arxiv link
https://arxiv.org/pdf/1511.01432
Introduction
RNN은 Sequential data를 모델링하는데 강력한 도구임에도 불구하고, backpropagation을 통한 학습이 어렵다는 단점이 있다 (장기 기억 소실 문제, vanishing gradient). 따라서 텍스트 분류와 같은 NLP task에 잘 쓰이지 않는다.
여러 문서 분류 작업에 대해 LSTM RNN의 하이퍼파라미터를 최적화할 경우 좋은 성능을 달성할 수 있음을 발견하였다. 또한 간단한 Pre-Training만으로도 LSTM의 훈련을 안정시킬 수 있다 (ex : NLP task에서 recurrent Language Model을 unsupervised method로 훈련시키기). 다른 방법은 sequence autoencoder을 사용하는 것으로, 이는 Long input sequence를 읽고 single vertor로 인코딩한 뒤, single vector을 이용하여 original sequence를 복원한다. 이 두 가지 Pre-training으로 얻어진 가중치는 LSTM RNN의 초기 가중치로 사용되어 training / generalization 성능을 향상시킬 수 있다.
본 실험에서는 20 Newsgroup 및 DBpedia 와 같은 문서 분류 작업, IMDB, Rotten Tomatoes와 같은 감정 분석 작업에 대해 LSTM Pretrained with recurrent LM 혹은 sequence autoencoder을 통해 사전학습된 모델들이 randomly initialized LSTM에 비해 좋은 성능을 보이는 것을 확인하였다.
또한 관련 작업의 unlabeled data를 이용하여 pretrain에 사용할 시 subsequent supervised model의 generalization performance를 향상할 수 있다. 예시로 Amazon의 review (no label)을 사용하여 sequence autoencoder을 학습하면 Rotten Tomato dataset의 성능이 79.7%에서 83.3%로 향상된다.
이러한 semi-supervised learning 접근은 unsupervised sequential learning에 비해 몇 가지 장점이 있는데, 그 중 하나는 Fine-tuning이 용이하다는 점이다. 이 논문에서 제시하는 semi-supervised learning approach는 Skip-Thought Vector와 관련이 있는데, Skip-thought는 인접 문장을 예측하기 때문에 더욱 아렵고 순수한 unsupervised learning이기 때문에 fine tuning을 포함하지 않는다는 차이점이 있다.
Sequence autoencoders and recurrent language models
본 연구는 seq2seq에서 영감을 받았다. 이 접근법의 핵심은 recurrent network를 input encoder로 사용하여 input sequence를 hidden state로 인코딩하고, 이 hidden vector을 recurrent networt를 사용한 decoder에 입력하여 output sequence를 예측하는 것이다.
sequence autoencoder은 이러한 컨셉과 비슷하긴 한데, unsupervised mmodel이라는 점이 다르다. sequence autoencoder은 input sequence를 그대로 reconstruction하는 것을 목표로 한다. 이는 seq2seq에서 output sequence를 input sequence로 대체하는 것을 의미하며, 따라서 이 논문에서의 sequence autoencoder는 input decoder와 ouptut decoder의 가중치가 동일하다.
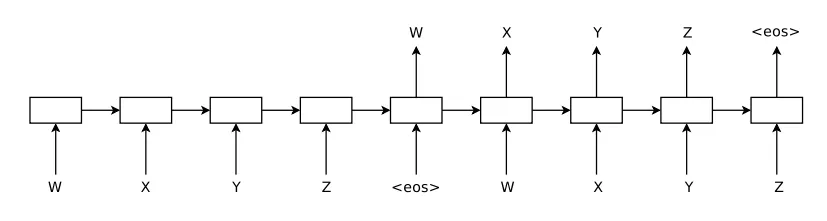
저자들은 sequence autoencoder에서 얻은 가중치를 sequence classify task에 사용되는 다른 supervised network의 초기 가중치로 사용할 수 있음을 발견한다. 이는 네트워크가 input sequence를 기억할 수 있기 때문이라고 가정한다. 또한 gradient에 shortcht이 존재하기 때문에 sequence autoencoder이 Recurrent Network의 초기화에 좋은 방법이라는 가설을 세웠다.
sequence autoencoder의 중요한 특징 중 하나는 unsupervised라는 점이며, 따라서 대규모의 unlabeled data를 이용해 성능을 개선할 수 있다. 결과에서 보겠지만, 적은 labeled data를 가지는 상황에서 unlabeled data를 이용하여 성능을 개선할 수 있다는 점이 매우 큰 장점이다.
또한 recurrent LM이 LSTM을 위한 pre-training 방법으로 사용될 수 있다는 것을 발견했다. 이는 위의 그림에서 encoder단을 제거하는 것과 같다. 이는 무작위로 초기화된 LSTM보다 나은 성능을 보인다.
Overview of methods
이 실험에서는 표준 LSTM recurrent network를 사용한다. 기본 LSTM과 sequence autoencoder method로 초기화된 LSTM을 비교한다. LSTM이 sequence autoencoder로 초기화 되었다면 SA-LSTM이라고 부르고 LM으로 초기화되었을 경우 LM-LSTM이라고 부른다.
대부분 실험에서 LSTM 출력의 마지막 timestep에서 문서의 label을 예측하는 output layer을 사용한다. 또한 모든 timestep에서 label을 예측하고 prediction objective의 가중치를 0에서 1까지 선형적으로 증가시키는 방법도 실험한다. 이를 통해 recurrent network의 초기 timestep에 gradient를 주입할 수 있으며, 이는 linear label gain 이라고 한다.
마지막으로, sequence autoencoder과 supervised learning task를 공동으로 학습하는 방법도 실험하며, 이는 joint training이라고 부른다.
Experiments
LSTM을 사용한 실험에서, cell ouptut과 gradient를 clipping한다. benchmark는 text understanding task이다. 여기에는 IMDB and Rotten Tomatoes 데이터셋을 사용한 sentiment analysis와 20 Newsgroups and DBpedia를 사용한 text classification이 포함된다. 이러한 데이터셋에서 주로 사용되는 방법인 bag-of words 혹은 n-grams는 긴 범위의 문장 순서를 무시한다. 따라서 순서 정보를 유지하는 recurrent method가 좋은 성능을 낼 것이라고 예상되지만, 최적화가 어려워 잘 쓰이지 않았다.
sequence autoencoder을 사용한 실험에서는 모든 입력 단어를 읽은 뒤 전체 문서를 reproduce하도록 한다. 즉 truncation 혹은 windowing을 수행하지 않는다. 각 input sequence 끝에 eos (end of sentence) 마커를 추가하고 네트워크가 eos 이후에 sequence를 reproduce하도록 학습한다. 또한 sequence의 끝에서 400 timestep까지 truncated backpropagation을 수행한다. 텍스트 전처리 과정에서는 구두점을 별도의 토큰으로 취급하고, 영어가 아닌 문자나 단어는 무시하였다. 또한 데이터셋에서 한번만 나타나는 단어들은 제거하였고, term weighting or stemming은 수행하지 않았다.
recurrent LM 혹은 sequence autoencoder을 batch size 128, 500k step만큼 학습한 뒤 word embedding parameter와 LSTM weight를 LSTM for supervised task의 가중치를 초기화하는데 사용하였다. 이후 embedding parameter와 weight를 fine tuning하며 학습하고, val error가 증가하기 지삭할 때 earlystopping을 사용한다. dropout rate는 val set을 기반으로 선택한다.
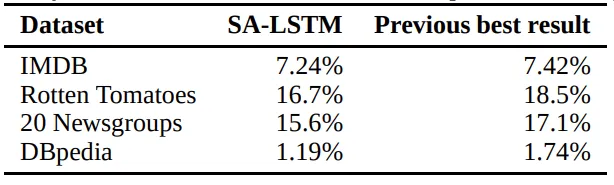
SA-LSTM을 사용하였을 때 모든 데이터셋에서 보고된 결과와 비슷하거나 그 이상의 성능을 달성할 수 있었다. 이전의 결과들은 다른 다양한 방법들을 사용하였을 때 도출된 결과로, SA-LSTM 하나의 방법으로 모든 데이터셋에서 최고의 성능을 도출한 것은 중요한 의미를 가지며, text understanding에서 general model로 사용될 수 있음을 시사한다.
Sentiment analysis experiments with IMDB
IMDB 영화 감정 데이터셋에서 모델을 실험한다. training set에는 25000개의 labeled document와 50000개의 unlabeled document가 있으며, test set에는 25000개의 document가 있다. labeled document의 15%를 val set으로 사용한다. 각 문서의 평균 길이는 241개의 단어이며, 최대 길이는 2526개의 단어이다. baseline은 bag-of-word, ConvNet, Paragraph vector이다.
문서가 길기 때문에 recurrent network가 학습하기 어렵다고 생각할 수도 있으나, tuning을 통해 LSTM recurrent network가 training set을 학습할 수 있음을 발견한다. 예를 들어 hidden state의 크기를 512unit으로 설정하고 backprop를 400 step으로 제한하면, LSTM은 괜찮은 성능을 낸다. 또한 random embedding dimension dropout과 random word dropout을 사용하면 86.5%의 정확도를 달성할 수 있다.
이 접근 방식의 문제점은 unstable하다는 것이다 : 즉 hidden unit을 늘리거나 backprop step을 늘리면 training이 매우 불안정해진다. 즉 gradient clipping을 수행하더라도 objective function이 explode하게 된다. 이는 LSTM이 긴 문서를 다룰 때 하이퍼파라미터에 매우 민감하기 때문이다. 반면 SA-LSTM은 이러한 하이퍼파라미터를 변경해도 거의 영향을 받지 않았다. 이는 모델 학습을 더욱 용이하게 만든다.
sequence autoencoder을 사용하면 LSTM의 optimization instability를 해결할 수 있으며 training set에서 분류를 빠르고 쉽게 달성할 수 있다. overfitting을 해결하기 위해 input dimension dropout을 사용한다. 실험 결과는 아래의 표에 나타난다. 또한 training set의 word2vec embedding으로 LSTM을 초기화한 성능도 추가한다.
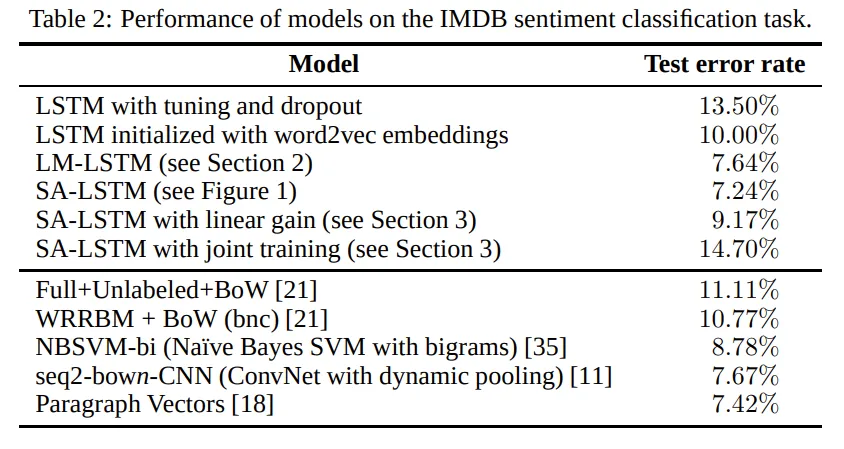
input embedding dropout과 함께 사용된 SA-LSTM이 이 데이터셋에서 이전에 나타난 최고성능과 비슷하거나 더욱 좋은 결과를 낼 수 있음을 나타낸다. 반면 sequence autoencoder가 없는 LSTM은 long range dependency때문에 최적화에 어려움을 겪는다.
LM을 초기화에 사용하는 방법 (LM-LSTM)도 잘 작동하긴 하지만 SA-LSTM에 비하면 성능이 떨어지는데, 이는 LM이 short-term에 최적화되어있기 때문에 hidden state가 다음 몇 개의 단어만을 예측하는 능력을 가지고 있기 때문일 것이다.
여기서 memory cell에 1024 unit을, input embedding layer에 512 unit을 사용하였고, 마지막 hidden state와 classifier 사이에 50%의 dropout을 가지는 512 unit의 hidden layer을 사용한다. 이후 실험에서도 이러한 설정을 계속 사용한다.
table 3에서는 SA-LSTM으로는 잘 분류되었지만 bigrams NBSVM으로는 잘 분류되지 않은 예시를 보여준다. 이는 long-term dependency를 가지거나 짧은 구절만으로는 찾기 힘든 비유/풍자를 포함한다.

Sentiment analysis experiments with Rotten Tomatoes and the positive effects of additional unlabeled data
이 실험에서는 Rotten tomato dataset을 사용한다. 10662개의 문서로 이루어지며, 80%는 training, 10%는 validation, 10%는 test에 사용된다. 각 문서의 평균 단어 길이는 22개이며, 가장 긴 것은 52개를 가진다. 문서 수와 단어 수가 모두 IMDB보다 작다.
첫 번째로 이 데이터셋이 IMDB보다 LSTM을 훈련하기 좋다는 것을 발견한다. 또한 LSTM, LM-LSTM, SA-LSTM간의 성능 격차가 이전보다 작았다. 이는 Rotten tomato의 리뷰는 문장 단위인 반면 IMDB는 문단 단위였기 때문이다.
데이터셋이 매우 작기 때문에 training set에서 overfitting이 일어날 가능성이 있었다. 따라서 SA-LSTM에 95%의 input embedding dropout과 50%의 word dropout 을 결합하고, 하이퍼파라미터를 튜닝하여 test error rate를 낮추었다.
또한 성능 개선을 위해 IMDB와 Amazon movie review에서 unlabeled data를 추가하여 autoencoder의 훈련 단게에 사용하였다. 또한 Google News로부터 word2vec 방식으로 학습된 pretrained word vectors를 사용하는 실험도 수행하였다.
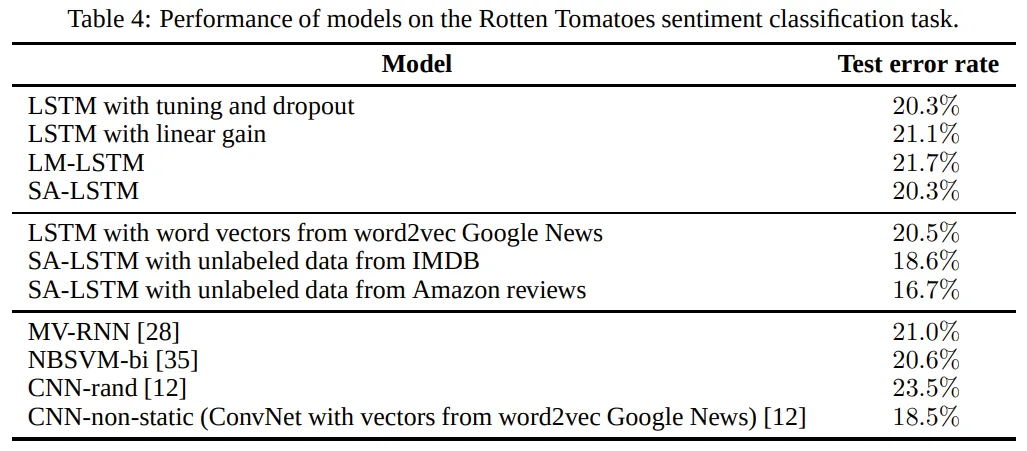
word2vec에서 word vector을 사용할 경우 0.5%의 성능 향상만을 보였다. 이는 recurrent weight가 중요한 역할을 하며, 이 실험에서는 적절하게 초기화되지 않았기 때문일 것이다. 그러나 IMDB를 이용하여 equence autoencoder을 pretrain할 경우 2%의 정확도 상승을 보였다. Amazon review (7.9백만 개)와 같이 더 큰 unlabeled dataset을 이용하여 pretrain을 진행할 경우 정확도는 또 2%만큼 상승하였다.
이는 unlabeled data를 사용하는 것이 labeled data를 추가하는 것에 비해 얼마나 좋은지에 대한 질문으로 이어진다. “Recursive deep models for semantic compositionality over a sentiment treebank”를 참고하자면, 여기서 이 방법이 아직 완벽하지 않은 이유는 labeled training data가 부족하기 때문이다. 이들은 Stanford Parser을 이용하여 더 많은 label data를 사용하는 방법을 제안했다. 이 경우 test set에서 15%의 error rate를 달성하며, 이는 label data가 적은 방법보다 5% 개선된 수치이다.
저자들은 문장 단위의 classification에서 위 방법론과 sequence autoencoder을 비교하며, unlabeled data와 sequence autoencoder을 이용한 경우 16.7%의 error rate를 달성하며 다른 labeled corpus를 이용하는 방법들 사이에서 두번째로 좋은 성능을 발휘한다. unlabeled data는 구하기가 쉬우며, 이러한 점에서 unlabeled data를 이용할 수 있다는 점이 중요하다.

Text classification experiments with 20 newsgroups
지금까지는 문서 내의 단어수가 비교적 적은 데이터셋에 대해 실험을 진행했으나, 이 섹션에서는 20 Newsgroups dataset에 대해 실험을 수행한다. 여기에는 training set에 11293개, test set에 7528개의 문서가 있고 training set의 15%는 val set으로 사용된다. 각 문서는 이메일 형식으로 되어 있으며 평균 267개의 단어가 존재하며, 최대 단어수는 11925개이다. 이전에는 문서의 길이가 매우 길기 때문에 Recurrent network에서 학습이 잘 안될 것이라고 예상했다. 기존의 가장 우수한 방법은 Bag of words이기도 했다.
LSTM과 SA-LSTM을 이용하여 동일한 실험을 반복한 결과, 기존과 마찬가지로 SA-LSTM은 LSTM보다 안정적으로 훈련되었다. input embedding dropout과 word dropout을 사용한 결과 SA-LSTM은 test set에서 15.6%의 error rate를 달성했으며, 이는 기존의 방법들보다 좋은 성능이다.
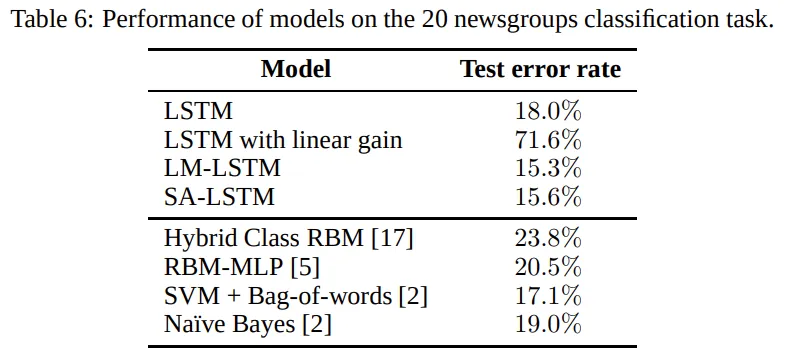
Character-level document classification experiments with DBpedia
이 실험에서는 문자 단위 입력을 받는 위키피디아 페이지를 분류하는 task에 대해 실험한다. 실험에 사용되는 데이터셋은 DBpedia dataset으로, 중복이나 taint가 없어서 이 데이터셋에 대해 이전 연구들의 결과를 비교한다.
이 실험에서는 문자 단위의 입력을 읽은 후 DBpedia dataset을 14개의 카테고리 중 하나로 분류한다. 데이터셋은 560000개의 training set과 70000개의 test set으로 나뉜다. 문서의 평균 길이는 300자이며, 최대 길이는 13467자이다. 이렇게 크기가 크기 때문에 overfitting의 문제는 고려하지 않으며, 따라서 dropout은 생각하지 않는다. 두 개의 LSTM layer을 가지며 각 layer은 512개의 hidden unit을 가진다. input embedding은 128개의 unit으로 사용한다.
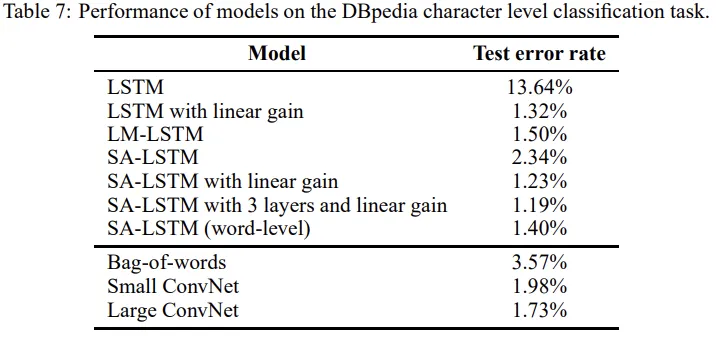
linear label gain이 학습의 초기 단계에서 LSTM에 gradient를 주입할 수 있기 때문에 효과적임을 발견했다. 특히 SA-LSTM과 linear label gain을 결합하였을 때 성능이 가장 높았다.
Object classification experiments with CIFAR-10
이 실험에서는 텍스트가 아닌 데이터에 대해서도 pre-training이 효과적인지 확인한다. CIFAR-10 이미지 데이터셋은 10개 클래스에 속하는 60000개의 32 * 32 컬러 이미지로 구성되어 있으며, 여기서 LSTM을 학습시킨다. LSTM의 한 timestep 입력은 row의 전체 픽셀 (32개) 이며, 마지막 row를 읽은 후 이미지의 클래스를 예측한다. 추가적으로 crop과 같은 데이터 증강 방법을 사용한다.
추가적으로 LSTM을 현재의 row가 주어졌을 때 다음 row의 prediction을 하는 용도(이를 LM-LSTM이라고 부름), 이미지를 자동으로 row 단위로 인코딩하는 용도 (SA-LSTM)으로 훈련시킨다. unsupervised learning에 필요한 loss function은 Euclidean L2 loss로 설정하고, 분류 작업에 대해 fine-tuning하여 결과를 제시한다.
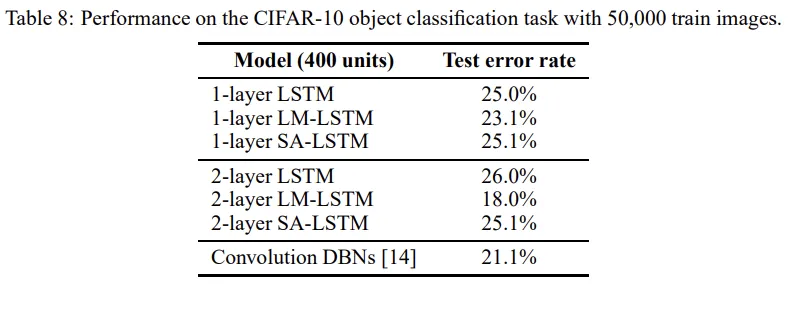
기존 CNN에 비해서는 조금 성능이 떨어지지만, convolution을 사용하지 않고도 좋은 결과를 낼 수 있음을 보여줌.
