
인덱스(Index)란?
인덱스는 데이터베이스에서 검색 속도를 높이기 위해서 사용하는 자료구조이다.
저장한 데이터를 특정 열에 추가적인 구조를 만들고, 원하는 데이터를 빠르게 찾을 수 있다.
인덱스의 비유를 들어보자면,
책이 있고 그 안에 책의 목차가 있다. 목차를 이용하여 책 안의 특정 정보에 대해 빠르게 찾을 수 있다.
장점
- 검색 속도 향상
테이블 전체를 검색할 필요 없이 트리 자료 구조를 통해서 필요한 데이터를 빠르게 찾을 수 있다. - 정렬 성능 향상
기본적으로 정렬된 상태로 데이터를 저장하기 때문에 추가적인 정렬 기능 없이도 효율적으로 정렬된 결과를 반환할 수 있다. - 조인 최적화
테이블 간의 조인을 수행할 때 인덱스를 사용하여 조인 조건에 만족하는 데이터를 빠르게 찾을 수 있다.
인덱스 자료구조
인덱스의 자료구조는 대표적으로 B+Tree가 있다.
B+Tree에 대해 알아보기 전에,
지금 참고하고 있는 책에는 대표적인 자료구조가 B-Tree로 나온다. 하지만? 다른 블로그 글들을 찾아보면 B+Tree라고 설명하는 글이 많다.
B-Tree는 뭘까?
B-Tree
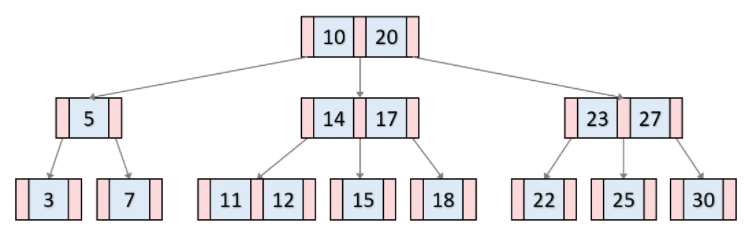
- 이어져있는 노드들이 정렬된 상태
- 일반적인 이진트리와 달리 자식 노드가 두 개 이상이 가능하다.
- 균형이진트리 (앞부터 꽉꽉 채우고 가는 것...)
만약 내가 18번 인덱스를 찾고 싶다? 하면 아래와 같은 과정을 거친다.
- 루트 노드에서 시작
10과 20 사이이므로 10과 20 사이 자식 노드로 이동 - 두 번째 레벨 노드 탐색
17보다 크므로 17의 오른쪽 자식 노드로 이동 - 세 번째 레벨 노드 탐색
18번 인덱스 찾음
B-Tree는 탐색을 하기 위해서 노드를 찾아 이동해야 한다는 단점이 있다.
이를 보완해서 나온 것이 B+Tree이다.
B+Tree
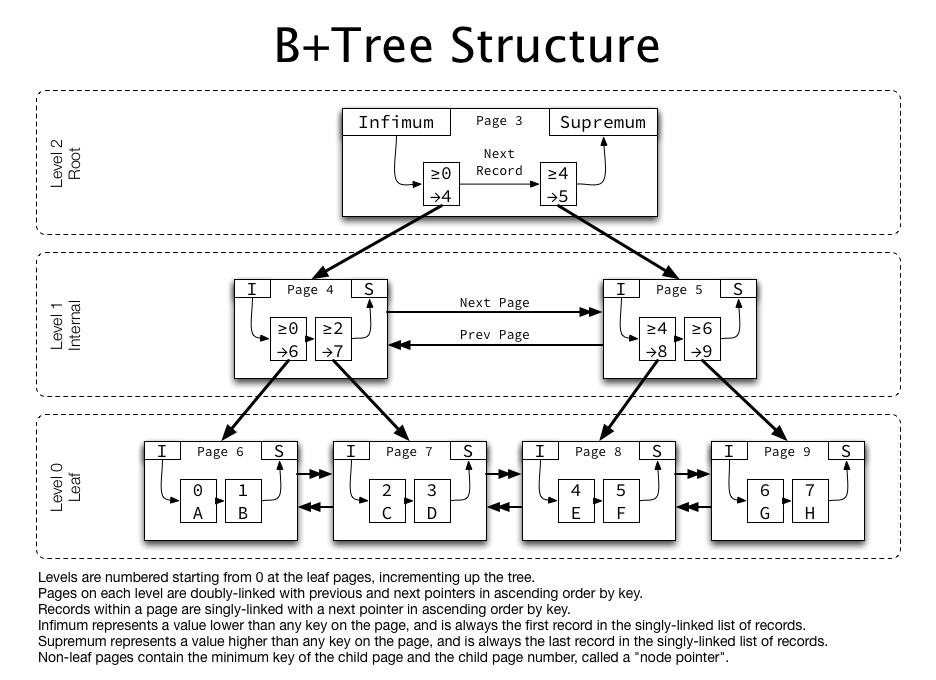
- 리프 노드의 값들이 다 정렬이 되어 있고, 그 노드들이 연결리스트로 형태이다.
- 리프 노드가 아닌 것들은 인덱스 노드, 리프 노드는 데이터 노드라고 부른다.
- 반드시 리프 노드까지 내려가야 데이터를 찾을 수 있다.
만약 내가 4번 인덱스를 찾고 싶다? 하면 아래와 같은 과정을 거친다.
- 루트 노드에서 시작
4와 같으므로 오른쪽 노드, page 5로 이동 - 두 번째 레벨 노드 탐색
4와 같으므로 왼쪽 노드, page 8로 이동 - 세 번째 레벨 노드 탐색
4 찾음
여기까지 보면 B-Tree와 무엇이 다른지 의문점이 든다.
결국 루트 노드에서 리프 노드까지 내려가는 건데...?
심지어 B-Tree는 리프 노드까지 안 내려가는 경우도 생긴다.
B+Tree는 단순 검색에서 효율이 나오는 것이 아니다.
리프 노드가 연결 리스트로 되어 있기 때문에 범위 검색과 순차적 접근을 할 때 매우 효율적으로 처리가 가능하다.
만약, WHERE column BETWEEN 4 AND 7 쿼리가 동작한다고 해보자
- B-Tree
4 인덱스를 루트 노드에서 내려오면서 찾은 뒤 5, 6, 7 인덱스를 찾을 때마다 처음부터 트리를 다시 돌아야 한다. - B+Tree
4 인덱스를 루트 노드에서 내려오면서 찾은 뒤 트리를 처음부터 검색할 필요 없이 연결 리스트를 이용해서 순차적으로 접근이 가능하다.
사진을 통해서 보면 오른쪽으로 쭉쭉 이동만 해주면 되는 것
B+Tree가 무조건 리프 노드까지 내려가야 하지만 B-Tree보다 효율적이다.
그래서 B+Tree가 MySQL, PostgreSQL, InnoDB 등 대규모 데이터베이스에서 사용된다!
🦴 참고
https://velog.io/@alicesykim95/DB-%EC%9D%B8%EB%8D%B1%EC%8A%A4Index%EB%9E%80
https://ssocoit.tistory.com/217
