HINet: Half Instance Normalization Network for Image Restoration
CVPR 2021 Workshop에 게재된 논문.
Contribution: NTIRE 2021 Image Deblurring Challenge Track2에서 1위 달성
https://arxiv.org/abs/2105.06086
기존의 Image Classification, Object Dection, Segmentation등의 High-level Vision Task에서는 BN, IBN, LN, GN 등의 Normalization의 성능이 매우 뛰어났지만,
Denoising, Deblurring, Deraining, Super-resolution등의 Task에서는 normalization이 range Flexibility이 상실되므로 사용되지 않았다.
이는 Batch Normalization의 통계적 불안정성으로부터 비롯되는데,
해당 배치 크기가 작으면, 샘플 평균/분산의 Variance가 증가하므로, 배치마다 통계량이 크게 변동하며, 따라서 불안정한 학습으로 이어질 수 밖에 없다.
low - level task인 image resolution이나, deblurring은 배치크기가 32, 2인 경우가 많으므로 해당 task에 BN을 적용하면 성능이 떨어질 수 밖에 없다.
Instance Normalization
이를 극복하기 위해서 Style transfer task에서는 Instance Normalization의 사용이 제안되었다.
Instance Normalization 이란 2016년 Dmitry Ulyanov등이 제안한 기법으로 주로 스타일 전이 작업에 사용된다.
이는 각 샘플(여기선 이미지)에 대해 평균과 분산을 계산하고, 계산된 평균과 분산으로 입력을 정규화, ,의 스케일, 시프트 파라미터를 적용한다. (Learnable parameters)
Architecture
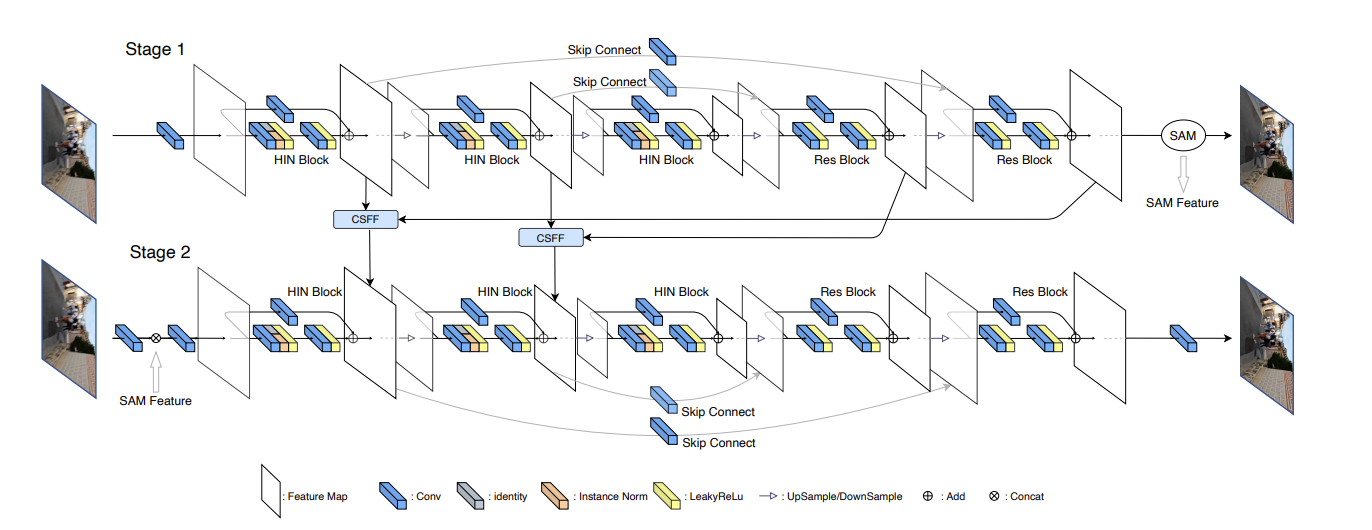
HINet은 U-net의 구조를 사용한 multi-stage 방식으로서, SAM과 CSFF를 차용하여 설계되었다.
전반적인 구조는 다음과 같다. 두개의 sub-network로 구성된 HINet은 initial feature의 추출을 위해 3x3의 conv layer를 사용하며 이는 4개의 downsampling과 upsampling을 수행하는 block들을 가진 encoder-decoder로 연결된다.
Encoder는 HIN Block 여러개를 쌓아 구성한다. 이를 통해 down sampling이 진행될 때, feature에 대한 수용력과 robustness가 증가하는 효과를 가진다.
Decoder는 high-level feature의 효율적인 추출을 위해 ResBlock으로 구성된다. 동시에 resampling 과정에서 수반되는 정보의 손실을 최소화하기위해 encoder에서 전달받은 특성들을 적절히 섞어주는 역할을 한다.
최종적으로는 3x3의 conv layer를 통해 재구성된 image의 잔차를 반환한다.
부가적으로 attention module로써 CSFF와 SAM이 활용되었다. CSFF는 3x3의 conv layer를 통해 다음 stage로의 통합을 위해 feature를 변환시키는 역할을 하는데, 이는 다음 stage에서의 feature representation을 풍부하게 만들어준다.
SAM은 유용한 feature는 다음 stage로 잘 전달되도록 하는 역할을 하지만, 그렇지 못한 부분은 attention mask를 통해 가림으로써 feature 전달의 효율성을 높여준다.
마지막으로 loss function은 PSNR 기반을 사용했다. 다만 단순히 output image와 ground truth의 비교가 아닌, 각 sub-network의 input image와 output을 더한 것을 ground truth를 비교하는 방식으로 PSNR loss를 정의했다.
Half Instance Normalization Block(HIN Block)
앞에서 서술한 Low -Level Task에서의 BN적용의 부적절성으로 인해, 저자들은 대안으로 IN을 활용한 HIN Block을 제안한다. 구조는 다음 그림과 같다.
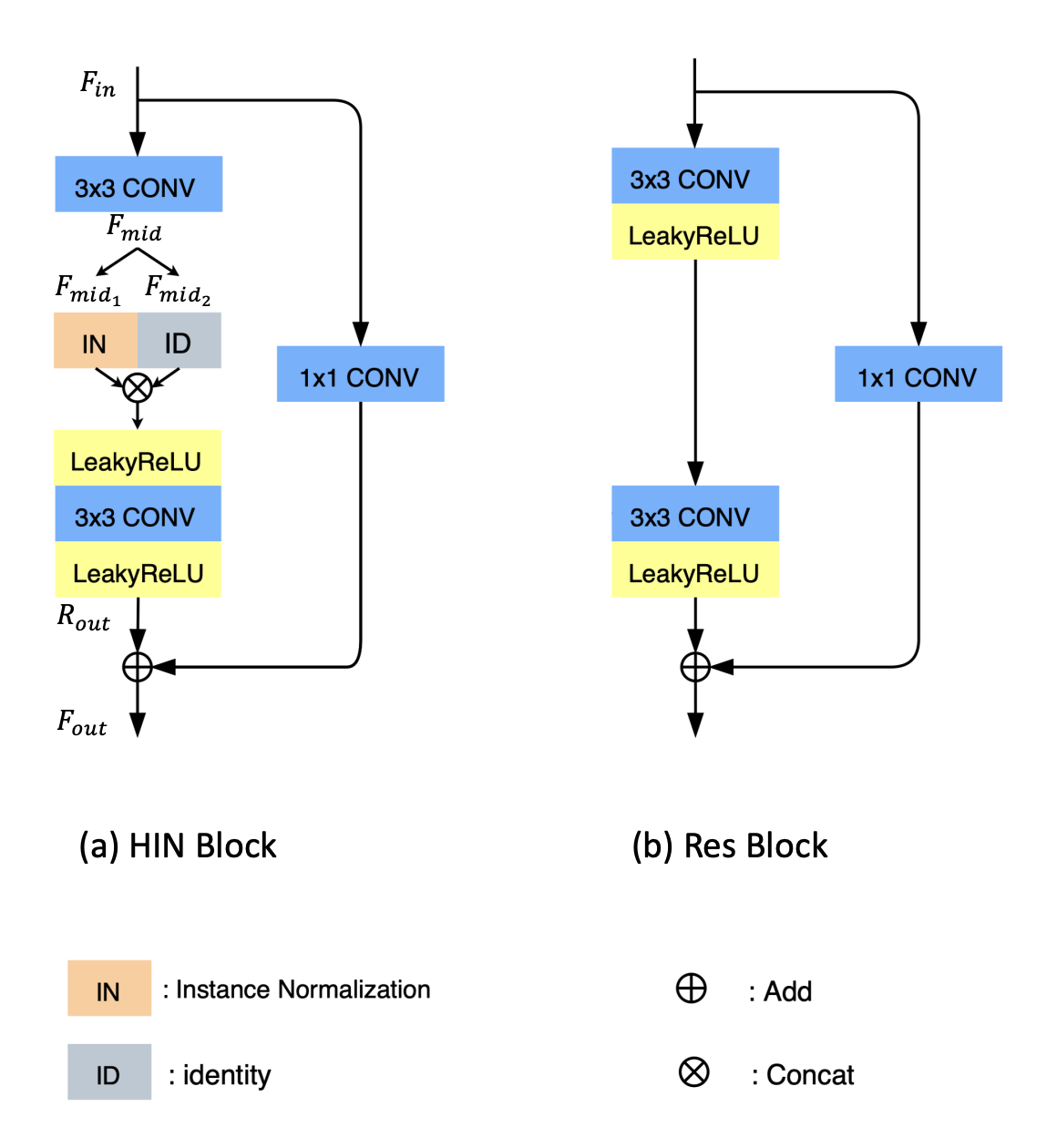
HIN Block은 Input Feature에 대해 절반만 IN을 적용하는 block이다.
구체적인 과정을 보면 Input feature가 3x3 conv layer를 거쳐 가 산출된다. 는 두 파트로 나누어지는데, 오직 한 부분에서만 IN을 수행하고 나머지 부분과 concat된다.
즉 IN을 half part에만 적용하며 나머지 half에 대해서는 channel의 정보들을 보존할 수 있도록 한다. 이후 LeakyReLU와 3x3 conv layer를 거친 output이 shortcut feature와 더해져 block의 output인 을 산출한다.
수식으로 간단하게 본다면 다음과 같다.
- Feature 분할(채널별)
,
- Instance Normalization 적용
첫 번째 절반 ( X_1 ) 에 대해 IN을 적용:
여기서 각 instance ( b ) 와 channel ( c ) 에 대해:
: 수치 안정성을 위한 작은 상수(Zero by division 방지)
- Feature 결합 (Concatenation)
전체 HIN 연산
Experiments & Results
실험에서 수행한 task는 Denoising, Deblurring, Deraining으로 3가지이다. 각각 SIDD와 GoPro, REDS 그리고 Rain 13k를 사용해 SSIM과 PSNR을 metric으로 사용했다. 추가로, MACs와 inference time를 측정해 기존 network와 비교했다. 학습시에는 2e-4의 learning rate와 1e-7의 cosine annealing을 사용했으며 256x256 크기의 patch로 flip과 rotation을 적용했다.
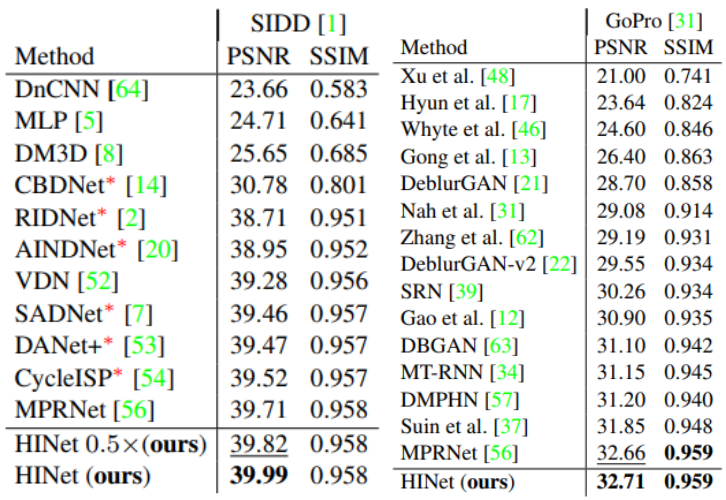
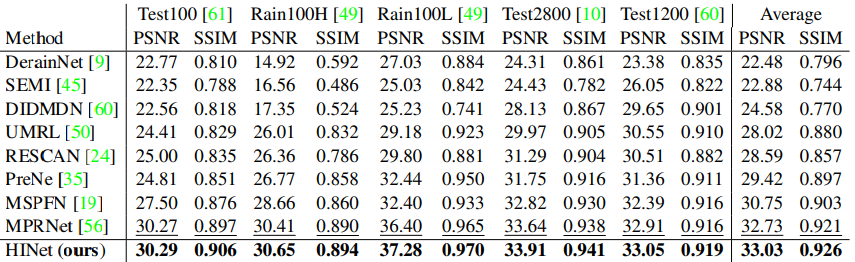
결과적으로 모든 dataset에서 SOTA를 달성했다. MACs 부분에 있어서도 이전 sota인 MPRNet과 비교했을 때, 매우 큰 차이로 더 좋은 연산 효율성을 보였으며 추론시간에 있어서도 SIDD에서는 3배 REDS&GoPro에서는 6배 이상의 빠른 속도를 보여주었다. 이는 계산적으로도 연산량이 적으며 동시에 성능적인 측면에서 더 높은 질을 보여주는 것으로 아주 훌륭하게 task들을 수행했다는 것을 의미한다.
Ablation
HINet의 핵심은 'HIN' 이다. 따라서 저자들은 해당 Block의 우수성과 효용성을 입증하기위해 몇가지 ablation case에 대한 실험을 추가로 보여준다.
The effectiveness of Half Instance Normalization

앞선 실험에서의 결과는 HIN Block에서 기인한 결과라는 가정을 세우고, 저자들은 여러 모델에 HIN Block을 도입했을 때 나타나는 결과의 차이를 비교해 제시했다. HINet와 DMPHB, PRMID, CycleISP에 HIN의 사용 유무에 따른 성능 차이를 비교했는데, 모든 경우에서 HIN의 사용이 더 높은 score를 달성해 그 우수성을 입증했다.
Comparision with other Noramlization
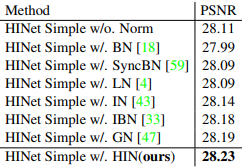
해당 부분은 연구 동기에 부합하는 가장 핵심적인 부분이다. 본 논문은 기존 normalization의 한계점에서 기인해 이를 개선하고자 시작된 연구로, 다른 normalization을 적용했을때와 비교했다. BN을 포함해 LN, IN등을 적용한 HINet을 사용한 결과 역시 HIN의 경우가 가장 좋았으며 특히 BN은 심각한 성능의 저하가 나타났다. 특히 full IN을 사용했을때보다 HIN을 사용한 것이 더 효과적이라는 점은 괄목할만한 점이라고 할 수 있다.
Comparision with other Noramlization
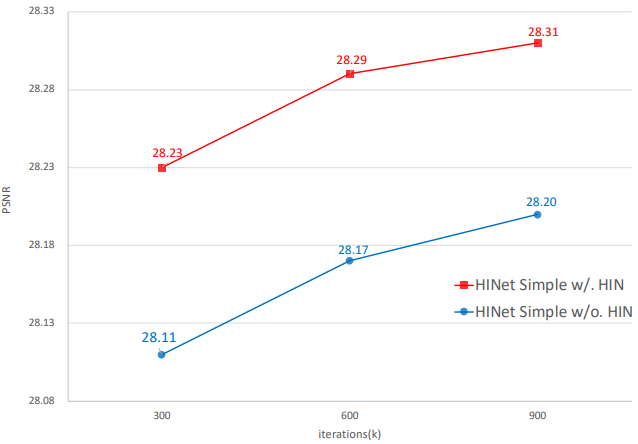
학습시 iterations의 증가와 HIN의 사용여부에 따른 성능 향상의 폭을 측정했다. 마찬가지로 HIN을 사용한 경우가 더 높은 성능을 보여주며, 사용하지 않은 경우와의 차이는 iteration이 증가해도 감소하지않는다. HIN은 모델의 수렴속도를 빠르게 해주는 것 뿐만 아니라 성능의 상한선 역시 높여주는 역할을 하고있다.
Guideline of add HIN layer in an existing network
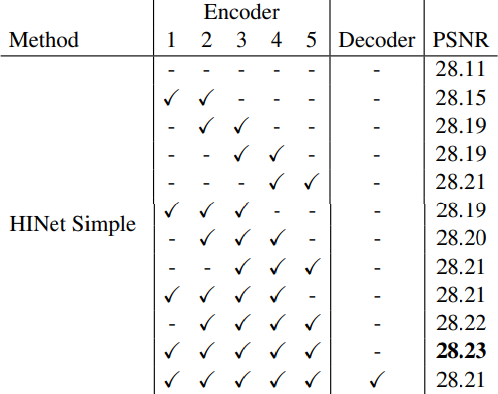
앞선 ablation study를 통해 HIN의 효과는 충분히 입증되었다. 마지막으로 저자는 HIN layer의 최적 위치를 찾기 위한 실험을 진행했는데, 결론적으로 encoder block 모두에 HIN을 배치하고, decoder에는 배치하지 않는 것이 가장 좋았다. 따라서 HIN의 무조건적인 추가가 긍정적인 영향으로 반드시 이어지지는 않으며, 적절한 위치산정의 필요성을 역설한다.
한계
항상 고정비율이 50:50으로 고정되어 있기 때문에 유연성 부족으ㅜ로 다양한 시나리오에 적응하기 어려우며, 채널을 단순히 절반으로 나누기 때문에 채널간의 의미론적 관계를 고려하지 않아, Style 정보/ Contents 정보를 어떤 채널이 담고있는지를 학습할 수 없다.
추가
PSNR과 SSIM
PSNR과 SSIM은 영상 품질을 평가할 때 자주 쓰이는 두가지 대표적인 지표이다. 둘다 "얼마나 원본에 가까운가?"를 측정하지만, 접근 방식과 수식 구조가 완전히 다르다.
PSNR(Peak Signal to Noise Ratio)
PSNR은 신호 대 잡은비를 로그 스케일로 표현한 것이다.
원본 이미지와 복원(혹은 재구성) 이미지의 픽셀 단위 차이 (MSE)를 기반으로 계산한다.
SSIM(Structural Similarity Index)
SSIM은 사람의 시각적 인지 특성을 모방하여 밝기(Luminance), 대비(Contrast), 구조(Structure)를 비교한다.
: 각 이미지의 평균 밝기
: 각 이미지의 분산
: 공분산
: 수치 안정성을 위한 작은 상수
해피추석 ^^
