Approximate Inference
Approximate Inference, 근사 추론은, 어떤 확률 모델에서 정확한 계산이 불가능해 데이터 분포를 표현하기 어려울 때 그와 유사한 표현을 통해 모델을 대체하겠다는 개념으로 근사시킨다는 말이다. 즉, approximate한 방법으로 데이터의 확률분포를 추정하는 것이다.
꽤 복잡한 확률 모델의 경우 특히 유용하다는 특징을 가지는데, 일반적으로 모델에서 정확한 추론(inference)를 수행하기 위해 exponetial한 계산을 필요로 하기 때문이다.
가령, RBM(Restricted Boltzmann machine) 이나 PPCA(probabilistic principle component analysis)등을 예시로 들 수 있고, graphical model with multiple layers of hidden variables 들이 언급한 intractable 한 posterior distibution을 갖는다.
다른 더 쉬운 예시를 들자면,
bayesian network model에서, 가능한 모든 상태의 조합을 고려하는 bayesian inference는 NP-hard 문제가 되어 일반적으로 계산하기 매우 어렵다는 특징을 갖는다.
이럴 때 근사 추론(approximate inference)를 사용해 문제를 해결한다.
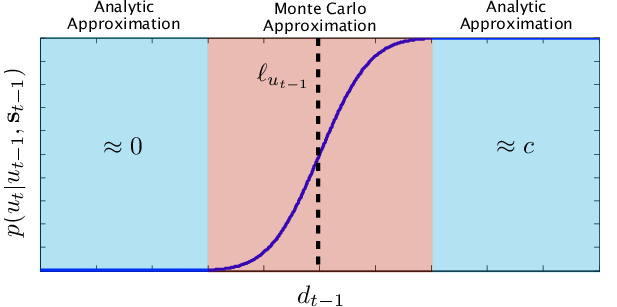
그렇다면 근사추론이 어떤 방식으로 수행되는가? 그를 수행하기 위해 먼저 베이지안 추론을 이해할 필요가 있고, 그를 위해 확률, 통계를 어떤 관점으로 이해해야 하는지 받아들일 필요가 있다.
확률을 바라보는 관점
확률을 바라보는 관점에는 크게 두가지가 있다. 빈도론(Frequentism)과 베이즈 주의라고 불리는 베이지안(Bayesianism)이 그것이다.
만약 90%의 성공확률을 갖는 아이템 강화가 있다고 해보자,
빈도론자는 이에 대해
"10번을 강화하면 9번, 100번을 강화하면 90번을 성공할것이다." 라고 해석할 것이다.
그러나 베이즈주의자는 이에 대해
"강화할때 성공할 것이라고 90%의 확률로 확신할 수 있다." 라고 해석할 것이다.
즉, 빈도론자는 확률에 대해 '사건이 일어나는 장기적인 확률'로서 오로지 경험적인 사실만을 통해 이야기할 수 있다는 객관적인 입장이고 베이지안은 '지식이나 판단의 정도를 나타내는 수단'으로서 주관적인 입장을 취한다.
우리가 흔히 알고있는 확률의 보편적인 정의, 즉 일상적으로 받아들이는 정의는 '빈도론'에 입각한 정의를 따른다. (강화의 기댓값 등..)
그러나 우리는 경험적으로 모든 데이터를 얻기에는 한계가 있다. 따라서 사전지식, 즉, Prior Probability를 통해서 경험적으로 얻기 힘든 사건에 대한 확률을 추정하는 것이 필요하다.
즉, 사후확률 Posterior Probability를 얻기 위해 베이지안이라는 관점이 필요한 것이고, 이러한 과정이 바로 베이즈 정리에 입각한 베이지안 추론이다.
베이지안 추론
데이터 셋 에 대하여 와 데이터의 모델 가 있다고 가정해보자
그렇다면
이때,
= Likelyhood of
= Prior prob of
= Posterior prob of
이때 우리가 원하는 것은 파라미터 를 데이터 로부터 추론하는 것이다.
를 데이터의 분포, 밀도함수라고 정의했을 때, 다음과 같이 정의해볼수 있다.
즉, 추론 대상에 대한 사전분포를 알고, 데이터에 대한 적절한 가정(Likelyhood)만 할 수 있다면, 이로부터 posterior distribution에 대한 추론이 가능하다는 것이 베이지안 추론이다.
P(D)의 문제
해당 베이지안 추론으로 모든 를 구할 수 있다면 좋겠지만 , 문제는 해당 Data의 분포나 확률값을 구하기가 어렵다는 것이 문제이다.
정확히 말하면 도출해낸 P(D)값이 실상은 해당 데이터의 분포를 다루는 Model로 부터 생성된 데이터가 D이고,
Model에서 현재 data가 나타났을 확률로서 를 사용하기 때문이다.
또한 고차원 데이터일수록 model이 Latent Variable을 쓰기 때문에 실상은
Latent Variable 를 이용,로 하기 때문에 정확한 P(D)의 값을 구하기 어렵다
따라서 근사적인 방법으로 를 로 근사하여 구하는 것이다.
해당 Approximation 방법론은 크게 Sampling Method와 Variational Method로 나뉜다.
sampling method
Samping method는 말 그대로 특정 distribution에서 모델의 분포를 샘플링하여 추정한다.
대표적인 방법으로는 Markov chain Monte Carlo(이하 MCMC)가 있다.
MCMC는 마르코프 체인의 안정상태확률로 부터 샘플링하여 모델의 분포를 추정한다.
마르코프 체인은 마르코프 성질을 지닌 이산확률과정으로서 마르코프 성질이란 의 상태(state)는 등의 상태가 현재/미래 상태에 영향을 미침을 의미한다.
이때 회의 상태가 전까지의 상태에 영향을 받는다면 그것을 차 마르코프 모델이라고 한다.
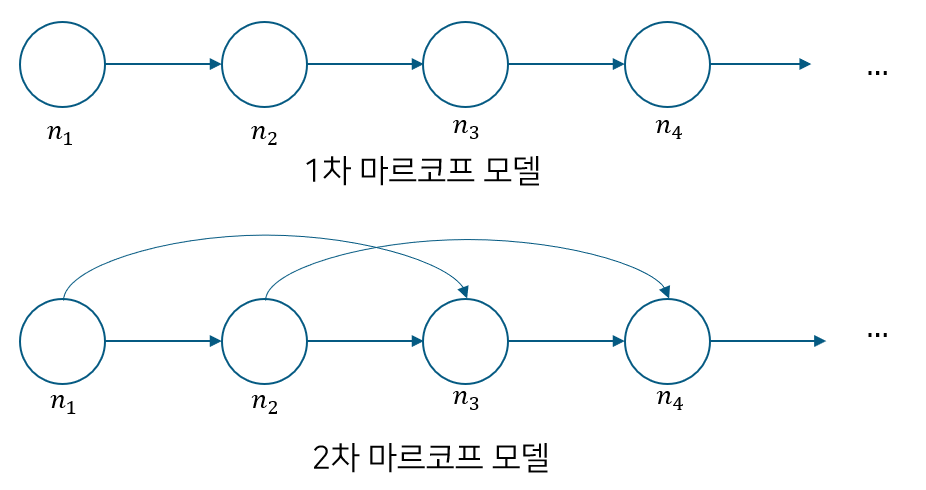
마르코프 프로세스는 다음과 같으며,

N차 전이확률을 로 보냈을 때의 확률을 안정상태확률이라고 한다.
MCMC는 현재 상태와 이전 상태 간의 관계만으로 다음 상태를 추론하는게 가능하므로
Markov chain을 이용하여 분포를 Samplin하는 것이 가능해진다.
따라서 Markov Chain이 충분한 시간이 지났을때 도달하는 분포인 안정상태 분포를 통해 해당 분포를 근사하여 구할 수 있다. (충분한 가 수행되면)
이때 는 Probability sampling strategy를 의미한다.(확률적 샘플링 기법)
Variational Method
MCMC와 다르게 VI는 다른 분포를 사용해(같은..) 모델의 분포를 근사한다.
이때 근사한 분포에 대한 을 최소화 하는 방식으로 추론을 하는데 이는 (Evidence lower bound)를 최대화 함과 동치이다.
즉, VI는 확률분포의 근사를 통해 Maximum likelihood inference 및 baysesian inference를 수행 하는 것이다.
사후확률 분포 를 다루기 쉬운 확률분포 로 근사한다고 생각해보자.
이때 KL발산의 식을 보면 다음과 같이 유도할 수 있다.
마지막 식을 통해서 K개의 몬테 카를로 서치를 하던지, 그래디언트를 적용하던지 등등의 많은 방법들이 쓰이지만 실제 생성형 모델 관점에서는 우도함수 를 알지 못하는 경우가 대부분이다. 따라서 EM 알고리즘을 활용한다.
알고리즘의 내용은 다음과 같다.
Expectaion : 를 줄이는 를 찾는다. (몬테카를로 방법을 활용한 VI, SVI 등 적용)
Maximization : E-step에서 찾은 를 고정한 상태에서 의 하한(lower bound)을 최대화하는 parameter 를 찾는다.
여기서 생소한 내용이 M-step이다. 우선 KLD는 다음 식의 우변과 같이 세 개 요소로 분해될 수 있다. E-step에서는 KLD를 줄이기 위해 만을 업데이트하므로 이 과정에서 는 변하지 않는다. 그런데 KLD를 줄이려면 또한 줄여야 한다..
위 식을 를 중심으로 정리하면 다음과 같이 쓸 수 있다.
(KLD는 항상 양수)
따라서 의 하한은 다음과 같다. 는 베이즈 정리에서 evidence라고 이름이 붙여진 항인데, 이 때문에 아래 부등식의 우변을 Evidence Lower Bound(ELBO)라고도 부른다.
위 부등식 우변의 값을 줄이게 되면 를 줄이게 되고, 결과적으로 KLD를 줄일 수 있게 된다. 따라서 를 고정시킨 채 위 부등식 우변의 값을 줄이는 방향으로 우도함수의 파라메터 를 업데이트하면 우리가 원하는 결과를 얻을 수 있다.
