지도 넓혀질 수 있다. 이들 data의 공통점은 압축이 되어있지 않고 parquet을 제외한다면 메모장이나 notePad 등의 툴을 이용하여 열었을 때 data의 구조를 직관적으로 알 수 있다는 것이다.
- 하지만 Cloudtrail 로그 데이터의 경우 S3에 저장되는 포맷을 보면 json.gz라는 json 압축파일로 저장이 되어 있는 것을 알 수 있다. 따라서 위에 언급한 우리에게 익숙한 csv, json, parquet 등의 포맷을 가진 데이터와 동일하게 Read를 하게 되면 문제가 발생할 수 있다.
- Nested Data
- Cloudtrail Data Schema를 보면 알 수 있듯, 저장되는 데이터가 Nested(중첩)한 형태를 가지고 있다. 즉, 컬럼의 내용에 list나 json 형태의 데이터가 들어가 있는 등 RDB의 관점에서 보면 정규화에 크게 위배된, NoSQL에 맞는 형식으로 저장되어 있다.
- 로그의 내용들을 제대로 확인하기 위해서는 중첩된 데이터의 제일 안쪽 부분까지 파고 들어가야 하며 이 중첩 부분을 flatten 시켜 정규화해주는 작업이 필요하다.
- 방대한 데이터
- 계정을 이용하는 사용자 수에 따라 크게 달라질 수 있겠지만 AWS 내에서 세세하게 일어나는 모든 event들에 대한 로그를 쌓기 때문에 하루에도 쌓이는 데이터의 양이 아주 방대하다. 우리 회사의 계정을 예로 들자면 1달에 table row로 약 2.5억건의 데이터가 저장된다.
- 당연한 말이겠지만 데이터의 양이 방대해지면 단순한 조회 쿼리나 코드를 던졌을 때에도 컴퓨팅 리소스를 많이 잡아먹고 시간도 오래걸리기 때문에 다루기가 상당히 까다로워진다. 따라서 이런 경우에는 Bronze, Silver, Gold로 데이터 계층을 나누어 차츰 정제된 데이터를 저장하게 되고 최종적으로는 Gold Data를 바라보고 시각화를 구성하게 된다.
- UTC 시간대로 저장
- 저장되는 로그 내부를 보면 해당 이벤트가 수행된 시간인 eventtime 이라는 컬럼이 있다. 하지만 이 컬럼에 나오는 시각은 국제표준시인 UTC를 기준으로 저장되고 있기 때문에 한국에 있는 우리의 입장에서 보기 위해서는 eventtime에 일괄적으로 9시간이 더해진 KST_eventtime 컬럼을 따로 생성해주고 이 컬럼을 바탕으로 날짜를 나누어주어야 한다.
- 크게는 위의 네가지 이유들 때문에 RDB database를 바라보고 하는 일반적인 데이터 분석에 비해 Cloudtrail로그 분석이 더 까다롭게 느껴졌다.
4. Cloudtrail Log 데이터 정제시 접근 방법 및 유의사항
-
Athena를 통한 Query
- Cloudtrail > Event History > Create Athena Table 에서 로그 데이터를 Athena Table로 만들어주는 DDL 쿼리를 제공해주므로 해당 내용에서 S3 Bucket 이름과 버킷 내부 디렉토리에 대한 내용만 추가해주면 간단히 Table 형태로 생성이 가능하다.
- Nested data 형태 그대로 저장이 되고 json.gz 파일을 바로 바라보고 조회하기 때문에 쿼리가 약간만 복잡해져도 시간이 굉장히 많이 소요된다. 나의 경험에 의하면 Group by가 두 번 들어간 서브쿼리에 대한 조회 결과를 받아오는데 2분 30초 가량이 걸렸다.
-
Spark를 통한 데이터 가공
- EMR 클러스터에 구축된 Pyspark 환경에서 Json 압축파일을 읽어들이고 Nested data를 펼쳐서 정규화시키고 이를 다시 UTC를 KST로 변환할 후 parquet 파일로 저장하는 과정을 거쳐야 하는데 이 전반적인 프로세스를 scratch부터 코딩해야했기 때문에 중간중간 번거로운 과정들이 많이 있었다.
- 월별로 다루기엔 데이터가 상당이 크고 UTC를 KST로 변환하는 작업도 해주어야 하기 때문에 작업일 기준 과거 이틀치 data path를 가지고 데이터 정제를 한다.
- 복잡한 과정들이 있지만 일단 잘 가공하여 parquet 파일로 저장해놓는다면 엄청난 시간 및 리소스 단축을 경험할 수 있다.
5. AWS Athena Table 형태로 변환
-
Cloudtrail > Event History > Create Athena Table 항목에서 아래와 같은 Create Table 쿼리 포맷을 얻을 수 있다. 해당 쿼리에서 [TABLE_NAME] 입력, [S3_BUCKET_NAME], [S3_BUCKET_URL] 부분만 로그 쌓이는 S3 버킷 정보에 맞게 변경해준 후 Athena 쿼리 창에 명령을 실행하면 로그 테이블이 생성된다.
CREATE EXTERNAL TABLE [TABLE_NAME] ( eventVersion STRING, userIdentity STRUCT< type: STRING, principalId: STRING, arn: STRING, accountId: STRING, invokedBy: STRING, accessKeyId: STRING, userName: STRING, sessionContext: STRUCT< attributes: STRUCT< mfaAuthenticated: STRING, creationDate: STRING>, sessionIssuer: STRUCT< type: STRING, principalId: STRING, arn: STRING, accountId: STRING, username: STRING>, ec2RoleDelivery: STRING, webIdFederationData: MAP<STRING,STRING>>>, eventTime STRING, eventSource STRING, eventName STRING, awsRegion STRING, sourceIpAddress STRING, userAgent STRING, errorCode STRING, errorMessage STRING, requestParameters STRING, responseElements STRING, additionalEventData STRING, requestId STRING, eventId STRING, resources ARRAY<STRUCT< arn: STRING, accountId: STRING, type: STRING>>, eventType STRING, apiVersion STRING, readOnly STRING, recipientAccountId STRING, serviceEventDetails STRING, sharedEventID STRING, vpcEndpointId STRING, tlsDetails STRUCT< tlsVersion: STRING, cipherSuite: STRING, clientProvidedHostHeader: STRING> ) COMMENT 'CloudTrail table for [S3_BUCKET_NAME] bucket' ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '[S3_BUCKET_URL]' TBLPROPERTIES ('classification'='cloudtrail');
6. EMR Pyspark를 통해 parquet 형태로 변환
-
분석 필요한 Data를 Schema와 함께 Read.
_path_list = ["작업일_기준_2일전_cloudtrail_s3_path", "작업일_기준_1일전_cloudtrail_s3_path"] cloudTrailSchema = T.StructType() \ .add("Records", T.ArrayType(T.StructType() \ .add("additionalEventData", T.StringType()) \ .add("apiVersion", T.StringType()) \ .add("awsRegion", T.StringType()) \ .add("errorCode", T.StringType()) \ .add("errorMessage", T.StringType()) \ .add("eventID", T.StringType()) \ .add("eventName", T.StringType()) \ .add("eventSource", T.StringType()) \ .add("eventTime", T.StringType()) \ .add("eventType", T.StringType()) \ .add("eventVersion", T.StringType()) \ .add("readOnly", T.BooleanType()) \ .add("recipientAccountId", T.StringType()) \ .add("requestID", T.StringType()) \ .add("requestParameters", T.MapType(T.StringType(), T.StringType())) \ .add("resources", T.ArrayType(T.StructType() \ .add("ARN", T.StringType()) \ .add("accountId", T.StringType()) \ .add("type", T.StringType()) \ )) \ .add("responseElements", T.MapType(T.StringType(), T.StringType())) \ .add("sharedEventID", T.StringType()) \ .add("sourceIPAddress", T.StringType()) \ .add("serviceEventDetails", T.MapType(T.StringType(), T.StringType())) \ .add("userAgent", T.StringType()) \ .add("userIdentity", T.StructType() \ .add("accessKeyId", T.StringType()) \ .add("accountId", T.StringType()) \ .add("arn", T.StringType()) \ .add("invokedBy", T.StringType()) \ .add("principalId", T.StringType()) \ .add("sessionContext", T.StructType() \ .add("attributes", T.StructType() \ .add("creationDate", T.StringType()) \ .add("mfaAuthenticated", T.StringType()) \ ) \ .add("sessionIssuer", T.StructType() \ .add("accountId", T.StringType()) \ .add("arn", T.StringType()) \ .add("principalId", T.StringType()) \ .add("type", T.StringType()) \ .add("userName", T.StringType()) \ ) ) \ .add("type", T.StringType()) \ .add("userName", T.StringType()) \ .add("webIdFederationData", T.StructType() \ .add("federatedProvider", T.StringType()) \ .add("attributes", T.MapType(T.StringType(), T.StringType())) \ ) ) \ .add("vpcEndpointId", T.StringType()))) # Schema와 함께 이틀치 로그 path Read sdf = \ spark \ .read \ .schema(cloudTrailSchema) \ .json(_path_list) -
최상위 컬럼 Flatten 작업 및 정규화 컬럼 이름 추출
# Array, Struct 형으로 들어가 있는 data들을 depth 탐색하여 정규화될 수 있도록 column을 생성해주는 함수 def column_explosion(df): exploded_columns = [] for col_name, col_type in df.dtypes: if col_type.startswith('array'): exploded_columns += [f"{col_name}.{i}" for i in df.select(F.explode(col_name).alias(col_name.lower())).select(f"{col_name.lower()}.*").columns] elif col_type.startswith('struct'): exploded_columns += [f"{col_name}.{i}" for i in column_explosion(df.select(f"{col_name}.*"))] else: exploded_columns.append(col_name) return exploded_columns # 최상위 컬럼 펼치기 작업(explode) table = \ table\ .select(F.explode("Records").alias("record")).select("record.*") # Nested 된 data 내의 컬럼들 포함하여 가장 안쪽에 있는 컬럼들 이름 추출 exploded_columns = column_explosion(table) # Nested data의 depth에 따른 구분자를 .에서 _으로 변경 및 컬럼명 소문자 처리 column_name = [i.replace('.','_').lower() for i in exploded_columns] # 최대한 정규화 할 수 있도록 추출한 column들을 기준으로 1차 explode된 테이블의 nested 데이터 내용 추출 및 컬럼명 일괄 변경 cloudtrail_table = \ table \ .select(exploded_columns) \ .toDF(*column_name) -
KST 컬럼 및 기준일자(proc_ymd) 컬럼 추가 후 최종 테이블 생성
# 정규화된 테이블, 작업일자를 변수로 넘겨준다. def cloudtrail_log_processing(sdf_cloudtrail, yyyymmdd: str): _sdf_cloudtrail = sdf_cloudtrail # 필요한 컬럼들 생성 # eventtime_kst : utc를 한국시간으로 변경 # proc_ymd : 기준일자 컬럼 생성 _sdf_cloudtrail = \ _sdf_cloudtrail \ .withColumn('eventtime_kst', _sdf_cloudtrail.eventtime + F.expr('INTERVAL 9 HOURS')) \ .withColumn('proc_ymd', F.date_format('eventtime_kst', 'yyyyMMdd')) # eventtime_kst이 yyyymmdd에 해당하는 날짜에 발생된 데이터만 필터링 _sdf_cloudtrail = \ _sdf_cloudtrail \ .filter(_sdf_cloudtrail.eventtime_kst.contains(f'{yyyymmdd[0:4]}-{yyyymmdd[4:6]}-{yyyymmdd[6:8]}')) # 컬럼 순서 선언 _sdf_cloudtrail_columns = ['proc_ymd', 'additionaleventdata', 'apiversion', 'awsregion', 'errorcode', 'errormessage' , 'eventid', 'eventname', 'eventsource', 'eventtime', 'eventtime_kst', 'eventtype', 'eventversion' , 'readonly', 'recipientaccountid', 'requestid', 'requestparameters', 'resources_arn', 'resources_accountid' , 'resources_type', 'responseelements', 'sharedeventid', 'sourceipaddress', 'serviceeventdetails' , 'useragent', 'useridentity_accesskeyid', 'useridentity_accountid', 'useridentity_arn' , 'useridentity_invokedby', 'useridentity_principalid', 'useridentity_sessioncontext_attributes_creationdate' , 'useridentity_sessioncontext_attributes_mfaauthenticated', 'useridentity_sessioncontext_sessionissuer_accountid' , 'useridentity_sessioncontext_sessionissuer_arn', 'useridentity_sessioncontext_sessionissuer_principalid' , 'useridentity_sessioncontext_sessionissuer_type', 'useridentity_sessioncontext_sessionissuer_username' , 'useridentity_type', 'useridentity_username', 'useridentity_webidfederationdata_federatedprovider' , 'useridentity_webidfederationdata_attributes', 'vpcendpointid'] _sdf_cloudtrail = \ _sdf_cloudtrail \ .select(_sdf_cloudtrail_columns) return _sdf_cloudtrail final_cloudtrail_log_table = cloudtrail_log_processing(cloudtrail_table, '작업일자')- 최종적으로는 _sdf_cloudtrail_columns 리스트에 있는 elements들을 컬럼으로 가지는 final_cloudtrail_log_table이라는 테이블이 Pyspark Dataframe 형태로 생성되게 된다.
-
Data 저장 및 마무리
- 위에서 만들어진 하루동안의 Cloudtrail 로그 데이터를 pyspark의 write.parquet 명령을 통해 S3 경로에 저장한다. 그 후 Glue Crawler를 작동시켜 Athena에서 조회할 수 있는 Table 형태로 생성이 가능하다.
- Airflow, Step-function, Glue-job 등을 통해 Cloudtrail 일별 데이터를 정제하는 코드가 매일매일 작동하여 지속적으로 가공되어 특정 S3 버킷에 쌓일 수 있도록 관리해주는 것이 필요할 것이다.
- 이렇게 만들어진 Data를 Athena를 통해 조회한 결과 기존 2분 30초가 걸렸던 쿼리 시간이 단 3초로 줄어들었고 Scan된 데이터 역시 어마어마하게 줄어든 것을 알 수 있었다. 즉, 무조건 정제가 필요하다!!
7. QuickSight를 통한 시각화
-
Cloudtrail 원천 데이터와 이를 정제하는 Spark 코드는 최종적으로 Airflow Dag의 Work Process에 맞게 스케쥴링되어 작업되고 매일매일 지속적인 정제작업이 일어나 특정 S3 디렉토리 내에 파티셔닝되어 저장되게 된다.
-
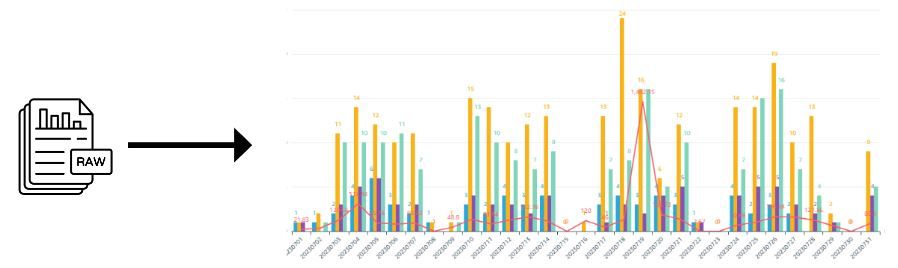
이렇게 정제되어 쌓이는 매일매일의 데이터들을 목적에 맞게 시각화 될 수 있도록 Athena를 통해 Custom Query를 짜고 QuickSight를 통해 해당 Custom Query 데이터를 바라보고 시각화한다. 아래는 최종적으로 시각화 된 화면들 중 일부이다.
-
Athena 및 Quicksight 월간 이용자 수 및 Event 횟수
-
AWS 서비스별 일일 이용자 수 및 일평균 Event
-
