작성일: 2023.06.07(수)
KT AIVLE AI 개발자 트랙 3기 과정의 마지막인 빅프로젝트를 진행하고 있습니다.
프로젝트에서 '백엔드'를 담당해 개발을 본격적으로 시작하기에 앞서 DB설계를 위한 ERD를 작성을 진행할 예정입니다.
프로젝트 소개
'Pose-Estimation과 Wi-Fi를 이용한 영아 위험 행동 감지 및 비상 상황 알림 서비스'(이하 ‘아일보리 프로젝트’)
영아의 안전 사고를 예방하고 영아를 키우는 부모들을 대상으로 한 프로젝트입니다.
아일보리 프로젝트에서는 다음과 같은 핵심 기능이 포함될 예정입니다.
- 실시간 영아 위험 행동 감지 및 알림
- 카메라 객체 인식과 WIFI를 활용한 객체 탐지 기술 활용
- 알림 전송 기능
- 서비스 이용을 위한 회원가입 및 로그인
- 서비스 가입자 커뮤니티 게시판
- 파일 업로드 기능
- 좋아요, 댓글 기능
- 버그 관리
- 문의 게시판
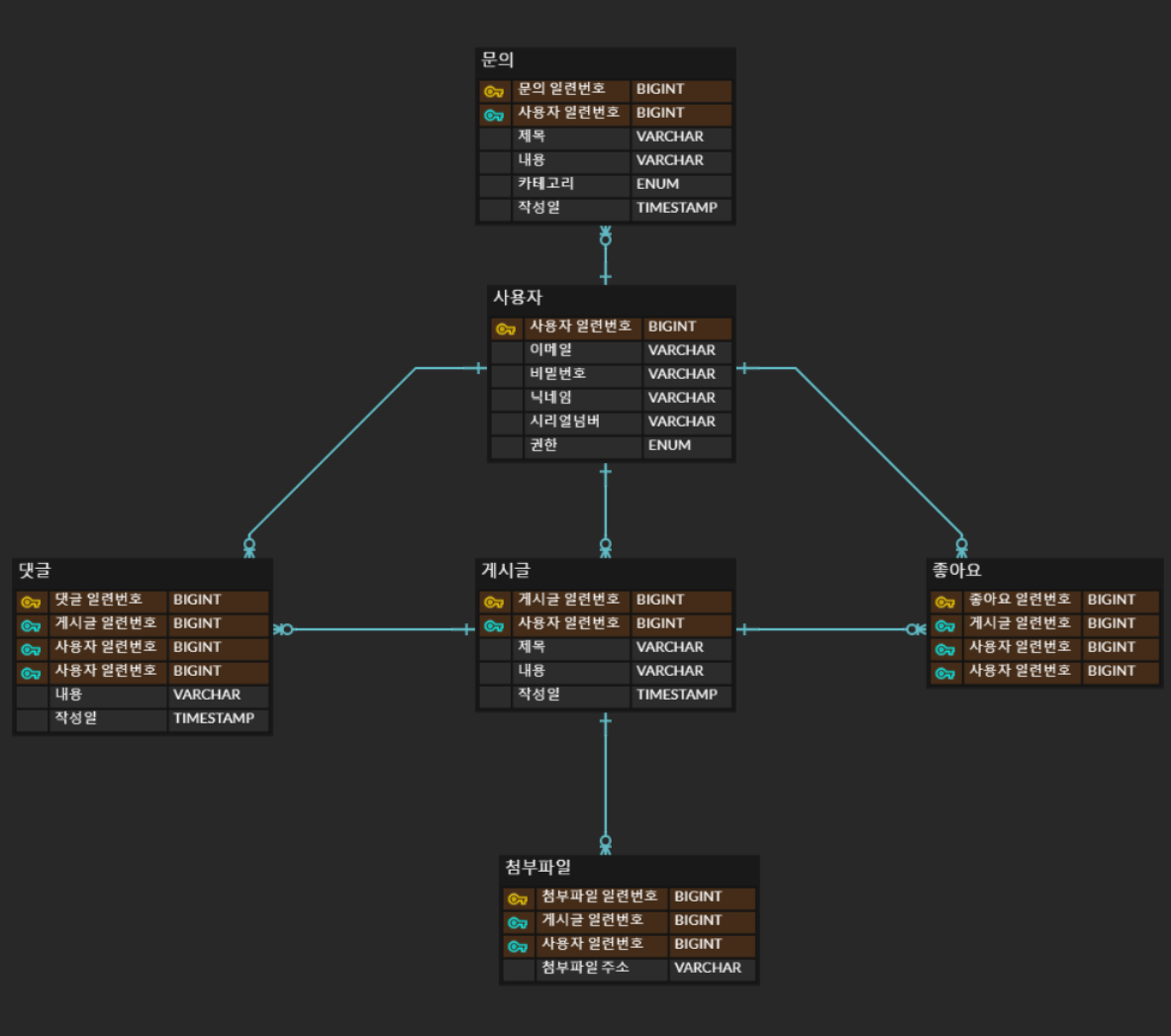
아래 서비스 플로우를 바탕으로 ERD를 작성할 예정
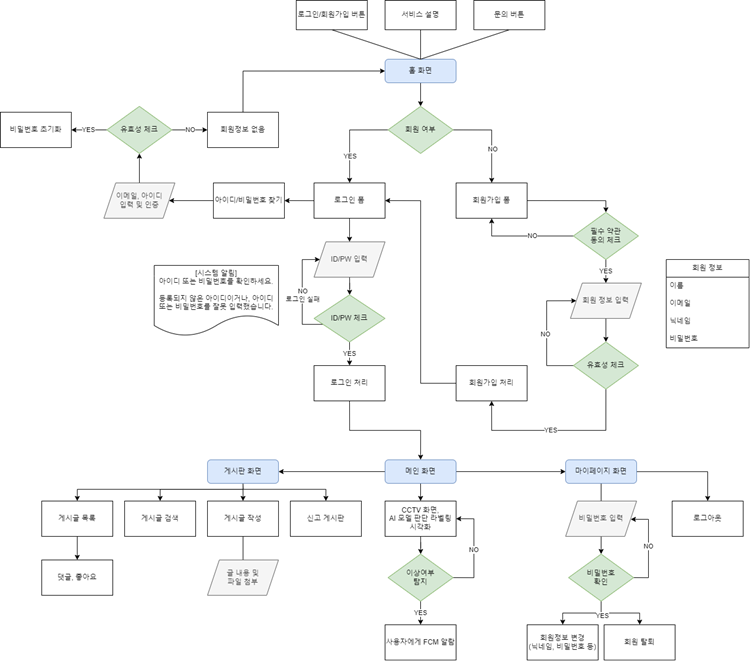
데이터베이스 설계
DB 설계는 어떻게 해야 할까? 이 글을 참고하여 진행하였다.
예비 테이블
- 먼저 필요한 필드들을 찾아보고 예비 필드 목록을 뽑아보기

- 자연키의 장점은 '성능', 인조키의 장점은 '유연성'
- '유연성' > '성능' 이므로 기본키 역할을 할 인조키를 생성한다.

- 다중값, 다중 부분 필드가 있는지 확인하기
- 'Post' 테이블의 '좋아요', '댓글', '파일'은 다중값

- '댓글'과 '좋아요'는 테이블이 존재하므로 적절히 수정해서 관계를 맺어줌
- 'Attachment' 테이블을 새로 만들어 'Post' 테이블과 관계를 맺어줌
- 모두 '식별 관계'로 연결했는데, 게시글 없이 '좋아요'와 '댓글'이 존재할 수 없기 때문
- 계산된 필드가 존재하는지 확인
- 계산된 필드는 계산에 참여하는 필드의 값이 바뀔 때 갱신되지 않음
- 갱신 작업의 책임이 응용프로그램으로 전가
- 현재 테이블 설계에서는 없음
- 외래키 이외에 불필요한 중복 필드 확인
- 저장공간 낭비 및 수정 발생 시 무결성 깨뜨릴 수 있음
- 현재 테이블 설계에는 없음
- 최소한의 중복 데이터만 남기기
- 수정한 내용 없음
필드 명세 설정
각 필드의 이름, 데이터 종류, 허용 길이, 값 범위, 유일성, NULL 지원, 기본값에 대해 생각해보아야 함.
- CHAR vs VARCHAR
- 고정길이 vs 가변길이
- 저장공간 낭비 vs 수정에 대한 성능 감소
- 조회 성능이 가장 중요하므로 대부분 VARCHAR 선택
- 이미지가 포함된 게시글 내용
- 이미지를 페이지에서 어떻게 처리할 것인지 먼저 결정
- DATETIME vs TIMESTAMP
- TIMESTAMP는 시간을 UTC로 저장
- 즉, TIME ZONE에 맞게 저장된 시간을 볼 수 있음
- 하지만, TIMESTAMP는 '2038-01-19'까지 밖에 저장할 수 없음
- ENUM 데이터 타입 vs 참조 테이블
- 필드에 들어갈 수 있는 값을 제한하는 역할
- ENUM: 성능, 간편함
- 참조 테이블: 유연성
- 기준을 설정하여 결정하는 것이 바람직
- 기준 예시) 자주 변경되는가, 같이 보관할 필요가 있는가 등
현재까지의 설계는 아래와 같다.
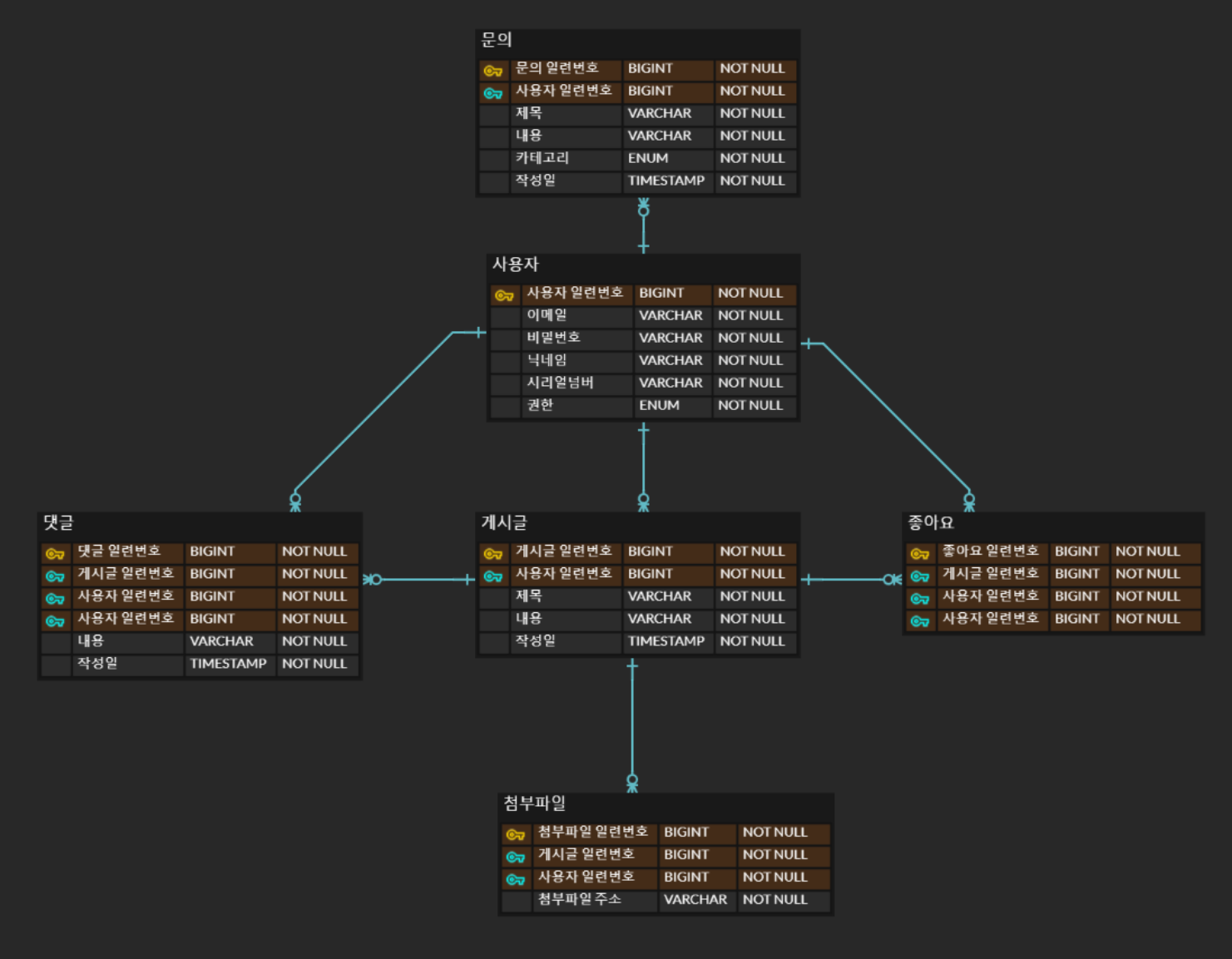
관계 설정
두 테이블은 '1:1', '1:N', 'N:M', '식별 관계', '비식별 관계'를 맺을 수 있음.
- A 테이블의 하나의 레코드가 B 테이블 레코드 몇 개와 연관될 수 있을 것인가?
이 물음에 대한 답이 관계를 설명해줄 수 있음.
N:M 관계
다중 값 필드가 생기거나 테이블에 대량의 중복 데이터가 포함될 수 있으므로 반드시 풀어주여야 함.(제거)
식별 vs 비식별
식별 관계
-
장점
데이터의 정합성
자식 테이블에 데이터가 존재한다면 부모 데이터도 반드시 존재한다고 보장 -
단점
요구사항이 변경 시 구조 변경이 어려움
비식별 관계
-
장점
변경되는 요구사항을 유동적으로 수용 가능
부모 데이터와 독립적인 자식 데이터를 생성 가능 -
단점
데이터 정합성을 지키기 위한 별도의 비즈니스 로직이 필요
자식 데이터가 존재해도 부모 데이터가 존재하지 않을 수 있음
즉, 데이터 무결성 미보장 -
정리
식별관계보다 비식별관계를 선호
구조 변경 용이
부모 테이블에 대한 의존성 제거
과도한 인덱스 제거
유연성을 생각한다면 '비식별 관계'로 설정하는 것이 맞지만,
우선, 개념만을 생각하여 '식별 관계'로 설정하였음(추후 변경 가능)
초안 결과
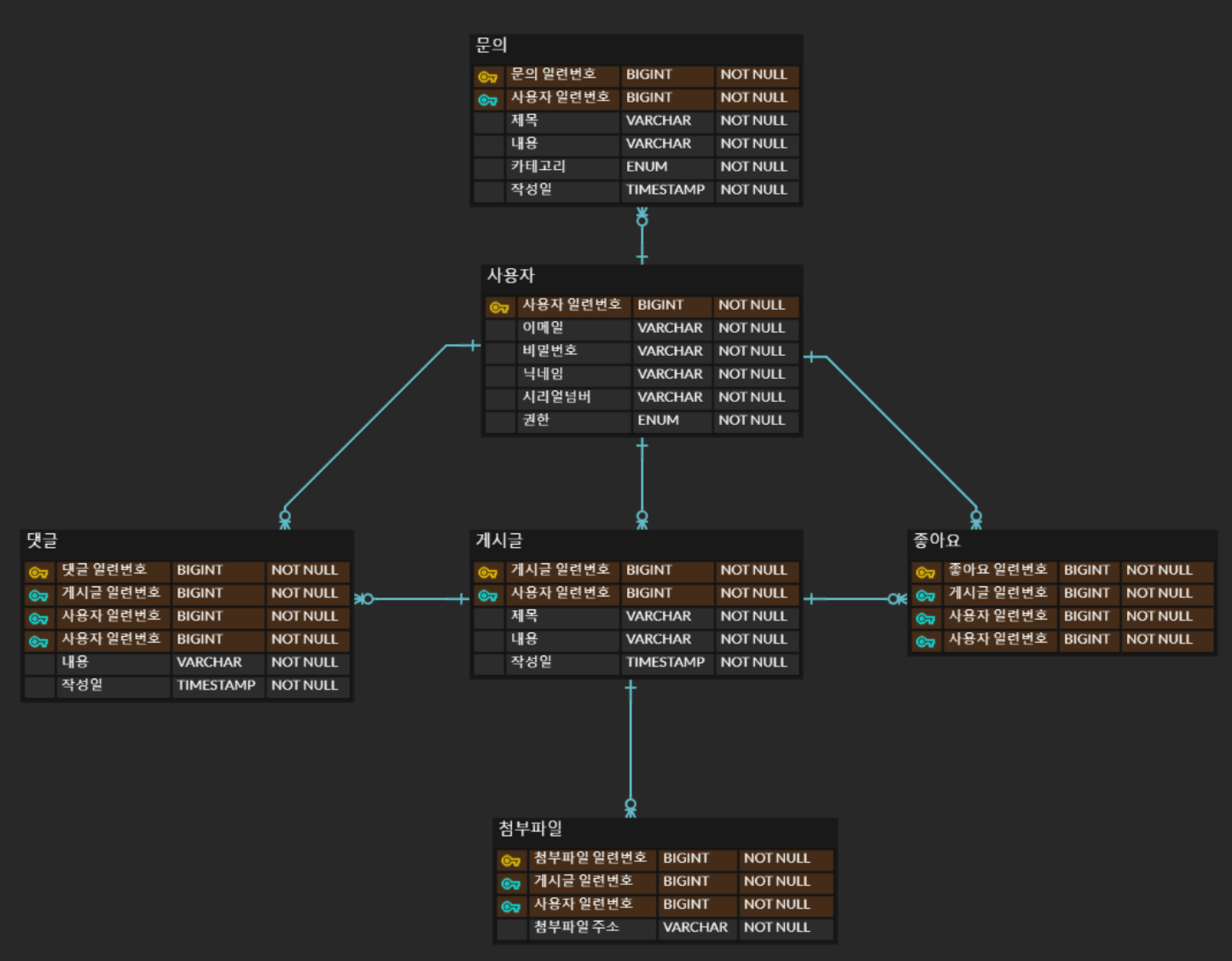
마치며
DB 설계를 체계적으로 해보는 과정을 처음 경험하고 있는데,
논리를 바탕으로 관계를 정의하고 설계를 이어나가는 점이 매우 흥미롭게 다가왔다.
물론 어렵지 않은 것은 아니지만, 더 거대한 DB를 설계할 수 있을 정도로 발전해나가는 과정이라고 생각한다면 오히려 좋아...
시작부터 완벽한 설계는 없다는 것을 알기에 초안은 바탕으로 지속적으로 수정해나가면서 진행할 예정이다.
