
데이터베이스는 기본적으로 서버와 스토리지가 1:1로 구성되어 작동한다.
이 구조는 단순하고 관리가 쉬운 장점이 있지만, 다음과 같은 한계를 가질 수 있다.
- 대규모 트랜잭션 처리 한계
대규모 DB 서버에서 다수의 사용자 요청(트랜잭션)을 동시에 처리를 못 한다. - 데이터 손실 위험
스토리지가 손상되거나 서버가 다운되면 데이터에 접근할 수 없게 된다.
이런 문제를 해결하기 위해서 데이터베이스는 아래와 같은 특성을 꼭 갖춰야 한다.
- 고성능
사용자의 요청에 대해 빠르고 안정적인 응답을 제공해야 한다. - 고가용성
데이터베이스는 항상 접근 가능해야 하며, 장애가 발생하더라도 서비스가 중단되면 안된다. - 확장성
데이터와 사용자가 폭발적으로 증가해도 이를 효율적으로 처리할 수 있는 구조가 필요하다.
위 세 가지를 충족시키기 위해서 나온 서버-스토리지 구성 기술이 클러스터링과 리플리케이션이다.
클러스터링 (Clustering)
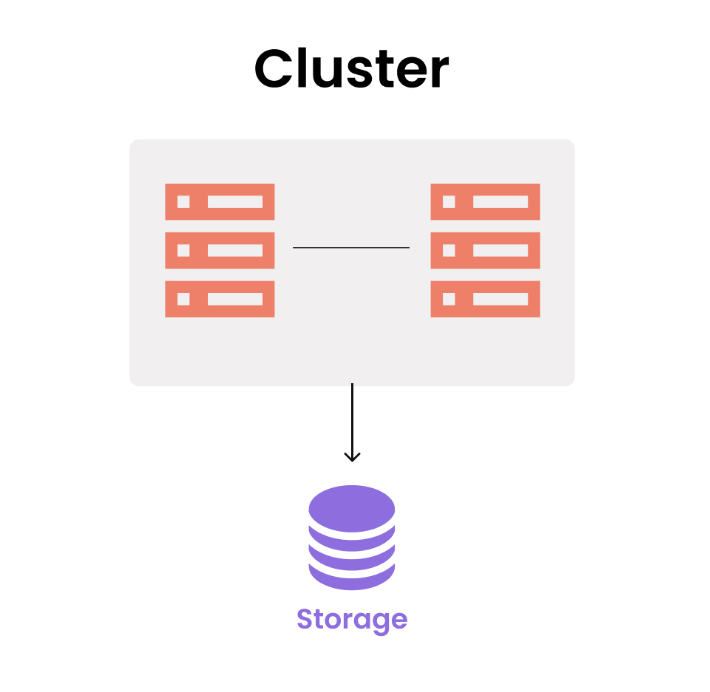
여러 개의 데이터베이스 서버를 수평적인 구조로 구축하고 하나의 스토리지를 나눠서 처리하는 방식이다.
클러스터링은 두 가지 방식으로 나뉜다.
Active-Active 방식
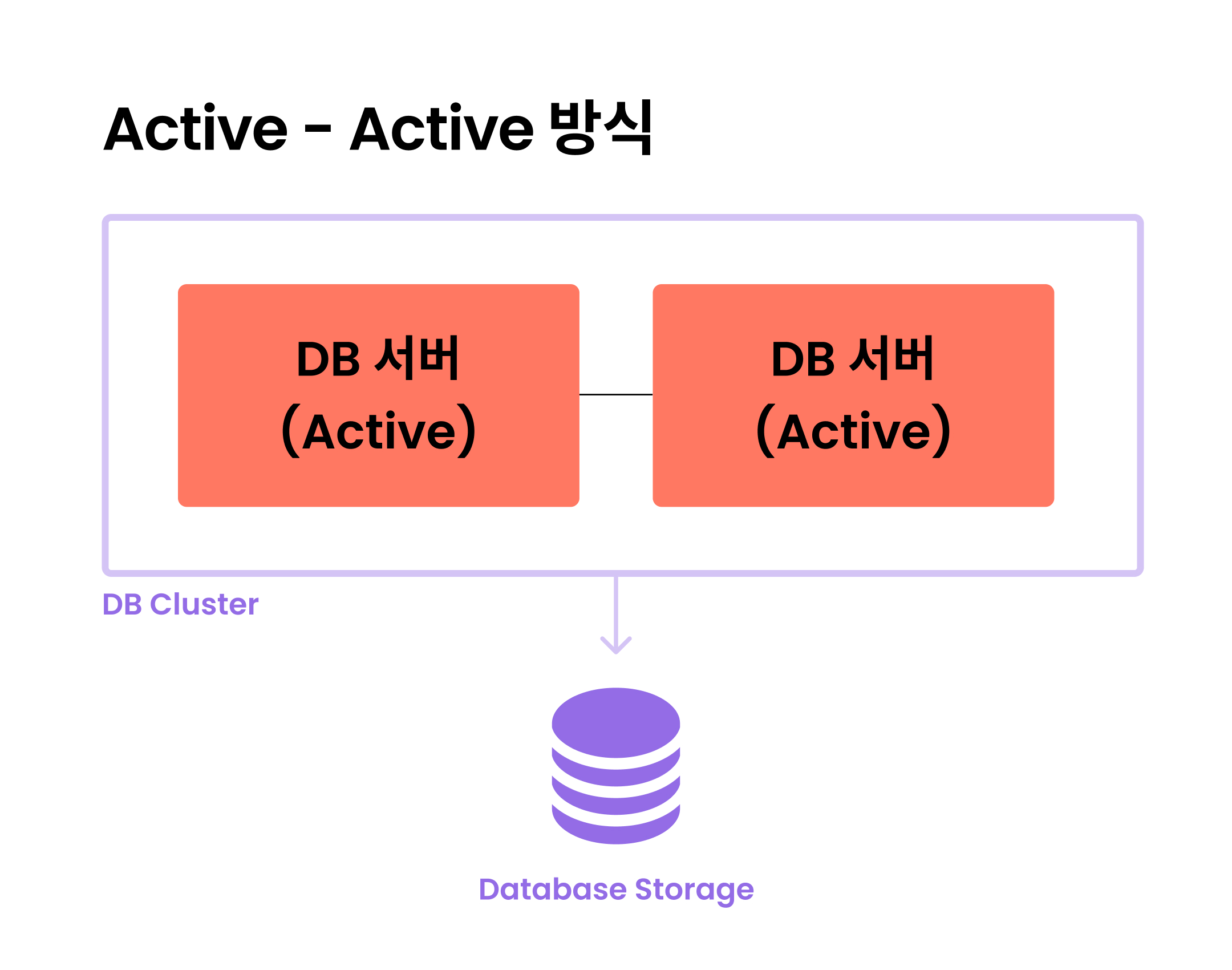
- 여러 서버가 동시에 데이터 읽기/쓰기 작업을 처리한다.
- 하나의 서버가 중단되더라도 바로 다른 서버가 작동할 수 있다.
- 서버가 여러 개 동작하므로 CPU, 메모리 등의 성능이 향상된다.
- 스토리지를 공유하기 때문에 데이터 충돌 현상이 발생할 수 있다.
- 다수의 서버를 운영하므로 비용 부담이 크다.
Active-Stand By 방식
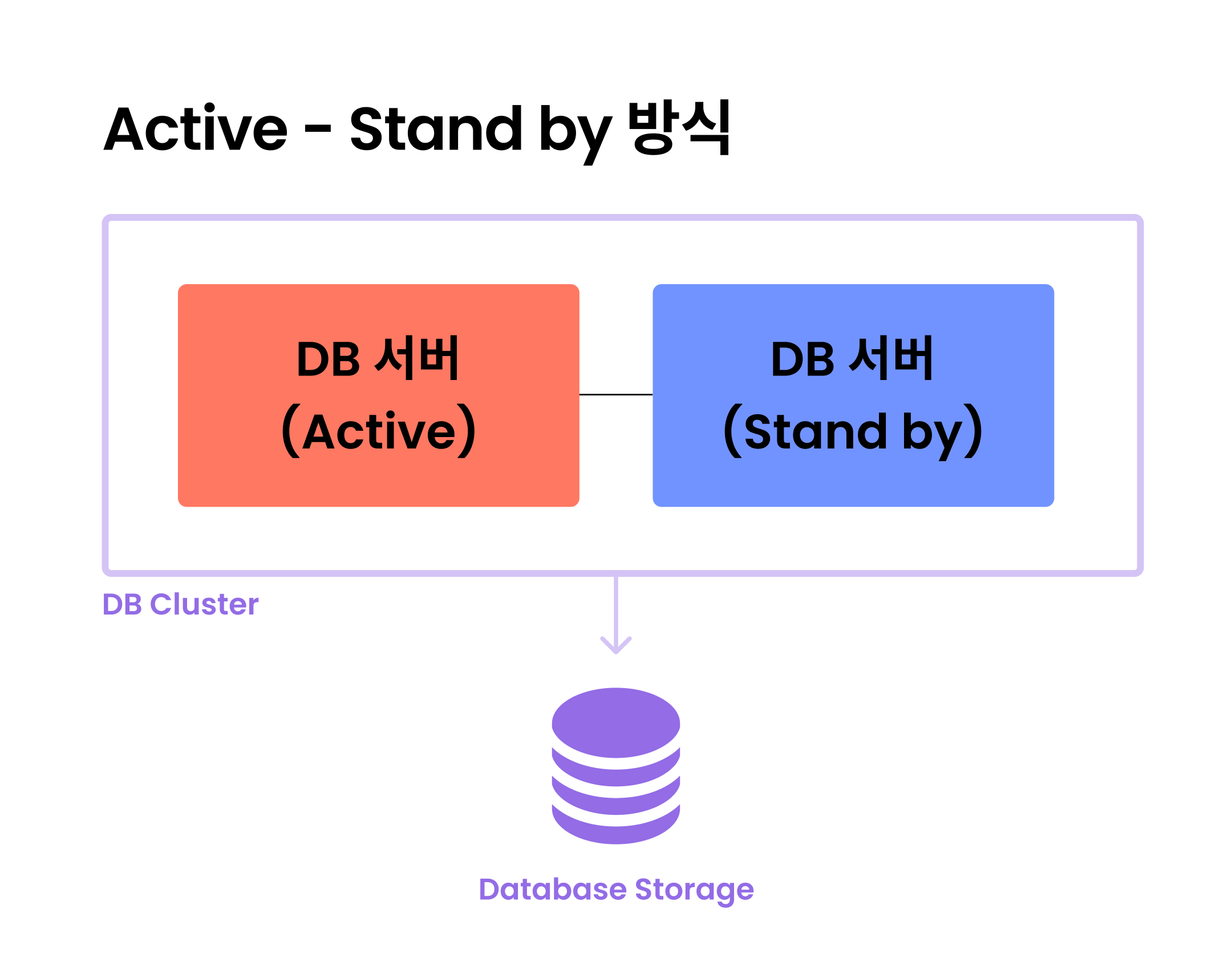
- 하나의 서버는 Active 상태로 작업을 처리하고, 나머지 하나는 Stand By 상태로 대기한다.
- Active된 서버에 문제가 생기면, Stand By 상태 서버를 Active로 바꿔서 작동시킨다.
- 한 번에 두 서버를 동시에 사용하는 것이 아니기 때문에 비용 부담이 덜하다.
- Stand By 서버는 평소에 작동하던 것이 아니기 때문에 Active 전환까지의 시간이 수십 초에서 수십 분까지 걸린다.
두 방식 차이점
| 특징 | Active-Active | Active-Standby |
|---|---|---|
| 가용성 | 고가용성 (서버 중단 시 다른 서버가 즉시 처리 가능) | 장애 발생 시 Standby 서버로 전환 필요 |
| 성능 | 여러 서버가 동시에 작동하므로 높은 성능 제공 | Standby 서버는 대기 상태로 성능에 기여하지 않음 |
| 비용 | 서버 여러 대가 동시에 작동하므로 비용 부담 증가 | Standby 서버는 대기 상태로 비용 부담 적음 |
| 데이터 동기화 | 데이터 충돌 가능성 존재 (동기화 필요) | 데이터 동기화 문제는 발생하지 않음 |
| 복구 시간(Failover) | 서버 장애 시 복구 즉시 가능 | Standby 전환에 수십 초~수분 소요 가능 |
장단점
장점
- 고가용성: 장애 발생 시에 대기 중이던 서버로 자동으로 전환한다.
- 확장성: 서버를 추가하여 처리 성능을 확장할 수 있다.
단점
- 설정과 관리가 복잡하다.
- 데이터 동기화를 하는데 비용이 증가한다.
리플리케이션 (Replication)
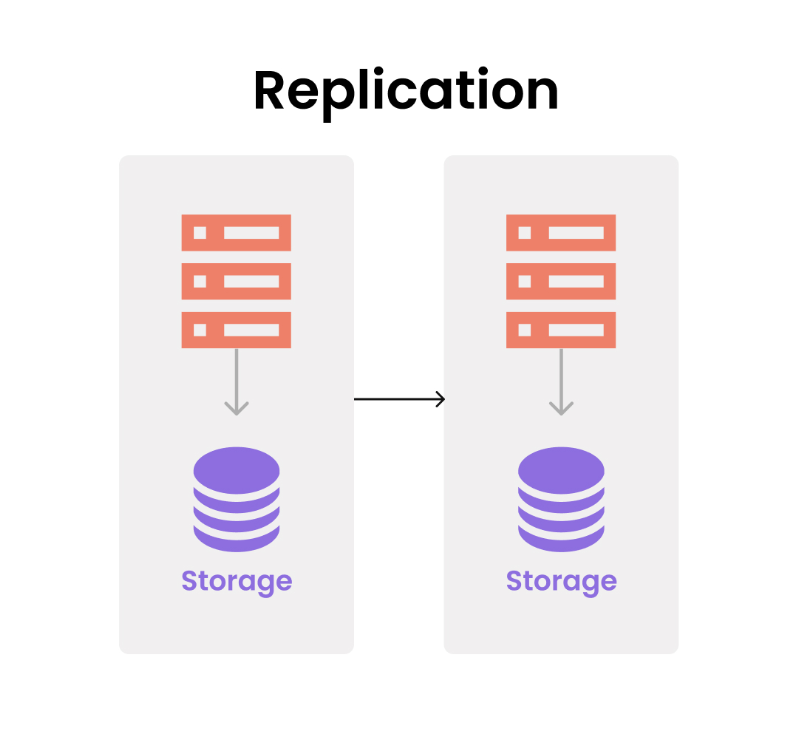
데이터 유실을 최소화하기 위해서 서버와 스토리지를 복제하여 데이터베이스 서버를 수직적인 구조로 구축한다.
리플리케이션은 Source(Master)와 Replica(Slave)로 나뉜다.
위 사진에서 왼쪽이 Source(Master), 오른쪽이 Replica(Slave)이다.
사용하는 목적은 아래와 같다.
- 스케일 아웃
갑자기 늘어나는 트래픽에 대비하기 위하여 서버를 늘려 성능을 개선하는 것이다. - 백업
백업 과정에서 쿼리 손상(데이터 유실)을 입을 가능성이 있어 Source 서버에 영향을 주지 않고 Replica에서 데이터 백업을 한다. - 데이터 분석
Source 서버에 영향을 주지 않고 Replica 서버에서 데이터 분석을 할 수 있다, - 데이터의 지리적 분산
Source 서버와 물리적인 거리가 있어도 Replica 서버를 통해서 동일한 데이터를 받을 수 있고, 속도도 높일 수 있다.
리플리케이션 처리 방식
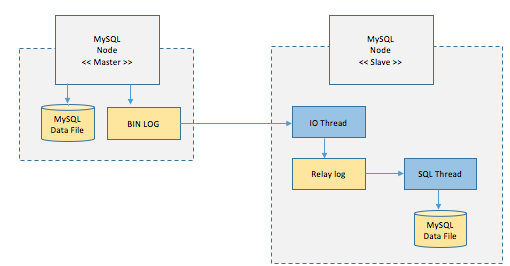
- Master 서버에 쓰기 트랜잭션이 들어온다.
- Master 서버는 데이터를 저장하고 트랜잭션에 대한 로그를 BIN LOG 파일에 기록한다.
- Source 서버는 Master 서버의 BIN LOG 파일을 Relay log 파일에 복사한다.
- Source 서버의 SQL Thread는 Relay log 파일을 하나씩 읽으며 데이터를 저장한다.
이렇게 두 서버 간 무결성 검사를 하지 않는 비동기 방식으로 데이터를 동기화한다.
장단점
장점
- 데이터 유실 위험이 감소한다.
- 읽기 부하 분산으로 성능이 향상된다.
단점
- 데이터 동기화를 하는데 지연 가능성이 있다.
- 쓰기 작업에 대한 부하가 증가한다.
🦴 참고
https://www.whatap.io/bbs/board.php?bo_table=blog&wr_id=189&page=3
https://mangkyu.tistory.com/97
