
1. 개요
해당 논문은 생성형 모델의 고질적 문제인 tractability와 flexibility 사이의 trade-off를 해결하고자 했다.
Tractability : 수치적으로 계산이 가능하다, 즉 분석을 할 수 있음을 의미하고
Flexibility: 임의의 데이터에 대해서 유연히 fit 하게 맞출 수 있음을 의미한다
이를 해결하기 위해 저자들은 Well-known된 분포에서 target data 분포로 점진적으로 변환하는 방식으로 생성형 모델을 설계했으며, 보다 핵심적으로 Markov chain을 사용하였다.
이 diffusion의 개념을 발전시켜 loss term과 parameter estimation 과정을 더 학습이 잘 되도록
발전시킨 model이 바로 2020년 NeurIPS에서 공개된 'Denoising Diffusion Probabilistic Models'이다.

Diffusion은 해당 원본이미지 에서 부터 noise(Gaussian Noise)를 미리 정의된 스케줄 에 따라 추가하는 Forward diffusion process와 부터 원본 이미지 까지 복원해나가는 reverse denoising process로 나뉜다.
해당 프로세스 과정들은 Markov process 즉 현재상태 가 이전 상태인 에만 영향을 받는 특성을 지닌다.
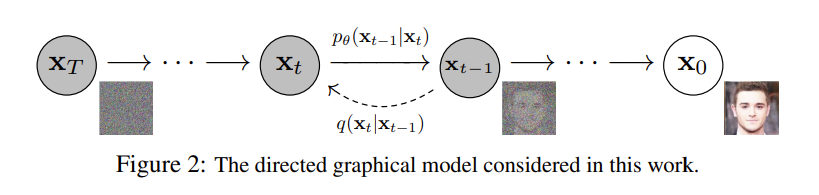
원본 이미지 에서 잘 알려진 노이즈를 추가하는 것은 쉬워보이지만, 에서, 즉 Random한 Gaussian Noise에서 원래 이미지를 복원하는 것은 어려워 보이는데, 해당 논문에서는 이를 수식적인 접근 및 알고리즘으로 구현했다.
2. Back Ground
먼저, DDPM에서는 순방향 프로세스를 (노이즈를 섞는) Diffusion Process라고 정의하고, 역방향 프로세스를(복원하는) Inverse Process라고 정의한다.
해당 프로세스들이 Gaussian markov chain을 가정했으므로 베이즈 룰에 의거해서 다음과 같이 정의된다.(전이확률)
Diffusion Process =
Inverse Process =
즉 디퓨전은 의 상태에서 로 전이하는 프로세스를 의미하며 Inverse Process는 그 역이다. DDPM의 목적은 Random Gaussian Noise에서 원 상태의 이미지를 generate하는 것이므로 해당 과정을 학습하는 것이고, 따라서 Gaussian Markov chain의 모수인 를 Parameter로 두어 이를 학습한다.
이에 따라, Inverse Process의 표현도 로 표현한다.
그렇다면 어떻게 해당 함수를 generate할까?
3. Diffusion loss function
Diffusion Loss Function
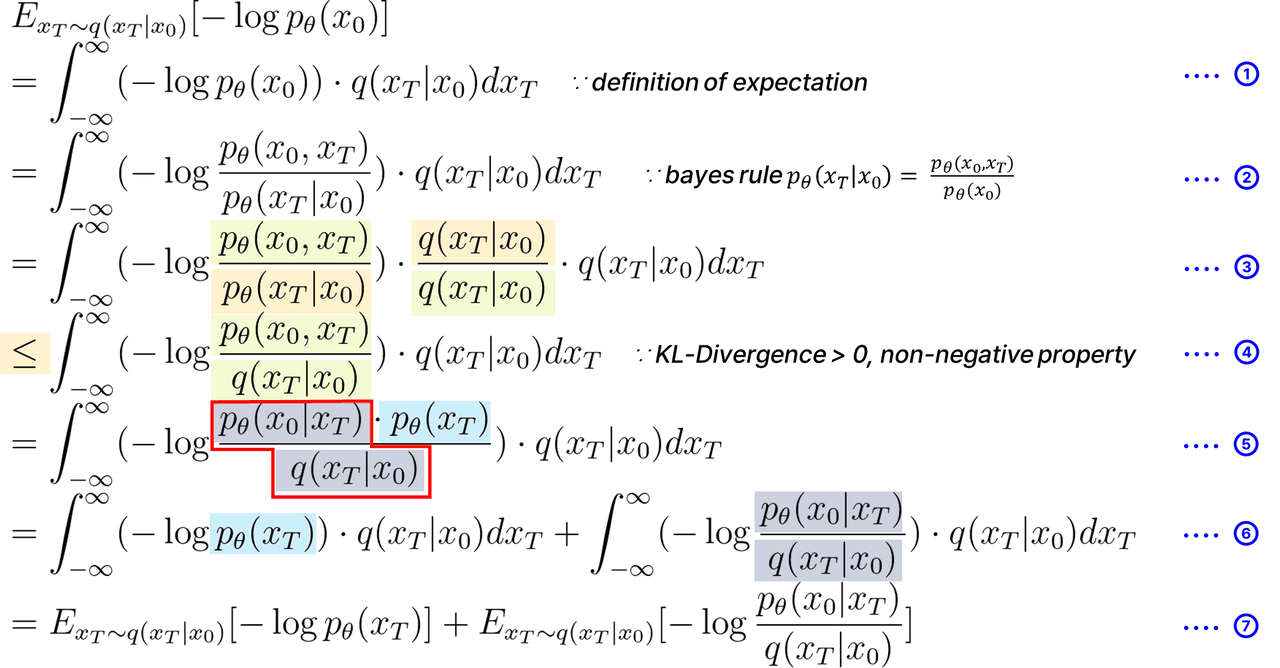
해당 DDPM의 Loss function은 VAE의 Lossfunction의 변형으로 볼 수 있다.
해당 식은 원본 이미지 의 등장 확률을 maximize해야 하므로 위의 식에서는 음의 로그우도로 변환 , 을 minimize하는 식으로 전개한다.
해당 2번식에서 Bayes rule을 적용하고,
4번 식에서 KL-발산의 non-negative property가 적용되어 부등호로 변환 하였다.
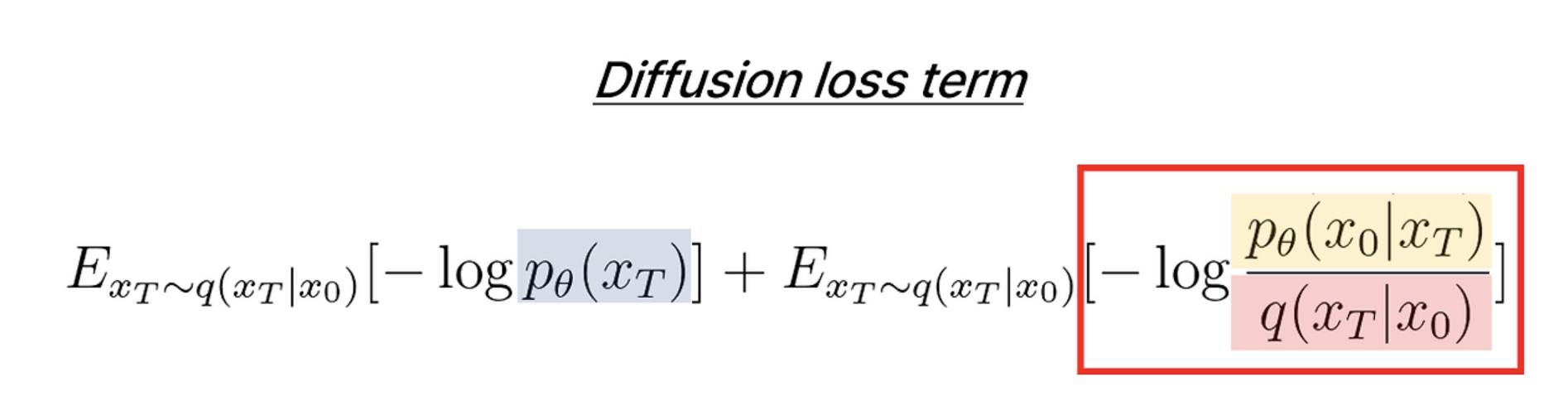
해당 마지막 식과 KL-Divergence의 식을 참고하면 KL 발산(Kullback–Leibler divergence)은 두 확률분포 간의 차이를 측정하는 비대칭적인 척도이므로
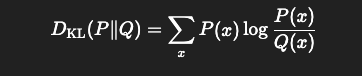
결국 과 간의 KL-divergence,즉 '두 확률 분포간의 차이를 재는 비대칭적 거리척도'를 최소화 하는 문제로 볼 수 있다.
해당 p,q noise가 Gaussian distribution을 따르고 있음을 알고있으므로

해당 공식들이 사용된다 (후술)
4. Intractable Diffusion loss function
위에서 유도한 Diffusion loss는 사실상 저 형태로는 계산이 불가하므로 형태의 공식으로 바꿔야 한다. 즉, Intractable한 Diffusion loss의 우항의 을 tractable 하도록 markov chain property를 사용함과 동시에 time step t가 discrete하므로 로 나타내는 것이다. 전체 전개식은 다음과 같다...

해당 식의 전개식은 해당 링크에서 후술 -> 수정

마지막 식만 보면 해당 식을 t에 대한 loss, t-1에 대한 loss, 0에 대한 loss로 나눌 수 있는 것을 확인할 수 있다.
논문에서는 다음과 같이 서술한다.
①
DDPM에서는 diffusion process 과정에서 noise의 주입정도를 사전에 정해진 schedule에 따라 fixed하였기에 별도의 학습가능한 parameter를 설정해두지 않은 으로 정의하였다. 또한 DDPM에서는 diffusion process q는 를 항상 gaussian distribution을 따르도록 하기 때문에 와 는 다를게 없을 정도로 거의 유사하여 결과적으로, 는 항상 0에 가까운 상수가 나온다고 한다. 따라서 는 학습과정에서 무시한다.
②
은 무수히 많은 t중 단일 시점에서의 로그우도 값이므로 무시한다.
따라서 해당 문제는 의 minimize로 변한다.
DDPM에서는 이를 간소화하여 tractable하고 parameter estimation을 더욱 쉽게 제안한다.
해당 간소화 수식은 해당 링크에서 서술 -> 후술
결과적으로 다음과 같은 간소화된 Loss function이 만들어진다.

학습과 샘플링과정은 다음 알고리즘과 같이 진행된다.

학습과정을 추가로 설명하자면, 역방향 에서는 모델이 입력된 noise img 에서 원래 추가된 noise 을 정확히 예측하도록 학습한다.
in (각 단계별 노이즈 감소계수),
(누적 감쇠 계수)
이고,
은 알다시피 이므로 해당 는 다음과 같다.
따라서 Step Gradient는 가 된다.
추가로, parameterization을 한 를 Objective Function에 대입하면
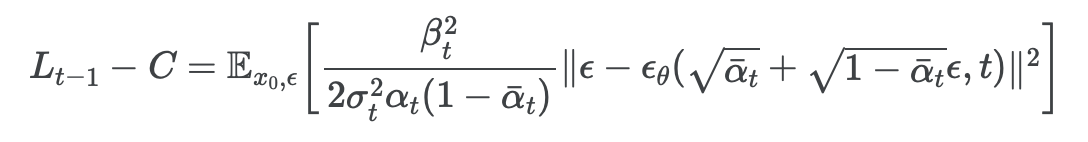
인데, 이는 여러 noise 레벨에서의 denoising score matching과 유사하며 Langevin-like reverse process의 variational bound과 같다.
U-net을 활용한 이미지 분석결과는 다음에..

깔끔하게 정리해주셔서 보기 좋았습니다! 감사합니다~