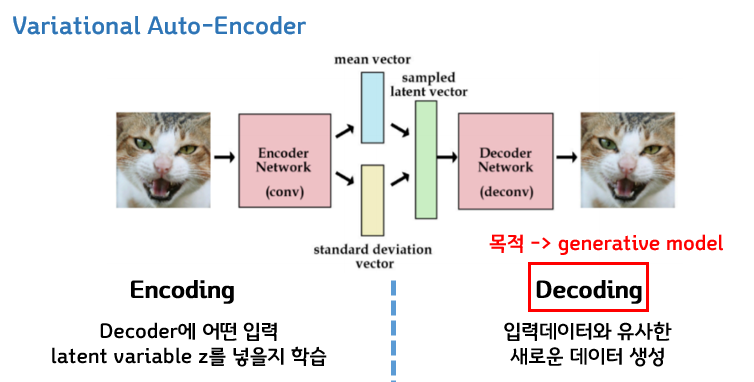
VAE
Variational Auto- Encoder는 인코더를 거치면 평균, 표준편차의 두개의 벡터를 아웃풋으로 내게 되는데, 이 두가지를 결합해서 어떤 Gaussian Distribution을 만들게 되고,
그렇게 만든 분포에서 Sampling을 통해 Z를 만들고 그 Z가 다시 decoder를 통과해 어떤 기존의 input 데이터와 유사한 새로운 데이터들을 생성 할 수 있다.
이 VAE는 해당 확률 분포들을 이용해서 어떤 새로운 데이터를 생성하는 것을 목적으로 개발된 모델이므로 생성형 모델이라고 할 수 있다.
기존 Variational Bayesian (이하 VB) 방법들은 두가지 문제점이 있는데.
1: 해당 생성을 위해서 θ \theta θ x x x L a t e n t V a l u e Latent\, Value L a t e n t V a l u e Z Z Z
E q ϕ ( z ∣ x ) [ l o g q ϕ ( z ∣ x ) ] E_{q\phi(z|x)}[log_{q\phi}(z|x)]\, E q ϕ ( z ∣ x ) [ l o g q ϕ ( z ∣ x ) ] 를 풀기위해 해당 ∫ p θ ( z ) p θ ( x ∣ z ) d z \int p_\theta (z)p_\theta(x|z)dz ∫ p θ ( z ) p θ ( x ∣ z ) d z p θ ( z ∣ x ) p_\theta(z|x) p θ ( z ∣ x ) intractable 하므로 해당 기댓값을 해석적으로 계산하기 어렵다.
2 : 대용량 데이터 셋에 대해서 기존 방법들이 비효율적이다.
따라서 해당 논문은 다음과 같은 해결책을 제시한다.Reparameterization Trick : 확률적 노드에 대한 역전파를 가능하게 함SGVB(Stochastic Gradient Variational Bayes) : 확장가능한 근사 추론 알고리즘 개발 AEVB(Auto-Encoding Variational Bayes) : 연속 잠재변수를 가진 생성모델의 효율적 학습 프레임 워크VAE(Variational AutoEncoder) : 신경망 기반의 실용적 구현 제시
결국 구현하고자 하는 것은
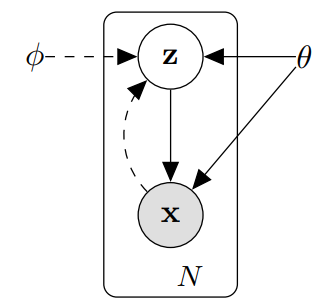
연속적인 Latent Variable과 Parameter가 다루기 힘든 사후분포를 갖는 Directed Probabilistic Model을 통해 효율적으로 Approximate Inference를 시행!
이제 구체적으로 알고리즘이 어떻게 되는지 Method 부분을 세세하게 나누어 확인해보자.
Method(2)
2.1 Problem Scenario
X X X x , x, x , N N N z z z x x x z z z p ( z ) p(z) p ( z )
이라고 했을때, 앞서말한 2가지 문제점에 대해서 해당 논문은 3가지 해결책을 제시했다.
파라미터 θ \theta θ ML: Maximum Likelihood :어떤 상황이 주어졌을 때 우도를 최대화 MAP: ML이 Likelihood를 최대화하는 방법이라면, MAP은 Posterior를 최대화 시키는 방법, 이때 Bayes Rule을 적용
관측값 x x x z z z
x x x
이때, 우리가 알고자 하는 p θ ( x ) p_\theta(x) p θ ( x ) z z z p θ ( x ) p_\theta(x) p θ ( x ) 결합확률 분포를 사용 )
p θ ( x ) = ∫ p θ ( x , z ) d z = ∫ p θ ( z ) p ( x ∣ z ) d z p_\theta(x) =\int p_\theta(x,z)dz =\int p_\theta(z)p(x|z)dz p θ ( x ) = ∫ p θ ( x , z ) d z = ∫ p θ ( z ) p ( x ∣ z ) d z 여기서 Intractable한 p θ p_\theta p θ
해당 추론은 l o g p θ ( x ) log\,p_\theta(x) l o g p θ ( x ) θ \theta θ x x x
l o g p θ ( x ) = 근사 / 실제 분포차이 + E L B O log\,p_\theta(x) = 근사/실제\,분포차이+ELBO l o g p θ ( x ) = 근 사 / 실 제 분 포 차 이 + E L B O 해당식을 전개해보면 다음과 같다.
l o g p θ ( x ) = D K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ∣ x ) + L ( θ , ϕ ; x ) log\,p_\theta(x) =D_{KL}(q_\phi(z|x)||p_\theta(z|x)\,+\,L(\theta,\phi;x) l o g p θ ( x ) = D K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ∣ x ) + L ( θ , ϕ ; x )
D K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ∣ x ) D_{KL}(q_\phi(z|x)||p_\theta(z|x) D K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ∣ x ) q ϕ ( z ∣ x ) q_\phi(z|x) q ϕ ( z ∣ x ) p θ ( z ∣ x ) p_\theta(z|x) p θ ( z ∣ x )
L ( θ , ϕ ; x ) L(\theta,\phi;x) L ( θ , ϕ ; x ) ELBO ,
D K L D_{KL} D K L j e n s e n s ′ s I n e q u a l i t y 증명에 의거 ) jensens's~~ Inequality ~증명에 ~의거) j e n s e n s ′ s I n e q u a l i t y 증 명 에 의 거 ) l o g p θ ( x ) ≥ L ( θ , ϕ ; x ) log\,p_\theta(x) \geq L(\theta,\phi;x) l o g p θ ( x ) ≥ L ( θ , ϕ ; x ) L L L l o g p θ ( x ) log\,p_\theta(x) l o g p θ ( x )
해당 ELBO의 식을 보면 다음과 같다.
L ( θ , ϕ ; x ) = E q ϕ ( z ∣ x ) [ − l o g q ϕ ( z ∣ x ) + l o g p θ ( x , z ) ] L(\theta,\phi;x) = E_{q\phi(z|x)}[-log\,q_\phi(z|x)\,+\,log\,p_\theta(x,z)] L ( θ , ϕ ; x ) = E q ϕ ( z ∣ x ) [ − l o g q ϕ ( z ∣ x ) + l o g p θ ( x , z ) ] 이때 ,B a y e s R u l e Bayes\, Rule B a y e s R u l e
B a y s e R u l e : l o g p θ ( x , z ) = l o g p θ ( x ∣ z ) + l o g p θ ( z ) Bayse\, Rule:log\,p_\theta(x,z) =log\,p_\theta(x|z) +log\,p_\theta(z) B a y s e R u l e : l o g p θ ( x , z ) = l o g p θ ( x ∣ z ) + l o g p θ ( z ) 해당 공식을 위에 대입하면
E q ϕ ( z ∣ x ) [ l o g p θ ( x ∣ z ) ] + E q ϕ ( z ∣ x ) [ l o g p θ ( z ) ] − E q ϕ ( z ∣ x ) [ l o g q θ ( z ∣ x ) ] , E_{q\phi(z|x)}[log\,p_\theta(x|z)]\,+\,E_{q\phi(z|x)}[log\,p_\theta(z)]\,-E_{q\phi(z|x)}[log\,q_\theta(z|x)], E q ϕ ( z ∣ x ) [ l o g p θ ( x ∣ z ) ] + E q ϕ ( z ∣ x ) [ l o g p θ ( z ) ] − E q ϕ ( z ∣ x ) [ l o g q θ ( z ∣ x ) ] , 두 확률분포 q , p q,p q , p K L − d i v e r g e n c e KL-divergence K L − d i v e r g e n c e
D K L = E z ∼ q [ l o g q ( z ) − l o g p ( z ) ] D_{KL}=E_{z\sim q}[log\,q(z)-log\,p(z)] D K L = E z ∼ q [ l o g q ( z ) − l o g p ( z ) ] 위의 2번째 항과 3번째 항을 D K L D_{KL} D K L
= − D K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ) ) =-D_{KL}(q_\phi(z |x)||p_\theta(z)) = − D K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ) ) 이제 남은 첫번째 항과 해당식을 결합하면 다음과 같은 식을 얻는다
E L B O = E q ϕ ( z ∣ x ) [ l o g p θ ( x ∣ z ) ] − D K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ) ) ELBO =E_{q\phi(z|x)}[log\,p_\theta(x|z)]\,-D_{KL}(q_\phi(z |x)||p_\theta(z)) E L B O = E q ϕ ( z ∣ x ) [ l o g p θ ( x ∣ z ) ] − D K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ) )
이때 앞의 기댓값 항이 음의 재구성 오차 이며,(Latent variable로 복구된 결과 x에 대한 기댓값)정규화 부분 이다.
2.3 SGVB & AEVB algorithm
2.2에서 문제를 정의를 했다면 이제 해당 알고리즘을 풀어야 하는데,z z z
따라서 이를 위해 Reparameterization Trick 을 사용한다.
E q ϕ ( z ∣ x ) [ l o g p θ ( x ∣ z ) ] E_{q\phi(z|x)}[log\,p_\theta(x|z)] E q ϕ ( z ∣ x ) [ l o g p θ ( x ∣ z ) ] q ϕ ( z ∣ x ) q_\phi(z|x) q ϕ ( z ∣ x ) ϕ \phi ϕ l o g p θ ( x ∣ z ) log\,p_\theta(x|z) l o g p θ ( x ∣ z ) ϕ \phi ϕ
따라서 연구자들이 제시한 방법은 분포 q ϕ ( z ∣ x ) q_\phi(z|x) q ϕ ( z ∣ x ) deterministic 한 분포에서 샘플링 후 g ϕ g_\phi g ϕ
이렇게 재파라미터화 방법을 취하면 ϕ \phi ϕ g ϕ g_\phi g ϕ 명시적 함수 로서 표현 가능하다.
수식적으로 비교해보면, 기존 방식
z ∼ q ϕ ( z ∣ x ) = N ( μ ϕ ( x ) , d i a g ( σ ϕ 2 ( x ) ) z\sim q_\phi(z|x) = \mathcal{N}(\mu_\phi(x),\,diag(\sigma^2_\phi(x)) z ∼ q ϕ ( z ∣ x ) = N ( μ ϕ ( x ) , d i a g ( σ ϕ 2 ( x ) ) 재파라미터화 (가우시안)
z = g ϕ ( ϵ , x ) = μ ϕ ( x ) + σ ϕ ( x ) ⊙ ϵ z=g_\phi(\epsilon,x) =\mu_\phi(x) + \sigma_\phi(x)\odot\epsilon z = g ϕ ( ϵ , x ) = μ ϕ ( x ) + σ ϕ ( x ) ⊙ ϵ 따라서 z z z z z z ϕ \phi ϕ
Monte Carlo L ( θ , ϕ ; x ) L(\theta,\phi;x) L ( θ , ϕ ; x ) l o g p θ ( x ∣ z ) logp_\theta(x|z) l o g p θ ( x ∣ z )
해석적 계산∫ R d N ( z ; μ ϕ ( x ) , σ ϕ 2 ( x ) ) log p θ ( x ∣ z ) d z \int_{\mathbb{R}^d} \mathcal{N}(z; \mu_\phi(x), \sigma_\phi^2(x)) \log p_\theta(x|z) dz ∫ R d N ( z ; μ ϕ ( x ) , σ ϕ 2 ( x ) ) log p θ ( x ∣ z ) d z z z z p θ ( x ∣ z ) p_\theta(x|z) p θ ( x ∣ z )
수치적 적분∝ O ( N d ) ∝ O(N^d) ∝ O ( N d ) Monte Calro 근사를 활용한다.
몬테카를로 근사의 식은 다음과 같다
E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) ] ≈ 1 L ∑ l = 1 L log p θ ( x ∣ z ( l ) ) \mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)] \approx \frac{1}{L} \sum_{l=1}^{L} \log p_\theta(x|z^{(l)}) E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) ] ≈ L 1 l = 1 ∑ L log p θ ( x ∣ z ( l ) ) 재파라미터화로 샘플링 한 후 몬테카를로 근사를 적용하면
i n ϵ l ∼ N ( 0 , I ) , z l = g ϕ ( ϵ , x ) = μ ϕ ( x ) + σ ϕ ( x ) ⊙ ϵ l , in~~~~\epsilon^{l}\sim\mathcal{N}(0,I)~~, z^{l}=g_\phi(\epsilon,x) =\mu_\phi(x) + \sigma_\phi(x)\odot\epsilon^{l}, i n ϵ l ∼ N ( 0 , I ) , z l = g ϕ ( ϵ , x ) = μ ϕ ( x ) + σ ϕ ( x ) ⊙ ϵ l , E L B O : L ~ = 1 L ∑ l = 1 L log p θ ( x ∣ z ( l ) ) − D K L ( q ϕ ( z ∣ x ) ∥ p ( z ) ) ELBO:~~~~\widetilde{\mathcal{L}} = \frac{1}{L} \sum_{l=1}^{L} \log p_\theta(x|z^{(l)}) - D_{KL}(q_\phi(z|x) \| p(z)) E L B O : L = L 1 l = 1 ∑ L log p θ ( x ∣ z ( l ) ) − D K L ( q ϕ ( z ∣ x ) ∥ p ( z ) ) 따라서 재구성오차의 그래디언트 또한 근사가 가능하므로
재구성오차의 그래디언트∇ ϕ E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) ] ≈ ∇ ϕ log p θ ( x ∣ z ) \nabla_\phi \mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)] \approx \nabla_\phi \log p_\theta(x|z) ∇ ϕ E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) ] ≈ ∇ ϕ log p θ ( x ∣ z )
z z z ∂ z ∂ ϕ = ∂ μ ϕ ( x ) ∂ ϕ + ∂ σ ϕ ( x ) ∂ ϕ ⊙ ϵ \frac{\partial z}{\partial \phi} = \frac{\partial \mu_\phi(x)}{\partial \phi} + \frac{\partial \sigma_\phi(x)}{\partial \phi} \odot \epsilon ∂ ϕ ∂ z = ∂ ϕ ∂ μ ϕ ( x ) + ∂ ϕ ∂ σ ϕ ( x ) ⊙ ϵ 연쇄법칙∇ ϕ log p θ ( x ∣ z ) = ∂ log p θ ( x ∣ z ) ∂ z ∂ z ∂ ϕ \nabla_\phi \log p_\theta(x|z) = \frac{\partial \log p_\theta(x|z)}{\partial z} \frac{\partial z}{\partial \phi} ∇ ϕ log p θ ( x ∣ z ) = ∂ z ∂ log p θ ( x ∣ z ) ∂ ϕ ∂ z
전체 ELBO의 그래디언트∇ ϕ L ~ = ∇ ϕ log p θ ( x ∣ z ) − ∇ ϕ D K L ( q ϕ ( z ∣ x ) ∥ p ( z ) ) \nabla_\phi \widetilde{\mathcal{L}} = \nabla_\phi \log p_\theta(x|z) - \nabla_\phi D_{KL}(q_\phi(z|x) \| p(z)) ∇ ϕ L = ∇ ϕ log p θ ( x ∣ z ) − ∇ ϕ D K L ( q ϕ ( z ∣ x ) ∥ p ( z ) )
추가로, 가우시안 분포로 설정한다면 L은 다음과 같다.
L ( θ , ϕ ; x ( i ) ) ≈ 1 2 ∑ j = 1 J ( 1 + log ( ( σ j ( i ) ) 2 ) − ( μ j ( i ) ) 2 − ( σ j ( i ) ) 2 ) + 1 L ∑ l = 1 L log p θ ( x ( i ) ∣ z ( i , l ) ) \mathcal{L}(\boldsymbol{\theta}, \boldsymbol{\phi}; \mathbf{x}^{(i)}) \approx \frac{1}{2} \sum_{j=1}^{J} \left(1 + \log\left((\sigma_j^{(i)})^2\right) - (\mu_j^{(i)})^2 - (\sigma_j^{(i)})^2\right) + \frac{1}{L} \sum_{l=1}^{L} \log p_{\boldsymbol{\theta}}(\mathbf{x}^{(i)}|\mathbf{z}^{(i,l)}) L ( θ , ϕ ; x ( i ) ) ≈ 2 1 j = 1 ∑ J ( 1 + log ( ( σ j ( i ) ) 2 ) − ( μ j ( i ) ) 2 − ( σ j ( i ) ) 2 ) + L 1 l = 1 ∑ L log p θ ( x ( i ) ∣ z ( i , l ) ) where z ( i , l ) = μ ( i ) + σ ( i ) ⊙ ϵ ( l ) and ϵ ( l ) ∼ N ( 0 , I ) \text{where } \mathbf{z}^{(i,l)} = \boldsymbol{\mu}^{(i)} + \boldsymbol{\sigma}^{(i)} \odot \boldsymbol{\epsilon}^{(l)} \quad \text{and} \quad \boldsymbol{\epsilon}^{(l)} \sim \mathcal{N}(0, \mathbf{I}) where z ( i , l ) = μ ( i ) + σ ( i ) ⊙ ϵ ( l ) and ϵ ( l ) ∼ N ( 0 , I ) Algorithm
X M = ( x i ) i = 1 M X^M =({x^i})^M_{i=1} X M = ( x i ) i = 1 M i ~~i~~ i
노이즈 샘플링 ϵ ( i ) ∼ N ( 0 , I ) \epsilon^{(i)} \sim \mathcal{N}(0, I) ϵ ( i ) ∼ N ( 0 , I )
인코더 forward pass μ ( i ) , log σ 2 ( i ) = encoder ϕ ( x ( i ) ) \mu^{(i)}, \log \sigma^{2(i)} = \text{encoder}_\phi(x^{(i)}) μ ( i ) , log σ 2 ( i ) = encoder ϕ ( x ( i ) )
재파라미터화 z ( i ) = μ ( i ) + σ ( i ) ⊙ ϵ ( i ) z^{(i)} = \mu^{(i)} + \sigma^{(i)} \odot \epsilon^{(i)} z ( i ) = μ ( i ) + σ ( i ) ⊙ ϵ ( i ) where σ ( i ) = exp ( 1 2 log σ 2 ( i ) ) \text{where } \sigma^{(i)} = \exp\left(\frac{1}{2} \log \sigma^{2(i)}\right) where σ ( i ) = exp ( 2 1 log σ 2 ( i ) )
디코더 forward pass x ^ ( i ) = decoder θ ( z ( i ) ) \hat{x}^{(i)} = \text{decoder}_\theta(z^{(i)}) x ^ ( i ) = decoder θ ( z ( i ) )
3.loss 계산
재구성오차 : L recon ( i ) = − log p θ ( x ( i ) ∣ z ( i ) ) ~~\mathcal{L}_{\text{recon}}^{(i)} = -\log p_\theta(x^{(i)} | z^{(i)}) L recon ( i ) = − log p θ ( x ( i ) ∣ z ( i ) )
D K L l o s s D_{KL}~loss D K L l o s s L K L ( i ) = 1 2 ∑ j = 1 J ( ( μ j ( i ) ) 2 + ( σ j ( i ) ) 2 − log ( σ j ( i ) ) 2 − 1 ) \mathcal{L}_{KL}^{(i)} = \frac{1}{2} \sum_{j=1}^{J} \left( (\mu_j^{(i)})^2 + (\sigma_j^{(i)})^2 - \log(\sigma_j^{(i)})^2 - 1 \right) L K L ( i ) = 2 1 ∑ j = 1 J ( ( μ j ( i ) ) 2 + ( σ j ( i ) ) 2 − log ( σ j ( i ) ) 2 − 1 ) 전체 손실: L ~ ( i ) = L recon ( i ) + L K L ( i ) \widetilde{\mathcal{L}}^{(i)} = \mathcal{L}_{\text{recon}}^{(i)} + \mathcal{L}_{KL}^{(i)} L ( i ) = L recon ( i ) + L K L ( i )
미니배치 손실:L ~ ( i ) = L recon ( i ) + L K L ( i ) \widetilde{\mathcal{L}}^{(i)} = \mathcal{L}_{\text{recon}}^{(i)} + \mathcal{L}_{KL}^{(i)} L ( i ) = L recon ( i ) + L K L ( i )
U p d a t e : Update:~ U p d a t e : θ ← θ − α ∇ θ L ~ M , ϕ ← ϕ − α ∇ ϕ L ~ M \theta \leftarrow \theta - \alpha \nabla_\theta \widetilde{\mathcal{L}}^M , ~~~~~~\phi \leftarrow \phi - \alpha \nabla_\phi \widetilde{\mathcal{L}}^M θ ← θ − α ∇ θ L M , ϕ ← ϕ − α ∇ ϕ L M