'운영체제 아주 쉬운 세 가지 이야기' 제2편 병행성을 바탕으로 작성하였습니다👏
(아래 질문에 답할 수 있다면 패스하셔도 좋습니다.👏👏)
-
프로세스와 쓰레드의 차이를 설명할 수 있다.
-
왜 쓰레드를 사용할까요?
-
데이터 경쟁(data race)을 해결하는 방법은?
-
동기화 함수(synchronization primitives)를 설명할 수 있다.
📚참고도서📚

🌻들어가기 전🌼
왜 운영체제에서 이런 걸 배울까요? 운영체제는 최초의 병행 프로그램으로 "역사"입니다!
1. 쓰레드와 프로세스
프로그램에서 한 순간에 하나의 명령어만을 실행하는 고전적인 관점에서 벗어나 멀티 쓰레드 프로그램은 하나 이상의 실행 지점을 갖는다. 쓰레드는 프로세스와 유사하지만, 차이가 있다면 쓰레드들은 주소 공간을 공유하기 때문에 동일한 값에 접근할 수 있다.
👨💻문맥교환(context switch)👨💻 : 두 개의 쓰레드가 하나의 프로세서에서 실행 중이라면 실행하고자 하는 쓰레드는 반드시 문맥 교환을 통해 교체되어야한다.
프로세스가 문맥 교환을 할 때에 프로세스의 상태를 프로세스 제어 블럭(PCB)에 저장하듯이 쓰레드들의 상태를 저장하기 위해서는 쓰레드 제어 블럭(TCB)이 필요하다.
쓰레드와 프로세스의 또 다른 차이는 스택에 있다. 고전적 프로세스 주소 공간과 같은 간단한 모델(단일 쓰레드 프로세스)에서는 스택이 하나만 존재한다. 그림과 같이 주소 공간 하부에 위치한다.
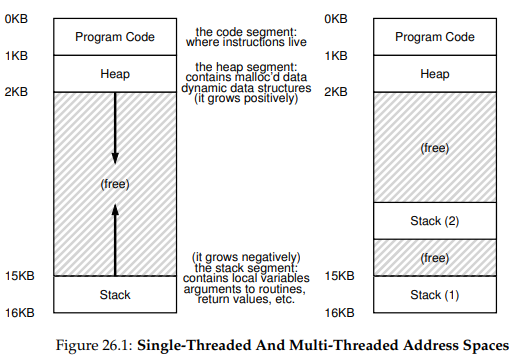
멀티 쓰레드 프로세스의 경우, 각 쓰레드가 독립적으로 실행되며 주소 공간에는 하나의 스택이 아니라 쓰레드마다 스택이 할당되어 있다.
2. 왜 쓰레드를 사용할까요?
🌻이유🌼 : (1)병렬 처리 (2)자연스러운 진행
첫 번째 병렬 처리란 무엇일까? 만약, 단일 프로세서라면 작업을 실행할 때 각 작업을 하나씩 수행하고 종료한다. 만약 멀티 프로세서 시스템이라면, 각 프로세서가 작업의 일부분을 수행하여 실행 속도를 상당히 높힌다. 표준 단일 쓰레드 프로그램을 멀티프로세서상에서 같은 작업을 하는 프로그램으로 바꾸는 것을 병렬화(parallelization)라고 한다.
두 번째 막힘 없는 진행, 느린 I/O로 인해 프로그램이 실행이 멈추지 않도록 쓰레드를 사용한다. 다른 종류의 I/O가 발생할 때, 우리는 기다리는 대신 다른 작업을 수행한다. CPU 스케줄러는 다른 쓰레드로 전환시켜, 쓰레드를 사용하면 자연스레 진행할 수 있다. 쓰레딩은 하나의 프로그램 안에서 I/O와 다른 작업이 중첩(overlap)될 수 있게 한다.
3. 데이터 경쟁(data race)
명령어의 실행 순서에 따라 결과가 달라지는 상황을 경쟁 조건(race condition) 혹은 더 구체적으로 데이터 경쟁(data race)이라고 부른다.
컴퓨터는 우리의 예상과 다르게, 일반적으로 발생하는 결정적 결과와 달리 결과가 어떠할 지 알지 못 하거나 실행할 때마다 결과가 다른 경우를 비결정적(indeterminate) 결과라고 부른다.
멀티 쓰레드가 같은 코드를 실행할 때 경쟁 조건이 발생하기 때문에 이러한 코드 부분을 임계 영역(critical section)이라고 부른다. 공유 변수를 접근하고 하나 이상의 쓰레드에서 동시에 실행되면 안되는 코드를 다룰 때 임계 영역을 지정한다.
이러한 코드에서 필요한 것은 상호배제(mutual exclusion)다. 상호 배제를 통해 하나의 쓰레드가 임계 영역 내의 코드를 실행 중일 때는 다른 스레드가 실행할 수 없도록 보장해준다.
4. 동기화 함수
🌻임계 영역을 해결할 강력한 방법?🌼
다음과 같은 강력한 명령어가 있다고 해보자
memory-add 0x8049a1c, 0x1이 명령어는 메모리 상의 위치에 어떤 값을 더하는 명령어다. 하드웨어가 이 명령어가 원자적으로 실행된다는 것을 보장한다면 명령어 수행 도중에 인터럽트가 발생하지 않는다. 우리는 이런 일을 할 동기화 함수(synchronization primitives)를 구현하면 된다.
