🌻구현 예정 리스트🌼
1. Argument Passing
2. User Memory Access
3. System Calls
4. Process Termination Message
5. Deny Write on Executables
📚참고도서📚
운영체제 아주 쉬운 세 가지 이야기 제1편 가상화
컴퓨터 시스템 8장 예외적인 제어 흐름
0. 들어가기에 앞서서
이번 과제는 프로그램이 시스템 콜(system call)을 통해 OS와 상호작용할 수 있도록 만들어야한다. USERPROG 영역에서 이루어지지만, 핀토스에 존재하는 거의 모든 요소와 상호 작용하게 된다. OS(는 커널)의 최상단(user program on top of the operating system)에서 작동하는 유저 프로그램을 실행하기 시작하면 더 이상 커널에 손쉽게 접근할 수 없다. 해당 과제에서는 하나 이상의 프로그램이 실행될 수 있도록 구현할 것이며, 각각의 프로세스들은 하나의 쓰레드를 갖는다.(멀티쓰레드 프로세스는 제외)
유저프로그램을 구현하기 위해서는 동기화(synchronization)와 가상 메모리(virtual memory)에 대한 이해가 선행되어야 한다.
1. 유저프로그램
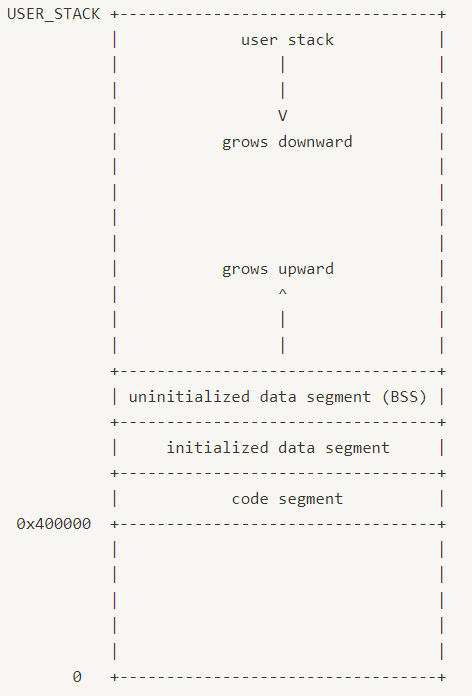
유저 프로그램은 자신의 유저 가상메모리에만 접근한다. 유저 프로그램이 커널 가상메모리에 접근하게 되면, page fault가 발생하고 프로세스가 종료된다. page fault는 userprog/execption.c에 있는 page_fault()라는 함수에 의해 이루어진다.
커널 프로그램은 커널 가상 메모리에 접근 가능하며, 유저 프로세스가 running 상태라면 이 유저 프로세스의 유저 가상메모리에 접근할 수 있다. 그러나, 커널에서 매핑되지 않은 유저 가상 주소 메모리에 접근한다면 page fault가 발생한다.
유저 가상메모리는 아래와 같은 레이아웃을 갖는다.
2. Argument Passing 인자 전달
유닉스 64비트 x86-64 구현에 있는 몇 가지 중요한 호출 규약들은 다음과 같다.
- 유저-레벨 어플리케이션은
%rdi,%rsi,%rdx,%rcx,%r8,%r9시퀀스들을 전달하기 위해 정수 레지스터를 사용합니다. - 호출자는 다음 인스트럭션의 주소(리턴 어드레스)를 스택에 푸시하고, 피호출자의 첫번째 인스트럭션으로 점프합니다.
CALL이라는 x86-64 인스트럭션 하나가 이 두 가지를 모두 수행합니다. - 피호출자가 실행됩니다.
- 만약 피호출자가 리턴 값을 가지고 있다면, 리턴 값은 레지스터 RAX에 저장됩니다.
- 피호출자는 x86-64 인스트럭션인
RET를 사용해서, 스택에 받았던 리턴 어드레스를 pop하고 그 주소가 가리키는 곳으로 점프함으로써 리턴됩니다.
1.인자 전달을 구현하기 위해 Tokenize 작업을 해주고, argv에 넣어주어야한다.
// Tokenize & put them to argv
char *token, *save_ptr;
char *argv[40];
int argc = 0;
if (strchr(file_name, ' '))
{
for (token = strtok_r (file_name, " ", &save_ptr); token != NULL; token = strtok_r (NULL, " ", &save_ptr)){
argv[argc] = token;
argc++;
}
}
else
{
argv[argc] = file_name;
argc++;
}
2.이 단어들을 스택의 맨 처음 부분에 놓고 순서는 상관 없다. 왜냐면 포인터에 의해 참조될 예정이기 때문이다!
size_t sum = 0;
char *argv_address[40];
for(int i = argc-1; i >= 0; i--) {
size_t len = strlen(argv[i]) + 1; // '\0' 포함
sum += len;
argv_address[i] = (if_->rsp - sum);
memcpy((if_->rsp - sum), argv[i], len);
}3.각 문자열의 주소 + 경계조건을 위한 널포인터를 스택에 오른쪽→왼쪽 순서로 푸시한다. 이들은 argv_address의 원소가 된다. 널포인터 경계는 argv_address[argc] 가 C언어 표준의 요구사항에 맞춰서 널포인터라는 사실을 보장해준다. 그리고 이 순서는 argv_address[0]이 가장 낮은 가상 주소를 가진다는 사실을 보장해준다. 또한 word 크기에 정렬된 접근이 정렬되지 않은 접근보다 빠르므로, 최고의 성능을 위해서는 스택에 첫 푸시가 발생하기 전에 스택포인터를 8의 배수로 반올림하여야 한다.
// Word-Align
while((if_->rsp - sum) % 8 != 0){
sum++;
*(uint8_t *) (if_->rsp - sum) = 0;
}
//Push the address of each string plus a null pointer sentinel
for (int i = argc; i >=0 ; i--){
sum += 8;
if (i == argc)
memset(if_->rsp - sum, 0, sizeof(char **));
else
memcpy(if_->rsp - sum, &argv_address[i], sizeof(char **));
}%rsi가argv_address주소(argv_address[0]의 주소)를 가리키게 하고,%rdi를argc로 설정한다.
if_->rsp -= sum;
if_->R.rdi = argc;
if_->R.rsi = if_->rsp;- 마지막으로 가짜 “리턴 어드레스”를 푸시한다 : entry 함수는 절대 리턴되지 않겠지만, 해당 스택 프레임은 다른 스택 프레임들과 같은 구조를 가져야 한다.
memset(if_->rsp - 8, 0, sizeof(void *));2. User Memory Access 유저 메모리 접근
시스템 콜 기능을 구현하기 이전에, 만약 유저가 유저에게 할당되지 않은 메모리에 접근하려하거나 커널 영역에 직접 접근하려고 한다면 유저 프로세스를 종료시켜야 할 것이다.
먼저, 시스템 콜을 통해 받은 인자의 포인터가 유효한 지 체크해야 한다. 예를 들어, 커널 메모리를 가리키는 포인터라던가, 블록의 일부가 이런 영역들 중 하나의 블록을 가리키는 포인터라면, 유저 프로세스를 종료시켜야한다.
if (!(filename // 유효한 filenamee인가?
&& is_user_vaddr(filename) // 가상주소 공간이 유저의 가상주소 공간인가?
&& pml4_get_page(curr->pml4, filename))) // 유저 주소가 올바르게 매핑되었는가?
{
curr->my_exit_code = -1;
thread_exit();
}3. System Calls 시스템콜
이전 프로젝트를 통해서, 운영체제가 유저 프로그램에게서 제어권을 되찾아가는 방법을 배웠다. 타이머와 I/O 디바이스들로부터의 인터럽트들(외부 인터럽트)들이 바로 그 것이다. 운영체제는 프로그램 코드에서 발생하는 이벤트인 SW exception도 다룬다. 예를 들어, page fault, division by zero가 이에 해당한다. 또한 시스템콜이라는 서비스 또한 SW exception에 해당한다.
시스템 콜 핸들러(syscall_handler)가 제어권을 얻으면 시스템 콜 번호는 rax에 있고, 시스템 콜을 호출한 콜러의 레지스터는 전달받은 struct intr_frame(커널스택에 존재)에 접근한다.
- halt
halt는 return 값이 존재하지 않는다. power_off()를 호출해 Pintos를 종료하면 된다.
case SYS_HALT:
sys_halt_handler();
break;void
sys_halt_handler(){
power_off();
}- exit
현재 동작 중인 유저 프로그램을 종료한다. 커널에 상태를 return하면서 종료한다. 만약, 부모 프로세스가 현재 유저 프로그램의 종료를 기다리던 중이라면, 종료되면서 리턴될 그 상태를 기다리는 것을 의미한다. 관례적으로 상태 = 0은 성공을 뜻 하고 그 외는 에러를 의미한다.
case SYS_EXIT:
sys_exit_handler(f->R.rdi);
break;void
sys_exit_handler(int arg1){
thread_current()->my_exit_code = arg1;
thread_exit();
}- fork
THREAD_NAME이라는 이름을 가진 현재 프로세스의 복제본인 새 프로세스를 만든다. 자식 프로세스의 pid를 반환해야 하며 그렇지 않으면 유효한 pid가 아닐 수 있다. 자식 프로세스에서 반환 값은 0이어야 한다. 자식 프로세스에는 파일 식별자 및 가상 메모리 공간을 포함한 복제된 리소스가 있어야 한다. 부모 프로세스는 자식 프로세스가 성공적으로 복제되었는지 여부를 알 때까지 fork에서 반환해서는 안된다. 즉, 자식 프로세스가 리소스를 복제하지 못하면 부모의 fork() 호출이 TID_ERROR를 반환할 것이다.
case SYS_FORK:
f->R.rax = sys_fork_handler(f->R.rdi, f);
break;int sys_fork_handler(char *thread_name, struct intr_frame *f){
return process_fork(thread_name, f);
}tid_t
process_fork (const char *name, struct intr_frame *if_) {
/* Clone current thread to new thread.*/
struct semaphore dup_sema;
struct thread *p_thread = thread_current();
void *arr[3] = {p_thread, if_, &dup_sema};
tid_t child_pid;
sema_init(&dup_sema, 0);
child_pid = thread_create(name, PRI_DEFAULT, __do_fork, arr);
if (child_pid != TID_ERROR)
{
sema_down(&dup_sema);
if (p_thread -> exit_check == true){
return -1;
}
return child_pid;
}else{
return child_pid;
}
}static void
__do_fork (void **aux) {
// struct intr_frame if_;
struct thread *parent = (struct thread *)aux[0];
struct thread *current = thread_current();
struct intr_frame if_ = current->tf;
struct intr_frame *parent_if = (struct intr_frame *)aux[1];
struct semaphore *dup_sema = (struct semaphore *)aux[2];
bool succ = true;
/* 1. Read the cpu context to local stack. */
memcpy (&if_, parent_if, sizeof (struct intr_frame));
/* 2. Duplicate PT */
current->pml4 = pml4_create();
if (current->pml4 == NULL){
goto error;
}
process_activate (current);
#ifdef VM
supplemental_page_table_init (¤t->spt);
if (!supplemental_page_table_copy (¤t->spt, &parent->spt))
goto error;
#else
if (!pml4_for_each (parent->pml4, duplicate_pte, parent)){
goto error;
}
#endif
for (int fd = FDBASE; fd < FDLIMIT; fd++){
if (parent->fd_table[fd]){
current->fd_table[fd] = file_duplicate(parent->fd_table[fd]);
}else{
current->fd_table[fd] = NULL;
}
}
if_.R.rax = 0;
process_init();
/* Finally, switch to the newly created process. */
if (succ){
sema_up(dup_sema);
do_iret(&if_);
}
error:
sema_up(dup_sema);
current->my_exit_code = -1;
parent->abc = true;
thread_exit();
}
fork를 위해 thread 구조체에 멤버를 추가해준다.
struct child_info{
bool finished;
tid_t c_tid;
int c_exit_code;
struct list_elem c_elem;
struct semaphore c_sema;
};
struct thread
{
/* Owned by thread.c. */
tid_t tid; /* Thread identifier. */
enum thread_status status; /* Thread state. 4가지 : ready, blocked, running, dying*/
char name[16]; /* Name (for debugging purposes). */
int my_exit_code;
int priority; /* Priority. */
int init_priority;
bool exit_check;
int64_t wakeup_tick; /* Shared between thread.c and synch.c. */
struct lock* wait_on_lock;
struct thread *my_parent;
struct file *my_file;
struct child_info *my_info;
struct file* fd_table[FDLIMIT]; /* file descriptor(fd) table */
struct list_elem donation_elem;
struct list_elem elem; /* List element. */
struct list child_list;
struct list donations;- exec
현재 프로세스가 cmd_line에서 이름이 주어지는 실행간으한 프로세스로 변경된다. 성공적으로 진행된다면 어떤 것도 반환되지 않는다. 만약 프로세스를 로드하지 못 하거나, 다른 이유로 진행하지 못 하게 된다면 exit status를 -1로 반환하며 프로세스를 종료한다.
case SYS_EXEC:
sys_exec_handler(f->R.rdi);
break;int sys_exec_handler(char * cmd_line){
struct thread *curr = thread_current();
if (!(cmd_line
&& is_user_vaddr(cmd_line)
&& pml4_get_page(curr->pml4, cmd_line)))
{
curr->my_exit_code = -1;
thread_exit();
}
char *fn_copy = palloc_get_page (0);
strlcpy (fn_copy, cmd_line, PGSIZE);
return process_exec(fn_copy);
}int
process_exec (void *f_name) {
char *file_name = f_name;
bool success;
/* We cannot use the intr_frame in the thread structure.
* This is because when current thread rescheduled,
* it stores the execution information to the member. */
struct intr_frame _if;
_if.ds = _if.es = _if.ss = SEL_UDSEG;
_if.cs = SEL_UCSEG;
_if.eflags = FLAG_IF | FLAG_MBS;
/* We first kill the current context */
process_cleanup();
lock_acquire(&filesys_lock);
/* And then load the binary */
success = load (file_name, &_if);
/* If load failed, quit. */
lock_release(&filesys_lock);
palloc_free_page (file_name);
if (!success)
return -1;
/* Start switched process. */
do_iret (&_if);
NOT_REACHED ();
}-
wait
자식 프로세스(pid)를 기다리며 자식의 종료 상태(exit status)를 가져온다. 만약 자식 프로세스가 아직 살아있다면 종료될 때까지 기다린다. 종료가 되면 그 프로세스가 exit 함수로 전달해준 상태를 반환한다.만약, 자식 프로세스가 exit() 함수를 호출하지 못 하고 커널에 의해 종료된다면, wait(pid)는 -1을 반환해야 한다.
case SYS_WAIT:
f->R.rax = sys_wait_handler(f->R.rdi);
break;int sys_wait_handler(int pid){
return process_wait(pid);
}int
process_wait (tid_t child_tid) {
int result;
struct thread *curr = thread_current();
struct list_elem *child_elem = list_begin(&curr->child_list);
struct child_info *c_info;
while (child_elem != list_end(&curr->child_list))
{
c_info = list_entry(child_elem, struct child_info, c_elem);
if(c_info->c_tid == child_tid){
while(!c_info->finished){
sema_down(&c_info->c_sema);
}
result = c_info->c_exit_code;
list_remove(child_elem);
free(c_info);
c_info == NULL;
return result;
}
child_elem = list_next(child_elem);
}
return -1;
}- create
create 함수는 file(첫 번째 인자)를 이름으로 하고 크기가 initial_size(두 번째 인자)인 새로운 파일을 생성한다. 성공적으로 파일이 생성되었다면 true를 반환하고, 실패했다면 false를 반환한다. 새로운 파일을 생성하는 것이 그 파일을 여는 것을 의미하지는 않는다: 파일을 여는 것은 open 시스템콜의 역할로, ‘생성’과 개별적인 연산이다.
case SYS_CREATE:
f->R.rax = sys_create_handler(f->R.rdi, f->R.rsi);
break;int sys_open_handler(char *filename){
struct thread *curr = thread_current();
if (!(filename
&& is_user_vaddr(filename)
&& pml4_get_page(curr->pml4, filename)))
{
curr->my_exit_code = -1;
thread_exit();
}
lock_acquire(&filesys_lock);
struct file *file = filesys_open(filename);
lock_release(&filesys_lock);
if (!file)
return -1;
struct file **f_table = curr->fd_table;
int i = FDBASE;
for (i; i < FDLIMIT; i++)
{
if (f_table[i] == NULL){
f_table[i] = file;
return i;
}
}
lock_acquire(&filesys_lock);
file_close(file);
lock_release(&filesys_lock);
return -1;
}- remove
remove 함수는 file(첫 번째)라는 이름을 가진 파일을 삭제한다. 성공적으로 삭제했다면 true를 반환하고, 그렇지 않으면 false를 반환한다. 파일은 열려있는지 닫혀있는지 여부와 관계없이 삭제될 수 있고, 파일을 삭제하는 것이 그 파일을 닫았다는 것을 의미하지는 않는다.
case SYS_REMOVE:
f->R.rax = sys_remove_handler(f->R.rdi);
break;bool sys_remove_handler(char *filename){
bool result;
lock_acquire(&filesys_lock);
result = filesys_remove(filename);
lock_release(&filesys_lock);
return result;
}-
open
open 함수는 file(첫 번째 인자)이라는 이름을 가진 파일을 연다. 해당 파일이 성공적으로 열렸다면, 파일 식별자로 불리는 비음수 정수(0또는 양수)를 반환하고, 실패했다면 -1를 반환한다. 0번 파일식별자와 1번 파일식별자는 이미 역할이 지정되어 있으며, 0번은 표준 입력(STDIN_FILENO)을 의미하고 1번은 표준 출력(STDOUT_FILENO)을 의미한다.open 시스템 콜은 아래에서 명시적으로 설명하는 것처럼 시스템 콜 인자로서만 유효한 파일 식별자들을 반환하지 않는다. 각각의 프로세스는 독립적인 파일 식별자들을 갖는다. 파일 식별자는 자식 프로세스들에게 상속(전달)된다. 하나의 프로세스에 의해서든 다른 여러개의 프로세스에 의해서든, 하나의 파일이 두 번 이상 열리면 그때마다 open 시스템콜은 새로운 식별자를 반환한다.
하나의 파일을 위한 서로 다른 파일 식별자들은 개별적인 close 호출에 의해서 독립적으로 닫히고 그 한 파일의 위치를 공유하지 않는다.
case SYS_OPEN:
f->R.rax = sys_open_handler(f->R.rdi);
break;int sys_open_handler(char *filename){
// return -1;
struct thread *curr = thread_current();
if (!(filename
&& is_user_vaddr(filename)
&& pml4_get_page(curr->pml4, filename)))
{
curr->my_exit_code = -1;
thread_exit();
}
lock_acquire(&filesys_lock);
struct file *file = filesys_open(filename);
lock_release(&filesys_lock);
if (!file)
return -1;
struct file **f_table = curr->fd_table;
int i = FDBASE;
for (i; i < FDLIMIT; i++)
{
if (f_table[i] == NULL){
f_table[i] = file;
return i;
}
}
lock_acquire(&filesys_lock);
file_close(file);
lock_release(&filesys_lock);
return -1;
}- filesize
filesize 함수는 fd(첫 번째 인자)로서 열려 있는 파일의 크기가 몇 바이트인지 반환한다.
case SYS_FILESIZE:
f->R.rax = sys_filesize_handler(f->R.rdi);
break;int sys_filesize_handler(int fd){
int result;
struct thread *curr = thread_current();
struct file **f_table = curr->fd_table;
struct file *f = f_table[fd];
lock_acquire(&filesys_lock);
result = file_length(f);
lock_release(&filesys_lock);
return result;
}- read
buffer 안에 fd 로 열려있는 파일로부터 size 바이트를 읽는다. 실제로 읽어낸 바이트의 수를 반환한다 (파일 끝에서 시도하면 0). 파일이 읽어질 수 없었다면 -1을 반환한다.(파일 끝이라서가 아닌 다른 조건에 때문에 못 읽은 경우)
case SYS_READ:
f->R.rax = sys_read_handler(f->R.rdi, f->R.rsi, f->R.rdx);
break;int sys_read_handler(int fd, void* buffer, unsigned size){
struct thread *curr = thread_current();
int result;
if (fd < FDBASE || fd >= FDLIMIT || curr->fd_table[fd] == NULL || buffer == NULL || is_kernel_vaddr(buffer) || !pml4_get_page(curr->pml4, buffer))
{
thread_current()->my_exit_code = -1;
thread_exit();
}
struct file *f = curr->fd_table[fd];
lock_acquire(&filesys_lock);
result = file_read(f, buffer, size);
lock_release(&filesys_lock);
return result;
}-
write
buffer로부터 open file fd로 size 바이트를 적어준다. 실제로 적힌 바이트의 수를 반환해주고, 일부 바이트가 적히지 못했다면 size보다 더 작은 바이트 수가 반환될 수 있다.이로 인해 파일의 끝까지 최대한 많은 바이트를 적어주고 실제 적힌 수를 반환하거나, 더 이상 바이트를 적을 수 없다면 0을 반환한다. fd 1은 콘솔에 적어준다. 콘솔에 작성한 코드가 적어도 몇 백 바이트를 넘지 않는 사이즈라면, 한 번의 호출에 있는 모든 버퍼를 putbuf()에 적어주는 것이다.(더 큰 버퍼는 분해하는 것이 합리적이다!!)
case SYS_WRITE:
f->R.rax = sys_write_handler(f->R.rdi, f->R.rsi, f->R.rdx);
break;int sys_write_handler(int fd, void *buffer, unsigned size){
struct thread *curr = thread_current();
int result;
if (fd == 1)
{
putbuf(buffer, size);
return size;
}
if (fd < FDBASE || fd >= FDLIMIT || curr->fd_table[fd] == NULL || buffer == NULL || is_kernel_vaddr(buffer) || !pml4_get_page(curr->pml4, buffer))
{
curr->my_exit_code = -1;
thread_exit();
}
struct file *f = curr->fd_table[fd];
lock_acquire(&filesys_lock);
result = file_write(f, buffer, size);
lock_release(&filesys_lock);
return result;
}- seek
open file fd에서 읽거나 쓸 다음 바이트를 position으로 변경한다. position은 파일 시작부터 바이트 단위로 표시된다. (따라서 position 0은 파일의 시작을 의미한다). 이후에 read를 실행하면 파일의 끝을 가리키는 0바이트를 얻는다. 이후에 write를 실행하면 파일이 확장되어 기록되지 않은 공백이 0으로 채워진다.
case SYS_SEEK:
sys_seek_handler(f->R.rdi,f->R.rsi);
break;void
sys_seek_handler(int fd, unsigned position){
struct thread *curr = thread_current ();
struct file **f_table = curr->fd_table;
if (fd < FDBASE || fd >= FDLIMIT || curr->fd_table[fd] == NULL) {
curr->my_exit_code = -1;
thread_exit();
}
struct file *f = f_table[fd];
lock_acquire(&filesys_lock);
file_seek(f, position);
lock_release(&filesys_lock);
}- close
파일 식별자 fd를 닫는다. 프로세스를 나가거나 종료하는 것은 묵시적으로 그 프로세스의 열려있는 파일 식별자들을 닫는 것이다. 마치 각 파일 식별자에 대해 이 함수가 호출된 것과 같다.
case SYS_CLOSE:
f->R.rax = sys_close_handler(f->R.rdi);
break;int sys_close_handler(int fd){
struct file **f_table = thread_current()->fd_table;
if (fd < FDBASE || fd >= FDLIMIT){
thread_current()->my_exit_code = -1;
thread_exit();
}
else if (f_table[fd]){
lock_acquire(&filesys_lock);
file_close(f_table[fd]);
lock_release(&filesys_lock);
f_table[fd] = NULL;
}
else{
thread_current()->my_exit_code = -1;
thread_exit();
}
}참고하면 좋을 블로그.
https://velog.io/@rivolt0421/Pintos-2.-UserPrograms (고마워요!!)
