[논문리뷰] Time LLM - Time Series Forecasting by reprogramming large language model
Arxiv link
https://arxiv.org/pdf/2310.01728
Github link
https://github.com/KimMeen/Time-LLM?tab=readme-ov-file
Abstract
Pre-trained foundation model은 NLP와 CV에서 좋은 성능을 달성했지만, time series에서는 data sparsity때문에 발전이 제한되었다. 최근 연구들은 LLM이 complex sequence of token에서 pattern recognition과 reasoning ability를 가지고 있음을 입증했으나, 이러한 능력을 time series에 적용하기 위해서는 modality를 일치시키는게 중요하다. 따라서 이 연구는 LLM의 backbone은 유지한 채 time series의 forcasting을 위해 LLM을 reprograming하는 Time-LLM을 제안한다. time series를 text prototype으로 재구성 한 뒤 이를 LLM에 입력하여 modality를 일치시킨다. LLM의 time series 추론 능력 향상을 위해 input context를 풍부하게 하고 reprogrammed input patches의 변환을 가능하게 하는 Prompt-as-Prefix(PaP)를 제시한다.
Introduction
time series forcasting은 다양한 real-world에 적용되고 있지만, 각 task는 domain과 그 작업에 특화된 모델 설계가 필요하다. 반면 LLM은 단일 모델에서도 few-shot이나 zero-shot과 같은 NLP Task를 잘 수행할 수 있다.
LLM을 forcasting task에 적용하기 위해서는 여러 필요 조건이 있다.
Generalizability : LLM은 few-shot, zero-shot transfer learning에서 좋은 성능을 보인다. 이는 task에 따라 모델을 재학습하지 않고도 domain간에 forcasting을 수행할 수 있는 잠재력이 있다고 볼 수 있다.
Efficiency : LLM은 pre-training knowledge를 이용하여 새로운 task를 few example만을 이용하여 수행할 수 있다. 이는 historical data가 제한된 상황에서의 forcasting을 가능하게 할 수 있다.
Reasoning : LLM은 복잡한 추론과 패턴인식 문제에서 좋은 성능을 보여 왔다. 이러한 high-level concept를 이용하여 정밀한 예측을 가능하게 할 수 있다. 반면 기존 방법들은 통계적 기법에 의존하는 경우가 많다.
Multimodal knowledge : LLM의 구조와 training technique이 발전함에 따라, 여러 modality (vision, text, speech…)에서 다양한 지식을 습득한다. 이러한 특징은 여러 data type을 융합하여 forcasting을 수행할 수 있는 잠재력이 있다.
Easy optimization : LLM은 대규모 데이터셋에 대해 한번 학습되면, 모델을 다시 처음부터 짜고 학습할 필요 없이 forcasting을 수행할 수 있다. 반면 기존의 방법들은 아키텍쳐를 구현하고 하이퍼파라미터를 튜닝하는 작업이 필요하다.
이러한 특징들을 이용하기 위해서는 time series data와 natural language간의 modality를 일치시키는 작업이 필요하다. 하지만 LLM은 discrete token을 다루는 반면 time series는 continous하기 때문에 이는 어려운 작업이다. 게다가 time series 패턴 해석을 위한 knowledge와 reasoning 능력은 LLM의 pre-training만으로는 얻어지지 않는다. 따라서 task-agnostic, data-efficient, accurate한 방식으로 LLM의 능력을 time series에 적용하는 것이 문제라고 볼 수 있다.
이 연구에서는 LLM의 backbone을 수정하지 않으면서도 LLM에 time series forcasting을 가능하게 하는 reprogramming framework인 Time-LLM을 제안한다. 중요한 아이디어인 reprogram은 input time series를 LM에 더 적합한 text prototype representation으로 변환하는 것이다. 또한 time series에 대한 모델의 reasoning ability를 강화하기 위해 Prompt-as-Prefix(PaP)를 제시한다. 이는 시계열 입력에 추가적인 context를 추가하고 자연어 modality로 task instruction을 제공한다. 모델의 출력은 time series forcasting을 생성하기 위해 projected된다. 추가적으로 reprogramming approach를 통해 기존 모델들보다 뛰어난 성능을 보이는 few-shot, zero-shot time series 학습 또한 가능하다는 것을 입증한다.
Methodology
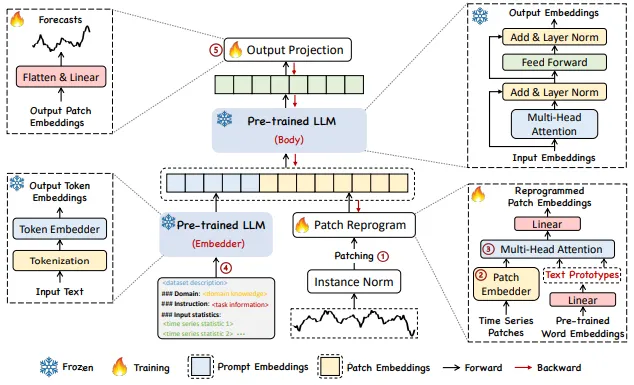
여기서 제시하는 방법은 크게 3가지로 이루어진다.
- input transformation
- pre-trained and frozen LLM
- output projection
N개의 feature을 가지는 MTS는 N개의 UTS로 변환되어 독립적으로 처리된다. i번째 series는 로 표기되며, 이는 normalization, patching, embedding을 거쳐 모델에 학습된 text prototype으로 reprogram되어 source and target modalities를 일치시킨다. 이후 reprogram된 patch와 프롬프트를 LLM에 추가하여 추론 능력을 강화하고, 마지막 출력을 최종 예측 로 projection한다. 이 과정에서 입력의 변환과 출력층의 파라미터만 업데이트되며, 모델이 backbone은 고정된다.
where p : # of patch, : len of patch, : Embedding dimension
where V : vocabulary size, V’ << V
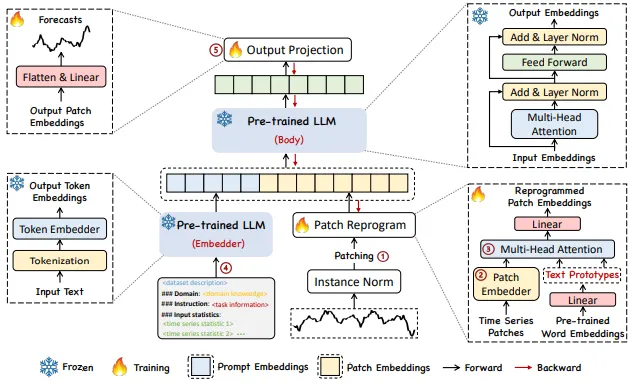
Input Embedding : 각 input channel 는 우선 reversible instance normalization (RevIN)을 통해 개별적으로 정규화된다. 이후 를 의 길이를 가진 overlapped or nonoverlapped patch로 나눈다. 따라서 input patch는 개가 된다.(S는 stride) 이 작업의 목적은 1) 각 패치에 local semantic information을 잘 보존할 수 있게 하는 것과 2) sequence의 길이를 줄여 연산 자원의 소모를 줄인다. 에서 linear layer을 이용하여 의 차원을 생성한 뒤 으로 임베딩한다.
Patch Reprogramming : 여기서는 TS와 NL의 modality를 일치시켜 모델의 TS 이해 및 추론 능력을 향상시키기 위해 patch embedding을 source data representation space로 reprogram한다. 일반적인 방법으로는 noise의 형태를 학습하는 것으로, target input sample을 적용할 때 pre-train된 모델이 파라미터 업데이트 없이도 원하는 target output을 생성할 수 있도록 하는 것이다. 이는 비슷하거나 동일한 modality를 연결하는 데 사용되지만, TS는 직접 편집하거나 NL로 완전하게 설명되기 어렵다. 따라서 연산 자원을 많이 사용하는 fine tuning을 이용하여 LLM을 활용하여야 한다.
이를 해결하기 위해 backbone model에 학습된 word embedding 을 사용하여 을 reprogramming할 것을 제안한다 (V는 vocabulary size). 다만 어떤 토큰들이 연관되어 있는지 모르게 때문에 를 직접적으로 이용할 경우 매우 큰 reprogramming space가 생길 수 있다. 이를 해결하기 위해 를 이용한다.
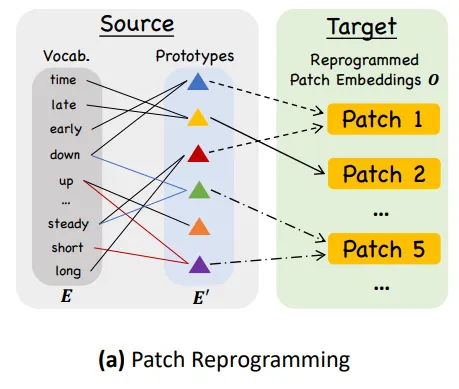
그림에서 Vocab으로 표시된 원래 단어 집합에서 word2Vec 형식 (단어 간 유사도를 반영할 수 있음) 을 통해 E’를 제작함. short+up, steady+down으로 prototype을 제작하고, 이 둘의 결합으로 patch 5는 “short up then down steadily”와 같은 의미 정보를 표현할 수 있다. 이를 구현하기 위해 text prototype과 time series patch는 Cross Multi head attetion을 사용한다.
각 head 에 대해 query matrixes ,
key matrix , value matrix 를 정의한다.
따라서 각 attention head에서 TS patch를 reprogramming하는 작업은 다음과 같이 정의된다.
각 를 모든 헤드에서 concat하여 를 얻는다. 이후 모델의 hidden demention에 맞춰 linear projection을 수행하여 를 얻는다.
Prompt-as-Prefix : 프롬프트는 LLM에서 작업을 활성화하는데 있어 가장 간단한 접근 방식이다. 이 연구의 모델에 적합한 프롬프트를 prefix로 이용하여 input context를 더욱 풍부하게 하며 TS patch에 대한 정보를 제공한다. 이를 Prompt-as-Prefix(PaP)라고 명명하고, LLM의 적응성을 향상시키며 patch reprogramming을 보완하는 것을 발견하였다.
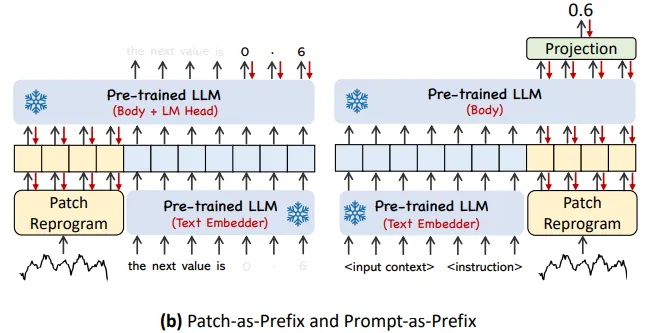
2가지 접근법이 있는데, 좌측은 patch as prefix이다. 시계열의 이어지는 예측값을 prompt로 주는 방식인데, 여기에는 1) LM은 정밀한 숫자를 처리하는 능력이 부족하며 2) 정밀한 숫자를 예측하고 생성하는 과정에서 서로 다른 토큰화 타입으로 인해 언어 모델마다 각각의 post processing이 필요하다. 결과적으로 예측이 자연어 형태로 표현되는게 다른데, [‘0’, ‘.’, ‘6’, ‘1’]와 [‘0’, ‘.’, ‘61’] 이런식으로 된다.
우측은 prompt as prefix로 이러한 제약조건이 없다. 이를 구성하기 위해 3가지 구성 요소들을 준비하는데, 1) data context, 2) task instruction, 3)input statistic으로 구성된다.
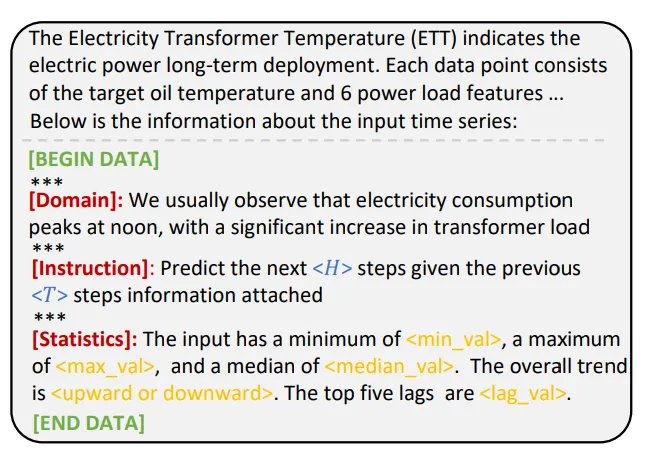
이를 통해 LLM에게 도메인별로 다른 background information을 제공하고, 특정 작업을 수행하는 데 patch embedding에 도움을 준다.
Output Projection : 프롬프트와 patch embedding을 LLM에 입력하여 출력을 얻는다. 그리고 이를 Linear layer에 입력하여 선형 투영한 뒤 최종 예측을 도출한다.
Main Results
backbone model로는 기본적으로 Llama-7B를 사용한다.
baselines
- Transformer-based methods : PatchTST, ESTformer, Non-Stationary Transformer, FEDformer, Autoformer, Informer, and Reformer.
- Recent competitive models : GPT4TS, LLMTime, DLinear, TimesNet, and LightTS.
추가적으로 short-term forecasting을 위해 N-HiTS, N-BEATS를 이용한다.
Long-term forecasting
ETTh1, ETTh2, ETTm1, ETTm2, Weather, Electricity (ECL), Traffic, ILI dataset에 대해 Long-term forecasting을 진행했다. input Time series length T는 512이며, 4개의 prediction horizons 에 대해 forecasting을 진행한다.
Red: best performance, Blue: second best를 나타낸다.
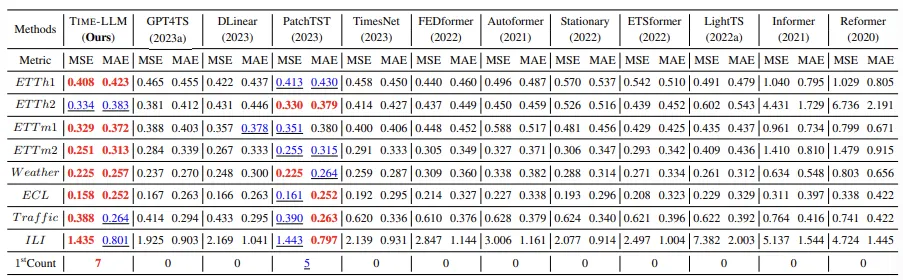
거의 모든 경우에서 baseline의 성능을 뛰어넘음. GPT4TS는 backbone language model을 fine tuning하는 본 연구와 결이 비슷한 연구인데, 이보다 12% 좋은 성능을 얻었음. smallest Llama를 reprogramming하는 SOTA model인 PatchTST의 경우 MSE에서 1.4%의 개선을 이루어 냈다.
Short-term forecasting
marketing data를 다른 주기로 샘플링한 M4 dataset을 testbed로 사용하여 진행한다. prediction horizons 내의 값으로 설정되었으며, input length는 H의 2배로 설정된다.

모든 baseline을 능가하는 성능을 달성했으며, GPT4TS보다 8.7% 성능이 증가함. SOTA인 N-hiTS보다도 좋은 성능을 달성하였음.
Few-shot forecasting
LLM의 경우 few-shot learning에 대해 그 성능이 입증된 바 있음. 여기서는 LLM을 training data를 적게 주고 성능을 평가하였음.
- Training data의 10%만으로 few shot learning 진행
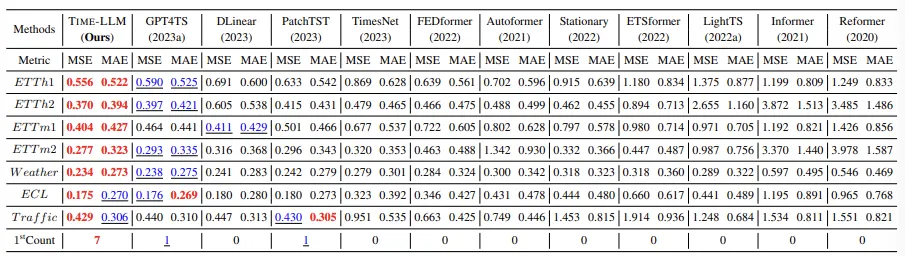
GPT4TS보다 5%의 MSE 감소를 이끌어 냈으며, LLM에 대한 fine-tuning 없이도 이러한 성능을 달성하였다.
- Training data의 5%만으로 few shot learning 진행
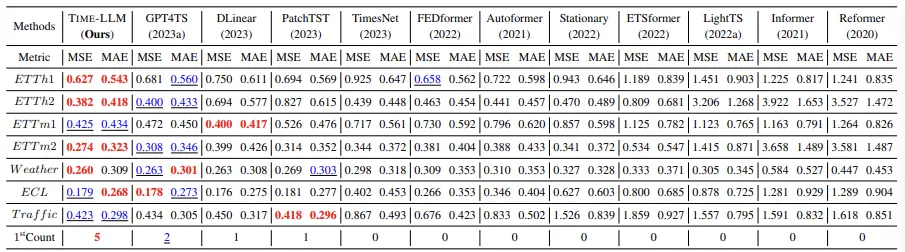
GPT4TS와 비교했을 때 5%의 성능 향상이 일어났음.
특기할만한 사항은 Time-LLM과 GPT4TS가 다른 baseline들을 능가하는 성능을 보였으며, 이는 LM이 time series 분석 도구로써 유용함을 시사한다.
Zero-shot forecasting
LLM은 few-shot learning 뿐 아니라 zero-shot learning도 수행할 수 있는 잠재력을 가진다. 이 섹션에서는 reprogrammed LLM의 zero-shot learning 학습 능력을 cross-domain adaptation에서 평가한다. 자세히는 dataset A에서 optimize된 모델이 dataset B를 얼마나 잘 forecasting하는지 평가하며, 이때 모델은 dataset B의 어떠한 샘플들에 대해서도 학습되지 않았다.
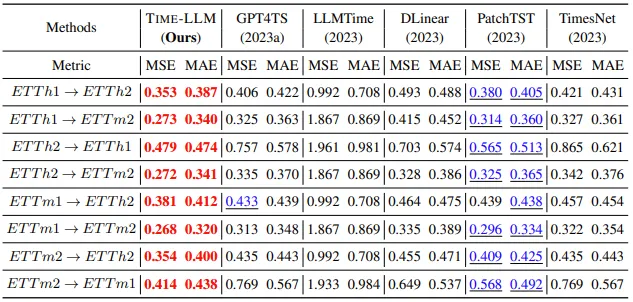
모든 시나리오에서 14.2% 이상의 큰 차이로 우수한 성능을 보임. Few-shot 시나리오에서 향상한 성능이 약 5% 정도임을 감안한다면 Time-LLM은 학습 데이터가 부족한 상황에서 좋은 성능을 발휘한다는 것을 확인함.
Model Analysis
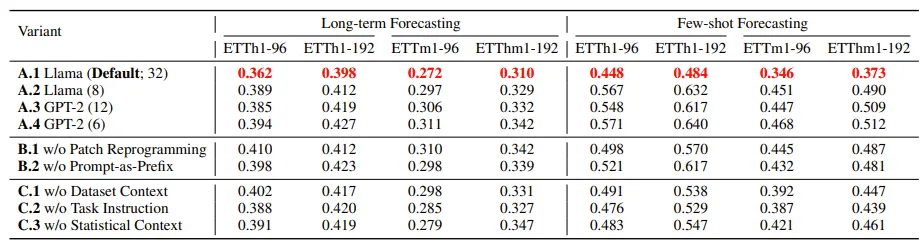
-
Language Model Variants : 다른 용량을 가지는 LLM을 비교하였고, LLM reprogramming 뒤에도 scaling law가 유지됨을 나타낸다. 즉 parameter의 개수가 커질수록 성능이 좋아지는 것을 볼 수 있다. (A.1, A.2, A.3, A.4)
-
Cross-modality Alignment : Patch reprogramming, 즉 representation alignment (B.1)을 제거하면 평균 성능이 9.2% 감소하고, few-shot task에서는 17% 감소한다. 또한 Time-LLM에서는 prompt가 inputs과 task를 이해하는 데 중요한 역할을 하는데, 이를 제거할 경우 (B.2) 평균 성능과 few-shot task에서 각각 8%, 19%의 성능 저하를 보인다. prompt에서 input statistic (C.3)을 제거할 경우 성능 저하가 가장 크며, Task instruction과 input context (각각 C.2, C.1)을 제거하였을 때도 성능 저하가 일어난 것으로 이러한 prompt가 모델의 성능에 영향을 미친다고 해석할 수 있겠다.
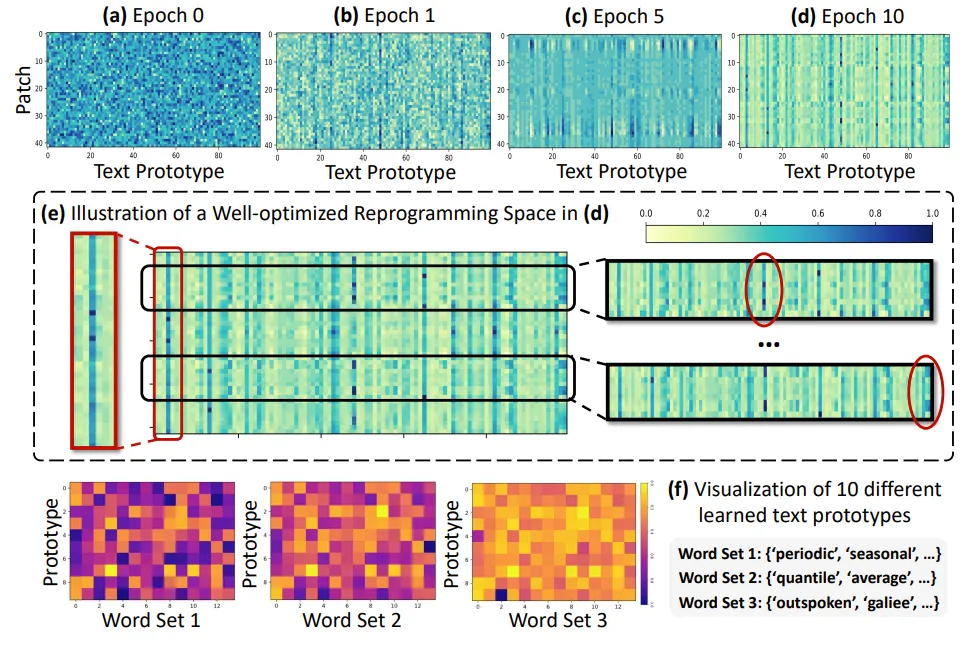
-
Reprogramming Interpretation : 48개의 ETTh1 time series patch를 100개의 text prototype로 reprogram한 결과가 제시됨. 위에 4개의 subplot은 무작위로 초기화된 (a)의 상태에서부터 최적화된 (d)의 상태까지 reprogramming space의 optimization 과정을 나타냄. (e)에서 확인할 수 있듯, input patches (행)을 reprogramming하는데 참여하는 prototypes (열)은 소수에 불과함. 또한 patches들은 서로 다른 prototypes들의 조합을 통해 여러 representation을 거친다. 이는 다음과 같은 점을 시사함.
- text prototype는 language cues를 요약하는 법을 학습하며, 일부 prototype이 time series patch의 정보를 나타내는 데 매우 중요함. subplot (f)에서 무작위로 선택된 10개의 prototype과 time series data의 특성을 설명하는 word set 1, 2와의 연관성이 높은 것을 확인할 수 있음.
- patch들은 다른 의미를 가지며, 이를 표현하기 위해서는 다른 prototype이 필요함.
