1. 용어 설명
-
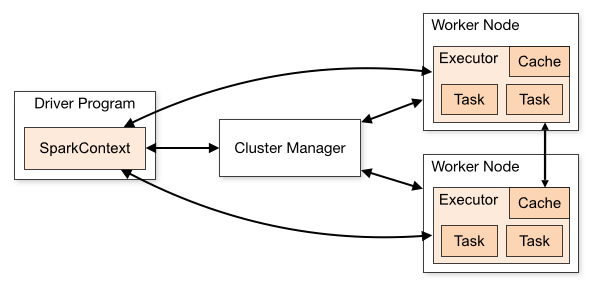
Job : 작업은 스파크에서 실행되는 작업 단위를 나타냅니다. 스파크 애플리케이션은 여러 작업으로 나뉠 수 있으며, 각 작업은 데이터를 처리하거나 연산을 수행하는 데 사용됩니다.
-
Stage : 단계는 스파크 작업의 실행 계획을 세분화하는 단위입니다. 각 단계는 단계 내에서 병렬로 실행될 수 있는 여러 태스크로 분할됩니다.
-
Task : 태스크는 스파크에서 데이터 처리 또는 연산을 수행하는 단위입니다. 각 태스크는 작업의 일부이며, 여러 태스크가 병렬로 실행됩니다.
-
Executor
- Executor는 스파크 애플리케이션에서 코드를 실행하는 프로세스입니다. 각 클러스터 노드에 하나 이상의 실행자가 있으며, 태스크를 실행하는 역할을 합니다. Driver와 직접적으로 명령을 주고받습니다.
- Executor는 드라이버를 대신하여 cluster manager에 의해 시작되며 작업 완료시 종료됩니다.
-
Driver : 드라이버는 스파크 애플리케이션의 주요 제어 프로세스입니다. 드라이버는 애플리케이션의 진행을 관리하고 실행자에게 작업을 할당합니다.
-
Slot : 슬롯은 실행자 내에서 태스크를 실행하는 데 사용되는 리소스의 단위입니다. 각 실행자에는 여러 개의 슬롯이 있으며, 병렬 처리를 지원합니다.
-
DataFrame : 데이터프레임은 스파크에서 구조화된 데이터를 처리하기 위한 데이터 구조입니다. 테이블과 유사한 형태로 데이터를 다루며, SQL 쿼리나 함수를 사용하여 데이터를 조작할 수 있습니다.
-
RDD (Resilient Distributed Dataset, 내구 분산 데이터 집합): RDD는 스파크에서 분산되어 저장되는 데이터의 추상화입니다. RDD는 장애 내성을 가지며, 데이터를 병렬로 처리하고 변환하는 데 사용됩니다. 다수의 노드에 걸쳐 분산되어 저장됩니다.
-
Partition : 파티션은 RDD나 데이터프레임과 같은 데이터 구조를 물리적으로 나누는 단위입니다. 각 파티션은 독립적으로 처리되며, 데이터를 분산 저장하고 병렬로 처리하는 데 도움이 됩니다.
-
Cluster manager : 클러스터 매니저는 Spark 애플리케이션을 실행하기 위한 클러스터 리소스를 관리하고 조절하는 역할을 수행합니다. Standalone, YARN, MESOS, Kubernetes 등이 있습니다.
-
Node manager : 노드 매니저는 클러스터 내의 각 머신(노드)에서 실행되며, 해당 머신의 리소스를 관리하고 Spark 애플리케이션의 작업을 실행하는 역할을 합니다.
- Spark 클러스터의 작업 수행 순서 및 각 특성들의 계층관계 등에 대해서는 아래 블로그에서 이해하기 쉽게 설명을 잘 해놓았습니다.
-> Spark의 구동방식 이해하기
-> Pyspark tutorial
2. Spark의 특성
-
Fault Tolerance : 장애 내성은 스파크가 데이터 또는 작업의 일부 손실에 대해 견딜 수 있는 능력을 나타냅니다. 스파크는 데이터의 복제와 재실행을 통해 장애 내성을 제공합니다.
-
Lazy Evaluation : 지연 평가는 스파크에서 데이터 처리 작업이 실제로 수행되기 직전까지 연기되는 특성을 의미합니다. 이는 효율적인 데이터 처리와 연산 최적화를 가능하게 합니다.
-
Adaptive Query Execution : 적응형 쿼리 실행은 스파크가 실행 중에 쿼리 실행 계획을 최적화하고 조정하는 기능을 나타냅니다. 이를 통해 쿼리 성능을 향상시키고 자원을 효율적으로 활용할 수 있습니다.
-
Action vs Transformation : 액션은 스파크에서 실제 결과를 생성하는 작업을 의미하며, Transformation은 데이터를 가공하거나 변경하는 중간 단계 작업을 나타냅니다.(Lazy Evaluation)
-
Narrow vs Wide Transformation : Narrow Transformation은 동일한 노드끼리 data의 공유 없이 파티션에서 데이터를 처리하는 변환을 나타내며, Wide Transformation은 여러 파티션 간에 데이터를 셔플링하여 처리하는 변환을 나타냅니다.
-
Shuffle
- 셔플링은 스파크에서 데이터를 다시 조합하고 재배치하는 과정을 의미합니다. 이는 Wide Transformation과 관련이 있으며 성능에 영향을 미칠 수 있습니다. 셔플되는 동안 spark는 데이터를 디스크에 씁니다. (디폴트 셔플 파티션은 200)
- Shuffle에는 정렬 프로세스가 포함되므로 shuffle중에는 파티션간 데이터가 이동/비교됩니다.
-
Broadcast
- 브로드캐스트는 작은 크기의 데이터를 클러스터의 모든 노드에 복제하여 효율적으로 공유하는 방법을 나타냅니다.
- 크기 차이가 많이 나는 dataframe끼리의 Join시 크기가 작은 dataframe을 broadcast해주어 더 효율적으로 처리가 가능하다.
-
Accumulator Variables
- Accumulator Variables는 스파크에서 여러 태스크에서 공유되는 변수로, 값을 누적하거나 집계하는 데 사용됩니다.
- Executor는 이 변수를 읽을 수 없고 오직 driver만 읽을 수 있습니다.
- Accumulator Variables를 포함하는 작업이 처음에 실패하고 spark가 작업을 다시 시작하여 성공하였다면 실패한 작업의 결과는 제외되고 성공시에만 Accumulator Variables에 포함된다.
-
Storage Levels : 저장 수준은 RDD나 데이터프레임이 디스크 또는 메모리에 저장되는 방식을 나타냅니다. 스파크는 다양한 저장 수준을 지원하여 성능을 최적화할 수 있습니다.
-
Deployment Modes : 배포 모드는 스파크 애플리케이션이 클러스터가 배포되는 방식을 나타냅니다.
- standalone, Apache YARN, Apache Mesos and Kubernetes.
-
Execution modes : 스파크 애플리케이션이 클러스터에서 어떻게 실행되는지를 나타내는 설정입니다.
- Client, Cluster, Local
-
Cluster Mode vs Client Mode (클러스터 모드 대 클라이언트 모드): 클러스터 모드는 스파크 애플리케이션을 클러스터 내에서 실행하는 모드를 나타내며, 클라이언트 모드는 로컬 머신에서 실행되며 클러스터에서 작업을 실행하는 모드를 나타냅니다.
-
Dynamic partition pruning :
- Dynamic partition pruning은 데이터베이스 또는 데이터 처리 시스템에서 사용되는 최적화 기술 중 하나로, 쿼리 실행 중에 필요한 파티션만 실제로 스캔하고 처리하는 방법을 나타냅니다. 이 기술을 사용하면 불필요한 데이터 파티션을 스캔하지 않고도 쿼리 실행 속도를 향상시킬 수 있습니다.
- 동적 파티션 가지치기는 주로 대용량 데이터베이스나 데이터 웨어하우스 시스템에서 사용되며, 데이터 파티션을 효율적으로 관리하여 쿼리 성능을 최적화하는 데 도움을 줍니다. 이 기술을 통해 데이터베이스나 데이터 처리 시스템은 필요한 파티션만 읽고 처리하여 작업을 가속화하고 자원을 절약할 수 있습니다.
-
Garbage collection : 프로그램이 실행 중에 사용하지 않는 메모리를 자동으로 식별하고 해제하는 프로세스를 의미합니다. 이를 통해 메모리 누수를 방지하고 시스템의 안정성과 성능을 향상시킵니다.
-
Dataset API vs DataFrame API : Scala programming에서는 Dataset API를 사용하며, 그 이외의 Python 같은 언어로 spark를 다룰때는 Dataset API를 기반으로 하는 DataFrame API를 사용합니다.
-
DAG(Directed Acyclic Graph) : DAG는 Spark의 워크로드 계층 구조(Job > Stage > Task)를 따릅니다. 이러한 작업 중 일부는 서로 의존하지 않기 때문에 병렬로 실행될 수 있습니다. DAG를 탐색하는 가장 좋은 방법은 Spark UI를 이용하는 것입니다.
3. 기타 설명
-
cache(), persist() 관련 설명 -> cache()와 persist()의 차이
-
sample() 관련 설명 -> Spark에서 sample() API 알고 쓰기
-
repartition() API는 실행시 full shuffle을 동반하며(Wide Transformation) 일반적으로 partition 개수를 늘릴때 사용하며, coalesce()는 suffle일 일어나지 않고(Narrow Transformation) partition 개수를 줄일때 사용한다.
-
Spark에서 RDD는 불변하는 특성이며 그 위에 구축된 DataFrame역시 변하지 않는다. 따라서 DataFrame 수정을 시도하면 Spark는 수정하는 대신 새로운 DataFrame을 생성한다.
4. 특정 코드 사용 패턴
-
transactionsDf.repartition(14, "storeId", "transactionDate").count()
-
DataFrame.sample(withReplacement=None, fraction=None, seed=None)
- withReplacement : True - 중복 있을 수 있음 / False - 중복X -
df.write.format("csv").mode("").save("경로")
-
transactionsDf.write.format("parquet").option("mode", "append").save(path)
-
transactionsDf.repartition(14, "storeId", "transactionDate").count()
-
transactionsDf.repartition(transactionsDf.rdd.getNumPartitions()+2)
-
spark.read.option("mergeSchema", "true").parquet(filePath)
-
spark.createDataFrame([(,), (,), (,)], [컬럼이름])
-
itemsDf.select("itemId", explode("attributes").alias("attribute"))
- explode는 select 내부에 위치 -
UDF register
def pow_5(x): if x: return x5 return x spark.udf.register('power_5_udf', pow_5, T.LongType()) spark.sql('SELECT power_5_udf(value) AS result FROM transactions') -
Union
- union : 컬럼 이름이 달라도 숫자가 같으면 무시하고 그냥 row append
- unionByName : 컬럼이름이 같으면 새로운 df에 append시키고 아니면 무시 -
transactionsDf.dropna(thresh=4)
- thresh > null이 아닌 값이 thresh의 숫자보다 적으면 drop한다.
- 예를들어 전체 컬럼이 10이고 thresh가 4면, 10개중에 1개(9개 null), 2개(8개 null), 3개(7개 null) 값만 있는 row들이 drop된다.

Spark Certified Associate 정보를 찾고 있었는데, 감사합니다~!