
요약
- 딥러닝 복습
- CNN 기초
딥러닝 Review
Tensorflow
- 딥러닝 프레임워크(Google 개발)
- 다른 프레임워크로는 PyTorch가 있음(Meta 개발)
keras
- Tensorflow에 포함된 high-level API 라이브러리
딥러닝 구현 방법
1. Sequential API
- 레이어를 순차적으로 쌓아나가는 방식
2. Functional API
- 레이어를 능동적으로 조절해가며 연결하는 방식
레이어 연결 방식
1. Fully Connected
- 모든 노드를 연결하는 구조
2. Locally Connected
- Feature 간 연결을 제어하며 일부만 사용하는 구조
- Concatenate: 별도의 Feature로 학습한 서로 다른 레이어를 하나로 합하는 역할의 레이어
cl = Concatenate()([레이어1, 레이어2]) - Add: 각 레이어에서 추출된 특징을 더함으로써 합하는 방식의 레이어
cl = Concatenate()([레이어1, 레이어2])
- Concatenate: 별도의 Feature로 학습한 서로 다른 레이어를 하나로 합하는 역할의 레이어
Dropout
- 학습과정에서 '특정 비율(rate)'만큼 노드를 비활성화하는 것
- 이유: 오버피팅의 위험을 줄이고, General(Robust)한 모델을 만들기 위함 => 초기값에 덜 민감해짐
- 일반적으로 Dense 레이어 뒤에만 위치시킴
Batch Normalization
- 여기서의 Batch는 'mini-batch'를 의미함
- covariate shift에 의해 학습이 들쑥날쑥하게 진행되는 것을 방지
- 은닉층 & 활성화 함수 -> BatchNormalization Layer 순서로 사용
(원래는 활성화 함수와 BN의 순서가 반대이나, 이것이 성능이 더 좋다고 함.)
전처리
- 목적: 모델의 성능을 조금이라도 개선하는데 기여하기 위함 + 데이터를 목적에 맞게 조정
- 예시: MultiClass Classification의 전처리 과정
1) reshape 또는 flatten layer: 학습을 위해 데이터 모양 변형
2) One-Hot Encoding
3) Scaling: 데이터의 범위를 통일시키는 과정(주의: 데이터의 분포는 변하지 않음)from tensorflow.keras.utils import to_categorical y_train = to_categorical(y_train, class의 개수)
컴파일(Compile)
-
선형 회귀 로지스틱 회귀 멀티 클래스 분류 activation
(활성화 함수)linear sigmoid softmax loss
(손실함수)mse binary_crossentropy categorical_crossentropy metrics
(평가 지표)x accuracy accuracy optimizer
(최적화)adam adam adam
학습(Fit)
Early Stopping
CV, Computer Vision
- (32 X 32 X 3) 컬러 이미지를 (3072 X 1)로 만들어서 학습시키는 것이 좋을까?
- NO! 단순한 이미지(MNIST, Fashion-MNIST 등)에서는 어느정도 성능이 나오지만, 일정 수준을 넘기기 힘듦
- 이미지의 구조를 손상시키지 않으면서, 특징을 잘 뽑아낼 수 있는 방법 필요 -> CNN
CNN
- Convolutional Neural Network
- Convolutional Layer를 이용한 Conv.작업이 포함된 Neural Network
- 이미지의 한 픽셀과 주변 픽셀들의 연관성을 살리는 것에 포인트를 둔 모델
Convolutional Layer
- 이미지에서 세부적인 특징들을 뽑아내는 역할을 하는 레이어
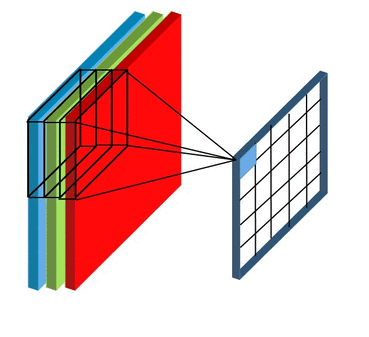
- (출처: quora.com)
- 합성곱 연산: 같은 위치에 있는 원소끼리 곱한 값들을 합하는 것
- 합성곱에 대한 자세한 설명
필터(Filter, Sliding Window)
- 이미지의 특징을 찾아내기 위한 일종의 kernel
- 필터의 depth는 적용할 데이터의 depth와 같아야 함.(반드시 그런가?)
- ex)
- (32 X 32 X 3) 컬러 이미지와 (5 X 5 X 3) 필터
- 적용 결과: (28 X 28 X 1)의 'Feature map'
- Feature map 은 activation map이라고도 함
- 결과로 나올 Feature map의 수 = (서로 다른 가중치를 가진)필터의 개수
Stride
- 필터 중심점의 이동거리 => 몇 칸을 건너고 필터를 이동시킬 것인가?(Step 설정)
- 데이터의 외곽에 존재하는 정보들이 덜 쓰이게 되는 부작용이 생김
Zero Padding
- Stride에서 언급한 부작용을 해결하기 위한 방법
- 원본 데이터 가장자리에 0으로 이루어진 값들을 추가하여 크기를 키우는 것
1 X 1 CONV
- 데이터의 depth를 조정하는데 사용됨
- 데이터의 depth -> (1X1 CONV)의 개수
Pooling Layer
- 데이터를 더 작고, 관리하기 쉽게 만드는 역할
- 가로, 세로를 줄이는 것이 목적(= 연산량 줄이기)
- Subsampling(Downsampling)
- ex) Max Pooling, Average Pooling
다음 레이어의 크기
- N: 원래 데이터의 크기(정사각형 기준 한변의 길이)
- F: 필터의 크기
- P: 패딩의 크기
- S: Stride(보폭)
마무리
- sparse_categorical_crossentropy: to_categorical 전처리없이 데이터를 모델에 사용 가능

A smooth sea never made a skilled sailor