
주제
- 미세먼지 농도 예측 머신러닝 모델링
목표
- 탐색적 데이터 분석 복습
- 데이터 전처리 과정 복습
- 머신러닝 모델링 과정 복습
- 머신러닝 모델 평가
프로젝트 내 역할
- 개인 프로젝트이므로, 혼자서 과정들을 진행하였음
1. 데이터 분석
1.1 구성
-
air_2021, air_2022
- 미세먼지 및 오염물질(SO2, CO, O3, NO2, PM25, PM10) 정보
-
weather_2021, weather_2022
- 날씨 정보(기온, 강수량, 풍속, 풍향, 습도, 시정 등)
1.2 분석
- 코로나19 전후 미세먼지 농도에 영향을 미치는 요인 비교분석
- 필요한 내용만 정리하자면 '후차적 생성요인', '다중공선성' 등을 고려했을 때, 의미있는 독립변수는 아래와 같다.
- CO, SO2, 기온, 습도, 풍향, 풍속, 강수량
2. 데이터 전처리
2.1 time 컬럼 생성
air_21['측정일시'] -= 1
air_21['time'] = pd.to_datetime(air_21['측정일시'].astype(str), format = '%Y%m%d%H')- to_datetime은 str자료형을 Timestamp 자료형으로 바꿔주는 역할
- 기존 '측정일시'의 값은 int64이므로 'astype(str)'를 통해 형변환이 필요함
- format에서 지정하는 형식은 '바꿔줄 형식'을 지정하는 것이 아닌 '현재 주어진 문자열의 형식'을 알려주는 역할
2.2 time 컬럼 기준 병합
df_21 = air_21.merge(weather_21, on = 'time')
# 병합 결과 = 데이터프레임_1.merge(데이터프레임_2, on = 기준 컬럼)- 컬럼을 기준으로 병합하므로 'merge' 사용
- 인덱스 기준 병합이라면 join을 사용하면 됨
2.3 time 컬럼 인덱스 지정
df_21.set_index('time', drop = True, inplace = True)- set_index: 지정한 컬럼을 인덱스로 만들어주는 메소드
- 'inplace = True'를 통해 원본을 변경해줘야 함
- 다시 없애려면 reset_index를 사용하면 됨.
2.4 사용하지 않을 변수 제거
- drop을 통해 사용할 변수들만 남기고 나머지는 제거
- 컬럼을 제거할 것이므로 'axis = 1'을 꼭 넣어야 함
2.5 결측치 처리
- '시계열 데이터'이므로 결측치를 제거하기보다는 대체하여 데이터를 최대한 보존하는 방향으로 처리
- 변수들의 특징에 따라 'fillna'와 'interpolate'를 각각 적용함.
# inter: 'interpolate'를 적용할 컬럼명을 담은 배열
for c in inter:
df_21[c].interpolate(method = 'linear', inplace = True)
df_22[c].interpolate(method = 'linear', inplace = True)
# fill: 'fillna'를 적용할 컬럼명을 담은 배열
for c in fill:
df_21[c].fillna(0, inplace = True)
df_22[c].fillna(0, inplace = True)2.6 컬럼 추가
- 시계열 인덱스에서 값 추출하기
- Timestamp 자료형인 인덱스에서 값을 추출
df_21['month'] = df_21.index.month
df_21['day'] = df_21.index.day
df_21['hour'] = df_21.index.hour- 만약 인덱스가 아닌 일반 컬럼일 경우: .dt 사용
df_21['month'] = df_21['time'].dt.month
df_21['day'] = df_21['time'].dt.day
df_21['hour'] = df_21['time'].dt.hour2.7 Target 컬럼 생성
- 예측해야하는 값은 '1시간 뒤의 PM10'
- 'shift'를 활용하여 새로운 컬럼 생성
df_21['PM10_1'] = df_21['PM10'].shift(-1)- '24시간 전의 PM10'이 필요하다면
df_21['PM10_lag1'] = df_21['PM10'].shift(24)- shift 과정에서 결측치가 생기므로 적절한 값을 채워넣어야 함.
2.8 train, test 데이터 저장
- train, test 데이터에 대해 x, y값을 나누어서 저장
train_x = df_21.drop('PM10_1', axis = 1)
train_y = df_21.loc[:, 'PM10_1']
test_x = df_22.drop('PM10_1', axis = 1)
test_y = df_22.loc[:, 'PM10_1']
train_x.to_csv('train_x.csv')
train_y.to_csv('train_y.csv')
test_x.to_csv('test_x.csv')
test_y.to_csv('test_y.csv')3. 머신러닝 모델링 및 평가
-
Linear Regression, RandomForest, Gradient Boost 등의 모델을 만들어 성능을 평가해보았음
-
RandomForestRegressor 모델에서 feature importance
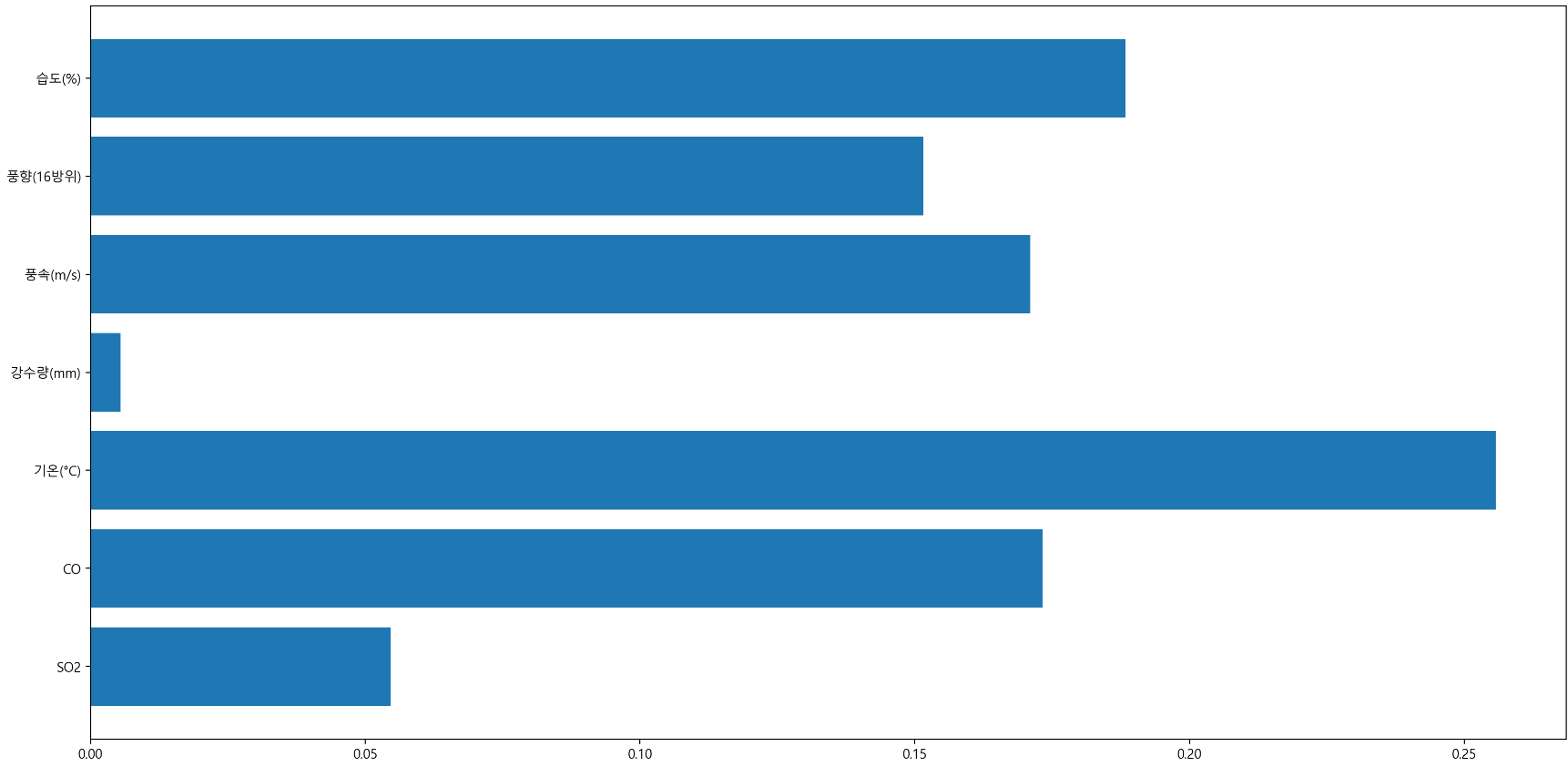
-
GradientBoostingRegressor 모델에서 feature importance
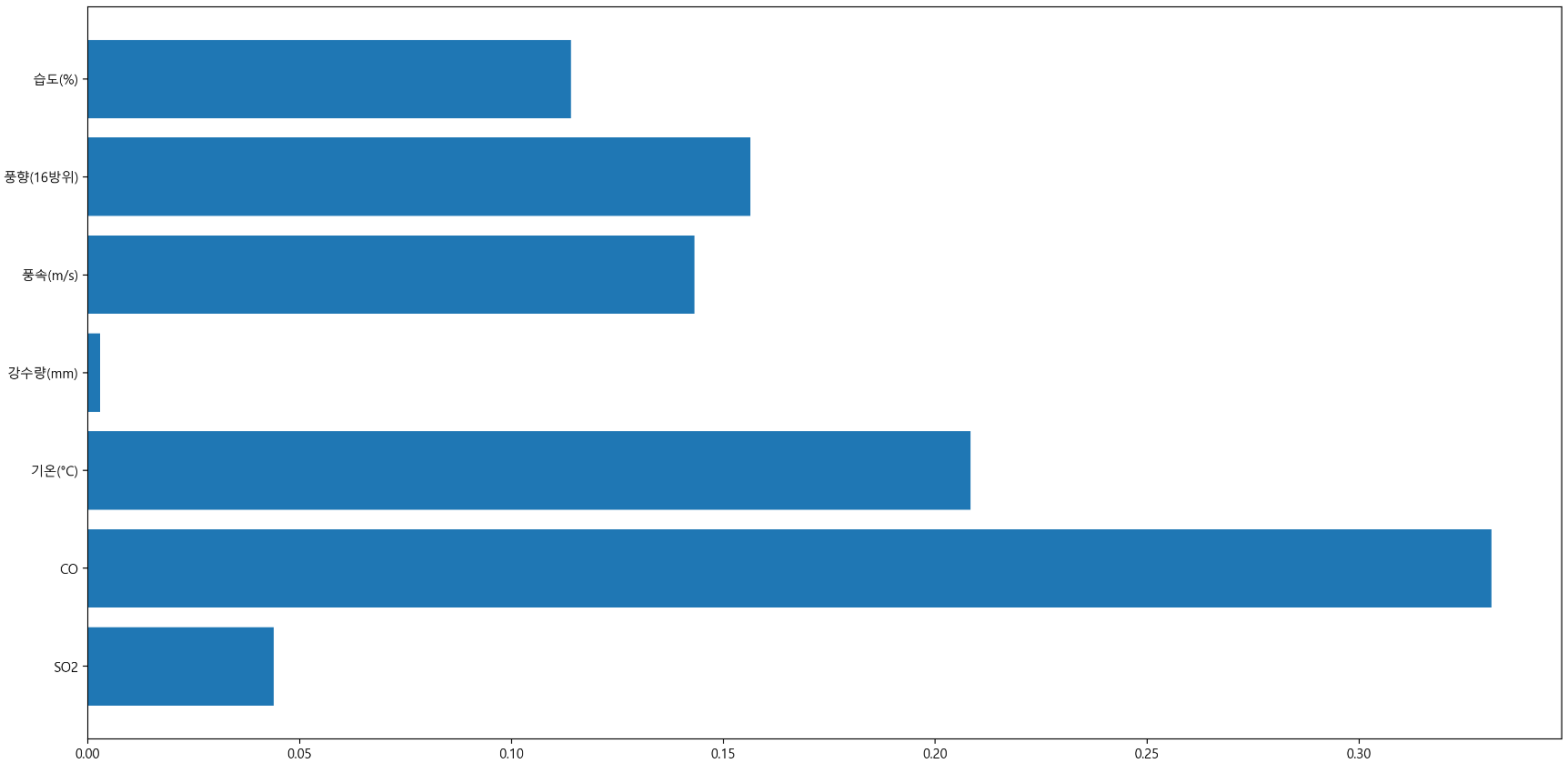
-
Linear Regression에서 성능이 좋지 않아 'Elastic Net'을 시도해보았고, 성능이 개선되었음을 확인함
model = ElasticNet(alpha=0.01, l1_ratio=0.5)
model.fit(train_x, train_y)
y_pred_EN = model.predict(test_x)
print(mse(test_y, y_pred_EN)**(0.5))
print(r2_score(test_y, y_pred_EN))어려웠던 부분
- 전처리 과정 중 결측치 처리에서 대체방법을 결정하는 과정
- 모든 변수들에 대해 결측치는 어떻게 구성되어 있는지, 앞뒤 값과의 관계 유무 등을 하나씩 확인해보며 결정함
- plt에서 한글 깨짐 문제
- 한글 폰트 깨짐 수정: 해당 글을 보며 해결
마무리
- '1시간 뒤의 PM10'을 예측하는데 가장 큰 영향을 미치는 것은 '현재 PM10'이었음
- 하지만, 같은 PM10 값이므로 정답으로 정답을 예측하는 느낌이 강하여 제외하고 시도해보았음.
- 제외하고 feature importance를 확인해본 결과, PM25값이 가장 큰 영향을 미쳤음.
- 마찬가지로 PM25와 PM10은 거의 같다고 해도 무방하므로 제외하고 시도해봄.
- 이번에는 '시정' 변수가 가장 큰 영향을 미치는 것으로 나왔으나, '시정거리가 짧으니 미세먼지가 많다'가 아닌 '미세먼지가 많아 시정거리가 짧음'이 맞음. 즉, 시정은 미세먼지에 의해 결정된다고 볼 수 있으므로 변수에서 제외해야 함.
- 강수량의 importance가 낮게 나오는 이유는 결측치 처리를 제대로 하지 못한 결과로 보임. 아래와 같이 데이터를 바꿔보면 좋을 것 같음.
- 강수량이 있으면 1, 없으면 0으로 바꾸기
- 결측치가 비가 내리지 않아서 생긴 것인지, 측정을 하지 못해서 생긴 것인지를 확인하고 경우에 맞게 처리하기

A smooth sea never made a skilled sailor